一种云存储节点负载均衡方法与流程
本发明涉及云计算,特别涉及一种云存储节点负载均衡方法。
背景技术:
云计算作为一种服务,需要向用户提供可靠、高效的大规模数据服务,并且由服务运营商保证数据的安全性以及可用性。但是,在主流云存储的mapreduce过程中存储节点意外失效的概率很大,大规模的云平台出现过由于存储节点失效而造成的系统崩溃事件曾经给数以千万计的企业用户和个人用户造成了巨大的损失。因而,容错技术的发展是为存储节点中的数据创建多个数据拷贝,并将生成的若干个拷贝按照一定的策略分散存储到不同的存储节点上。当存储节点失效造成数据丢失时,按照策略访问存储在有效存储节点上的有效拷贝恢复数据。所以,只要能从网络中获取足够多的数据块,就能够还原出系统所存储的原始数据,这尽管增加了系统的可靠性,但也成为系统的安全瓶颈。存储集群彼此间需要依靠外网进行连接,那么必然要向外开放端口,而且,存储集群之间往往距离较远,系统很难完全掌控整个系统中存储集群内存储节点的状态,这样的特点也使攻击者更容易利用存储集群的开放性来实现对云的攻击。
技术实现要素:
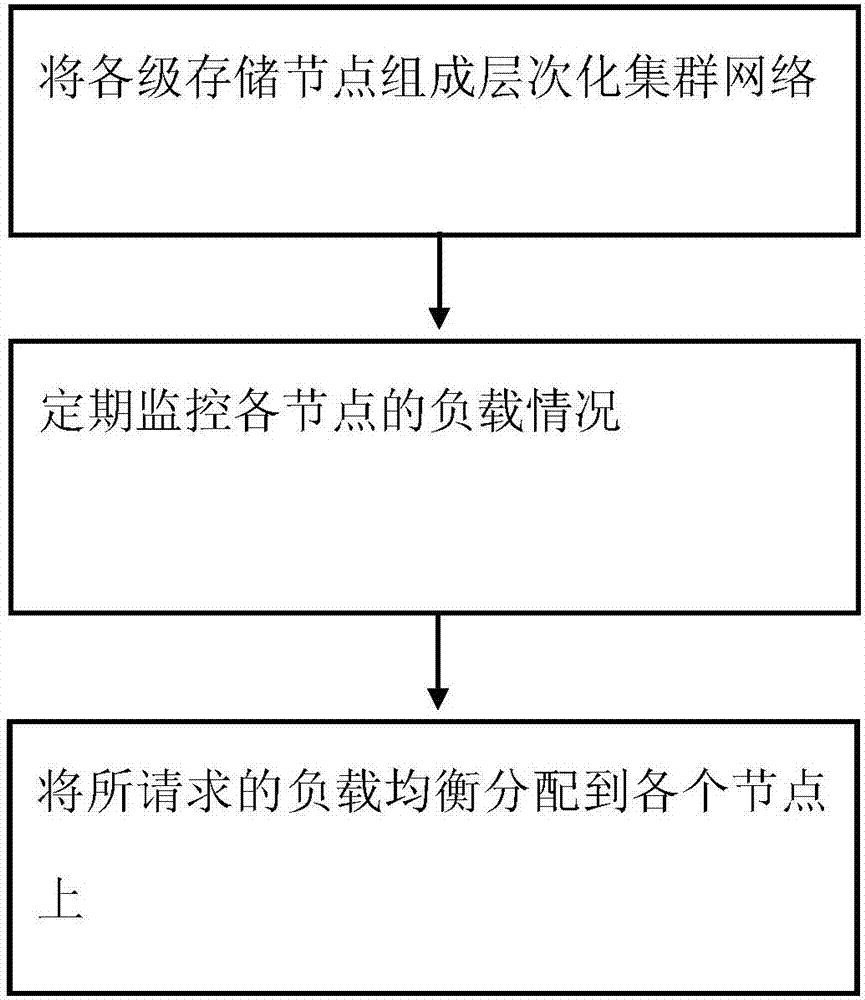
为解决上述现有技术所存在的问题,本发明提出了一种云存储节点负载均衡方法,包括:
将各级存储节点组成层次化集群网络,定期监控各节点的负载情况,将所请求的负载均衡分配到各个节点上。
优选地,所述将各级存储节点组成层次化集群网络,进一步包括:
主节点维护全部数据拷贝,主节点将所有数据拷贝分配到各个次级节点,次级节点再将数据拷贝分配到下属节点。
优选地,所述定期监控各节点的负载情况之前,还包括:
将叶节点及其向上的各级父节点构成一个虚拟群组;
所述将请求的负载均衡分配到各个节点,进一步包括,将请求的负载均衡分配到虚拟群组中的各个节点上。
优选地,由云计算环境中设置的负载均衡控制引擎来实现系统访问性能的全局最优化。
优选地,当用户通过接口api访问云存储环境时,首先查询全局根数据库,获取存储数据所在的各级存储节点地址,即某个虚拟群组;
接着请求发起节点根据各个节点存储的负载情况选择访问速度最快的节点;
由负载均衡控制引擎协调系统全局资源分配,通过监控各个存储节点的请求负载情况,根据资源分配策略调整各节点的请求通行能力,从而优化系统全局访问性能。
本发明相比现有技术,具有以下优点:
本发明提出了一种云存储节点负载均衡方法,通过智能负载均衡策略实现了系统访问性能的全局最优化,并基于安全架构防止非法用户实现对分布式存储节点之间的非法存取和攻击。
附图说明
图1是根据本发明实施例的一种云存储节点负载均衡方法的流程图。
具体实施方式
下文与图示本发明原理的附图一起提供对本发明一个或者多个实施例的详细描述。结合这样的实施例描述本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求书限定,并且本发明涵盖诸多替代、修改和等同物。在下文描述中阐述诸多具体细节以便提供对本发明的透彻理解。出于示例的目的而提供这些细节,并且无这些具体细节中的一些或者所有细节也可以根据权利要求书实现本发明。
本发明的一方面提供了一种云存储节点负载均衡方法。图1是根据本发明实施例的一种云存储节点负载均衡方法流程图。
大规模分布式系统中,即特定区域内的用户只对特定部分的数据最感兴趣,因此在本发明的云存储环境中,各级存储节点组成一个层次化集群网络,主节点维护全部数据拷贝,主节点按照数据所属地域将所有数据拷贝分配到各个次级节点,次级节点再将数据拷贝分配到下属节点。叶节点及其向上的各级父节点构成一个虚拟群组。系统负载均衡控制引擎定期监控各节点的负载情况,将各虚拟群组的请求负载分配到虚拟群组内部的各个节点上,实现系统访问性能的全局最优化。
当用户通过接口api访问云存储环境时,首先查询全局根数据库,获取存储该数据所在的各级存储节点地址,即某个虚拟群组。接着请求发起节点根据各个节点存储的负载情况选择访问速度最快的节点。负载均衡控制引擎负责协调系统全局资源分配,通过监控各个存储节点的请求负载情况,根据资源分配策略调整各节点的请求通行能力。
云计算环境体系结构有以下3个优点:(1)系统数据具有高可靠性。主节点和各级节点的数据互为异地备份。每一个数据有多个拷贝,且拷贝互为异地备份。(2)系统具有很好的容错性。任何节点的单点故障都不会影响系统运行。例如,当主节点发生故障时,其他拷贝节点可继续为用户提供数据访问服务。(3)系统具有负载均衡能力。主节点和各级节点构成:一个分布式虚拟群组。当某个节点或某条路径访问负载高于预设值时,系统自动将访问请求分配到其他节点上。
在云计算环境多存储节点有向图g(v,e)中,如果单位时间内到达系统的总请求数为λ,访问虚拟群组v的请求数为λv,带宽分配后到达节点j的请求数为λj,节点j的处理能力为μj,则节点j的平均请求等待时间tj为
并计算得到单位时间内到达节点j的请求数占其最大处理能力的比例即节点资源利用率sj为
用θm,j表示节点j的不同服务等级m下的负载请求变量。云存储节点资源调度可以分为2个子问题:一是为不同服务等级用户分配带宽,使用户平均请求等待时间最小化。二是节点负载利用率最大化,即充分利用冗余节点实现请求负载均衡。
综上所述,全局最优化目标为确定负载请求变量θm,j使得不同服务等级业务的平均请求等待时间最小化,同时实现节点资源利用率最大化。
其中n为集群节点总数,m为服务级别数量。
采用线性加权和法将上述目标问题转换为全局最优资源调度目标函数minz(λ):
minz(λ)=αt(θ1,j)+βt(θ2,j)+γt(θ3,j)-hs(λ)/ε
以存储节点间的有向连接数作为解空间维度,每一维对应一条有向连接,其取值为分配给该连接的请求流量。每个粒子对应的d维向量x表示系统资源调度问题的一个解,适应度函数为上式所定义的目标函数。
给定一个l层的云存储集群拓扑图g(v,e),用l(v)表示节点所属的层次。用p(vi,vj)表示vj是vi的子节点。对节点进行划分计算等价关系r(lk)。该r(lk)将某一级节点及其各自所有子节点看作一个粒子,和上级节点归为同一等价类。当li从1增大到k时,在各个级别层次上构建不同粒度的网络拓扑,形成分层的解空间链。
定义等价关系r(lk)对应的解空间为vk={v1k,v2k…,vnk},k=1,2,…,l。v1表示最粗粒度的空间,即将所有节点集合看做一个粒子v11,vl表示最细粒度的空间,其中的节点集合vl={v1l,v2l…,vnl}和原始云存储中的节点一一对应。按照节点集合由粗到细得到v1>v2>…>vl的分层的商集。在vk上定义边集合ek,在层次k的粒度上节点间存在连接的条件为这对粒子包含的子节点在层次l的原始拓扑中存在连接。记存储集群拓扑解空间为gk(vk,ek),k=1,2,...l。根据节点粒度进行排序,g1>g2>…>gl构成一个分层解空间链。
基于上述解空间,逐层对系统负载进行分配。对于位于第k层的某节点vik,其单位时间请求率λ1k为其所有子节点的请求率之和,其请求处理率μ1k为其所有子节点的请求处理率之和。解空间gk中最优分配策略对应的解向量表示为xk。存储节点负载调度根据以下步骤执行。
1.在构建解空间并构建分层解空间链g1>g2>…>gl之后,确定求解最优化算法的粒子群规模m和算法参数,包括惯性因子w、学习因子c和速度阈值s,其中速度阈值s为集群最大负载;。
2.设定最大迭代次数n和迭代终止阈值ε,从第二层解空间开始进行递归求解。即k=2;
3.在解空间gk中,根据节点数量vk构建负载请求变量θkm作为解向量xk。使用粒子群算法完成一次搜索,求得本层粒子的一个最优解;査看该空间是否有更细粒度的空间,如果有转到4),否则转到5)。
4.进入更细一层解空间gk+1,构建负载请求变量θk+1m,使用两个粒子群按照不同的策略进行搜索。第一个粒子群中增加上一层空间求得的最优解作为本次求解的约束条件,即由上一层粒子分解而得的各粒子负载之和不超出上一层粒子获得的最优分配值;第二个粒子群则不增加约束条件进行搜索;当两个粒子群分别完成最优化搜索之后,比较其最优解。如果不加约束条件的粒子群获得的解更优,则将该解合成为上一层空间的最优解,重复步骤4),跳转到上一层空间重新搜索;如果施加约束条件的粒子群获得的解更优,则该最优解为本层粒子的最优解;査看本层是否有更细粒度的空间,如果有则重复步骤4),跳转到下一层空间进行搜索,否则转到5)。
5.完成最细一层解空间,得到原始拓扑空间的负载分配向量。系统根据最优值定义的负载请求变量调度各级服务级别业务请求流量。
在本发明的存储集群体系结构中,为防止非法数据发送和恢复,设备在发送数据时必须使用地址作为来源,在数据发送过程中,该地址被鉴别,从外网通过开放端口传入存储集群内部的数据在没有被分配合法地址的情况下禁止在存储集群内部进行转发。在数据存入系统时,系统为其选择一个安全服务器的集合作为数据恢复服务器。当存储节点失效时,只有系统选定的数据恢复服务器才能够实现数据恢复,而其他服务器即使截获了发送给数据恢复服务器的数据块,也无法恢复原始数据。同时采用独立密钥服务器,用户将数据存放于存储集群时从编码阵列中选取部分加密信息,并将加密信息分发给独立密钥服务器,当需要对失效存储节点中的数据进行恢复或者是其他数据使用者下载数据时,需要向独立密钥服务器提供安全性鉴别,通过鉴别后才能够从中获取编码阵列的加密信息,进而构造解码阵列恢复失效数据或下载原始数据。
本发明的集群网络采用分层体系结构,包括集群接入层以及集群网络层的鉴别,门户网关负责存储集群网络与外网之间的数据交换,并构建不同门户网关之间的穿越外网的数据通道,并具备来源鉴别功能。每个存储集群网络中,设置有一台dns,当主机接入该存储集群网络时,通过向dns发送请求获取可鉴别的来源,该地址理论上在存储集群网络内全局唯一。主机使用该地址向外发送报文,并接受两层鉴别。
存储集群网络外部的合法设备对存储集群的访问是通过存储集群网络的管理设备完成。未被分配可鉴别来源的外部设备若直接访问存储集群网络,其报文将被鉴别设备过滤。
集群接入层设置在汇聚交换机上利用了交换机的物理地址防伪实现服务器物理地址与ip地址的绑定。集群网络层设置在存储集群的门户网关以及汇聚交换机的上游路由器上,对本数据中心内的存储节点向外发送的报文的来源进行鉴别,防止存储集群内的存储节点发起来源伪造攻击,并防止来自于同一网络的其他存储集群的来源伪造攻击。
网络节点由路由器、网关以及交换机组成。网络节点包括密钥存储模块,用于存储和更新鉴别来源所必需的密钥;转发信息数据库,用于保存分组转发所需的路由和交换信息;转发引擎,用于依据转发信息数据库转发报文;鉴别引擎,用于对来源进行鉴别,只有通过鉴别的报文才被送交转发引擎转发。鉴别协议模块:用于网络节点间交换来源鉴别信息,是密钥更新协议和鉴别算法更新;路由交换协议模块:用于网络节点间交换转发信息。
本发明利用散列算法来生成节点的接口id。散列地址的接口id由两部分组成,存储节点的存储集群id和存储节点id,其中存储集群id用以实现集群网络层的存储集群内验证,而存储节点id则用于实现集群接入层鉴别。在每一个存储集群中存储节点id必须全局唯一,保证在存储集群网络中,每一个存储节点的接口id是全局唯一的。
散列地址的生成过程包括以下步骤:
1.存储集群中的存储节点向dns发出申请。存储节点向dns发送的申请中包含有存储节点所属存储集群信息、存储节点管理者信息以及存储节点物理地址,这些信息用于dns判断该节点是否具备获取地址的条件。
2.dns根据存储节点所在存储集群为其选择子网标识。每一个接入子网都被分配一个全局唯一的子网标识,dns依据存储节点提供的存储集群所在网络位置信息选择与之相对应的子网标识用以生成地址;
3.利用散列算法为存储节点生成存储节点id(snid),可表示为:
snid=sha(mac||addrkey)
其中mac为存储节点物理地址;addrkey为dns所拥有的用于生成和鉴别地址的密钥,该密钥存储在dns以及支持分层来源鉴别的网络节点的密钥存储模块中。
4.利用散列算法为存储节点生成存储集群id(scid),可表示为:
scid=sha(snid||addrkey)
5.检查该地址是否全局唯一,若该地址已存在,重新生成snid,生成过程可表示为:
snid=(mac||addrkey||addr_rdmpara)
其中addr_rdmpara为dns选取的用以重新生成存储节点id的随机参数。若生成的地址全局唯一,则将地址分配给存储节点使用。
存储节点向dns申请地址后,集群接入层鉴别过程包括:
1.存储节点向dns申请地址,并以该地址为来源向外发送数据;
2.汇聚交换机从链路层获取存储节点的物理地址;
3.汇聚交换机使用addrkey和存储节点的物理地址,计算发送服务器的存储节点id如果地址生成过程使用了addr_rdmpara,还需要查询并使用与该物理地址对应的addr_rdmpara;
4.将计算出的存储节点id与当前报文中来源的存储节点id进行比较,若相同则继续传输,反之,则丢弃该报文。
集群网络层鉴别可分为存储集群内部鉴别和存储集群间鉴别两部分。存储集群内部鉴别流程包括:
1.路由器从报文中获取来源的存储节点id;
2.路由器使用addrkey和报文来源中的存储节点id计算发送节点的集群id;
3.将计算出的存储集群id与当前报文来源的存储集群id进行比较;若相同,则鉴别通过,进行转发,反之,则丢弃该报文。
存储集群间鉴别由存储集群的门户网关完成,在鉴别过程中,门户网关一是向由本存储集群发往其他存储集群的报文中添加签名信息,用以表示该报文在集群内己经过鉴别;二是检查所收到的来自于其他存储集群的报文是否具有签名信息,并对签名信息进行鉴别。
本发明在存储集群网络中为所有存储集群建立一台管理节点,通过该服务器实现对存储集群网络中门户网关的管理。具体描述如下。
1.门户网关进行注册,然后为注册成功的门户网关对应分配一个随机数,为下一步做准备。产生门户网关的密钥,即为各门户网关安全生成并分发私钥,而门户网关公钥是由门户网关根据其所在存储集群子网标识和系统共享参数生成的。通过管理节点的主私钥和门户网关在上一步得到的随机数,保证只有拥有合法身份的门户网关才能获得对应的私钥,同时保证门户网关获得的私钥是由管理节点产生。
其中,门户网关进行注册过程进一步包括:
(1)管理节点运行初始设置算法。输入一个安全参数,输出一系列系统共享参数(包括明文空间、密文空间、哈希函数)、主公钥kmp和主私钥kms。主私钥用来生成门户网关私钥。
(2)门户网关向管理节点发送注册信息。每台门户网关在准备连接到该存储集群网络时,都需要先以其所在存储集群的子网标识作为身份向管理节点进行注册。
(3)管理节点响应门户网关注册请求。管理节点收到主机注册请求后,记录下该主机的子网标识,并为其生成一个随机数rdm。同时,将每个门户网关的子网标识和分配给该主机的随机数对应起来,以列表的形式保存,称该列表为lmac。然后,管理节点将随机数rdm、主公钥kmp及系统共享参数发送给门户网关。
进一步,门户网关生成并分发私钥的具体过程为:
(1)门户网关根据注册过程中收到的主公钥和系统共享参数,结合其子网标识,根据基于身份的数字签名方案计算出门户网关公钥kp。
(2)门户网关用主公钥kmp对随机数rdm进行加密,生成加密信息,防止随机数在发送过程中被篡改。然后,门户网关把子网标识及该加密信息发送给管理节点,申请门户网关私钥。
(3)管理节点收到门户网关请求后,首先根据信息中的子网标识查找其保存的列表lmac。如果在列表中能找到对应表项,则说明该门户网关注册过,进行下一步鉴别;否则,丢弃该请求信息。找到对应的表项后,对收到信息的剩余部分进行解密,将解密得到的信息与对应表项中的随机数比较。如果匹配成功,则说明请求是由注册过的合法接入网关发出的,鉴别成功;否则丢弃该请求信息。
(4)鉴别成功后,管理节点根据该门户网关子网标识和主私钥kms生成门户网关私钥ks。管理节点将该门户网关私钥与对应表项的随机数rdm进行异或运算,然后,使用主私钥kms对子网标识及异或值进行私钥运算,将运算结果作为响应信息发送给主机。
(5)门户网关收到响应信息后,使用之前收到的主公钥kmp对该响应信息进行鉴别。如果其中的子网标识与门户网关的子网标识一致,则判定该信息是来自管理节点,将信息的剩余部分与其保存的随机数进行异或操作,得到私钥并将其安全保存;否则,丢弃该响应信息,门户网关重新发送私钥申请。
2.门户网关每隔预定的时间将向存储集群网络中的其他门户网关分别发送一个签名报文,估算出与其他门户网关通信所需要的时间,即报文从门户网关发送到其他门户网关所花费的时间,将该时间记为t,由门户网关保存。签名报文生成过程如下。假设f为伪随机函数,门户网关使用其密钥发生器来生成两个会话密钥k0、k1并计算f(k0)、f(k1)然后使用门户网关私钥对子网标识sp和f(k0)进行签名,得到签名报文s,使用k0和集合d1计算一个消息认证码mack0d1,其中d1为{sp,k0,f(k1)}。将f(k0)和mack0d1作为数据,生成一个报文,并将签名s添加到报文的扩展首部,将该签名报文发送给其他门户网关。
门户网关收到来自其他门户网关的签名信息后,根据主公钥系统共享参数及源门户网关的子网标识来计算出一个公钥kp’。用公钥对报文扩展首部中的签名进行鉴别,将得到的子网标识、f(k0)与报文中的子网标识、报文中的数据f(k0)分别进行比较。如果都一致,则鉴别通过,记录下报文的数据f(k0)、mack0d1及子网标识地址,保存在以子网标识为索引的列表lip。
3.门户网关在发送完签名报文后,首先记录下发送完成的时刻t1。然后生成下一个密钥k2,计算出f(k2)、mack1d2,其中d2={sp,k1,f(k2)},当门户网关需要向其他门户网关转发报文时,需要在其所转发的报文的扩展首部中添加{k0,f(k1),mack1d2}。当门户网关准备转发报文时,首先计算此时时刻t2与t1的差值δt。如果δt>t,则确定之前发送的签名报文已经到达目的门户网关,将这些报文全部转发出去;否则直到δt>t再发送报文。
门户网关收到来自其他门户网关转发的一组报文后,对其中的每个报文分别进行鉴别:根据报文中的来源的子网标识在表lip中找到对应的f(k0)和mack0d1;再使用报文扩展首部中的k0来计算f(k0),将此计算结果与表lip中的进行比较,如果比较结果一致,则说明传递过来的f(k0)是合法的;然后,用f(k0)来鉴别表lip中的mack0d1,如果此鉴别通过,则将报文扩展首部去除后向存储集群内转发。
对于该组中第1个鉴别成功的报文,在执行完上述鉴别后,还要在表lip对应表项中添加上f(k1)和mack1d2。对于该组中最后一个被鉴别的报文,还要将表lip对应表项中的f(k0)和mack0d1删除。对此后收到的该门户网关的报文,需要执行此鉴别过程。
数据分发到存储节点的过程,以及数据从有效节点发送给待恢复存储节点的过程可以看作为一个广播过程。本发明将将待恢复存储节点分为可信服务器和非可信服务器,可信服务器可以参与数据恢复,而非可信服务器无法参与数据恢复,同时将用户也看作为参与到广播加密中的向可信服务器发送数据的存储节点,即对数据接收节点进行选择,只有被选中的节点才能够对数据进行解码,确保数据的安全性。
用户的数据在存储前将进行编码,编码后的数据分为两类,一类为存储数据块,另一类为加密信息数据,其中包含有数据编码恢复的关键信息,其由可信数据恢复服务器存储,当存储节点存在失效存储节点时,系统依据传输路径最优原则从可信数据恢复服务器中选择若干服务器进行数据恢复,对于非可信数据服务器而言,由于其没有加密信息数据,所以无法对数据进行编码恢复。
在用户将数据提交存储节点时,存储节点将数据构造为d×d消息阵列m,利用n×d编码阵列ψ对m进行编码,编码阵列ψ表示为ψ=[φ,δ],其中φ,δ分别为n×k和n×(d-k)阵列,且满足ψ中的任意d行是线性无关的,φ中的任意k行是线性无关的。
通过编码可以获取n个数据片段,并分别存储于n个存储节点,每个服务器存储m/k的数据量,任意k个存储节点即可以重构原始数据m。
当有r个存储节点失效后,为了保证数据的可靠性,存储节点选取大于等于r个可信数据恢复服务器,通过仍然有效的n-r存储节点来为每个可信数据恢复服务器获取大于等于d个数据块用以恢复数据。数据恢复过程可以描述如下:
1.每个可信数据恢复服务器连接d台存储节点进行修复,d台存储节点是最初由存储节点分配的存储节点,或已经完成数据恢复的可信数据恢复服务器;
2.每台可信数据恢复服务器利用其收到的d个数据块来产生一个与已失效服务器存储数据相同的大小为m/k的数据块。
3.数据恢复完成后,从n个存储节点中任意选取d个来重构原始数据文件。
综上所述,本发明提出了一种云存储节点负载均衡方法,通过智能负载均衡策略实现了系统访问性能的全局最优化,并基于安全架构防止非法用户实现对分布式存储节点之间的非法存取和攻击。
显然,本领域的技术人员应该理解,上述的本发明的各模块或各步骤可以用通用的计算系统来实现,它们可以集中在单个的计算系统上,或者分布在多个计算系统所组成的网络上,可选地,它们可以用计算系统可执行的程序代码来实现,从而,可以将它们存储在存储节点中由计算系统来执行。这样,本发明不限制于任何特定的硬件和软件结合。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!