一种基于预测的键值存储数据库副本选择方法与流程
本发明涉及一种基于预测的键值存储数据库副本选择方法。
背景技术:
在分布式键值存储系统中,一个终端请求可以生成大量的键值,需要几十个甚至几百个服务器来进行服务。这些键值请求的延迟直接影响终端请求的响应时间。响应时间过长一直是影响用户体验和收益的重要因素之一,降低键值请求的尾延迟具有重要意义。其中,为键值请求选择合适的副本服务器是降低尾延迟的有效方法之一。
由于服务器的性能波动等原因,选到合适的副本服务器并非易事。首先,如果所有的客户端都选择最快的副本服务器,高并发会导致副本服务器性能的急剧下降。因此,副本选择算法必须能够避免这样的羊群效应。其次,由于键值存取的轻量级特性,副本选择算法必须足够简单。为解决以上问题,适应服务器的性能变化,副本选择算法c3应运而生。c3的主要思想是,将服务器的等待队列长度信息及键值的服务时间随返回值一起反馈给客户端,并通过这些反馈信息对副本服务器进行打分排序,从而选出最快的副本服务器。
在键值存储数据库中,副本选择算法决定了每一键值存取操作的副本服务器,极大地影响每一个键值存取操作的延时,是降低应用请求的响应时间(亦即所有键值操作的尾延时)的重要方法之一。虽然c3在降低尾延迟方面表现良好,但是我们发现c3依然存在进一步的改进空间。当收到反馈信息时,c3对反馈信息进行指数加权平滑(ewma)计算来估计服务器端的等待队列长度和服务器的服务速度。然而,副本排序操作与收到反馈信息之间存在时间差,一旦这个等待时间(τw)较长,服务器的性能波动会导致服务器的状态发生变化,而之前的等待队列长度估计值将无法反应此时的服务器状态。我们把这种情况称之为时效性问题。虽然当前的副本选择算法c3创造性的引入反馈信息指导副本选择,并获得了良好的性能表现,但是其存在反馈信息的时效性经常会变得很差。当时效性很差(τw≥100ms)时,c3不准确的等待队列长度估计,将直接影响副本服务器的选择,致使等待队列长度增长迅速,进而导致排队延迟剧增。
技术实现要素:
为了解决上述c3副本选择算法的时效性问题,本发明提出了一种基于预测的键值存储数据库副本选择方法,即predication-basedreplicaselectionalgorithm,简称为prs。在反馈信息不具有时效性时,即τw≥100ms时,prs方法使用预测方法代替简单的指数加权平滑估计服务器的等待队列长度。通过更准确的等待队列长度估计,选择更合适的副本服务器。
为了实现上述技术目的,本发明的技术方案是,
一种基于预测的键值存储数据库副本选择方法,包括依次执行的等待队列长度变化趋势判断、预测等待队列长度和副本排序三个步骤;
其中等待队列长度趋势判断包含以下三个步骤:
步骤一:通过键值访问操作的返回值携带的方式将包括等待队列长度变化量在内的信息反馈给客户端,客户端收到反馈信息时,执行步骤二;
步骤二:根据反馈信息判断当前副本服务器的等待队列长度的变化趋势;
步骤三:如果等待队列长度变化趋势未改变,存储当前反馈信息及其时间戳,如果等待队列长度变化趋势发生变化,存储当前反馈信息及其时间戳,同时删除上一个等待队列长度变化趋势内所有存储的反馈信息;
预测服务器等待队列长度分为以下三个步骤:
步骤1:判断步骤三中新存储的反馈信息的时效性的强弱,如果是强时效性执行步骤2,如果是弱时效性执行步骤3;
步骤2:取这个强时效性的反馈信息中的等待队列长度,与之前所有收到的反馈信息中等待队列长度进行指数加权平滑的历史记录结果再进行指数加权平滑,以作为服务器端的等待队列长度估计,并将结果存储为新的指数加权平滑的历史记录结果,然后执行副本排序操作;
步骤3:根据步骤二的等待队列长度变化趋势以及步骤三存储的信息,对服务器端的等待队列长度进行预测,执行副本排序操作;
副本排序操作:根据步骤2或步骤3算出的估计等待队列长度对服务器副本进行性能评估,最后选取性能评估结果最好的副本服务器。
所述的方法,步骤一中,反馈信息包括每5ms内的等待队列长度的变化量δqs,等待队列长度
所述的方法,步骤二中,根据等待队列长度的变化量δqs和等待队列长度
所述的方法,步骤三中,如果等待队列长度变化趋势发生变化,则通过以下步骤来判断上一个反馈信息是否保留:使用上一个反馈信息中的等待队列长度减去新的反馈信息中等待队列长度,如果结果为正,且当前等待队列长度变化趋势为下降,该反馈信息需要保留;如果结果为负,且当前等待队列长度变化趋势为上升,该反馈信息也需要保留,否则不保留。
所述的方法,步骤1中,判断反馈信息是否时效性的强弱是用反馈信息的时间戳与当前时间比对,阈值设定为100ms,如果小于等于100ms,反馈信息具有强时效性,如果大于100ms,反馈信息具有弱时效性。
所述的方法,步骤3中,如等待队列长度变化趋势为上升或下降状态,预测所使用的方法为最小二乘拟合方法,根据当前存储的反馈等待队列长度及其时间戳,拟合出一个等待队列长度对时间的线性函数,代入当前时间,计算结果即为预测的等待队列长度;
如等待队列长度变化趋势为平稳状态,使用指数加权平滑算法预测等待队列长度
其中
所述的方法,副本排序操作中,对副本进行排序的操作分为以下步骤:将步骤2或3算出的等待队列长度值代入打分函数,按照得分从小到大的顺序对副本进行排序,选取分数最低的副本服务器。打分函数如下所示:
其中,rs为客户端收集的响应时间,
本发明解决上述时效性问题的技术方案包含以下几个步骤:首先,将等待队列长度的变化趋势分为三种状态:平稳状态,上升状态和下降状态。在收到反馈信息时,通过反馈信息判断服务器当前的等待队列长度变化的趋势,并将处于当前趋势的反馈信息及其时间戳存储下来,除位于边界的有用的反馈信息外将上一个等待队列长度变化趋势的反馈信息删除。其次,把反馈信息按时效性分为τw超过100ms和不超过100ms两个部分。实验证明τw不超过100ms的反馈信息为具有时效性的可用反馈信息,因此,在τw不超过100ms时,依然采用与c3相同的等待队列长度估计方法。在τw超过100ms时,通过当前的等待队列长度的变化趋势以及在等待队列长度变化趋势判断后存储的反馈信息对服务器的等待队列长度进行预测。在对服务器端等待队列长度进行预估后,prs依旧选用与c3相同的打分函数进行副本排序,但是由于prs的等待队列长度预测更准确,因此prs的性能优于c3。
下面结合附图对本发明作进一步说明。
附图说明
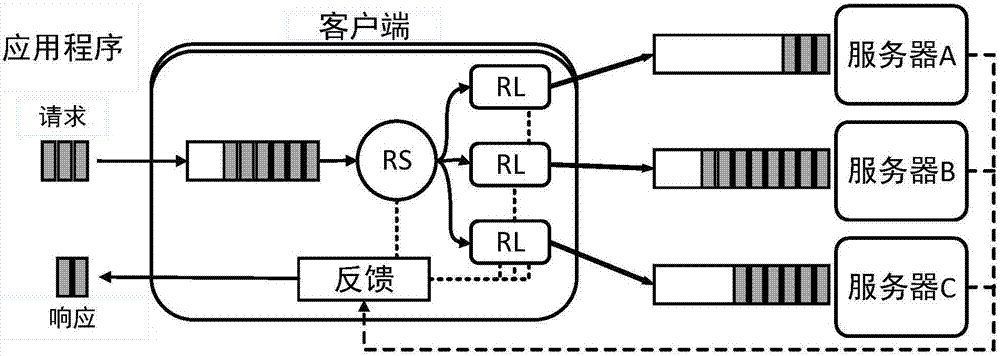
图1为键值存储系统的副本选择架构图。
图2为c3的等待队列长度,反馈等待队列长度以及估计等待队列长度,上图为τw≥100ms的情况,下图为τw<100ms的情况。
图3为c3的等待队列长度及其反馈的等待队列长度。
图4为prs的等待队列长度趋势及其判断条件示意图。
图5当等待队列长度变化趋势发生变化时,位于边界的反馈信息不需删除的情况的示意图。
图6为prs的预测等待队列长度以及等待队列长度趋势判断的效果图。
图7为prs算法与c3算法在不同客户端数目环境下的延迟表现的测试效果图。
图8为prs算法与c3算法在20%的客户端产生80%的请求的环境下的测试效果图。
图9为prs算法与c3算法在50%的客户端产生80%的请求的环境下的测试效果图。
图10为prs算法与c3算法在不同副本数的环境下的延迟表现的测试效果图。
具体实施方式
为使本发明的目的、内容及优点更加清楚,下面结合附图对本发明的实施方式进行具体的阐述。
本发明所述的prs算法,是针对副本选择算法c3的时效性问题,进行改进。由于排队延迟是尾延迟的重要组成部分,所以等待队列长度估计是副本打分函数的核心所在。c3副本选择算法在τw大于100毫秒时,会遇到严重的时效性问题。此时,使用过时的反馈信息加以指数加权平滑(ewma)获得的估计等待队列长度与服务器的等待队列长度相差极大。如图2所示,qs表示服务器端的真实等待队列长度,
为解决该时效性问题,我们对c3进行了仿真复现,发现在时效性较差时,等待队列长度的变化趋势存在一些规律。首先,服务器的等待队列长度虽然变化频繁,但其趋势变化并不剧烈,甚至可以维持几千毫秒不变化。其次,虽然反馈队列长度不能表示当前的服务器状态,但其依然可以反映等待队列长度的变化趋势。如图3所示,
所述的prs算法对服务器端等待队列长度的预测由判断等待队列长度变化趋势和预测等待队列长度两个部分组成。
判断等待队列长度变化趋势由以下三个步骤组成:
步骤一:将服务器的等待队列长度
步骤二:根据反馈的等待队列长度以及δqs判断等待队列长度的当前变化趋势。
图4为等待队列长度趋势状态及其转换条件。prs将等待队列长度的趋势分为三种状态,平稳,上升和下降。判断当前等待队列长度处于何种状态的操作过程如下:
初始状态设置为平稳状态。prs进入或保持平稳状态的唯一条件为①,
②和③为prs进入到上升状态的条件。如果prs是从平稳状态转换为上升状态,说明等待队列长度增长迅速,因此转换条件为δqs>0与
④和⑤为prs进入到下降状态的条件。这两种条件的设计与上述条件②和③类似。事实上prs不可能从平稳状态直接过渡到下降状态,但是上升状态可能会有反馈信息缺失,因此,条件⑤也是必要的。
步骤三:对反馈信息进行选择,只保留同一趋势内的反馈信息用于预测等待队列长度,之前所保存的上一个不同变化趋势内的反馈信息则删除。其中,对于处于转换边界的反馈信息,需要对其进行判断,如果为可用信息则保留,否则,将之删除。具体的判断方法是使用上一个反馈信息中的等待队列长度减去新的反馈信息中等待队列长度,如果结果为正,且当前等待队列长度变化趋势为下降,该反馈信息需要保留;如果结果为负,且当前等待队列长度变化趋势为上升,该反馈信息也需要保留,否则不保留。
图5所示的三种情况的边界反馈信息为可用的,需保留的信息。即只有该反馈可以作为下一趋势的起点时,判定该反馈信息有用。
预测等待队列长度由以下步骤组成:
步骤1:判断反馈信息的时效性,即τw是否超过100ms。
步骤2:如果τw≤100ms,即认为反馈信息具有强时效性,使用ewma方法估计等待队列长度。取这个强时效性的反馈信息中的等待队列长度,与之前所有收到的反馈信息中等待队列长度进行指数加权平滑的历史记录结果再进行指数加权平滑,以作为服务器端的等待队列长度估计,并将结果存储为新的指数加权平滑的历史记录结果,然后执行副本排序操作。此处执行ewma方法所取的历史记录结果,是指从运行prs开始,在执行该步骤时,对反馈信息中等待队列长度进行指数加权平滑后,会得到一个指数加权平滑的结果,将这个结果保存,并在下一次运行该步骤时作为指数加权平滑的其中一个输入,与新的反馈信息中等待队列长度再次执行指数加权平滑后,将新的结果覆盖原来的历史记录结果,如此循环运行。
步骤3:如果τw>100ms,即认为反馈信息具有弱时效性,利用判断等待队列长度变化趋势操作收集的信息,进行等待队列长度预测。具体操作如下:
如果当前等待队列长度的变化趋势为平稳,prs使用判断等待队列长度变化趋势操作收集的反馈信息的ewma值作为预测等待队列长度值。计算公式如下:
其中
如果当前等待队列长度的变化趋势为上升或者下降,prs使用判断等待队列长度变化趋势操作收集的信息进行最小二乘拟合,在拟合函数中代入当前时间计算出预测等待队列长度值。
另外,在上升状态,如果同一个拟合函数被重复使用了4次,证明反馈信息已经很久没有更新,在这种情况下,prs增加了一个补充机制。如果这4次预测的osk(客户端已发送但未收到反馈的请求数)都等于0,那么第5次打分时,直接将预测等待队列长度值置0,以确保该服务器能够确定被选到。对于一个长时间没有键值请求发送过去的服务器,需要尝试发送请求以获得其反馈信息。在下降状态,如果预测值小于0,直接将其置0。
根据步骤2或步骤3算出的估计等待队列长度对服务器副本进行性能评估,最后选取性能评估结果最好的副本服务器。具体是将步骤2或3算出的等待队列长度值代入打分函数,按照得分从小到大的顺序对副本进行排序,选取分数最低的副本服务器。打分函数如下所示:
其中,rs为客户端收集的响应时间,
为了验证本发明的性能表现,对prs与c3进行了仿真实验。
在仿真模拟实验中,终端请求的到达服从泊松分布。每个键值请求的服务时间服从均值为4的指数分布。为了模拟服务器的性能波动,每隔500毫秒每个服务器的服务速率有50%的概率在均值μ和μ*3之间波动。单程的网络延迟为250微秒。系统共有200个请求生成器,50个服务器,默认有150个客户端。每次实验重复五次取平均值。键值请求总数为600000。
图6为prs的预测等待队列长度以及等待队列长度变化趋势判断的效果图。qp为使用prs方法预测的等待队列长度,qe为c3使用的ewma等待队列长度估计,此图只展示了τw>100ms的情况。显然,prs的预测等待队列长度更加的准确,尤其是在等待队列长度的变化趋势未改变的时候。等待队列长度的变化趋势的判断的正确性直接的影响等待队列长度预测的准确程度。从图6中也可以看出,prs对于等待队列长度的变化趋势判断的先见之明。三种不同的线型表示等待队列长度即将进入对应的三种状态。图6显示出大部分的预判是正确的,而少部分的误判,会在下次反馈到来时得到及时的修正。为了更有说服力,本发明统计了prs和ewma的估计值与真实等待队列长度值的差值,结果显示,prs比c3更接近真实等待队列长度的预测结果占57%,两者相似的结果占13%,剩下的30%c3较prs接近。其中,两种方法的差值小于等于1的情况,在统计中认为二者相似。总的来说,相比于c3,prs的预测等待队列长度更加的准确
图7展示了prs算法与c3算法在不同客户端数目环境下的99th%的延迟表现的测试效果图。客户端数目的变化可以直接影响键值请求的并发程度以及反馈信息的疏密,因此客户端越多,延迟越大。从图7中可以看出,prs算法是优于c3算法的。
图8和图9展示了prs算法与c3算法在键值请求偏斜的情况下的99th%的延迟,分别为20%的客户端生成80%的键值请求和50%的客户端生成80%的键值请求。显而易见地,prs的延迟远小于c3。在键值请求偏斜的情况下,反馈信息更加的密集,prs的性能更优。
图10展示了副本数目的变化对99th%的延迟的影响。在这里将副本数从3依次增加到5。由于副本数目的增加,选择最快的副本服务器变得更难,尾延迟也随着副本数增加而增加。从图10中可以看出,在副本数增加时,prs在降低尾延迟方面依然优于c3。
- 还没有人留言评论。精彩留言会获得点赞!