通过多个交替数据路径进行分组喷射的无阻塞的任意到任意数据中心网络的制作方法
本申请要求2017年6月2日提交的美国临时申请号62/514,583和2017年3月29日提交的美国临时申请号62/478,414的权益,这两者的全部内容通过引用结合于此。本发明涉及计算机网络,更具体地,涉及数据中心网络。
背景技术:
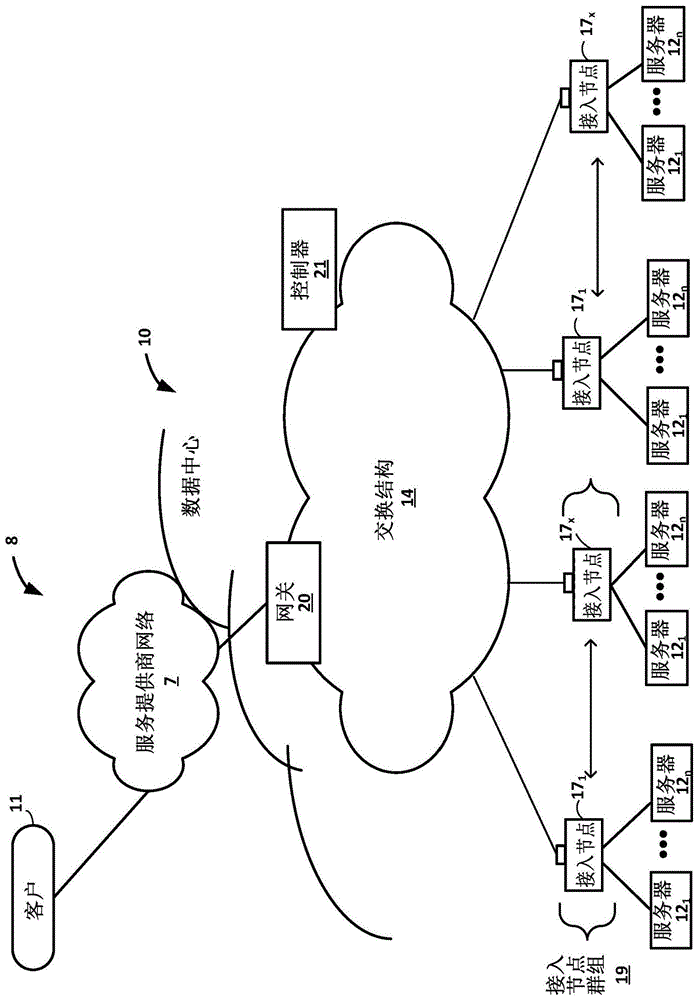
:在典型的基于云的数据中心中,大量互连的服务器为各种应用的执行提供计算和/或存储容量。例如,数据中心可以包括为订户(即数据中心的客户)托管应用和服务的设施。例如,数据中心可以托管所有基础设施设备,例如,计算节点、网络和存储系统、电力系统和环境控制系统。在大多数数据中心,存储系统和应用服务器的集群经由一层或多层物理网络交换机和路由器提供的高速交换结构互连。数据中心的规模差异很大,一些公共数据中心包含数十万个服务器,并且通常分布在多个地理区域以实现冗余。典型的数据中心交换结构包括多层互连的交换机和路由器。在当前实现中,在源服务器与目的地服务器或存储系统之间的给定分组流的分组总是通过包括交换结构的路由器和交换机沿着单个路径从源转发到目的地。技术实现要素:本公开描述了新颖的数据中心网络系统。在网络系统中描述的各种实现可以使用存在于数据中心的两个服务器之间的交换结构中的多个路径中的任一个来承载两个服务器之间的单个流的分组。描述了用于数据中心的网络系统的实例实现,其中,交换结构提供全网状互连,使得任何服务器可以使用数据中心交换结构内的许多并行数据路径中的任一个将给定分组流的分组数据传送到任何其他服务器。例如,描述了网络架构和技术,在实例实现中,这些网络架构和技术有助于在数据中心交换结构中在多个并行数据路径中的一些或所有并行数据路径上喷射给定分组流的各个分组,并对分组进行重新排序以传送到目的地。在实例实现中,这些技术可以在数据中心的服务器之间提供全网状互连,并且仍然可以是无阻塞和无丢包的(drop-free),并且与现有方法相比,提供显著更好(例如,3x或更多)的交换结构利用率。在各种实例中,描述了专用接入节点的实现,其中,接入节点作为服务器和交换结构之间的互连前端来操作。如本文进一步描述的,在一个实例中,每个接入节点是高度可编程的i/o处理器,其专门设计用于从服务器卸载某些功能。在一个实例中,接入节点包括一个或多个处理核,该处理核包括配备有硬件引擎的多个内部处理器集群,该硬件引擎卸载加密/安全功能、压缩和正则表达式处理、数据存储功能、加速和联网操作。以这种方式,接入节点可以包括用于代表一个或多个服务器完全实现和处理网络和存储栈的组件。此外,每个接入节点可以被编程地配置为充当其相应服务器的安全网关,释放服务器的处理器,以将资源专用于应用工作负载。描述了各种数据中心网络架构和配置。在某些实例中,根据本文描述的技术,交换结构的耦接到服务器的接入节点、中间光置换装置和核心交换机可以被配置和设置为使得交换结构中的并行数据路径在接入节点的任何成对组合之间提供全网状(任意到任意)互连,即使在具有数万十个服务器的大规模数据中心中也是如此。光置换装置通过光链路将接入节点光耦接到核心交换机,以在接入节点和核心交换机之间将数据包作为光信号传送。每个光置换装置包括一组输入光端口和一组输出光端口,以在接入节点和核心交换机之间引导光信号,从而传送数据包。每一个光置换装置被配置为使得从输入光端口接收的光通信基于波长在输出光端口上被置换,以便在没有光干扰的情况下提供在面向边缘的端口和面向核心的端口之间的全网状光连接。在其他实例中,光置换装置可以由电子开关或路由器代替。在其他实现中,光置换装置可以与电子交换机和路由器结合使用,以互连甚至更多数量的服务器。在一些实例实现中,本公开涉及一种光置换器,其作为光学互连来操作,用于在网络装置(例如,数据中心内的装置)之间传输光通信。如本文所述,光置换器提供接收相应光输入信号的多个输入端口,每个端口潜在地承载多个不同波长的光通信。光置换器的内部光学元件被配置为使得从输入端口接收的光通信基于波长在输出光端口上“置换”,从而在端口之间并且以保证不会由于波长冲突而产生光干扰的方式提供全网状连接。即,光置换器被配置为确保从任一个光输入端口接收的光通信可以引导到任一个光输出端口,而不会对任何其他输入端口上的任何同时通信产生光干扰。此外,光置换器可以是双向的。以这种方式,光置换器可以提供双向、全网状点对点连接,用于传输光通信。在一个实例中,一种网络系统包括:多个服务器;交换结构,其包括多个核心交换机;以及多个接入节点,每个接入节点耦接到服务器的子集并耦接到核心交换机的子集。当在源服务器和目的地服务器之间传送分组的分组流时,耦接到源服务器的第一接入节点被配置为在多个并行数据路径上将分组流的分组喷射到耦接到目的地服务器的第二接入节点。第二接入节点被配置为将分组重新排序成分组流的原始序列,并将重新排序的分组传送到目的地服务器。在另一实例中,一种方法包括:通过中间网络互连数据中心的多个服务器,中间网络包括交换结构,交换结构包括多个核心交换机、多个接入节点,每个接入节点耦接到服务器的子集以与服务器传送数据包,并且还耦接到核心交换机的子集。该方法还包括在源服务器和目的地服务器之间传送分组的分组流,包括:利用耦接到源服务器的第一接入节点,在第一接入节点和耦接到目的地服务器的第二接入节点之间的多个并行数据路径上喷射分组流的分组,并且利用第二接入节点将分组重新排序为分组流的原始序列,并将重新排序的分组传送到目的地服务器。在附图和以下描述中阐述一个或多个实例的细节。从说明书和附图以及权利要求书中,本发明的其他特征、目的和优点将变得显而易见。附图说明图1是示出具有数据中心的实例网络的框图,在该数据中心中可以实现本文描述的技术的实例。图2是进一步详细示出由接入节点和数据中心内的交换结构提供的逻辑互连的框图。图3是示出包括接入节点群组及其支持服务器的网络存储计算单元(nscu)40的一个实例的框图。图4是示出包括来自图3的两个nscu的实例逻辑机架设置的框图。图5是示出逻辑机架内的两个接入节点群组之间的全网状连接的实例的框图。图6是示出包括来自图4的两个逻辑机架的完全物理机架的实例设置的框图。图7a是示出接入节点内的网络数据路径和操作的逻辑视图的框图。图7b是示出在逻辑机架内的一组接入节点之间实现的实例一级网络扇出的框图。图8是示出接入节点之间的数据中心交换结构上的实例多级网络扇出的框图。图9是更详细地示出图1的网络的一个实例的框图。图10是示出网络的更详细的实例实现的框图,其中,利用一组接入节点和光置换器来互连全网状网络中的端点,其中,每个接入节点逻辑连接到m群核心交换机中的每一群。图11是示出实例网络集群架构的概念图,其中,八个物理机架经由四个光转换器和四个交换机群组互连。图12是示出来自图11的实例网络集群架构的框图。图13是示出另一实例网络集群架构的框图,其中,八个物理机架经由八个光置换装置和八个交换机群组互连。图14是示出两个网络集群之间的实例互连的框图。图15是示出实例光置换器的框图,该光置换器可以是本文描述的任何光置换器,例如,图9、图11和图12中所示的。图16是进一步详细示出图15的光学多路复用器切片的实例的框图。图17是示出实例光置换器的框图,该光置换器可以是本文描述的任何光置换器,例如,图9、图11和图12中所示的。图18是图17的光置换器的另一实例实现的框图。图19是示出具有多个逻辑置换平面的光置换器的框图。图20是示出根据本文描述的技术的网络系统的实例操作的流程图。具体实施方式图1是示出具有数据中心10的实例网络8的框图,在数据中心10中可以实现本文描述的技术的实例。通常,数据中心10为通过内容/服务提供商网络7和网关装置20耦接到数据中心的客户11的应用和服务提供操作环境。在其他实例中,内容/服务提供商网络7可以是数据中心广域网(dcwan)、专用网络或其他类型的网络。例如,数据中心10可以托管基础设施设备,例如,计算节点、网络和存储系统、冗余电源和环境控制。内容/服务提供商网络7可以耦接到由其他提供商管理的一个或多个网络,并且因此可以形成大规模公共网络基础设施(例如,互联网)的一部分。在一些实例中,数据中心10可以表示许多地理上分布的网络数据中心中的一个。在图1的实例中,数据中心10是为客户11提供信息服务的设施。客户11可以是集体实体(例如,企业和政府)或个人。例如,网络数据中心可以为几个企业和最终用户托管网络服务。其他实例服务可以包括数据存储、虚拟专用网络、文件存储服务、数据挖掘服务、科学或超级计算服务等。在该实例中,数据中心10包括经由高速交换结构14互连的一组存储系统和应用服务器12。在一些实例中,服务器12被设置为多个不同的服务器群,每个服务器群包括任意数量的服务器,例如,多达n个服务器121-12n。服务器12为与客户11相关联的应用和数据提供计算和存储设施,并且可以是物理(裸金属)服务器、在物理服务器上运行的虚拟机、在物理服务器上运行的虚拟化容器或其组合。在图1的实例中,软件定义网络(sdn)控制器21提供了用于配置和管理数据中心10的路由和交换基础设施的高级控制器。根据本公开的一个或多个实施方式,sdn控制器21提供逻辑上并且在某些情况下物理上集中的控制器,用于促进数据中心10内的一个或多个虚拟网络的操作。在一些实例中,sdn控制器21可以响应于从网络管理员接收的配置输入而操作。在一些实例中,根据本文描述的技术,sdn控制器21操作以配置接入节点17,以在逻辑上建立一个或多个虚拟结构,作为在由交换结构14提供的物理底层网络之上动态配置的覆盖网络。例如,sdn控制器21可以学习和维护接入节点21的知识,并与每个接入节点建立通信控制信道。sdn控制器21使用其对接入节点17的知识来定义两个以上接入节点17的多组(群),以在交换结构14上建立不同的虚拟结构。更具体地,sdn控制器21可以使用通信控制信道来通知给定组中的每个接入节点17哪些其他接入节点包括在同一组中。作为响应,接入节点17通过分组交换网络410与包括在同一组中的其他接入节点动态建立fcp隧道,作为虚拟结构。以这种方式,sdn控制器21为每个虚拟结构定义接入节点群组17,并且接入节点负责建立虚拟结构。这样,交换结构14的底层组件可以不知道虚拟结构。在这些实例中,接入节点17与交换结构14接口连接并利用交换结构14,以便在任何给定虚拟结构的接入节点之间提供全网状(任意到任意)互连。以这种方式,连接到形成给定一个虚拟结构的任何接入节点的服务器可以使用交换结构14内互连该虚拟结构的接入节点的多个并行数据路径中的任一个,将给定分组流的分组数据传送到耦接到该虚拟结构的接入节点的任何其他服务器。在于2018年3月5日提交的题为“networkaccessnodevirtualfabricsconfigureddynamicallyoveranunderlaynetwork”的美国临时专利申请号62/638,788中,提供了操作以在虚拟覆盖网络内和虚拟覆盖网络上喷射分组的接入节点的更多细节,其全部内容通过引用结合于此。虽然未示出,但是数据中心10还可以包括例如一个或多个非边缘交换机、路由器、集线器、网关、安全装置(例如,防火墙、入侵检测和/或入侵防御装置)、服务器、计算机终端、膝上型计算机、打印机、数据库、无线移动装置(例如,蜂窝电话或个人数字助理)、无线接入点、网桥、电缆调制解调器、应用加速器或其他网络装置。在图1的实例中,服务器12中的每一个通过接入节点17耦接到交换结构14。如本文进一步描述的,在一个实例中,每个接入节点17是高度可编程的i/o处理器,其专门设计用于从服务器12卸载某些功能。在一个实例中,每个接入节点17包括由多个内部处理器集群组成的一个或多个处理核,例如,mips核,该处理核配备有卸载加密功能、压缩和正则表达式(regex)处理、数据存储功能和网络操作的硬件引擎。以这种方式,每个接入节点17包括用于代表一个或多个服务器12完全实现和处理网络和存储栈的组件。此外,接入节点18可以被编程地配置为充当其相应服务器12的安全网关,释放服务器的处理器,以将资源专用于应用工作负载。在一些实例实现中,每个接入节点17可以被视为网络接口子系统,该子系统实现对所附接的服务器系统的数据包处理(服务器存储器中零拷贝)和存储加速的完全卸载。在一个实例中,每个接入节点17可以被实现为一个或多个专用集成电路(asic)或其他硬件和软件组件,每个组件支持服务器的子集。接入节点17也可以称为数据处理单元(dpu)或者包括dpu的装置。换言之,术语接入节点在本文可以与术语dpu互换使用。在2017年9月15日提交的题为“accessnodefordatacenters”的美国临时专利申请号62/559,021和2017年7月10日提交的题为“dataprocessingunitforcomputingdevices”的美国临时专利申请号62530691中描述了各种实例接入节点的额外实例细节,这两个申请的全部内容通过引用结合于此。在实例实现中,接入节点17可以被配置为在具有一个或多个接入节点的独立网络设备中操作。例如,接入节点17可以被设置到多个不同的接入节点群组19中,每个接入节点群组包括任意数量的接入节点,例如,多达x个接入节点171-17x。这样,多个接入节点17可以被分组(例如,在单个电子装置或网络设备内),本文称为接入节点群组19,用于向由装置内部的一组接入节点支持的一组服务器提供服务。在一个实例中,接入节点群组19可以包括四个接入节点17,每个接入节点支持四个服务器,以便支持一组十六个服务器。在图1的实例中,每个接入节点17为不同组的服务器12提供到交换结构14的连接,并且可以被分配相应的ip地址,并且为与其耦接的服务器12提供路由操作。如本文所述,接入节点17为来自/去向各个服务器12的通信提供路由和/或交换功能。例如,如图1所示,每个接入节点17包括用于与相应的一组服务器12通信的一组面向边缘的电或光的本地总线接口以及用于与交换结构14内的核心交换机通信的一个或多个面向核心的电或光接口。此外,本文描述的接入节点17可以提供额外服务,例如,存储(例如,固态存储装置的集成)、安全性(例如,加密)、加速(例如,压缩)、i/o卸载等。在一些实例中,一个或多个接入节点17可以包括存储装置,例如,高速固态驱动器或旋转硬盘驱动器,其被配置为提供网络可接入存储,以供在服务器上执行的应用使用。虽然图1中未示出,但是接入节点17可以直接彼此耦接,例如,公共接入节点群组19中的接入节点之间的直接耦接,以提供同一群组中的接入节点之间的直接互连。例如,多个接入节点17(例如,4个接入节点)可以位于公共接入节点群组19内,以用于服务一组服务器(例如,16个服务器)。作为一个实例,多个接入节点17的每个接入节点群组19可以被配置为独立的网络装置,并且可以被实现为占用装置机架的两个机架单元(例如,插槽)的两个机架单元(2ru)装置。在另一实例中,接入节点17可以集成在服务器中,例如,单个1ru服务器,其中,四个cpu耦接到部署在公共计算装置内的母板上的本文描述的转发asic。在又一实例中,接入节点17和服务器12中的一个或多个可以集成在合适大小(例如,10ru)的帧中,在该实例中,该帧可以成为数据中心10的网络存储计算单元(nscu)。例如,接入节点17可以集成在服务器12的母板内,或者以其他方式与服务器共同位于单个机箱中。根据本文的技术描述了实例实现,其中,接入节点17与交换结构14接口连接并利用交换结构14,以便提供全网状(任意到任意)互连,使得任何服务器12可以使用数据中心10内的任何多个并行数据路径将给定分组流的分组数据传送到任何其他服务器。例如,描述了示例网络架构和技术,其中,在实例实现中,接入节点在接入节点之间并且跨数据中心交换结构14中的多个并行数据路径中的一些或所有路径喷射分组流的各个分组,并且重新排序分组以传送到目的地,从而提供全网状连接。以这种方式,根据本文的技术,描述了实例实现,其中,接入节点17与交换结构14接口连接并利用交换结构14以便提供全网状(任意到任意)互连,使得任何服务器12可以使用数据中心10内的任何多个并行数据路径将给定分组流的分组数据传送到任何其他服务器。例如,描述了示例网络体系结构和技术,其中,在实例实现中,接入节点在接入节点之间并且跨数据中心交换结构14中的多个并行数据路径中的一些或所有路径喷射分组流的各个分组,并且重新排序分组以传送到目的地,从而提供全网状连接。如本文所述,本公开的技术引入了称为结构控制协议(fcp)的新数据传输协议,该协议可由任何接入节点17的不同操作网络组件使用,以促进在交换结构14上传送数据。如进一步描述的,fcp是端到端准入控制协议,其中,在一个实例中,发送方明确向接收方请求传输特定字节数量的有效载荷数据的意图。作为响应,接收方基于其缓冲资源、qos和/或结构拥塞的度量来发布授权。通常,fcp使能够将流的分组喷射到源节点和目的地节点之间的所有路径,并且可以提供本文描述的任何优点和技术,包括抗请求/授权分组丢失的弹性、自适应和低延迟结构实现、故障恢复、降低或最小的协议开销成本、支持未经请求的分组传输、支持有/无fcp能力节点共存、流感知公平带宽分配、通过自适应请求窗口缩放来传输缓冲器管理、接收基于缓冲器占用的授权管理、改进的端到端qos、通过加密和端到端认证的安全性和/或改进的ecn标记支持。可在题为“fabriccontrolprotocolfordatacenternetworkswithpacketsprayingovermultiplealternatedatapaths”的2017年9月29日提交的美国临时专利申请号62/566,060中获得关于fcp的更多细节,其全部内容通过引用结合于此。这些技术可以提供某些优势。例如,这些技术可以显著提高底层交换结构14的带宽利用率。此外,在实例实现中,这些技术可以在数据中心的服务器之间提供全网状互连,并且仍然可以是无阻塞的和无丢包的。尽管在图1中针对数据中心10的交换结构14描述了接入节点17,但是在其他实例中,接入节点可以通过任何分组交换网络提供全网状互连。例如,分组交换网络可以包括局域网(lan)、广域网(wan)或一个或多个网络的集合。只要在接入节点之间存在完全连接,分组交换网络可以具有任何拓扑,例如,平面或多层。分组交换网络可以使用任何技术,包括提供以太网的ip以及其他技术。不管分组交换网络的类型如何,根据本公开中描述的技术,接入节点可以针对接入节点之间并且在分组交换网络中的多个并行数据路径上喷射分组流的各个分组,并且将分组重新排序以传送到目的地,从而提供全网状连接。图2是进一步详细示出由接入节点17和数据中心内的交换结构14提供的逻辑互连的框图。如该实例中所示,接入节点17和交换结构14可以被配置为提供全网状互连,使得接入节点17可以使用到核心交换机22a-22m(统称为“核心交换机22”)中的任一个的m个并行数据路径中的任一个路径将任何服务器12的分组数据传送到任何其他服务器12。此外,根据本文描述的技术,接入节点17和交换结构14可以被配置和设置为使得交换结构14中的m个并行数据路径在服务器12之间提供减少的l2/l3跳和全网状互连(例如,二分图),即使在具有数万个服务器的大规模数据中心中也是如此。注意,在该实例中,交换机22彼此不连接,这使得一个或多个交换机的任何故障更有可能彼此独立。在其他实例中,交换结构本身可以使用多层互连交换机来实现,如在clos网络中一样。因此,在一些实例实现中,每个接入节点17可以具有多个并行数据路径,用于到达任何给定的其他接入节点17和通过这些接入节点可到达的服务器12。在一些实例中,交换结构14可以被配置为使得对于服务器12之间的任何给定分组流,接入节点17可以在交换结构14的m个并行数据路径的全部或子集上喷射分组流的分组,通过这些路径可以到达目的地服务器12的给定目的地接入节点17,而不是局限于沿着交换结构中的单个路径发送给定流的所有分组。根据所公开的技术,接入节点17可以在m个路径上喷射各个分组流的分组,端到端地形成源接入节点和目的地接入节点之间的虚拟隧道。以这种方式,交换结构14中包括的层数或沿着m个并行数据路径的跳数对于本公开中描述的分组喷射技术的实现可能无关紧要。然而,在交换结构14的m个并行数据路径的全部或子集上喷射各个分组流的分组的技术使得交换结构14内的网络装置的层数能够减少,例如,减少到最少一层。此外,它使能实现交换机不彼此连接的结构架构,降低了两个交换机之间故障依赖性的可能性,从而提高了交换结构的可靠性。平整交换结构14可以通过消除需要电力的网络装置层来降低成本,并且通过消除执行分组交换的网络装置层来降低延迟。在一个实例中,交换结构14的平整拓扑可以导致核心层仅包括一级主干交换机,例如,核心交换机22,这些交换机可以不直接相互通信,而是沿着m个并行数据路径形成单跳。在该实例中,将业务注入到交换结构14的任何接入节点17可以通过经由一个核心交换机22的单跳l3查找来到达任何其他接入节点17。为源服务器12注入分组流的接入节点17可以使用任何用于在可用并行数据路径上喷射分组的技术,例如,可用带宽、随机、循环、基于散列或其他机制,该机制可以被设计为最大化例如带宽的利用或以其他方式避免拥塞。在一些实例实现中,不一定需要利用基于流的负载平衡,并且可以通过允许由服务器12提供的给定分组流(五元组)的分组穿过在耦接到源和目的地服务器的接入节点17之间的交换结构14的不同路径来使用更有效的带宽利用率。与目的地服务器12相关联的相应目的地接入节点17可以被配置为对分组流的可变长度的ip分组重新排序,并且以发送的顺序将分组传送到目的地服务器。在一些实例实现中,每个接入节点17实现四个不同的操作网络组件或功能:(1)源组件,可操作以从服务器12接收业务,(2)源交换组件,可操作以将源业务切换到不同接入节点17(可能是不同接入节点群组)的其他源交换组件或到核心交换机22,(3)目的地交换组件,可操作以切换从其他源交换组件或核心交换机22接收的入站业务,以及(4)目的地组件,可操作以对分组流重新排序并将分组流提供给目的地服务器12。在该实例中,服务器12连接到接入节点17的源组件,以将业务注入交换结构14,并且服务器12类似地耦接到接入节点17内的目的地组件,以从其接收业务。由于交换结构14提供的全网状并行数据路径,因此给定接入节点17内的每个源交换组件和目的地交换组件不需要执行l2/l3交换。相反,接入节点17可以应用喷射算法来喷射分组流的分组,例如,可用带宽、随机地、循环地、基于qos/调度,或者以其他方式高效地转发分组,而在一些实例中,不需要分组分析和查找操作。接入节点17的目的地交换组件可以提供有限的查找,该查找仅是选择用于将分组转发到本地服务器12的适当输出端口所必需的。这样,关于数据中心的完整路由表,可能只有核心交换机22需要执行完整查找操作。因此,交换结构14提供了高度可扩展、平坦、高速的互连,其中,在一些实施方式中,服务器12实际上是来自数据中心内的任何其他服务器12的一个l2/l3跳。接入节点17可能需要连接到相当数量的核心交换机22,以便将分组数据传送到任何其他接入节点17和通过这些接入节点可接入的服务器12。在一些情况下,为了提供链路乘数效应,接入节点17可以经由架顶(tor)以太网交换机、电置换装置或光置换(op)装置(图2中未示出)连接到核心交换机22。为了提供额外的链路乘数效应,接入节点17的源组件可以被配置为在包括于一个或多个接入节点群组19中的一组其他接入节点17上喷射从服务器12接收的业务的各个分组流的分组。在一个实例中,接入节点17可以实现来自接入节点间喷射的8倍乘数效应以及来自op装置的额外8x乘数效应,以连接到多达64个核心交换机22。通过网络在等成本多路径(ecmp)路径上的基于流的路由和切换可能容易受到高度可变的负载相关延迟的影响。例如,网络可能包括许多小带宽流和一些大带宽流。在通过ecmp路径进行路由和交换的情况下,源接入节点可以为两个大带宽流选择相同的路径,从而导致该路径上的大延迟。例如,为了避免该问题并保持网络的低延迟,管理员可能会被迫将网络利用率保持在25-30%以下。在本公开中描述的将接入节点17配置为在所有可用路径上喷射各个分组流的分组的技术使能够实现更高的网络利用率,例如,85-90%,同时保持有界或有限的延迟。分组喷射技术使得源接入节点17能够在考虑链路故障的同时,在所有可用路径上公平地分配给定流的分组。以这种方式,不管给定流的带宽大小如何,负载都可以通过网络公平地分布在可用路径上,以避免特定路径的过度利用。所公开的技术使得相同数量的网络装置能够通过网络传输三倍的数据业务量,同时保持低延迟特性并减少消耗能量的网络装置的层数。如图2的实例所示,在一些实例实现中,接入节点17可以被设置为多个不同的接入节点群组191-19y(图2中的ang),每个接入节点群组包括任意数量的接入节点17,例如,多达x个接入节点171-17x。这样,多个接入节点17可以被分组和设置(例如,在单个电子装置或网络装置内),本文称为接入节点群组(ang)19,用于向装置内部的该组接入节点所支持的一组服务器提供服务。如上所述,每个接入节点群组19可以被配置为独立的网络装置,并且可以被实现为被配置为安装在计算机架、存储机架或融合机架中的装置。通常,每个接入节点群组19可以被配置为作为高性能i/o集线器来操作,该高性能i/o集线器被设计为聚合和处理多个服务器12的网络和/或存储i/o。如上所述,每个接入节点群组19内的一组接入节点17提供高度可编程的专用i/o处理电路,以用于代表服务器12处理联网和通信操作。此外,在一些实例中,每个接入节点群组19可以包括存储装置27,例如,高速固态硬盘驱动器,其被配置为提供网络可接入存储,以供在服务器上执行的应用使用。每个接入节点群组19(包括其一组接入节点17、存储装置27和由该接入节点群组的接入节点17支持的一组服务器12)在本文可以称为网络存储计算单元(nscu)40。图3是示出包括接入节点群组19及其支持服务器52的网络存储计算单元(nscu)40的一个实例的框图。接入节点群组19可以被配置为作为高性能i/o集线器来操作,该高性能i/o集线器被设计为聚合和处理到多个服务器52的网络和存储i/o。在图3的具体实例中,接入节点群组19包括连接到本地固态储存器41的池的四个接入节点171-174(统称为“接入节点17”)。在所示实例中,接入节点群组19支持总共十六个服务器节点121-1216(统称为“服务器节点12”),接入节点群组19内的四个接入节点17中的每一个支持四个服务器节点12。在一些实例中,由每个接入节点17支持的四个服务器节点12中的每一个可以被设置为服务器52。在一些实例中,贯穿本申请描述的“服务器12”可以是双插槽或双处理器“服务器节点”,该节点在独立的服务器装置(例如,服务器52)内以两个或更多个为一组设置。尽管接入节点群组19在图3中示出为包括全部连接到固态储存器41的单个池的四个接入节点17,但是接入节点群组可以以其他方式设置。在一个实例中,四个接入节点17中的每一个可以包括在单独的接入节点滑动部件上,该滑动部件还包括固态储存器和/或用于接入节点的其他类型的储存器。在该实例中,接入节点群组可以包括四个接入节点滑动部件,每个滑动部件具有一个接入节点和一组本地存储装置。在一个实例实现中,接入节点群组19内的接入节点17使用外围组件互连快速(pcie)链路48、50连接到服务器52和固态储存器41,并且使用以太网链路42、44、46连接到其他接入节点和数据中心交换结构14。例如,每个接入节点17可以支持六个高速以太网连接,包括用于与交换结构通信的两个外部可用以太网连接42、用于与其他接入节点群组中的其他接入节点通信的一个外部可用以太网连接44、以及用于与同一接入节点群组19中的其他接入节点17通信的三个内部以太网连接46。在一个实例中,每个外部可用连接42可以是100千兆以太网连接。在这个实例中,接入节点群组19具有8x100ge外部可用端口,以连接到交换结构14。在接入节点群组19内,连接42可以是铜链路,即,电链路,该链路被设置为每个接入节点17和接入节点群组19的光端口之间的8x25ge链路。在接入节点群组19和交换结构之间,连接42可以是耦接到接入节点群组19的光端口的光以太网连接。光以太网连接可以连接到交换结构内的一个或多个光装置,例如,下面更详细描述的光置换装置。光以太网连接可能比电连接支持更多带宽,而不会增加交换结构中的电缆数量。例如,耦接到接入节点群组19的每个光缆可以承载4x100ge光纤,每个光纤承载四种不同波长或λ的光信号。在其他实例中,外部可用连接42可以保留作为到交换结构的电以太网连接。每个接入节点17支持的其余四个以太网连接包括用于与其他接入节点群组内的其他接入节点通信的一个以太网连接44以及用于与同一接入节点群组19内的其他三个接入节点通信的三个以太网连接46。在一些实例中,连接44可以称为“接入节点群组间链路”,连接46可以称为“接入节点群组内链路”。以太网连接44、46在给定结构单元内的接入节点之间提供全网状连接。在一个实例中,这种结构单元在本文可以称为逻辑机架(例如,半机架或半物理机架),其包括具有两个agn19的两个nscu40,并且支持用于这些agn的八个接入节点17的8向网格。在该具体实例中,连接46将在同一接入节点群组19内的四个接入节点17之间提供全网状连接,并且连接44将在每个接入节点17与逻辑机架的另一接入节点群组(即,结构单元)的四个其他接入节点之间提供全网状连接。此外,接入节点群组19可以具有足够的(例如,16个)外部可用以太网端口,以连接到其他接入节点群组中的4个接入节点。在接入节点的8向网格的情况下(即两个nscu40的逻辑机架),每个接入节点17可以通过50ge连接而连接到其他七个接入节点中的每一个。例如,同一接入节点群组19内的四个接入节点17之间的每个连接46可以是设置为2x25ge链路的50ge连接。四个接入节点17和另一接入节点群组中的四个接入节点之间的每个连接44可以包括四个50ge链路。在一些实例中,四个50ge链路中的每一个可以被设置为2x25ge链路,使得每个连接44包括到另一接入节点群组中的其他接入节点的8x25ge链路。下面将参考图5更详细地描述该实例。在另一实例中,以太网连接44、46在给定结构单元内的接入节点之间提供全网状连接,该给定结构单元是全机架或全物理机架,包括具有四个agn19的四个nscu40,并支持这些agn的接入节点17的16向网格。在这个实例中,连接46在同一接入节点群组19内的四个接入节点17之间提供全网状连接,并且连接44在每个接入节点17和三个其他接入节点群组内的十二个其他接入节点之间提供全网状连接。此外,接入节点群组19可以具有足够的(例如,48个)外部可用以太网端口,以连接到其他接入节点群组中的四个接入节点。在接入节点的16向网格的情况下,例如,每个接入节点17可以通过25ge连接而连接到其他15个接入节点中的每一个。换言之,在该实例中,同一接入节点群组19内的四个接入节点17之间的每个连接46可以是单个25ge链路。四个接入节点17和三个其他接入节点群组中的十二个其他接入节点之间的每个连接44可以包括12x25ge链路。如图3所示,接入节点群组19内的每个接入节点17还可以支持一组高速pcie连接48、50,例如,pciegen3.0或pciegen4.0连接,用于与接入节点群组19内的固态储存器41通信以及与nscu40内的服务器52通信。每个服务器52包括由接入节点群组19内的一个接入节点17支持的四个服务器节点12。固态储存器41可以是每个接入节点17可经由连接48接入的基于非易失性存储器快速(nvme)的固态驱动器(ssd)存储装置的池。在一个实例中,固态储存器41可以包括二十四个ssd装置,针对每个接入节点17具有六个ssd装置。二十四个ssd装置可以排列成四行,每行六个ssd装置,每行ssd装置连接到一个接入节点17。每个ssd装置最多可提供16兆兆字节(tb)的存储,每个接入节点群组19总共可提供384tb的存储。如下文更详细描述的,在一些情况下,物理机架可以包括四个接入节点群组19及其支持的服务器52。在这种情况下,典型的物理机架可能支持大约1.5千兆字节(pb)的本地固态存储。在另一实例中,固态储存器41可以包括多达32u.2x4ssd装置。在其他实例中,nscu40可以支持其他ssd装置,例如,2.5英寸串行ata(sata)ssd、微型sata(msata)ssd、m.2ssd等。在上面描述的实例中,其中,每个接入节点17包括在具有针对接入节点的本地储存器的单独的接入节点滑动部件上,每个接入节点滑动部件可以包括四个ssd装置和一些可以是硬盘驱动器或固态驱动器装置的额外储存器。在该实例中,四个ssd装置和额外储存器可以为每个接入节点提供与前一实例中描述的六个ssd装置大致相同的存储量。在一个实例中,每个接入节点17支持总共96个pcie通道。在该实例中,每个连接48可以是8x4通道pcigen3.0连接,经由该连接,每个接入节点17可以与固态储存器41内多达八个ssd装置通信。此外,给定接入节点17和由接入节点17支持的服务器52内的四个服务器节点12之间的每个连接50可以是4x16通道pciegen3.0连接。在这个实例中,接入节点群组19总共具有256个面向外部的pcie链路,这些链路与服务器52接口连接。在一些情况下,接入节点17可以支持冗余服务器连接,使得每个接入节点17使用8x8通道pciegen3.0连接而连接到两个不同服务器52内的八个服务器节点12。在另一实例中,每个接入节点17支持总共64个pcie通道。在该实例中,每个连接48可以是8x8通道pciegen3.0连接,经由该连接,每个接入节点17可以与固态储存器41内的多达八个ssd装置通信。此外,给定接入节点17和由接入节点17支持的服务器52内的四个服务器节点12之间的每个连接50可以是4x8通道pciegen4.0连接。在这个实例中,接入节点群组19总共具有128个面向外部的pcie链路,这些链路与服务器52接口连接。图4是示出包括来自图3的两个nscu401和402的实例逻辑机架设置60的框图。在一些实例中,基于接入节点群组19“夹在”顶部的两个服务器52和底部的两个服务器52之间的结构设置,每个nscu40可以称为“计算夹层”。例如,服务器52a可以称为顶部第二服务器,服务器52b可以称为顶部服务器,服务器52c可以称为底部服务器,服务器52d可以称为底部第二服务器。每个服务器52可以包括四个服务器节点,并且每个服务器节点可以是双插槽或双处理器服务器滑动部件。每个接入节点群组19使用pcie链路50连接到服务器52,并使用以太网链路42连接到交换结构14。接入节点群组191和192可以各自包括使用以太网链路彼此连接的四个接入节点以及使用pcie链路连接到接入节点的本地固态储存器,如以上参考图3所述。接入节点群组191和192内的接入节点在全网格64中彼此连接,这将参考图5进行更详细的描述。此外,每个接入节点群组19支持到服务器52的pcie连接50。在一个实例中,每个连接50可以是4x16通道pciegen3.0连接,使得接入节点群组19具有总共256个外部可用的pcie链路,这些链路与服务器52接口连接。在另一实例中,每个连接50可以是用于在接入节点群组19内的接入节点和服务器52内的服务器节点之间通信的4x8通道pciegen4.0连接。在任一实例中,连接50可以提供每个接入节点19的512千兆比特或者每个服务器节点大约128千兆比特的带宽的原始吞吐量,而不考虑任何开销带宽成本。如以上参考图3所讨论的,每个nscu40支持从接入节点群组19到交换结构14的8x100ge链路42。因此,每个nscu40支持四个服务器52中的多达十六个服务器节点、本地固态储存器和800gbps的全双工(即双向)网络带宽。因此,每个接入节点群组19可以提供服务器52的计算、存储、联网和安全性的真正超级融合。因此,包括两个nscu40的逻辑机架60为八个服务器52中的多达三十二个服务器节点、接入节点群组19处的本地固态储存器以及到交换结构14的16x100ge链路42提供支持,这导致全双工网络带宽为每秒1.6兆兆位(tbps)。图5是示出逻辑机架60内的两个接入节点群组191、192之间的全网状连接的实例的框图。如图5所示,接入节点群组191包括四个接入节点171-174,并且接入节点群组192也包括四个接入节点175-178。每个接入节点17以网状结构拓扑连接到逻辑机架内的其他接入节点。网状拓扑中包括的八个接入节点17可以称为接入节点“集群”。以这种方式,每个接入节点17能够将入站分组喷射到集群中的每个其他接入节点。在互连两个接入节点群组19的8向网格的图示配置中,每个接入节点17经由全网状连接而连接到集群中的其他七个接入节点中的每一个。接入节点17之间的网状拓扑包括同一接入节点群组19中包括的四个接入节点之间的接入节点群组内链路46以及接入节点群组191中的接入节点171-174与接入节点群组192中的接入节点175-178之间的接入节点群组间链路44。尽管图示为每个接入节点17之间的单个连接,但是连接44、46中的每一个是双向的,使得每个接入节点经由单独的链路连接到集群中的每个其他接入节点。第一接入节点群组191内的每个接入节点171-174具有到第一接入节点群组191中其他接入节点的三个接入节点群组内连接46。如第一接入节点群组191所示,接入节点171支持到接入节点174的连接46a、到接入节点173的连接46b以及到接入节点172的连接46c。接入节点172支持到接入节点171的连接46a、到接入节点174的连接46d、以及到接入节点173的连接46e。接入节点173支持到接入节点171的连接46b、到接入节点172的连接46e、以及到接入节点174的连接46f。接入节点174支持到接入节点171的连接46a、到接入节点172的连接46d、以及到接入节点173的连接46f。接入节点175-178类似地连接在第二接入节点群组192内。第一接入节点群组191中的每个接入节点171-174也具有到第二接入节点群组192中的接入节点175-178的四个接入节点群组间连接44。如图5所示,第一接入节点群组191和第二接入节点群组192各自具有16个外部可用端口66,以彼此连接。例如,接入节点171支持通过第一接入节点群组191的四个面向外部的端口66到第二接入节点群组192的四个外部可用端口66的连接44a、44b、44c和44d,以到达接入节点175-178。具体地,接入节点171支持到第二接入节点群组192内的接入节点175的连接44a、到第二接入节点群组192内的接入节点176的连接44b、到第二接入节点群组192内的接入节点177的连接44c、以及到第二接入节点群组192内的接入节点178的连接44d。第一接入节点群组191内的其余接入节点172-174类似地连接到第二接入节点群组192内的接入节点175-178。另外,在相反的方向上,接入节点175-178类似地连接到第一接入节点群组191内的接入节点171-174。每个接入节点17可以被配置为支持高达400千兆比特的带宽,以连接到集群中的其他接入节点。在所示实例中,每个接入节点17可以支持到其他接入节点的多达八个50ge以太网链路。在该实例中,由于每个接入节点17仅连接到七个其他接入节点,因此可能剩余50千兆比特的带宽并用于管理接入节点。在一些实例中,连接44、46中的每一个可以是单个50ge连接。在其他实例中,连接44、46中的每一个可以是2x25ge连接。在再其他的实例中,每个接入节点群组内连接46可以是2x25ge连接,并且每个接入节点群组间连接44可以是单个50ge连接,以减少盒间电缆的数量。例如,从第一接入节点群组191内的每个接入节点171-174,4x50ge链路断开盒,以连接到第二接入节点群组192中的接入节点175-178。在一些实例中,可以使用dac电缆从每一个接入节点17取出4x50ge链路。图6是示出包括来自图4的两个逻辑机架60的完全物理机架70的实例设置的框图。在图6所示的实例中,机架70在垂直高度上具有42个机架单元或插槽,该42个机架单元包括2个机架单元(2ru)的架顶(tor)装置72,该装置用于提供到交换结构14内的装置的连接。在一个实例中,tor装置72包括架顶以太网交换机。在其他实例中,tor装置72包括将在下面进一步详细描述的光置换器。在一些实例中,机架70可以不包括额外的tor装置72,而是具有典型的40个机架单元。在所示实例中,机架70包括四个接入节点群组191-194,每个接入节点群组在高度上都是独立的网络设备2ru。每个接入节点群组19包括四个接入节点,并且可以如图3的实例所示进行配置。例如,接入节点群组191包括接入节点an1-an4,接入节点群组192包括接入节点an5-an8,接入节点群组193包括接入节点an9-an12,接入节点群组194包括接入节点an13-an16。接入节点an1-an16可以基本上类似于上述接入节点17。在这个实例中,每个接入节点群组19支持16个服务器节点。例如,接入节点群组191支持服务器节点a1-a16,接入节点群组192支持服务器节点b1-b16,接入节点群组193支持服务器节点c1-c16,并且接入节点群组194支持服务器节点d1-d16。服务器节点可以是宽为1/2机架、高为1ru的双插槽或双处理器服务器滑动部件。如参考图3所述,四个服务器节点可以设置在高度为2ru的服务器52中。例如,服务器52a包括服务器节点a1-a4,服务器52b包括服务器节点a5-a8,服务器52c包括服务器节点a9-a12,并且服务器52d包括服务器节点a13-a16。服务器节点b1-b16、c1-c16和d1-d16可以类似地设置在服务器52中。从图3至图4中,接入节点群组19和服务器52设置在nscu40中。nscu40高度为10ru,并且每个nscu包括一个2ru接入节点群组19和四个2ru服务器52。如图6所示,接入节点群组19和服务器52可以被结构化为计算夹层,其中,每个接入节点群组19“夹在”顶部的两个服务器52和底部的两个服务器52之间。例如,相对于接入节点群组191,服务器52a可以称为顶部第二服务器,服务器52b可以称为顶部服务器,服务器52c可以称为底部服务器,并且服务器52d可以称为底部第二服务器。在所示的结构设置中,接入节点群组19由八个机架单元分开,以容纳由一个接入节点群组支持的底部两个2ru服务器52和由另一接入节点群组支持的顶部两个2ru服务器52。nscu40可以设置在来自图5的逻辑机架60(即,半物理机架)中。逻辑机架60的高度为20ru,并且每个机架包括具有全网状连接的两个nscu40。在图6所示的实例中,接入节点群组191和接入节点群组192与其相应支持的服务器节点a1-a16和b1-b16一起包括在同一逻辑机架60中。如以上参考图5更详细描述的,包括在同一逻辑机架60中的接入节点an1-an8以8向网格彼此连接。接入节点an9-an16可以类似地在另一逻辑机架60内以8向网格连接,该另一逻辑机架60包括接入节点群组193和194及其相应的服务器节点c1-c16和d1-d16。机架70内的逻辑机架60可以直接连接或通过中间架顶装置72连接到交换结构。如上所述,在一个实例中,tor装置72包括架顶以太网交换机。在其他实例中,tor装置72包括光置换器,该光置换器在接入节点17和核心交换机22之间传输光信号并且被配置为使得基于波长“置换”光通信,从而在没有任何光干扰的情况下在上游和下游端口之间提供全网状连接。在所示实例中,接入节点群组19中的每一个可以经由接入节点群组支持的8x100ge链路中的一个或多个连接到tor装置72,以到达交换结构。在一种情况下,机架70内的两个逻辑机架60可以各自连接到tor装置72的一个或多个端口,并且tor装置72也可以从相邻物理机架内的一个或多个逻辑机架接收信号。在其他实例中,机架70本身可以不包括tor装置72,而是逻辑机架60可以连接到包括在一个或多个相邻物理机架中的一个或多个tor装置。对于40ru的标准机架尺寸,可能希望保持在典型的功率限制内,例如,15千瓦(kw)的功率限制。在机架70的实例中,不考虑额外的2rutor装置72,即使有64个服务器节点和4个接入节点群组,也可以容易地保持在15kw功率限制内或附近。例如,每个接入节点群组19可以使用大约1kw的功率,导致接入节点群组大约4kw的功率。此外,每个服务器节点可以使用大约200w的功率,导致服务器52的功率大约为12.8kw。因此,在这个实例中,接入节点群组19和服务器52的40ru设置使用大约16.8kw的功率。图7a是示出接入节点17内的网络数据路径和操作的逻辑视图的框图。如图7a的实例所示,在一些实例实现中,每个接入节点17实现至少四个不同的操作网络组件或功能:(1)源(sf)组件30,可操作以从接入节点支持的一组服务器12接收业务,(2)源交换(sx)组件32,可操作以将源业务切换到不同接入节点17(可能是不同接入节点群组)的其他源交换组件或核心交换机22,(3)目的地交换(dx)组件34,可操作以切换从其他源交换组件或从核心交换机22接收的入站业务,以及(4)目的地(df)组件36,可操作以将分组流重新排序并将分组流提供给目的地服务器12。在一些实例中,接入节点17的不同操作网络组件可以对传输控制协议(tcp)分组流执行基于流的交换和基于ecmp的负载平衡。然而,通常ecmp负载平衡很差,因为它将流随机散列到路径,使得几个大的流可能被分配到相同的路径,并且使结构严重地不平衡。此外,ecmp依赖于本地路径决策,并且对于任何选择的路径不使用关于下游的可能拥塞或链路故障的任何反馈。本公开中描述的技术引入了称为结构控制协议(fcp)的新数据传输协议,该协议可以由接入节点17的不同操作网络组件使用。fcp是端到端准入控制协议,其中,发送方明确向接收方请求传输特定字节数量的有效载荷数据的意图。作为响应,接收方基于其缓冲资源、qos和/或结构拥塞的度量来发布授权。例如,fcp包括准入控制机制,通过该机制,源节点在将结构上的分组传输到目的地节点之前请求许可。例如,源节点向目的地节点发送请求传输一定数量的字节的请求消息,目的地节点在保留出口带宽之后向源节点发送授权消息。此外,fcp使单独的分组流的分组能够被喷射到源节点和目的地节点之间的所有可用链路,而不是用于在同一路径上发送tcp流的所有分组的基于流的交换和ecmp转发来避免分组重新排序。源节点为流的每个分组分配分组序列号,并且目的地节点使用分组序列号来排列同一流中的传入分组。接入节点17的sf组件30被认为是结构的源节点。根据所公开的技术,对于fcp业务,sf组件30被配置为通过到逻辑机架内接入节点的多个sx组件的链路喷射其输入带宽(例如,200gbps)。例如,如参考图7b更详细描述的,sf组件30可以在八个链路上将相同流的分组喷射到sx组件32和逻辑机架内其他接入节点的七个其他sx组件。对于非fcp业务,sf组件30被配置为选择将相同流的分组发送到的一个连接的sx组件。接入节点17的sx组件32可以从逻辑机架内的接入节点的多个sf组件接收传入分组,例如,逻辑机架内的sf组件30和其他接入节点的七个其他sf组件。对于fcp业务,sx组件32还被配置为在链路上将其传入带宽喷射到结构中的多个核心交换机。例如,如参考图8更详细描述的,sx组件32可以在八个链路上将其带宽喷射到八个核心交换机。在一些情况下,sx组件32可以在八个链路上将其带宽喷射到四个或八个中间装置,例如,tor以太网交换机、电置换装置或光置换装置,这些装置又将业务转发到核心交换机。对于非fcp业务,sx组件32被配置为选择将相同流的分组发送到的一个核心交换机。由于到sx组件32的传入带宽和来自sx组件32的输出带宽相同(例如,200gbps),即使对于大量分组流,也不应该在sx阶段发生拥塞。接入节点17的dx组件34可以直接或经由一个或多个中间装置,例如,tor以太网交换机、电置换装置或光置换装置,从多个核心交换机接收传入分组。例如,dx组件34可以从八个核心交换机或者四个或八个中间装置接收传入分组。dx组件34被配置为选择将接收到的分组发送到的df组件。例如,dx组件34可以连接到df组件36和逻辑机架内其他接入节点的七个其他df组件。在一些情况下,dx组件34可能成为拥塞点,因为dx组件34可能接收大量带宽(例如,200gbps),这些带宽都将发送到相同的df组件。在fcp业务的情况下,dx组件34可以使用fcp的准入控制机制来避免长期拥塞。接入节点17的df组件36可以接收来自逻辑机架内接入节点的多个dx组件(例如,dx组件34和逻辑机架内其他接入节点的七个其他dx组件)的传入分组。df组件36被认为是结构的目的地节点。对于fcp业务,df组件36被配置为在将流发送到目的地服务器12之前记录该相同流的分组。在一些实例中,接入节点17的sx组件32和dx组件34可以使用相同的转发表来执行分组交换。在这个实例中,接入节点17的个性和由转发表为同一目的地ip地址识别的下一跳可以取决于接收到的数据包的源端口类型。例如,如果从sf组件接收到源分组,则接入节点17作为sx组件32操作,并确定下一跳通过结构将源分组转发到目的地节点。如果从面向结构的端口接收到分组,则接入节点17作为dx组件34操作,并确定最后下一跳将传入分组直接转发到目的地节点。在一些实例中,接收到的分组可以包括指定其源端口类型的输入标签。图7b是示出在逻辑机架60内的一组接入节点171-178之间实现的实例一级网络扇出的框图。在图7b所示的实例中,逻辑机架60包括两个接入节点群组191和192,其包含八个接入节点171-178和由每一个接入节点支持的服务器节点12。如图7b所示,逻辑机架60内的接入节点17的sf组件30a-30h和sx组件32a-32h具有全网状连接,因为每个sf组件30连接到逻辑机架60内的八个接入节点17的所有sx组件32。如上所述,逻辑机架60内的八个接入节点17可以通过电以太网连接的8向网格彼此连接。在fcp业务的情况下,逻辑机架60内的接入节点17的sf组件30应用喷射算法来在所有可用链路上将任何给定分组流的分组喷射到sx组件32。以这种方式,sf组件30不必对源自服务器12的分组流的出站分组的l2/l3交换执行完全查找操作。换言之,给定分组流的分组可以由sf组件30(例如,sf组件30a)接收,并在一些或所有链路上喷射到逻辑机架60的sx组件32。以这种方式,逻辑机架的接入节点17实现了第一级扇出,在该示例中为1:8,并且在一些实例中可以这样做,而不会引起与分组报头中的密钥信息相关的任何l2/l3转发查找。这样,当由给定的sf组件30喷射时,单个分组流的分组不需要遵循相同的路径。因此,根据所公开的技术,当从一个服务器12接收到源业务时,例如,由接入节点171实现的sf组件30a执行在所有可用链路上的相同流的分组的8向喷射,喷射到由包括在逻辑机架60中的接入节点17实现的sx组件32。更具体地,sf组件30a在逻辑机架60内的同一接入节点171的一个内部sx组件32a和其他接入节点172-178的七个外部sx组件32b-32h上喷射。在一些实现中,逻辑机架60内的sf30和sx32之间的这种8向喷射可以称为第一阶段喷射。如本公开的其他部分所述,可以在接入节点17和核心交换机22之间的交换结构内的第二级网络扇出上执行第二阶段喷射。例如,第二阶段喷射可以通过中间装置来执行,例如,tor以太网交换机、电置换装置或光置换装置,这将在下面参考图9至图19更详细地描述。在一些实例中,如以上更详细描述的,前四个接入节点171-174可以包括在第一接入节点群组191中,后四个接入节点174-178可以包括在第二接入节点群组192中。第一和第二接入节点群组19内的接入节点17可以经由全网状网彼此连接,以便允许逻辑机架60内的sf30和sx32之间的8向喷射。在一些实例中,包括两个接入节点群组及其支持的服务器12的逻辑机架60可以称为半机架或半物理机架。在其他实例中,可以使用全网状连接将更多或更少的接入节点连接在一起。在一个实例中,16个接入节点17可以以全网状连接,以实现全物理机架内的第一级16向喷射。图8是示出接入节点17之间的数据中心交换结构上的实例多级网络扇出的框图。在图8所示的实例中,每个逻辑机架60包括八个接入节点171-178和由每一个接入节点支持的服务器节点12。第一逻辑机架601通过交换结构内的核心交换机22连接到第二逻辑机架602。在一些实例中,第一逻辑机架601和第二逻辑机架602可以是相同的逻辑机架。根据所公开的技术,交换结构包括fcp结构。fcp结构可以被可视化为包括多个信道,例如,请求信道、授权信道、fcp数据信道和非fcp数据信道。如图8所示,fcp数据信道经由逻辑隧道100承载数据包,该逻辑隧道100包括第一逻辑机架601中的源节点(例如,接入节点171的sf组件30a)和第二逻辑机架602中的目的地节点(例如,接入节点172的df组件36b)之间的所有路径。fcp数据信道使用fcp协议传输数据包。fcp分组通过合适的负载平衡方案在结构上从源节点喷射到目的地节点。fcp分组预期不会按顺序传送,但目的地节点预期会执行分组重新排序。例如,接入节点171的sf组件30a从源服务器12接收的业务流的分组可以在逻辑隧道100内的一些或所有可能的链路上喷射到接入节点172的df组件36b。df组件36b被配置为在将分组流发送到目的地服务器12之前,对接收到的分组重新排序,以重新创建分组流。fcp结构内的请求信道可用于将fcp请求消息从源节点传送到目的地节点。类似于fcp数据包,fcp请求消息可以在所有可用路径上喷射到目的地节点,但是请求消息不需要重新排序。作为响应,fcp结构内的授权信道可以用于将fcp授权消息从目的地节点传送到源节点。fcp授权消息也可以在所有可用路径上喷射到源节点,并且授权消息不需要重新排序。fcp结构中的非fcp数据信道承载不使用fcp协议的数据包。可以使用基于ecmp的负载平衡来转发或路由非fcp数据包,并且对于由五元组识别的给定流,分组预期将按顺序传送到目的地节点。图8的实例示出了第一逻辑机架601内的接入节点17之间的第一级网络扇出(如上参考图7b所述)以及接入节点17和核心交换机22之间的第二级网络扇出。如上参考图3至图4所述,第一逻辑机架601内的八个接入节点17使用电或光以太网连接而连接到核心交换机22。第二逻辑机架602内的八个接入节点17类似地连接到核心交换机22。在一些实例中,每个接入节点17可以连接到八个核心交换机22。在fcp业务的情况下,第一逻辑机架601内的接入节点17的sx组件32应用喷射算法来在所有可用路径上将任何给定分组流的分组喷射到核心交换机22。以这种方式,sx组件32可以不对接收分组的l2/l3交换执行完全查找操作。一旦从一个服务器12接收到源fcp业务,第一逻辑机架601中的接入节点171的sf组件30a就执行在所有可用路径上的fcp业务流的分组的8向喷射,喷射到第一逻辑机架601中的接入节点17实现的sx组件32。如图8中进一步示出的,每个sx组件32然后在所有可用路径上将fcp业务流的分组喷射到核心交换机22。在所示实例中,多级扇出是8乘8,并且因此支持多达64个核心交换机221-2264。在其他实例中,一级扇出在完全物理机架中为1:16,多级扇出可以为16乘16,支持多达256个核心交换机。尽管在图8中示出为直接发生在接入节点17和核心交换机22之间,但是可以通过一个或多个tor装置来执行第二级扇出,例如,架顶以太网交换机、光置换装置或电置换装置。下面参考图9至图19更详细地描述光置换装置。多级网络扇出使得在第一逻辑机架601内的任何接入节点17处接收的业务流的分组能够到达核心交换机22,以便进一步转发到第二逻辑机架602内的任何接入节点17。根据所公开的技术,在一个实例实现中,sf组件30和sx组件32中的每一个都使用fcp喷射引擎,该喷射引擎被配置为应用合适的负载平衡方案来在所有可用链路上将给定fcp分组流的分组喷射到目的地节点。例如,fcp喷射引擎可以跟踪在每个链路上传输的多个字节,以便选择最少负载的链路来转发分组。此外,fcp喷射引擎可以跟踪下游链路故障,通过在每个活动链路上喷射与带宽权重成比例的分组来提供流公平性。以这种方式,分组在可用链路上朝向目的地节点的喷射可能不均匀,但是即使在相对较短的时间段内,活动链路上的带宽也将平衡。在该实例中,第一逻辑机架601内的源节点(例如,接入节点171的sf组件30a)向第二逻辑机架602内的目的地节点(例如,接入节点172的df组件36b)发送请求特定权重或带宽的请求消息,并且目的地节点在保留出口带宽之后向源节点发送授权消息。源节点还确定核心交换机22和包括目的地节点的逻辑机架602之间是否发生了任何链路故障。源节点然后可以使用与源带宽和目的地带宽成比例的所有活动链路。例如,假设源节点和目的地节点之间有n个链路,每个链路具有源带宽sbi和目的地带宽dbi,其中,i=1...n。从源节点到目的地节点的实际带宽等于基于逐个链路确定的最小值(sb,db),以便将故障考虑在内。更具体地,源带宽(sb)等于并且目的地带宽(db)等于并且每个链路的带宽(bi)等于min(sbi,dbi)。每个链路上使用的带宽权重等于在fcp业务的情况下,sf组件30和sx组件32使用fcp喷射引擎,以基于每个链路上的负载来朝向目的地节点分发fcp业务的分组(与其权重成比例)。喷射引擎维护信用存储器,以跟踪每个下一跳成员链路的信用(即可用带宽),使用包括在fcp报头中的分组长度来扣除信用(即减少可用带宽),并将给定分组与具有最多信用的一个活动链路(即负载最少的链路)相关联。以这种方式,对于fcp分组,sf组件30和sx组件32与成员链路的带宽权重成比例地在目的地节点的下一跳的成员链路上喷射分组。核心交换机22沿第一逻辑机架601中的源节点(例如,接入节点171的sf组件30a)和第二逻辑机架602中的目的地节点(例如,接入节点172的df组件36b)之间的逻辑隧道100作为单跳操作。核心交换机22对接收分组的l2/l3交换执行完全查找操作。以这种方式,核心交换机22可以将相同业务流的所有分组转发到支持目的地服务器12的第二逻辑机架602中的目的地节点,例如,接入节点172的df组件36b。尽管在图8中示出为直接发生在核心交换机22和第二逻辑机架602的目的地接入节点172之间,但是核心交换机22可以将相同业务流的所有分组转发到与目的地节点具有连接性的中间tor装置。在一些实例中,中间tor装置可以将业务流的所有分组直接转发到由第二逻辑机架602的接入节点172实现的dx组件34b。在其他实例中,中间tor装置可以是被配置为提供另一扇出的光或电置换装置,分组可以通过该扇出被喷射在置换装置的输入和输出端口之间。在该实例中,第二逻辑机架602的接入节点17的全部或部分dx组件34可以接收相同业务流的喷射分组。第二逻辑机架602内的接入节点17的dx组件34和df组件36也具有全网状连接,因为每个dx组件34连接到第二逻辑机架602内的所有df组件36。当任何dx组件34从核心交换机22接收到业务流的分组时,dx组件34在直接路径上将分组转发到接入节点172的df组件36b。df组件36b可以执行有限的查找,这仅仅是为了选择合适的输出端口来将分组转发到目的地服务器12所必需的。响应于接收到业务流的分组,第二逻辑机架602内的接入节点172的df组件36b基于分组的序列号对业务流的分组进行重新排序。这样,关于数据中心的完整路由表,可能只有核心交换机22需要执行完整查找操作。因此,交换结构提供了高度可扩展、平坦、高速的互连,其中,服务器实际上是数据中心内任何其他服务器12的一个l2/l3跳。此处包括对fcp及其相对于图8的操作的一个实例的简要描述。在图8的实例中,接入节点17是fcp结构的结构端点(fep),该结构由以叶-主干拓扑排列的交换元件(例如,核心交换机22)组成。fpc结构允许一个接入节点17通过多个路径与另一接入节点进行通信。fcp结构内的核心交换机22具有浅分组缓冲器。fcp结构的横截面带宽等于或大于所有端点带宽的总和。以这种方式,如果每个接入节点17将输入数据速率限制到fcp结构,则fcp结构内的任何路径都不应该以非常高的概率长期拥塞。如上所述,fcp数据包经由逻辑隧道100从第一逻辑机架601内的源节点(例如,接入节点171的sf组件30a)发送到目的地节点(例如,第二逻辑机架602内的接入节点172的df组件36b)。在使用fcp通过隧道100发送任何业务之前,必须在端点之间建立连接。由接入节点17执行的控制平面协议可以用于在两个fcp端点之间建立一对隧道,每个方向一个。可选地,fcp隧道是安全的(例如,加密和认证)。隧道100被认为在从源节点到目的地节点是单向的,并且可以在从目的地节点到源节点的另一方向上建立fcp伙伴隧道。控制平面协议协商两个端点的能力(例如,块大小、mtu大小等),并且通过建立隧道100及其伙伴隧道以及每个隧道的初始化队列状态上下文来建立端点之间的fcp连接。每个端点被分配源隧道id和对应的目的地隧道id。在每个端点,基于分配的隧道id和优先级导出给定隧道队列的队列id。例如,每个fcp端点可以从手柄池中分配一个本地隧道手柄,并将该手柄传送到其fcp连接伙伴端点。fcp伙伴隧道手柄存储在查找表中,并从本地隧道手柄中引用。对于源端点,例如,第一逻辑机架601内的接入节点171,源队列由本地隧道id和优先级识别,并且基于本地隧道id从查找表中识别目的地隧道id。类似地,对于目的地端点,例如,第二逻辑机架602内的接入节点172,目的地队列由本地隧道id和优先级识别,并且源隧道id基于本地隧道id从查找表中识别。fcp隧道队列被定义为使用fcp在fcp结构上传输有效负载的独立业务流桶。给定隧道的fcp队列由隧道id和优先级识别,隧道id由给定隧道的源/目的地端点对识别。可替换地,端点可以使用映射表来基于给定隧道的内部fcp队列id导出隧道id和优先级。在一些实例中,fcp结构隧道(例如,逻辑隧道100)可以支持每个隧道1、2、4或8个队列。每个隧道的队列数是fcp结构属性,可以在部署时配置。fcp结构中的所有隧道可能支持每个隧道相同数量的队列。每个端点最多可以支持16,000个队列。当源节点与目的地节点通信时,源节点使用udp上的fcp封装来封装分组。fcp报头承载识别隧道id、队列id、分组序列号(psn)以及两个端点之间的请求、授权和数据块序列号的字段。在目的地节点,输入隧道id对于来自特定源节点的所有分组都是唯一的。隧道封装承载分组转发以及目的地节点使用的重新排序信息。单个隧道为源节点和目的地节点之间的一个或多个队列传送分组。只有单个隧道内的分组会基于跨同一隧道的队列的序列号标签重新排序。当分组通过隧道发送到目的地节点时,源节点用隧道psn标记分组。目的地节点基于隧道id和psn对分组进行重新排序。在重新排序结束时,目的地节点剥离隧道封装,并将分组转发到相应的目的地队列。此处描述了如何将在源端点进入fcp隧道100的ip分组传输到目的地端点的实例。ip地址为a0的源服务器12向ip地址为b0的目的地服务器12发送ip分组。源fcp端点(例如,第一逻辑机架601内的接入节点171)发送具有源ip地址a和目的地ip地址b的fcp请求分组。fcp请求分组具有fcp报头,以承载请求块号(rbn)和其他字段。fcp请求分组通过ip上的udp传输。目的fcp端点(例如,第一逻辑机架602内的接入节点172)将fcp授权分组发送回源fcp端点。fcp授权分组具有fcp报头,以承载授权块号(gbn)和其他字段。fcp授权分组通过ip上的udp传输。源端点在接收到fcp授权分组之后发送fcp数据包。源端点在输入数据包上附加一个新的(ip+udp+fcp)数据报头。目的地端点在将分组传送到目的主机服务器之前,删除附加的(ip+udp+fcp)数据报头。图9是更详细地示出图1的网络的一个实例的框图。在图9的实例中,交换结构14包括一组光置换器1321-132y(在本文中,“光置换器132”),也称为光置换装置,连接到一组基于核心分组的交换机22,这些交换机共同提供服务器12之间的全网状点对点连接。如进一步解释的,光置换器132是光互连装置,其通过利用波分复用在接入节点17和核心交换机22之间传输光信号,使得可以通过公共光纤22传送相同服务器群的服务器12的通信。例如,每个接入节点17可以利用不同的波长来传送同一服务器群的服务器12的通信。在图9的实例中,每个光置换器132包括用于与相应的一组接入节点171-17x进行光通信的一组面向边缘的光接口1361-136x以及用于与核心交换机22通信的一组面向核心的光接口1381-138x。尽管在图9中示出了每个光置换器132包括相同数量x的接入节点17和面向边缘的光接口136,但是在其他实例中,每个光置换器132可以包括光接口136,每个光接口136能够耦接到多于一个光纤22。在该另一实例中,每个光置换器132可以包括一组面向边缘的光接口1361-136x,用于与x的整数倍(例如,2x、3x或4x)的接入节点17进行光通信。此外,如本文所述,每个光置换器132被配置为使得在几个波长136的每个波长上从下游端口36接收的光通信基于波长在游端口138上“置换”,从而在上游端口和下游端口之间提供全网状连接,而没有任何光干扰。即,每个光置换器132被配置为确保从任一个下游服务器12接收的光通信可以引导到任何面向上游的光端口138,而不会对来自任何其他服务器12的任何同时通信产生光干扰。此外,光置换器132可以是双向的,即,类似地被配置为在下游端口136上置换来自上游端口138的通信,使得在任何下游端口上都不发生光干扰。以这种方式,光置换器132提供双向、全网状点对点连接,用于通过单独波长的粒度向/从核心交换机22传输服务器12的通信。例如,光置换器1321被配置为将光通信从面向下游的端口1361-136x光引导到面向上游的端口1381-138x,使得每个上游端口138承载面向下游的端口136和由这些端口承载的光频率的组合的一个不同的可能唯一置换,其中,没有单个面向上游的端口138承载来自与相同波长相关联的服务器12的通信。这样,在这个实例中,每个面向上游的端口138承载来自每个面向下游的端口136的非干扰波长,从而允许全网状的通信。在图9中,每个光置换器132的每个面向下游的光端口136接收光信号,在该实例中,该光信号承载服务器群的多达n个服务器的多达n个波长。作为一个实例,光置换器1321的端口1361可以从接入节点171接收光信号,该光信号承载作为在一个或多个光纤中承载的n个不同波长的通信。每个波长承载与耦接到接入节点171的服务器群的服务器12以及连接到作为接入节点171的相同接入组节点中的其他连接节点的服务器都相关联的通信。光置换器1321将光通信从面向下游的端口136引导到面向上游的端口138,使得每个面向上游的端口138承载光频率/下游端口组合的不同唯一置换,并且其中,没有面向上游的端口138承载来自与相同波长相关联的服务器12的通信。此外,光置换器1321可以类似地以双向方式配置,以在面向下游的端口1361-136x上置换来自面向上游的端口1381-138x的通信,并且使得没有面向下游的端口136承载与相同波长相关联的通信,从而提供完全双向、全网状点对点连接,用于向/从核心交换机22传输服务器12的通信。以这种方式,交换结构14可以提供全网状互连,使得任何服务器12可以使用多个并行数据路径中的任一个将分组数据传送到任何其他服务器12。此外,根据本文描述的技术,交换结构14可以被配置和设置为使得交换结构14中的并行数据路径在服务器12之间提供单个l2/l3跳、全网状互连(二分图),即使在具有数十万个服务器的大规模数据中心中也是如此。在一些实例实现中,每个接入节点17可以逻辑地连接到每个核心交换机22,因此具有多个并行数据路径,用于到达任何给定的其他接入节点以及通过这些接入节点可到达的服务器12。这样,在这个实例中,对于m个核心交换机22,在每个接入节点17之间存在m个可能的数据路径。每个接入节点17可以被视为有效地直接连接到每个核心交换机22(即使通过光置换器连接),因此任何将业务提供到交换结构14的接入节点都可以通过中间装置(核心交换机)的单跳l3查找到达任何其他接入节点17。在2017年3月29日提交的题为“non-blocking,full-meshdatacenternetworkhavingopticalpermutors”的美国临时申请号62/478,414中描述了光置换器的进一步的实例细节,该申请的全部内容通过引用结合于此。图10是示出网络200的更详细的实例实现的框图,其中,利用一组接入节点206和光置换器204来互连全网状网络中的端点,其中,每个接入节点206逻辑连接到m群核心交换机209中的每一群组。如该实例所示,如本文所述,每个服务器215经由一组并行数据路径向任何其他服务器传送数据。网络200可以位于数据中心内,该数据中心例如通过内容/服务提供商网络(未示出)(例如,图1和图9的内容/服务提供商网络7)为耦接到数据中心的客户提供应用程序和服务的操作环境。在一些实例中,将客户耦接到数据中心的内容/服务提供商网络可以耦接到由其他提供商管理的一个或多个网络,因此可以形成大规模公共网络基础设施(例如,互联网)的一部分。在该实例中,网络200表示多层网络,该多层网络具有m组z个物理网络核心交换机202a-1–202m-z(统称为“交换机202”),这些交换机光学互连到o个光置换器204-1–204-o(统称为“op204”),这些光置换器又经由y组x个接入节点206a-1–206y-x(统称为“an206”)互连端点(例如,服务器215)。端点(例如,服务器215)可以包括存储系统、应用服务器、计算服务器以及网络设备,例如,防火墙和/或网关。在图10的实例中,网络200包括三层:包括交换机202的交换层210、包括op204的置换层212以及包括接入节点206的接入层214a-214y(本文称为“接入层214”)。交换层210表示一组交换机202,例如,图9的核心交换机22,并且通常包括以交换拓扑互连的一个或多个高速核心以太网交换机,以便为在光链路上从光置换器204接收的并且由交换结构在光链路上转发到光置换器204的分组提供第2层/第3层分组交换。交换层210可替代地称为核心交换层/层或主干交换层/层。来自op204的每个光置换器从耦接到光置换器的一组多个光纤中的每一个接收一组波长的光,并在光耦接到光置换器的另一组多个光纤中的每一个之间重新分配和输出波长。每个光置换器204可以同时从接入节点206输入波长,以输出到交换机202,并从交换机202输入波长,以输出到接入节点206。在图10的实例中,网络200包括z*m个交换机202、o个光置换器204和y*x个接入节点206。接入节点206可以表示任何主机网络加速器(hna)或其他类似的接口装置、卡或虚拟装置(例如路由器)的实例,用于如本公开中所描述地与光置换器接合。光置换器204可以表示本公开中描述的任何光置换器的实例。网络200可以使用一个或多个交换架构(例如,多层多机架链路聚合组(mc-lag)、虚拟覆盖和ip结构架构)来互连端点。每个交换机202可以表示第2层/第3层(例如,以太网/ip)交换机,该交换机参与为网络200配置的一个或多个交换架构,以在接入节点对206之间提供点对点连接。在ip结构的情况下,交换机202和接入节点206均可以执行第3层协议(例如,bgp和/或ospf协议),以交换每个接入节点206后面的子网的路由。在图10的实例中,交换机202被设置成以z个交换机为一组的m组209a-209m(统称为“组209”)。每个组209具有一组交换机202,每个交换机202经由相应的光纤光耦接到同一光置换器204。换言之,每个光置换器204光耦接到一个组209的交换机202。例如,组209a包括光耦接到光置换器204-1的相应光端口的交换机202a-1–202a-z。作为另一实例,组209b包括光耦接到光置换器204-2的相应端口的交换机202b-1–202b-z。每个接入节点206包括至少一个光接口,以耦接到一个光置换器204的端口。例如,接入节点206a-1光耦接到光置换器204-1的端口。作为另一实例,接入节点206a-2光耦接到光置换器204-2的端口。在图10的实例中,接入节点206被分组成以x个接入节点为一组的y组211a-211y(统称为“组211”)。每个组211具有至少一个接入节点206,该接入节点206光耦接到每个o光置换器204。例如,组211a具有光耦接到光置换器204-1的接入节点206a-1、光耦接到光置换器204-2的接入节点206a-2等,直到光耦接到光置换器204-o的接入节点206a-x。由于这种拓扑,服务器215的接入节点的每个组211都具有到每个光置换器204的至少一个光耦接,并且相关地,由于光置换器204的操作,具有到每个交换机202的至少一个光耦接。在图10的实例中,接入节点206的组211包括相应的全网状连接220a-220y,以成对(点对点)连接每个组的接入节点206。例如,接入节点206a-1–206a-x的组211a包括[x*(x-1)]/2点对点连接的全网格220a,以便为服务器所连接的给定接入节点群组提供服务器215和接入节点206之间的完全连接。换言之,对于全网格220a,组211a中的每个接入节点包括到组211a中的每个其他接入节点中的源交换组件和目的地交换组件的至少一个点对点连接,从而允许通过接入节点去到或从交换层210到扇出/扇入的通信,以便经由一组并行数据路径源自或传送到任何服务器215。全网格220a的连接可以表示以太网连接、光连接等。组211a的全网格220a使得每对接入节点206a-1–206a-x(“接入节点206a”)能够彼此直接通信。因此,每个接入节点206a可以直接(经由直接光耦接,例如,具有光置换器204-1的接入节点206a-1)或者经由另一接入节点206a间接到达每个光置换器204。例如,接入节点206a-1可以经由接入节点206a-x到达光置换器204-o(并且,相关地,由于光置换器204-o的操作,交换机202m-1–202m-z)。接入节点206a-1可以经由其他接入节点206a到达其他光置换器204。因此,每个接入节点206a与每个交换机群组209具有点对点连接。组211b–211y的接入节点206具有与组211a的接入节点206a相似的拓扑。因此,由于本公开的技术,每个接入节点206与每个交换机群组209具有点对点连接。置换层212的每个光置换器204执行的波长置换可以减少在接入节点对206之间执行分组的第2层转发或第2/第3层转发所需的电交换操作的数量。例如,接入节点206a-1可以从本地耦接的服务器215接收出站分组数据,该出站分组数据去往与接入节点206y-1相关联的端点。接入节点206a-1可以选择特定的传输波长,在该特定的传输波长上,在耦接到光置换器204-1的光链路上传输数据,其中,所选择的传输波长由本文描述的光置换器204-1置换,用于在耦接到交换层210的交换机的特定光链路上输出,其中,交换机进一步通过另一光链路耦接到光置换器204-o。结果,交换机可以将承载数据的所选传输波长的光信号转换成电信号,并且第2层或第2/第3层将数据转发到光置换器204-o的光接口,光置换器204-o将数据的电信号转换成传输波长的光信号,该传输波长由光置换器204-o置换到接入节点206y-1。以这种方式,接入节点206a-1可以通过交换层210经由网络200向任何其他接入节点(例如,接入节点206y-1)传输数据,具有少至单个的中间电交换操作。图11是示出实例网络集群架构218的概念图,其中,在该实例中,八个物理机架701-708经由四个光置换器1321-1324和四个交换机群组2201-2204互连,每个交换机群组包含16个核心交换机。如图11所示,每个物理机架70包括具有第一接入节点群组191和第二接入节点群组192的第一逻辑机架601以及具有第三接入节点群组193和第四接入节点群组194的第二逻辑机架602。为了便于说明,由接入节点群组19支持的服务器52未在逻辑机架60内示出。在实例网络集群架构218中,如图6所示,四个物理机架70可以包括作为tor装置72的光置换器132,并且其他四个物理机架70可以不包括光置换器。在图11的实例中,每个逻辑机架60包括八个接入节点an1-an8,其中,四个接入节点包括在逻辑机架的两个接入节点群组19的每一个中。接入节点an1-an8可以基本上类似于上述接入节点17。此外,每个逻辑机架60包括四个电光电路eo1-eo4226,其中,两个电光电路设置在逻辑机架的两个接入节点群组19的每一个中。尽管示出了每个接入节点群组19具有两个电光电路226,但是在其他实例中,每个接入节点群组19可以包括由接入节点群组19中的四个接入节点17共享的单个电光电路或者四个电光电路,接入节点群组19中的四个接入节点17中的每一个都具有一个电光电路。在图11的实例中,每个光置换器132具有十六个面向下游的端口224,以连接到八个物理机架70中的十六个逻辑机架60。在图11的实例网络集群架构中,八个物理机架70上的每个逻辑机架60经由相应的光缆光耦接到四个光置换器132中的每一个。例如,机架701的逻辑机架601经由光缆230a光耦接到光置换器1321,并且还经由光缆230b耦接到光置换器1324。机架701的逻辑机架602经由光缆232a光耦接到光置换器1321,并且还经由光缆232b耦接到光置换器1324。机架708的逻辑机架601经由光缆240a光耦接到光置换器1321,并且还经由光缆240b耦接到光置换器1324。此外,机架708的逻辑机架602经由光缆242a光耦接到光置换器1321,并且还经由光缆242b耦接到光置换器1324。以这种方式,逻辑机架60与光置换器132具有全网状连接。如所示出的,光缆经由电光电路226连接到相应的逻辑机架60。因此,每个逻辑机架60具有四个光端口,每个光电电路226具有一个光端口。电光电路226将电信号转换成光信号,并将光信号转换成电信号。例如,在机架701的逻辑机架601中,eo1可以将来自接入节点群组191的an1和an2的电信号转换成光信号,用于通过光缆230a传输到光置换器1321。尽管在图11中没有完全示出,但是给定逻辑机架60的四个端口中的每一个都将连接到不同的一个光置换器132。例如,在每个逻辑机架60中,与eo1相关联的端口可以连接到光置换器1321,与eo2相关联的端口可以连接到光置换器1322,与eo3相关联的端口可以连接到光置换器1323,并且与eo4相关联的端口可以连接到光置换器1324。如上面详细描述的,每个接入节点支持到交换结构的2x100ge连接,使得给定的逻辑机架60支持来自八个接入节点an1-an8的16x100ge连接。给定逻辑机架60内的电光电路226将16x100ge连接上承载的电信号转换成光信号,用于通过4x400ge光缆传输到四个光置换器132。例如,在物理机架701的逻辑机架601中,an1和an2一起可以具有4x100ge连接,用于与交换结构通信。在接入节点群组191内,4x100ge连接是到eo1的铜链路。在一些实例中,这些铜链路可以具有更精细的粒度,例如,16x25ge链路。在将铜链路上接收到的电信号转换成光信号时,eo1通过单根400ge光缆230a将转换后的光信号发送到光置换器1321的面向下游的端口224。每个光置换器132还具有16个面向上游的端口222,以连接到给定一个交换机群组2201-2204内的16个核心交换机cx1-cx1622。如下面参考图15至图19更详细描述的,光置换器132被配置为在面向下游的端口224和面向上游的端口222之间喷射业务。以这种方式,光置换器132可以代替交换结构内电子交换机的额外叶层。每个交换机群组2201-2204都具有一组交换机22,每个交换机经由相应的光缆223光耦接到同一个光置换器1321-1324。例如,每个面向上游的端口222都可以支持光置换器1321和交换机群组2201内的一个核心交换机22之间的400ge光缆223。核心交换机22可以在对接收的业务执行完全查找和交换功能之前,将在光缆223上接收的光信号转换成电信号。在经由光缆223将业务转发回一个光置换器132之前,核心交换机22可以将业务转换回光信号。图12是示出来自图11的实例网络集群架构218的框图。图12更全面地示出了给定逻辑机架60和机架群组228内的每个光置换器132之间的全网状连接。机架群组228包括八个物理机架701-708和四个光置换器1321-1324。每个物理机架70具有两个逻辑机架601-602,其以全网状连接到四个光置换器132。四个光置换器132中的每一个都连接到四个交换机群组2201-2204中同一组内的十六个核心交换机(cx)。在图12的实例中,物理机架701的逻辑机架601经由四个光缆230连接到四个光置换器132中的每一个。如图所示,来自机架701的逻辑机架601的一个光缆230连接到每个光置换器1321-1324的面向下游的顶部端口224。机架701的逻辑机架602也经由四个光缆232连接到四个光置换器132中的每一个。如图所示,来自机架701的逻辑机架602的一个光缆232连接到每个光置换器1321-1324的第二面向下游的端口224。以这种方式,机架群组228内的每个物理机架70具有到每个光置换器132的两个连接,每个逻辑机架60具有一个连接。其他机架702-708中的每一个的逻辑机架60经由光缆类似地连接到四个光置换器132中的每一个。例如,来自机架708的逻辑机架601的一个光缆240连接到每个光置换器1321-1324的倒数第二个面向下游的端口224,并且来自机架708的逻辑机架602的一个光缆242连接到每个光置换器1321-1324的最后一个面向下游的端口224。光缆230、232、240、242中的每一个可以是400ge光缆。在一些实例中,400ge光缆中的每一个可以包括四个100ge光纤,每个光纤承载具有四个不同波长或λ的多路复用光信号。如上所述,当在面向下游的端口224上接收到来自逻辑机架60的业务时,光置换器132将业务喷射在所有面向上游的端口222上。光置换器132然后将面向上游的端口222上的业务转发到同一交换机群组220内的16个核心交换机中的每一个。例如,光置换器1321沿着光缆223将业务从每个面向上游的端口222传输到交换机群组2201中的一个核心交换机cx1-cx16。每个光缆223可以是400ge光缆。图13是示出另一实例网络集群架构318的框图,其中,八个物理机架701-708经由八个光置换装置3021-3028和八个交换机群组3201-3208互连。机架群组328包括以全8向网格连接的八个物理机架70和八个光置换器302。四个光置换器302中的每一个都连接到八个交换机群组320中同一交换机群组内的八个核心交换机(cx)。光置换器302的操作基本上类似于上述光置换器132,但是具有八个面向上游的端口322和八个面向下游的端口324。在图13的实例网络集群架构318中,每个光置换器302的面向上游的端口322连接到同一交换机群组320内的八个核心交换机。例如,光置换器3021的面向上游的端口322经由光缆323连接到交换机群组3201中的核心交换机cx1-cx8。此外,每个光置换器302的面向下游的端口324以全网状连接到八个物理机架70中的每一个。在图13的实例中,物理机架701经由八个光缆330连接到八个光置换器302中的每一个。如图所示,来自机架701的一个光缆330连接到每个光置换器3021-3028的面向下游的顶部端口324。其他机架702-708类似地经由光缆连接到八个光置换器302中的每一个。例如,来自机架702的一个光缆332连接到每个光置换器3021-3028的第二面向下游的端口324,来自机架703的一个光缆334连接到每个光置换器3021-3028的第三面向下游的端口324,并且来自机架708的一个光缆340连接到每个光置换器3021-3028的最后面向下游的端口324。光缆330、332、334、340中的每一个可以是400ge光缆。在一些实例中,400ge光缆中的每一个可以包括四个100ge光纤,每个光纤承载具有四个不同波长或λ的多路复用光信号。如上面详细描述的,每个物理机架70包括四个接入节点群组,每个接入节点群组包括四个接入节点。每个接入节点支持朝向交换结构的2x100ge连接,使得给定的物理机架70支持来自16个接入节点的32x100ge连接。给定物理机架70内的电光电路将32x100ge连接上承载的电信号转换成光信号,用于通过8x400ge光缆传输到八个光置换器302。如上所述,在接收到来自面向下游的端口324上的机架70的业务时,光置换器302将业务喷射在所有面向上游的端口322上。光置换器302然后在面向上游的端口322上将业务转发到同一交换机群组320内的八个核心交换机中的每一个。例如,光置换器3021沿着光缆323将业务从每个面向上游的端口322传输到交换机群组3201中的核心交换机cx1-cx8中的一个。每个光缆323可以是400ge光缆。分别在图12和图13中示出的实例网络集群架构218、318可以各自在单个半机架(即,逻辑机架60)和2000个物理机架70之间支持。例如,交换机群组220、320中包括的64个核心交换机22可以包括大量端口,并且被配置为作为多个机架群组228、328的主干交换机操作。在一些情况下,同一组64个核心交换机22可以作为多达250个不同的8机架群组(即2000个物理机架)的主干交换机操作。如上参考图4所述,每个半机架或逻辑机架60可以支持32个双插槽或双处理器服务器节点以及到交换结构的高达1.6tbps的全双工网络带宽。下面的表1包括分别由图12和图13所示的实例网络集群架构218、318支持的实例数量的接入节点、服务器节点、服务器插座或处理器以及不同数量的物理机架的网络带宽。表1机架接入节点服务器节点插座/处理器网络带宽1/2832641.6tbps116641283.2tbps81285121,02425.6tbps1001,6006,40012,800320tbps1,00016,00064,000128,0003.2pbps2,00032,000128,000256,0006.4pbps图14是示出两个网络集群350a和350b(统称为“集群350”)之间的实例互连的框图。互连网络集群350可以形成数据中心或数据中心的一部分,例如,图1和图9中的数据中心10。每个集群350可以基本上类似于图11、图12所示的网络集群架构218或图13所示的网络集群架构318。在一个实例中,集群350a可以被设置为基本上类似于网络集群架构218,集群350b可以被设置为基本上类似于网络集群架构318。每个集群350包括多个核心交换机22和多个接入节点17,每个接入节点17耦接到多个服务器121-12n。尽管图14中未示出,但是接入节点17和相应的服务器12可以被设置为一个或多个物理机架和/或一个或多个机架群组。在一些情况下,如图11至图13所示,物理机架和/或机架群组还可以包括一个或多个tor交换机、电置换器或光置换器,其作为网络集群内的接入节点17和核心交换机22之间的叶层和链路乘数操作。如图14所示,每个集群350内的核心交换机22还连接到一组网络装置对,每对包括接入节点352和边界网关装置354。接入节点352和边界网关装置354可以被视为背靠背接入节点,其操作基本类似于接入节点17。此外,边界网关装置354可以执行几个额外功能,例如,状态防火墙、应用层负载平衡器和路由器的功能。接入节点352可以使用pcie连接而连接到边界网关装置354。以这种方式,当接入节点352向边界网关装置354发送分组时,接入节点352就像向服务器(例如,服务器12)发送分组一样操作。在一些实例中,该组网络装置对可以包括物理机架中包括的多对接入节点352和边界网关装置354。例如,四对接入节点352和边界网关装置354可以设置在物理机架内的2ru滑动部件中。边界网关装置354使得集群350能够经由一个层次的路由器356和服务提供商网络360(例如,互联网或另一公共wan网络)彼此连接并与外部世界连接。例如,边界网关装置354可以基本上类似于图1中的网关装置20。如图14所示,边界网关装置354可以具有到路由器356的多个路径。在一些实例中,类似于上面详细描述的接入节点17的行为,边界网关装置354可以在链路上对各个分组流执行到路由器356的分组喷射。在其他实例中,边界网关装置354可以使用ecmp在链路上将分组流转发到路由器356。在图14所示的实例中,第一集群350a包括在第一建筑348a中,第二集群350b包括在第二建筑348b中。在其他实例中,两个集群350可以包括在同一建筑中。在任一实例中,为了作为单个数据中心操作,网络集群350可以相对共同靠近地定位。例如,集群350a可以在物理上位于离集群350b不超过两公里的地方。可以容纳在单个建筑或一组建筑中的集群350的数量可能主要受到功率限制的限制。例如,如上参考图6所述,每个物理机架使用大约15kw,使得一个或多个集群内的2,000个物理机架将使用大约30mw的功率,并且分布在两个或多个集群上的3,000个物理机架使用大约45mw的功率。在集群350a和350b之间转发分组的一个实例中,在时间t0,集群350a内的接入节点17a在结构14a上通过多个链路中的一个将分组发送到接入节点352a。在时间t1,接入节点352a从结构14a接收分组。在时间t2,接入节点352a通过pcie连接将分组发送到边界网关装置354a。边界网关装置354a对分组的目的地ip地址执行转发查找,并确定分组去往边界网关装置354a后面的集群350b。在时间t3,集群350a内的边界网关354a在服务提供商网络360上通过多个链路中的一个将分组发送到集群350b内的边界网关装置354b。例如,边界网关装置354a可以使用本公开中描述的分组喷射技术或ecmp技术,通过多个路径中的一个将分组发送到路由器356a、356b。在时间t4,集群350b内的边界网关装置354b从路由器356a、356b接收分组。边界网关装置354b对分组的目的地ip地址执行转发查找,并且通过pcie连接将分组发送到接入节点352b。在时间t5,接入节点352b在结构14b上通过多个链路中的一个将分组发送到集群350b内的接入节点17b。在时间t6,接入节点17b从结构14b接收分组。在时间t7,接入节点17b对分组的目的地ip地址执行转发查找,并且将分组发送到一个服务器12。图15是示出实例光置换器400的框图,光置换器40可以是图9、图11以及图12的任何光置换器132。在这个实例中,光置换器40包括多个双向输入端口(p1-p32),每个端口发送和接收相应的光信号。在这个实例中,光置换器400包括32个光端口,其中,p1-p16是面向接入节点的端口,用于光耦接到接入节点17,端口p17-p32是面向核心交换机的端口,用于与核心交换机22光耦接。在一个具体实例中,每个端口都包括双向400千兆位光接口,该接口能够耦接到四对100千兆位单模光纤(smf),每个光纤承载四个25g波长λ1、λ2、λ3、λ4。因此,在该实例中,每个端口p1-p32提供400千兆位光带宽。所描述的实例架构易于扩展,并且可以支持例如分别承载四个(或更多)50g和100g波长的200和400千兆位光纤。在图15的实例中,光学多路复用器400包括四个光学多路复用器/多路解复用器(图15中的“光学多路复用器切片0-3”)410a-410d(在本文称为“光学多路复用器切片410”),其具有四个面向400g接入节点的光端口430和十六个面向核心交换机的100g光端口450。如图16中更详细地示出的,每个光学多路复用器切片410接收由四个光端口430的组的smf承载的光信号,将每个smf的光信号中的四个波长分开,并且以4x4喷射的形式在十六个光端口450的组上喷射每个smf承载的波长。图16是进一步详细示出图15的光学多路复用器切片410的实例的框图。在图16的实例中,每个光学多路复用器切片410包括四个光学多路复用器/多路解复用器芯片470a-470d(本文称为“光学多路复用器/多路解复用器芯片470”)。每个光学多路复用器/多路解复用器芯片470从由光学多路复用器切片410服务的每个不同输入端口(p)的一个smf接收光信号,例如,图15的光学多路复用器切片410a的端口p1-p4。每个光学多路复用器/多路解复用器芯片470将每个smf的光信号中的四个波长分开,并且以4x4喷射的形式在四个光端口490的组上喷射每个smf承载的波长。例如,在图16,每个光通信称为λp,w,其中,下标p表示端口,下标w表示不同的波长。因此,使用这种命名法,光学多路复用器切片410的端口p1接收承载称为λ1,1、λ1,2、λ1,3以及λ1,4的n个不同波长的通信的光束,其中,在该实例中,n等于4。同样,光端口p2接收承载称为λ2,1、λ2,2、λ2,3以及λ2,4的n个不同波长的通信的光束。如图所示,每个光学多路复用器/多路解复用器芯片470a-470d接收来自端口p1的承载λ1,1、λ1,2、λ1,3以及λ1,4的光信号、来自端口p2的承载λ2,1、λ2,2、λ2,3以及λ2,4的光信号、来自端口p3的承载λ3,1、λ3,2、λ3,3以及λ3,4的光信号以及来自端口p4的承载λ4,1、λ4,2、λ4,3以及λ4,4的光信号。每个光学多路复用器/多路解复用器芯片470将每个smf的光信号中的四个波长分开,并喷射每个smf承载的波长,使得每个光端口490承载光学输入端口p1-p4和这些端口承载的光学波长的组合的一个不同的可能唯一置换,其中,没有单个光学输出端口490承载具有相同波长的多个光通信。例如,如图16所示,对于任何给定的光学多路复用器/多路解复用器芯片470,一组四(4)个光输出端口490可以在第一端口上输出波长λ1,1、λ4,2、λ3,3以及λ2,4的光信号,在第二端口上输出承载波长λ2,1、λ1,2、λ4,3以及λ3,4的光信号,在第三端口上输出承载λ3,1、λ2,2、λ1,3以及λ4,4的光信号,在第四端口上输出承载λ4,1、λ3,2、λ2,3以及λ1,4的光信号。以下提供了图15、图16的光置换器400的一个实现的完整实例。在这个实例中,每个端口p1-p32包括四个单独的单模光纤对(为每个端口指定f1-f4)。即,光置换器400的每个端口p1-p32包括被配置为接收四个单独的光纤的输入光接口,例如,被配置为耦接到四个单独的100g光纤并从四个单独的100g光纤接收光信号的400g光接口。此外,光置换器40的每个端口p1-p32包括输出光接口,该输出光接口被配置为连接到四个单独的光纤并在四个单独的光纤上传输光信号,例如,被配置为接收四个单独的100g光纤的400g光接口。此外,用于每个输入端口p1-p16的四个光纤对中的每一个耦接到不同的接入节点17,从而提供来自64个不同接入节点的双向光连接。表2列出了用于面向核心方向上的光通信的光置换器400的一个实例配置。即,表2示出了光置换器400的实例配置,用于在面向核心的输出端口p17-p32的光纤上产生一组64个唯一置换,用于光输入端口p1-p16和由这些输入端口承载的光波长l1-l4的组合,其中,没有单个光输出端口承载具有相同波长的多个光通信。例如,表2的第一列列出了端口p0-p16的每个输入光接口的四个光纤f1-f4承载的波长l1-l4,而右列列出了端口p17-p32的每个光学输出接口上输入端口光纤/波长组合输出的唯一且无干扰的置换。表2继续该实例,表3列出了光置换器400相对于反向、下游方向(即,从核心交换机22到接入节点17)的光通信的实例配置。即,表3示出了光置换器400的实例配置,用于在面向机架的输出端口p1-p16的光纤上产生一组64个唯一置换,用于面向核心的输入端口p16-p32和由这些输入端口承载的光波长l1-l4的组合,其中,没有单个光输出端口承载具有相同波长的多个光通信。表3表4列出了用于面向核心方向上的光通信的光置换器400的第二实例配置。与上面的表2一样,表4示出了光置换器400的实例配置,用于在面向核心的输出端口p17-p32的光纤上产生一组64个唯一置换,用于光输入端口p1-p16和由这些输入端口承载的光波长l1-l4的组合,其中,没有单个光输出端口承载具有相同波长的多个光通信。类似于上面的表2,表4的第一列列出了端口p0-p16的每个输入光接口的四个光纤f1-f4承载的波长l1-l4,而右列列出了端口p17-p32的每个光学输出接口上的输入端口光纤/波长组合输出的唯一且无干扰置换的另一实例。表4继续该实例,表5列出了光置换器400相对于反向、下游方向的光通信的另一实例配置,即,从核心交换机22到接入节点17。类似于上面的表3,表5示出了光置换器400的另一实例配置,用于在面向机架的输出端口p1-p16的光纤上产生一组64个唯一的置换,用于面向核心的输入端口p16-p32和由这些输入端口承载的光波长l1-l4的组合,其中,没有单个光输出端口承载具有相同波长的多个光通信。表5图17是示出实例光置换器500的框图,该光置换器可以是图9、图11以及图12的任何光置换器132。在这个实例中,光置换器500包括多个输入端口520a-520n(本文称为“输入端口520”),以用于接收相应的光信号,每个光信号承载一组n个波长的通信。每个通信称为λp,w,其中,下标p表示端口,下标w表示波长。因此,使用这种命名法,光输入520a接收承载称为λ1,1、λ1,2、…λ1,n的n个不同波长的通信的光束。同样,光输入520b接收承载称为λ2,1、λ2,2、…λ2,n的n个不同波长的通信的光束。光置换器500包括用于每个光输入接口520的相应一个光学多路解复用器600a-600n(本文称为“光学多路解复用器600”),其中,光学多路解复用器被配置为基于光通信的带宽将给定光输入的光通信多路分解到内部光路640上。例如,光学多路解复用器600a基于波长λ1,1、λ1,2、…λ1,n将在光输入接口520a上接收的光通信分离到一组内部光路640a上。光学多路解复用器600b基于波长λ2,1、λ2,2、…λ2,n将在光输入接口520b上接收的光通信多路分解到一组内部光路640b上。每个光学多路解复用器600以类似的方式操作,以分离从相应输入光接口520接收的光通信,从而通过内部光路640将光通信引导到光输出端口540a-540n(本文称为“光输出端口540”)。光置换器500包括用于每个光输出端口540的相应一个光学多路复用器620a-620n(本文称为“光学多路复用器620”),其中,光学多路复用器从通向每个光学多路解复用器600的光路640接收光信号,作为输入。换言之,光置换器500内部的光路640在光学多路解复用器600和光学多路复用器620之间提供n2光学互连的全网。每个光学多路复用器620接收n个光路,作为输入,并将由n个光路承载的光信号组合成单个光信号,以输出到相应的光纤上。此外,每个光学多路解复用器600被配置为使得从输入接口端口520接收的光通信基于波长在光输出端口540上“置换”,从而在端口之间以确保避免光干扰的方式提供全网状连接。即,每个光学多路解复用器600被配置为确保每个光输出端口540接收光输入端口520和由这些端口承载的光频率的组合的一个不同的可能唯一置换,其中,没有单个光输出端口540承载具有相同波长的通信。例如,光学多路解复用器600a可以被配置为将波长为λ1,1的光信号引导到光学多路复用器620a,波长为λ1,2的光信号引导到光学多路复用器620b,波长为λ1,3的光信号引导到光学多路复用器620c,…并且波长为λ1,n的光信号引导到光学多路复用器620n。光学多路解复用器600b被配置为通过向光学多路复用器620a输出波长λ2,n,向光学多路复用器620b输出波长λ2,1,向光学多路复用器620c输出波长λ2,2,…以及向光学多路复用器620n输出波长λ2,n-1来传送光信号的不同(第二)置换。光学多路解复用器600c被配置为通过向光学多路复用器620a输出波长λ3,n-1,向光学多路复用器620b输出波长λ3,n-2,向光学多路复用器620c输出波长λ3,n-3,…以及向光学多路复用器620n输出波长λ3,n-2来传送光信号的不同(第三)置换。该实例配置模式继续通过光学多路解复用器600n,该光学多路解复用器600n被配置为通过将波长λn,2输出到光学多路复用器620a,波长λn,3输出到光学多路复用器620b,波长λn,4输出到光学多路复用器620c,…以及波长λn,1输出到光学多路复用器620n来传送光信号的不同(第n)置换。在实例实现中,光路640被设置为使得输入接口/波长的不同置换传送到光学多路复用器620。换言之,每个光学多路解复用器600可以被配置为以类似的方式操作,例如,将λ1提供给多路解复用器的第一端口,将λ2提供给多路解复用器的第二端口…,并且将λn提供给多路解复用器的第n端口。光路640被设置为光学地将特定波长置换传送到每个光学多路复用器620,使得来自任一个光学多路解复用器600的任何通信可以到达任何光学多路复用器620,此外,选择每个波长置换,以避免信号之间的任何干扰,即,不重叠。例如,如图17所示,光路640a提供从承载λ1,1的光学多路解复用器600a的第一端口到光学多路复用器620a、从承载λ1,2的光学多路解复用器600a的第二端口到光学多路复用器620b、从承载λ1,3的光学多路解复用器600a的第三端口到光学多路复用器620c…以及从承载λ1,n的光学多路解复用器600a的第n端口到光学多路复用器620n的光互连。不是以与光路640a相同的方式提供互连,而是光路640b被设置为提供从承载λ2,1的光学多路解复用器600b的第一端口到光学多路复用器620b,从承载λ2,2的光学多路解复用器600b的第二端口到光学多路复用器620c,…从承载λ2,n-1的光学多路解复用器600b的第n-1端口到光学多路复用器620n以及从承载λ2,n的光学多路解复用器600b的第n端口到光学多路复用器620a的光互连。光路640c以另一种方式设置,以便提供从承载λ3,1的光学多路解复用器600c的第一端口到光学多路复用器620c,…从承载λ3,n-2的光学多路解复用器600c的第n-2端口到光学多路复用器620n,从承载λ3,n-1的光学多路解复用器600c的第n-1端口到光学多路复用器620a,以及从承载λ3,n的光学多路解复用器600c的第n端口到光学多路复用器620b的光互连。在该实例中,该互连图案继续,使得光路640n被设置为提供从承载λn,1的光学多路解复用器600n的第一端口到光学多路复用器620n、从承载λn,2的光学多路解复用器600n的第二端口到光学多路复用器620a、从承载λn,3的光学多路解复用器600n的第三端口到光学多路复用器620b以及从承载λn,4的光学多路解复用器600n的第四端口到光学多路复用器620c…的光互连。以这种方式,输入光接口/波长组合的不同置换提供给每个光学多路复用器620,此外,保证提供给相应光学多路复用器的每个置换包括具有非重叠波长的光通信。光置换器500示出了本文描述的技术的一个实例实现。在其他实例实现中,每个光接口420不需要从单个光纤接收所有的n个波长。例如,n个波长的不同子集可以由多个光纤提供,然后将其组合(例如,由多路复用器)并随后如本文所述进行置换。作为一个实例,光置换器500可以具有2n个光输入520,以便接收2n个光纤,其中,第一子集的n个光纤承载波长λ1…λn/2,第二子集的n个光纤承载波长λn/2+1…λn。来自第一和第二集合的成对光输入的光可以组合,以形成承载n个波长的光输入,然后可以如图17的实例所示置换该光输入。在实例实现中,包括光输入端口520、光学多路解复用器600、光路640、光学多路复用器620和光输出端口540的光置换器500可以实现为一个或多个专用集成电路(asic),例如,光子集成电路或集成光学电路。换言之,本文描述的光学功能可以集成在单个芯片上,从而提供集成光置换器,其可以包含到电子卡、装置和系统中。图18是光置换器500的另一实例实现的框图。在实例实现中,光学多路解复用器600被不同地配置,以便将输入接口/波长的不同的相应置换引导到光路640,用于传输到光学多路复用器620。在图18的实例实现中,每个光学多路解复用器600包括一系列光循环器700,光循环器700具有设置在每个光循环器之后的光栅元件720。光栅元件可以是例如光纤布拉格光栅(fbg)元件或阵列波导光栅(awg)。每对光循环器700和光栅元件720被配置为选择性地从光学多路解复用器600的相应输出端口引导出特定波长。具体地,每个光循环器700操作,以沿循环器周围的顺时针方向从下一个光接口引导出在其任何光接口上接收的所有入射光。例如,光循环器700a接收光接口740a上的光,并从光接口740b引导出光循环器周围的所有波长。每个光栅元件720被配置为反射特定波长,该特定波长重新进入接收光的上游循环器。例如,光栅元件720a接收来自上游循环器700a的波长λ1,1、λ1,2、…λ1,n,并被配置为反射λ1,1并通过所有其他波长λ1,2、…λ1,n。具有λ1,1的光重新进入循环器700a,其中,光传递到光路640的下一个光接口740c。波长为λ1,2、…λ1,n的光继续向下游传播,其中,光循环器700b和光栅元件720b被配置为选择性地从光路640的光接口740d引导出波长为λ1,2的光。以这种方式,每个光栅元件720被配置为选择性地从光学多路解复用器600的适当光端口重定引导出正确的波长,使得每个多路解复用器输出传输到光学多路复用器620的光学波长的不同置换。在其他实例中,光置换器132、400、500可以利用在kaminow的“opticalintegratedcircuits:apersonalperspective”,光波技术杂志,第26卷,第9期,2008年5月1日中描述的星形耦接器和波导光栅路由器,该文献的全部内容通过引用结合于此。图19是示出具有多个逻辑置换平面1-x的光置换器1000的框图。每个置换平面可以基本上如上所述配置,以便以保证无干扰的方式将波长/输入端口组合置换到输出端口。例如,每个置换平面1-x可以实现为图15、图16的光置换器400或图17、图18的光置换器500,并且多个置换平面可以封装在单个芯片上。在该实例实现中,光置换器1000可以容易地在单个装置中缩放,以支持大量的光学输入和输出。图20是示出根据本文描述的技术的网络系统的实例操作的流程图。为了便于说明,参考图1的网络系统8描述了图20的流程图,该网络系统8包括数据中心10的服务器12、接入节点17和交换结构14。然而,图20所示的技术很容易适用于本文描述的其他实例网络实现。如该实例中所示,一组接入节点17交换控制平面消息,以在多个并行网络路径上建立逻辑隧道,这些路径在接入节点之间提供基于分组的连接(1101)。例如,关于图1,交换结构14可以包括一层或多层交换机和/或路由器,提供多个路径,用于在接入节点17之间转发通信。可能响应于来自sdn控制器21的指示,相应的接入节点对17交换控制平面消息,以协商在接入节点之间的多个并行路径上配置的逻辑端到端隧道。一旦建立了逻辑隧道,一个接入节点(在图20中称为‘发送接入节点’)可以例如从应用程序或存储服务器12接收与相同的总分组流相关联的出站分组(1102)。作为响应,对于至少一些实例实现,发送接入节点发出发送指定量的分组数据的请求(1103)。一旦从与要发送的分组数据的目的地相关联的接入节点接收到许可(1108),发送接入节点就将出站分组封装在隧道分组内,从而形成每个隧道分组,以具有用于穿过逻辑隧道的隧道报头和包含一个或多个出站分组的有效载荷(1104)。一旦形成隧道分组,发送接入节点通过经由交换结构14在多个并行路径上喷射隧道分组来转发隧道分组,接收接入节点通过交换结构14是可到达的(1106)。在一些实例实现中,在将隧道分组转发到交换结构14之前,发送接入节点可以将隧道分组喷射在多个接入节点上,这些接入节点例如形成一个或多个接入节点群组(例如,在靠近发送接入节点的一个或多个机架群组内),从而提供用于在并行路径上分发隧道分组的第一级扇出。此外或者可替代地,当隧道分组穿过多个并行路径(即,多个非命运共享路径)时,隧道分组可以由中间光置换器(见图9)处理,中间光置换器在端口上置换通信,从而提供到达额外并行路径的第二级扇出,以便提供网络系统的更大可扩展性,同时仍然在接入节点之间提供高级连接。在其他实例实现中,网络系统不需要包括光置换器。一旦接收,接收接入节点提取封装在隧道分组内的原始分组(1109),按照应用程序或存储服务器发送的顺序对原始分组进行重新排序,并将分组传送到预期的目的地服务器(1110)。已经描述了各种实例。这些和其他实例在所附权利要求的范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1