处理3D视频内容的制作方法
相关申请的交叉引用
本申请要求以下美国临时专利申请的权益:
■2017年7月11日递交的序列号:62/531,284;
■2017年7月11日递交的序列号:62/531,310;
■2017年5月6日递交的序列号:62/502,647;
■2017年5月6日递交的序列号:62/502,650;
■2017年8月24日递交的序列号:62/549,593;
■2017年8月24日递交的序列号:62/549,606;以及
■2017年8月24日递交的序列号:62/549,632。
所有上述专利申请在此通过引用以其整体并入本文。
本发明主要涉及计算机图形学,并且更具体地涉及处理3d视频内容。
背景技术:
对于处理并呈现高质量的全息视频充满困难。例如,纹理化的网格全息图由一系列编码网格和相应的纹理视频组成。这些全息图通常使用低级语言和应用程序接口(api)在本机应用程序中进行渲染。在网络环境中(尤其是在移动设备上)交互式地压缩、解压缩、传输和渲染全息图面临着强大的技术挑战。
通过本文公开的系统和方法减少或消除了上述技术问题。
技术实现要素:
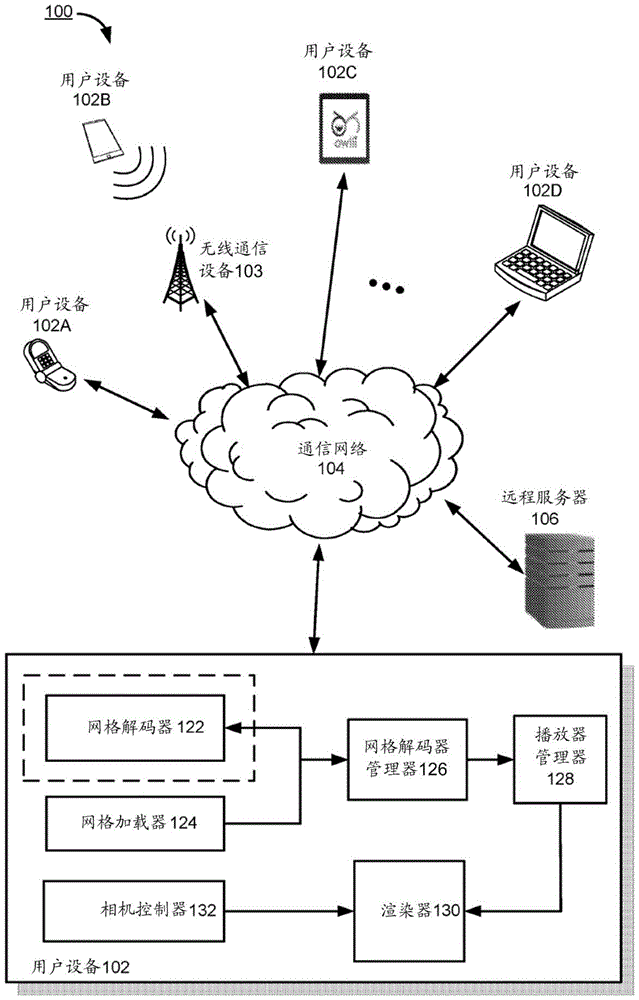
在本发明中公开了用于处理全息视频的系统和方法。一种示例性的基于网络(web-based)的交互式3d纹理网格全息图渲染移动设备包括:网格加载器,所述网格加载器管理被配置为将压缩的网格序列从远程服务器下载到本地存储缓冲器中;网格解码器,所述网格解码器被配置为将压缩的网格序列实时解码为网格帧;网格解码器管理器,所述网格解码器管理器被配置为从所述网格加载器请求压缩的网格序列,并请求所述网格解码器对所述压缩的网格序列进行解码;播放器管理器,所述播放器管理器被配置为对纹理视频进行解码并从所述网格解码器管理器请求相应的已解码的网格,并且保持请求所述相应的已解码的网格与解码所述纹理视频之间的同步;以及渲染器,所述渲染器被配置为使用渲染引擎在画布上渲染所述已解码的网格;以及相机控制器,所述相机控制器被配置为检测一个或多个用户动作,并根据所述一个或多个用户动作控制硬件相机。
在一些实施方式中,所述渲染引擎为webgl渲染引擎。
在一些实施方式中,所述画布为html5画布。
在一些实施方式中,所述网格解码器是从所述移动设备不支持的编程语言进行转码的。
在一些实施方式中,所述网格加载器和所述网格解码器管理器是同步执行的。
在一些实施方式中,所述相机控制器使用所述硬件相机捕获所述一个或多个用户动作并将所述一个或多个用户动作作为反馈提供给所述渲染器。
在一些实施方式中,所述网格解码器管理器被配置为根据需要请求所述网格解码器对所述压缩的网格序列进行解码。
在一些实施方式中,所述网格解码器管理器被配置为请求所述网格解码器对预定量的压缩的网格序列进行解码,所述预定量的压缩的网格序列比所述播放器管理器所请求的那些压缩的网格序列要多。
在一些实施方式中,所述网格解码器管理器被配置为从连接到所述播放器管理器的网格缓冲器中移除先前解码的网格。
在一些实施方式中,所述网格加载器被配置为:从所述远程服务器下载压缩的网格序列,甚至在所述网格解码器管理器没有请求下载所述压缩的网格序列的情况下也从所述远程服务器下载所述压缩的网格序列。
附图说明
图1为示出根据一些实施方式的示例性全息图处理系统的框图。
图2为示出根据一些实施方式的用于处理全息图的示例性方法的流程图。
图3为示出根据一些实施方式的用于渲染全息图的用户设备的框图。
图4为示出根据一些实施方式的用于渲染全息图的远程服务器的框图。
图5为示出根据一些实施方式的用于在网络环境中进行交互式3d纹理网格全息图渲染的方法的流程图。
图6为示出根据一些实施方式的i帧编解码器的示例性工作流程的流程图。
图7为示出根据一些实施方式的p帧编解码器的示例性工作流程的流程图。
图8为示出根据一些实施方式的用于压缩和解压缩全息图的示例性计算设备的框图。
图9为示出根据一些实施方式的用于压缩和解压缩全息图的示例性系统的框图。
图10为示出根据一些实施方式的用于动态3d重建和跟踪的方法的框图。
图11-图13为示出根据一些实施方式的用于泊松曲面视频的示例性方法的流程。
图14为示出根据一些实施方式的用于低比特率的3d动态重建和传输的示例性方法的流程图。
图15为示出根据一些实施方式的用于网格参数化的示例性工作流程的框图。
图16为示出根据一些实施方式的用于进行纹理化的示例性方法的流程图。
图17为示出根据一些实施方式的示例性边界因子扩展的框图。
图18为示出根据一些实施方式的用于3d动态重建和传输的示例性系统的框图。
图19为示出根据一些实施方式的用于在移动设备上进行混合现实内容处理的示例性方法的流程图。
图20-图24为示出根据一些实施方式的用于在移动设备上进行混合现实内容的呈现和交互的示例性方法的流程图。
图25-图26为示出用于图形化地移除全息图中显示的头戴式耳机并使用户的面部可见的示例性方法的流程图。
图27示出了四个图像,包括两个示出用户佩戴头戴式耳机设备的图像和两个示出用户没有佩戴头戴式耳机的图形化修改后的图像。
具体实施方式
基于网络的交互式3d纹理网格全息图渲染
图1为示出根据一些实施方式的示例性全息图处理系统100的框图。
在一些实施方式中,计算机系统100包括一个或多个用户设备102(例如,移动设备102a、102b、102c、102d、……、以及102n)、通信网络104和远程服务器106。
在一些实施方式中,用户设备102基于从远程服务器160接收到的数据来渲染全息图。用户设备102可以为移动设备(诸如智能手机、笔记本电脑、平板电脑、或音频/视频播放器)。在一些实施方式中,用户设备102包括网格解码器122、网格加载器124、网格解码器管理器126、播放器管理器128、渲染器130和相机控制器132。
在一些实施方式中,通信网络104将一个或多个设备102彼此互连,并将一个或多个设备102与集群系统106互连。在一些实施方式中,通信网络104可选地包括因特网(internet)、一个或多个局域网(localareanetwork,lan)、一个或多个广域网(wideareanetwork,wan)、其它类型的网络或这些网络的组合。
在一些实施方式中,远程服务器系统106存储全息图数据,该全息图数据可以被发送到用户设备120以供处理和呈现。远程服务器系统106可以通过压缩和解压缩所述全息图数据、以及分析和修改所述全息图数据来处理所述全息图数据,以进行重建。
图2为示出根据一些实施方式的用于处理全息图的示例性方法200的流程图。
方法200可以根据用户交互在网络环境中有效地渲染3d纹理的网格全息图。执行方法200的系统在本发明中也可以称为播放器。该系统可以被配置为在台式设备和移动设备两者上操作。
示例性播放器可以用javascript程序实现,并在各种类型的浏览器上运行。该播放器异步地加载已编码的网格和相应的纹理视频;将网格逐帧地解码为顶点(vertice)、三角形索引和纹理坐标;如果可能,则使用硬件解码器对纹理视频进行解码;以及在保持同步的同时对解码后的网格和纹理进行渲染。此外,该播放器可以响应于用户的动作(诸如鼠标拖动、手指捏放等)来移动、缩放或旋转全息图。
在一些实施方式中,方法200包括使用网格解码器122的网格解码过程。网格解码器可以用于将压缩的网格序列解码成网格帧。网格解码器可以仅执行计算,并因此可以不与任何ui组件交互。网格解码器因此可以容易地从其它语言(例如,使用emscripten从c/c++)进行转码。网格解码器可以在单独的网络工作者(webworker)上运行,使得网格解码器不会在主线程上阻塞cpu。
在一些实施方式中,方法200包括使用网格加载器124的网格下载过程124。网格加载器管理压缩的网格序列从远程服务器160的下载,并将下载的网格序列存储在存储缓冲器中,在存储缓冲器中网格序列等待解压缩和渲染。网格加载过程可以同时地、异步地加载多个网格序列,并且这些网格序列可以具有或不具有不同的优先级。
在一些实施方式中,方法200还包括使用网格解码器管理器124从网格加载器124请求压缩的网格字节,并且使用网格解码器122(例如根据需要且异步地)来解码压缩的网格字节。
网格解码器管理器124可以从网格缓冲器204检索解码的网格数据,并将解码的网格数据提供给播放器管理器128。
播放器管理器128可以对纹理视频进行解码,并从网格解码器管理器128请求相应的解码的网格,解码的纹理视频和解码的网格都可以发送到渲染器130。播放器管理器128可以保持网格和纹理之间的同步。
渲染器130从播放器管理器128获取解码的网格(该解码的网格可以包括顶点、三角形索引和纹理坐标)和视频帧,并使用例如webgl渲染接合来在html5画布上对解码的网格进行渲染。渲染器130使相机对象曝光以允许对渲染结果进行外部控制。
相机控制器还可以用于检测用户动作(例如鼠标拖动、鼠标滚动、手指移动、手指捏放(在台式计算机或移动设备上)),并从渲染器设置相机对象的参数,使得用户能够与经渲染的全息图交互。
还可以提供异步的网格下载和解码。压缩的网格序列为驻留在远程服务器106处的小的二进制文件,每帧一个文件。解码后的网格(顶点、三角形索引和纹理坐标)被存储在javascript阵列缓冲器(javascriptarraybuffer)中并且可能相对较大(每帧约1mb)。
如图2所示,网格加载器可以从远程服务器下载压缩的网格数据,并且将压缩的网络以二进制字节存储在下载缓冲器202中;网格解码器管理器从下载缓冲器中获取二进制字节,将二进制字节解码成解码后的网格,并将解码后的网格存储在网格缓冲器204中。
由于存储器的限制,在下载后可以将下载的压缩的网格序列保留在缓冲器中很长一段时间,而解码后的网格序列可能太大而无法保留很长一段时间。因此,在一些实施方式中,一旦播放器准备就绪后,网格加载器就可以开始下载压缩的网格序列;相反,网格解码器管理器可以根据需要或仅在满足预定条件时,对网格进行解码。
例如,网格解码器管理器可以接收来自播放器管理器的一个或多个解码请求,该解码请求可以包括如下数据,该数据定义在不久的将来可以使用哪个网格帧。在接收到解码请求后,网格解码器管理器可以开始进行解码且比原始请求多解码几帧(例如,多解码5帧),并从网格缓冲器中移除先前解码的帧。
注意,由于网格解码器按顺序解码网格帧,因此,如果所请求的帧具有的帧号(例如,4)比上次请求中解码的帧的总帧数(例如,9)少,则网格解码器管理器可能需要从头开始重新开始解码,当内容从头开始播放时,可能发生这种情况。如果尚未从网格缓冲器准备好用于解码所需要的数据,则网格解码器管理器可以暂停处理并在预定时间段(例如,30ms)之后重试。
网格解码器管理器通过使用网格解码器在单独的线程中(例如,在另一主机线程中)进行解码。网格解码器管理器将解码请求转发到网格解码器,并通过消息传递接口(messagepassinginterface)来接收解码后的网格并将解码后的网格存储在网格缓冲器中。网格加载器和网格解码器管理器可以异步工作,以避免长时间阻塞主事件循环。
网格(mesh)和纹理(texture)之间的同步:播放器管理器使用html5视频元素加载纹理视频,并根据用户请求开始播放视频。由浏览器提供的该视频元素使用本机解码器(如果可以,则为硬件解码器)来解码视频,以提供更高的性能。该视频元素未被添加到dom并且在移动浏览器中将该视频元素设置为“playsinline”,因此该视频元素将对用户隐藏。
html5视频元素可能不提供用于精确确定当前帧号以完美同步网格和纹理视频的api。可以将“帧号位图案(framenumberbitpattern)”添加到纹理视频。对于每个纹理帧,可以将其帧号转换成16位的二进制数,然后转换成64×4的黑/白位图,每个位具有4×4个像素。然后将得到的位图覆盖在每个纹理帧的左上角。由于纹理图像的分辨率通常为1024×1024或更大,并带有黑色填充,因此小的覆盖图案对纹理的影响几乎为零。注意,每个位使用4×4的像素区域,以避免视频编码后的数据丢失。
播放器管理器在每个浏览器使用窗口请求动画帧(window.requestanimationframe)api重新绘制之前注册回调。在每个回调调用中,播放器管理器通过将视频元素的64×4的图案绘制到画布并解析来读取当前的视频帧号,将新的解码请求发送到网格解码器管理器,并且如果相应的网格在网格缓冲器处可获得,则调用“渲染器”以渲染网格和视频。另一方面,如果相应的网格在网格缓冲器中尚不可获得,则播放器管理器将暂时暂停视频(通过设置视频的当前时间)并等待下一次调用。
使用webgl进行渲染:渲染器可以使用webglapi对解码的网格和纹理视频进行渲染。有两种不同的实现方式是可用的。
在第一种实现方式中,渲染器将html5视频元素作为纹理直接传递给webgl引擎。不需要复制两次纹理,从而提高了系统性能。然而,一些浏览器不支持该功能,在这种情况下,渲染器诉诸于如下讨论的第二种实现方式。另外,由于在上一节中描述的在帧号检测之后将纹理上传到gpu而没有任何同步,因此网格和纹理可能会变得不同步。
在第二种实现方式中,渲染器将视频内容绘制到html5画布元素中,并将该画布元素作为纹理传递给webgl。该实现方式提供了良好的兼容性,但性能略有下降。因为在检测到帧号时,绘制到画布的过程已经完成。在该第二种实现方式中,网格和纹理不会变得不同步。
图3为示出根据一些实施方式的用于渲染全息图的用户设备300(用户设备300可以为图1中示出的用户设备102a……用户设备102d中的任一用户设备)的框图。在一些实施方式中,用户设备300包括一个或多个处理单元cpu302(也称为处理器)、一个或多个网络接口304、用户接口305、存储器306以及用于将这些部件互连的一个或多个通信总线308。通信总线308可选地包括使系统部件互连并控制系统部件之间的通信的电路(有时称为芯片组)。存储器306通常包括高速随机存取存储器(诸如dram、sram、ddrram)或其它随机存取固态存储设备,以及可选地包括非易失性存储器(诸如一个或多个磁盘存储设备、光盘存储设备、闪存设备)或其它非易失性固态存储设备。存储器306可选地包括一个或多个远离所述(一个或多个)cpu302定位的存储设备。存储器306或者替选地存储器306内的(一个或多个)非易失性存储设备包括非暂时性计算机可读存储介质。在一些实施方式中,存储器306或可替选地非暂时性计算机可读介质存储以下程序、模块和数据结构或其子集:
●操作系统310,该操作系统310包括用于处理各种基本系统服务和用于执行硬件相关任务的程序;
●网络通信模块(或指令)312,该网络通信模块(或指令)312用于经由一个或多个网络接口304(有线或无线)或通信网络104(图1)将用户设备102与其它设备(例如,远程服务器106和用户设备102a……用户设备102d)连接;
●网格解码器122;
●网格加载器124;
●网格解码器管理器126;
●播放器管理器128;
●渲染器130;以及
●相机控制器132。
在一些实施方式中,用户接口205包括输入设备(例如,键盘、鼠标、触摸板、轨迹板和触摸屏)以供用户与设备300交互。
在一些实施方式中,上述的一个或多个元素被存储在一个或多个前述的存储设备中,并且与用于执行上述功能的指令集相对应。上面所述的模块或程序(例如,指令集)不需要被实现为单独的软件程序、程序或模块,并且因此这些模块的各个子集可以以各种实现方式进行组合或以其它方式重新布置。在一些实施方式中,存储器306可选地存储上述模块和数据结构的子集。此外,存储器306还可以存储上面未描述的其它模块和数据结构。
图4为示出根据一些实施方式的用于渲染全息图的远程服务器400(远程服务器400可以为图1中示出的远程服务器106)的框图。在一些实施方式中,远程服务器400包括一个或多个处理单元cpu402(也称为处理器)、一个或多个网络接口404、存储器406以及用于将这些部件互连的一个或多个通信总线408。通信总线408可选地包括使系统部件互连并控制系统部件之间的通信的电路(有时称为芯片组)。存储器406通常包括高速随机存取存储器(诸如dram、sram、ddrram)或其它随机存取固态存储设备,以及可选地包括非易失性存储器(诸如一个或多个磁盘存储设备、光盘存储设备、闪存设备)或其它非易失性固态存储设备。存储器406可选地包括一个或多个远离所述(一个或多个)cpu402定位的存储设备。存储器406或者替选地存储器406内的(一个或多个)非易失性存储设备包括非暂时性计算机可读存储介质。在一些实施方式中,存储器406或替选地非暂时性计算机可读介质存储以下程序、模块和数据结构或其子集:
●操作系统410,该操作系统410包括用于处理各种基本系统服务和用于执行硬件相关任务的程序;
●网络通信模块(或指令)412,所述网络通信模块(或指令)412用于经由一个或多个网络接口404(有线或无线)或通信网络104(图1)将远程服务器400与其它设备(例如,用户设备102a……用户设备102d中的任一者)连接;以及
●数据414,该数据414可以包括一个或多个全息图416或其一部分。
在一些实施方式中,一个或多个上面所述的元素被存储在一个或多个前述的存储设备中,并且与用于执行上述功能的指令集相对应。上述模块或程序(例如,指令集)不需要被实现为单独的软件程序、程序或模块,并且因此这些模块的各个子集可以以各种实现方式进行组合或以其它方式重新布置。在一些实施方式中,存储器406可选地存储上述的模块和数据结构的子集。此外,存储器406还可以存储上面未描述的其它模块和数据结构。
图5为示出根据一些实施方式的用于在网络环境中进行交互式3d纹理网格全息图渲染的方法500的流程图。方法500可以在用户设备(诸如移动设备或台式计算机)处实现。
在一些实施方式中,方法500包括使用网格解码器来执行一个或多个纯javascript程序以实时解码(502)一个或多个全息图;使用网格加载器同时下载和流传输(504)网格文件;以及从网格加载器请求(506)压缩的网格字节。
所述方法还可以包括使用网格解码器根据需要且异步地对压缩的网格字节进行解码(508);使用播放器管理器将用于传输到网格解码器的网格文件和纹理图文件(texturemapfile)同步(510);使用渲染器在html5画布上渲染(512)网格文件和视频帧;以及使用相机控制器检测(514)一个或多个用户动作并相应地做出反应。
压缩3d全息图
本发明还提供了用于压缩一个或多个全息图的技术。
i帧编解码器:图6为示出根据一些实施方式的i帧编解码器的示例性工作流程600的流程图。所述i帧编解码器可以包括如下所述的编码器和解码器。
i帧编解码器-编码器
1.顶点坐标
(1)重新排序
为了利用坐标的“连续性”(对于任何对象的3d网格模型,在3d空间中连接的顶点彼此接近),编码器首先对顶点进行重新排序,以使列表中的每个顶点都在3d空间中非常接近该顶点的前一个顶点。该步骤可以提高编码效率。
在文件中存在模型的顶点的列表。基本上,从列表中的任一顶点(通常只选择第一个顶点)开始,编码器基于顶点的连接性进行深度优先搜索,并按找到这些顶点的顺序将这些顶点推入新的列表。
为此,编码器维护一个fifo(先进后出)堆栈,该堆栈初始为空。编码器首先选择任一顶点,将该顶点标记为找到,并将该顶点推入堆栈。然后,每次编码器从堆栈中拉出一个顶点时,编码器都会找到该顶点的连接的所有未标记的相邻顶点,将这些顶点标记为已找到,将这些顶点按从最远到最近的顺序推入堆栈中,并将该顶点放到新列表的后面。一旦堆栈变为空(这意味着已经找到并标记了一个连接分量(connectedcomponent)的所有顶点,编码器应转到下一个连接分量),则编码器挑选未被标记的任一顶点作为新起点。
编码器重复该步骤,直至标记了所有顶点。保持顶点的新排序和旧排序之间的对应关系,这是因为需要对uv坐标、法线和连接以及p个帧中的那些坐标、法线和连接进行相同的重新排序。在完成重新排序之后,可以开始量化过程。
(2)量化
将输入坐标数据表示为32位浮点数,通常在负几千毫米到几千毫米的范围内。因此,实际上需要少得多的位来表示高分辨率的模型,因此使用量化来实现高压缩率。由于数据具有明确的物理意义(3d坐标),因此编码器对这些数据进行量化以得到超过所需的精度的明确控制,然后执行无损编码。
用户输入用于压缩的精度参数(即,允许的最大误差)。编码器首先将所有坐标除以2倍精度,然后去除小数部分。将保留的整数部分准备用于无损编码。
(3)差异化操作与格伦布(golomb)编码
由于重新排序步骤,现在新列表中的各个顶点都非常接近其之前的相邻顶点。因此,编码器不存储各个坐标,而是存储与前一个坐标的差值,这具有窄得多的动态范围。
可以发现,从之前的步骤获得的差值大致遵循双边指数分布。因此,对于分布的每一边,编码器都进行格伦布编码,排除那些偏离中心太多的地方,编码器使用固定数量的位来表示所述中心。
2.uv坐标
注意,uv坐标已经相应于顶点坐标的重新排序而重新排序。然后,uv坐标的编码遵循与顶点坐标相同的方式——量化、差异化、格伦布编码,因为对于3d空间中的两个相邻点,这两个相邻点的uv坐标通常彼此接近。
3.连接
每个连接由3个或更多数字组成,每个数字都是一个顶点的id。注意,顶点已重新排序,因此应该为各个连接分配相应的新顶点的id。现在编码器以与顶点完全相同的方式对连接进行重新排序。在重新排序之后,在连接中出现的顶点的id可能已经在先前的连接(或多个先前的连接之一)中出现。这意味着不需要存储顶点id,而是存储该id之前出现的最近的相对位置(如果有的话),否则存储该id本身(还可以存储与一些之前的id的差值)。这种方案极大地减少了存储信息所需要的位的数量。
4.法线
顶点的法线是用于3d模型的特殊信息,因为通常可以利用顶点坐标和连接以典型的方式来计算这些法线——顶点的法线是具有这些顶点的面的平均,且由面的面积加权。因此,如果法线确实是通过这种方式获得的,则不需要编码器存储关于这些法线的任何信息,否则,这些法线可以通过与顶点坐标相同的方式进行压缩。
在一些实施方式中,可以将通过上述编码过程产生的压缩数据注入到zip编码器,这带来大约10%的压缩的进一步增益。
i帧编解码器–解码器
解码器可以执行上述编码过程的逆过程。例如,解码器可以执行格伦布解码、去差异化等。此外,顶点的列表等不需要恢复到原始的排序,因为它实际上不会影响模型。
p帧编解码器:图7为示出根据一些实施方式的p帧编解码器的示例性工作流程700的流程图。
p帧编解码器–编码器
p帧的uv坐标和连接与i帧完全相同,因此只有顶点坐标和法线可能需要存储。
1.顶点坐标
在开始时,编码器根据i帧对顶点重新排序。只要帧速率等于或高于典型速率(25帧每秒(fps)),并且对象移动不太快(不比人的运动快很多),则相邻帧中的相应顶点通常就会彼此非常接近。因此,编码器通过先前帧中的相应顶点来预测顶点坐标,这可以称为运动预测。
一阶运动预测器仅通过前一帧中相应顶点的坐标(量化后)来预测顶点的坐标。然后,编码器从其预测值中获取真实坐标(量化后)的差值,并使用格伦布编码以与i帧相同的方式存储这些差值。
2.法线
类似地,如果可以在解码器处以典型方式来计算法线,则不需要存储任何信息。否则,以与顶点坐标相似的方式对法线进行编码(与前一帧的差异的格伦布编码)。
在一些实施方式中,可以将通过上述编码过程产生的压缩数据注入到zip编码器,这带来大约10%的压缩的进一步增益。
p帧编解码器–解码器
解码器可以执行上述编码过程的逆过程。例如,解码器可以执行格伦布解码、去差异化等。此外,顶点的列表等不需要恢复到原始的排序,因为它实际上不会影响模型。
图8为示出根据一些实施方式的用于压缩和解压缩全息图的示例性计算设备(该计算设备可以为图1中示出的远程服务器106)的框图。在一些实施方式中,远程服务器800包括一个或多个处理单元cpu802(也称为处理器)、一个或多个网络接口804、存储器806以及用于将这些部件互连的一个或多个通信总线808。通信总线808可选地包括使系统部件互连并控制系统部件之间的通信的电路(有时称为芯片组)。存储器806通常包括高速随机存取存储器(诸如dram、sram、ddrram)或其它随机存取固态存储设备,以及可选地包括非易失性存储器(诸如一个或多个磁盘存储设备、光盘存储设备、闪存设备)或其它非易失性固态存储设备。存储器806可选地包括一个或多个远离所述(一个或多个)cpu802定位的存储设备。存储器806或者替选地存储器806内的(一个或多个)非易失性存储设备包括非暂时性计算机可读存储介质。在一些实施方式中,存储器806或可替选地非暂时性计算机可读介质存储以下程序、模块和数据结构或其子集:
●操作系统810,该操作系统810包括用于处理各种基本系统服务和用于执行硬件相关任务的程序;
●网络通信模块(或指令)812,所述网络通信模块(或指令)812用于经由一个或多个网络接口404(有线或无线)或通信网络104(图1)将远程服务器400与其它设备(例如,用户设备102a……用户设备102d中的任一者)连接;
●i帧编解码器814,该i帧编解码器814可以包括:
●编码器822和解码器824;以及
●p帧编码解码器816,该p帧编码解码器816可以包括:
●编码器832和解码器834。
在一些实施方式中,一个或多个上面所述的元素被存储在一个或多个前述的存储设备中,并且与用于执行上述功能的指令集相对应。上述模块或程序(例如,指令集)不需要被实现为单独的软件程序、程序或模块,并且因此这些模块的各个子集可以以各种实现方式进行组合或以其它方式重新布置。在一些实施方式中,存储器806可选地存储上述模块和数据结构的子集。此外,存储器806还可以存储上面未描述的其它模块和数据结构。
图9为示出根据一些实施方式的用于压缩和解压缩全息图的示例性系统900的框图。
在一些实施方式中,计算设备910包括分段模块122、人体检测模块124、跟踪模块126、纹理化模块128和封装模块130。由这些模块中的每个模块提供的详细功能在下面参照相关附图进行描述。
用于动态3d重建的网格跟踪
动态3d重建可以产生3d网格序列,每个3d网格序列都是从观察到的每帧数据重建的。因此,不同的3d网格可以具有独立的连接,这使得很难压缩网格序列,并且在序列被回放时也可能导致抖动。
在本发明中提供了基于网格跟踪的动态3d重建过程。该过程可以将每帧重建的3d网格序列作为输入,并输出跟踪的网格序列。跟踪的网格序列可以包括多个组(组也称为子序列),包含相同组的网格共享相同的连接。
图10为示出根据一些实施方式的用于动态3d重建和跟踪的方法1000的框图。
在一些实施方式中,所述方法100包括关键帧选择过程(1004)。关键帧选择过程针对每个输入网格计算一分数(score)(1002),并且在一些情况下,从未跟踪的网格中选择具有最高分数的一个网格作为关键帧。在计算分数时,可以考虑三个因素:网格连接分量的数量、网格种类(genus)和网格面积area。
可以如下计算分数:
score=f(cc,genus,area)
其中,f(·,·,·)为连接分量的数量、种类和面积的函数。函数f(·,·,·)为网格连接分量数量的单调递减、网格种类的单调递减和网格面积的单调递增,这意味着具有小的连接分量数量、少的种类和大的面积的网格具有最高的得分。
在一些实施方式中,方法1000还包括非刚性配准过程(1006)。非刚性配准模块使关键帧网格变形以匹配附近的输入网格。变形的网格可以称为被跟踪的网格。以升序和降序两者执行从关键帧到附近帧的非刚性配准操作,直到满足组切换条件或已跟踪了所有的附近帧。通过使用迭代最近点(iterativeclosestpoint,icp)方法解决优化问题来实现非刚性配准。
在一些实施方式中,方法1000还包括子序列切换过程(1008)。与输入网格相比,被跟踪的网格可能具有大的对准误差,或者被跟踪的网格的质量严重下降,这两者中的任一者都可以触发组切换过程。注意非刚性配准是以升序和降序两者执行的,而组切换操作将非刚性配准过程以其当前顺序停止。如果升序和降序都停止,则方法1000返回关键帧选择步骤1004。可以重复上述过程,直到跟踪所有的输入网格。
这三个模块的详细操作列出如下。
关键帧选择过程:假设输入网格的帧索引为1、2、……、n并且将计算出的每个帧的分数表示为s1、s2、……、sn。每个帧都有指示该帧是否已被跟踪的状态指示符。在初始化步骤中,所有帧均保持在未被跟踪状态。将未被跟踪的帧的索引集表示为t。则关键帧选择操作可以表示为:
这意味着从未被跟踪的帧中选择具有最高分数的帧作为关键帧。
非刚性配准过程:在选择关键帧后,以递增和递减顺序两者执行非刚性配准以跟踪附近的帧。在本发明中以递增顺序为例。假设关键帧索引为n,并且已跟踪第i帧。可以计算从关键帧到第(i+1)帧的变换。
非刚性变换由k个嵌入式变形节点(embeddeddeformationnode,ednode)来描述,该嵌入式变形节点是通过对关键帧网格进行采样而获得的。每个ednode具有3×3的仿射矩阵ak和3维平移tk。要求解的参数构成集合
并且其法线nm被变换成:
其中,
注意,对ednode进行采样的方式、对ednode图的构建以及顶点与ednode之间的连接的方式对于非刚性配准的执行至关重要。在本发明中,对网格上的ednode进行均匀采样,并考虑测地距离和欧几里得(euclid)距离两者来确定连接和权重。
具体地,对关键帧网格上的ednode进行均匀采样。每个ednode随机地位于网格的面上,且其概率与该面的面积成比例。由于ednode位于面上,因此ednode的测地距离由特定面的测地距离表示。ednode图是通过将每个ednode连接到最近的kneighborednode来构建的,其中距离是通过测地距离测量的。在相同测地距离的条件下,考虑具有最小欧几里得距离的ednode。在构建ednode图之后,可以计算连接的ednode之间的平均欧几里得距离,并将其称为σ。
然后,将每个网格顶点连接到具有最小欧几里得距离的nneighborednode,并且网格顶点与所连接的ednode之间的测地距离应小于阈值η。该阈值可以防止将网格顶点连接到遥远的ednode。在确定连接之后,将权重计算为:
其中,z为确保
非刚性变换是通过求解如下优化问题而获得的:
e(g)=λfitefit+λrigiderigid+λsmoothesmooth+λcorrecorr
假设已经确定了从关键帧到第i帧的非刚性变换并将其表示为
这里的efit为拟合误差项,并表示为:
其中,v′m和n′m表示第m个网格顶点的变换位置和法线。x为在输入的第(i+1)帧网格上到v′m的最近点。erigid为刚性项,用于约束仿射矩阵δak的刚性,并表示为:
esmooth为空域平滑度项,用于进行由δg平滑度描述的变换,并表示为:
注意,
最后一项ecorr是对应关系项。可以通过如光流或人体姿势之类的技术来获得对应关系信息。该对应关系信息描述了第i帧中的一些3d点与第(i+1)帧中的一些3d点之间的匹配关系,并表示为
然后,变换的起点
其中,sm为连接到
在本发明中,可以使用迭代最近点(iterativeclosestpoint,icp)方法来估计非刚性变换。具体地,首先使用当前变换δg计算变换后的网格顶点。然后获得第(i+1)帧输入网格中的最接近点。接下来,求解优化问题e(g)以更新δg。重复上述过程直到满足一些条件。注意,可以使用如高斯-牛顿(gaussian-newton)方法的非线性的优化算法来求解优化问题e(g)。
可以实现多个特征以提高估计非刚性变换的准确度。
松弛刚性项和空间平滑度项。在迭代过程中,将大的值设置为λrigid和λsmooth。当能量的值e(g)在迭代过程中几乎保持不变(例如,
滤除拟合误差项。注意,拟合误差项是通过在第(i+1)帧输入网格中找到最近点来计算的。一些不期望的项可能降低性能。将不良项滤除以提高鲁棒性。可以使用距离过滤器、法线过滤器和深度过滤器。具体地,对于距离过滤器,当v′m和x之间的欧几里得距离大于阈值时,该v′m被滤除。对于法线过滤器,当法线n′m和x的法线之间的角度大于阈值时,该n′m被滤除。对于深度滤波器,将点v′m投影到观察到的深度图,读取深度值并将其重新投影以获得3d位置v″m。如果v′m和v″m之间的欧几里得距离大于阈值,则该点v′m被滤除。
组切换过程:该组切换过程可以用于确定是否满足跟踪终止条件。当满足一个或多个特定条件时,跟踪过程终止。终止条件可以包括以下条件。
遇到先前跟踪的网格。例如,在当前过程中,可以跟踪第i帧。如果之前已经跟踪过第i+1帧,则跟踪过程可以终止。
拟合误差条件。对于变换后的网格顶点v′m,计算目标网格的最接近点x。如果v′m和x之间的欧几里得距离大于阈值(称为拟合误差阈值),则将v′m标记为拟合错误顶点。如果拟合错误顶点的最大连接分量的大小大于阈值(称为拟合错误连接分量大小阈值(fittingerroneousconnectedcomponentsizethreshold)),则跟踪过程终止。类似地,对于目标网格的每个顶点um,计算变形网格上的最接近顶点y。如果um和y之间的欧几里得距离大于拟合误差阈值,则将um标记为拟合错误顶点。如果错误顶点的最大连接分量的大小大于拟合错误连接分量大小阈值,则跟踪过程终止。注意,拟合误差也可以使用点到面的距离(例如||n′m(v′m-x)||)来测量。
面拉伸条件。对于变形网格的每个面,如果其拉伸大于预定义的阈值(称为拉伸阈值),则将其标记为拉伸错误面。如果拉伸错误面的最大连接分量的大小大于阈值(称为拉伸错误连接分量大小阈值(stretcherroneousconnectedcomponentsizethreshold)),则可以终止跟踪。拉伸是通过面仿射矩阵的f-范数(f-norm)来测量的。
面翻转条件。对于变形的网格,如果从面中心点开始的沿反向面法线方向(inversefacenormaldirection)的射线不与该网格相交,则将该面标记为翻转错误。如果翻转错误面的最大连接分量的大小大于阈值(称为翻转错误连接分量大小阈值(flippmgerroneousconnectedcomponentsizethreshold)),则可以终止跟踪。注意,仅当关键帧网格为闭合网格时,翻转条件才适用。
泊松曲面重建
泊松曲面重建(psr)适用于3d重建,其涉及从定向点样本创建水密网格曲面。传统的psr算法可能遇到以下技术难题:第一,“隆起(bulging)”伪影经常出现在图形数据丢失的区域;第二,整个空间采用相同的重建深度,因此不支持特定区域处的高深度的曲面重建;以及第三,可能无法支持具有低厚度的对象(例如,薄的对象)的曲面重建。
本发明提供了针对上述技术难题的技术解决方案。例如,第一,利用轮廓信息的形状来补偿丢失的数据,从而减少或消除“隆起”伪影;第二,增加特定区域处的重建深度,以提高曲面重建精度;以及第三,沿法线方向将薄对象的点移动一小段距离,这使得可以重建薄对象的两侧。注意,这些技术解决方案可以单独应用,也可以相互结合应用。
图11为示出根据一些实施方式的用于泊松曲面重建的示例性方法1100的流程图。方法1100可以适用于减少或消除图形数据丢失区域处的“隆起”伪影。
示例性方法可以包括首先利用输入点云(inputpointcloud)解决泊松曲面重建问题并获得指示符功能。然后基于来自轮廓信息的形状来识别“隆起”区域。对于每个检测到的“隆起”区域,可以用来自轮廓网格的形状上的采样点来补偿原始点云。可以应用另一泊松曲面重建来补偿点云。
在一些实施方式中,方法1100可以包括以下步骤。可以使用现有的psr技术从现有的点云中识别(1102)出网格曲面。然后从网格曲面中识别(1104)出“隆起”区域。由于“隆起”效应是由于缺少相关图形数据而导致的,因此可以使用来自轮廓信息的形状来检测(1106)“隆起”区域。来自轮廓的形状可以从多视角背景蒙版获得,这些背景蒙版一定位于真实曲面的外侧。
如果在重建曲面的内侧找到来自轮廓的形状,则表示相对应的区域正遭受由于缺少图形数据而导致的“隆起”效应。采样来自轮廓网格的形状上的点(例如,来自轮廓网格的形状的每个面的中心点)。
对于每个采样点,识别出其所属的体素。如果体素位于重建曲面的内侧(例如,由于该体素的八个栅格处的指示符函数值都小于曲面等值(isovalue)),则保留该采样点。
所有保留的采样点(1108)和原始点云(1102)均可以用于形成新的点云。然后在将psr方法应用于(1110)新形成的点云之后,可以从新的点云中生成(1112)新的曲面网格。
图12为示出根据一些实施方式的用于泊松曲面重建的示例性方法1200的流程图。可以应用方法1200以在选定区域处支持高深度的曲面重建。
示例性方法可以包括首先识别“重要”区域。在本发明中,如果区域对应于(例如,包括或标识)人体部位(诸如人脸或人手)或者该区域由用户特别标识,则该区域被认为是重要的。对于每个重要区域,可以采用高深度八叉树(octree)划分;并且通过求解psr问题来获得曲面网格。
在一些实施方式中,方法1200可以包括以下步骤。首先识别出(1202)重要区域(诸如人脸或手以及由用户选择的区域)。例如,可以基于一个或多个视角图像的投影点(或像素)来识别人脸区域。如果在预定数量的图像(如由用户或由计算机系统定义)上的投影点位于人脸区域内,则可以将该投影点标记为重要点。
对于每个重要点,可以在八叉树划分步骤(1206)中使用更高的深度。在一些情况下,要投影的总点数可能很大。为了加快投影过程,可以实施以下过程。首先,使用原始深度执行八叉树划分以生成栅格。然后将栅格投影到多视角图像。如果在预定数量的图像上投影的栅格位于人脸区域内,则可以将该栅格标记为重要栅格。如果体素的八个栅格都被标记为重要栅格,则将该体素标记为重要体素。还可以进一步对重要体素进行划分直到达到预定深度。
根据新划分的八叉树,可以使用传统的psr方法(1210)来构建(1212)曲面网格。
图13为示出根据一些实施方式的用于泊松曲面重建的示例性方法1300的流程图。可以应用方法1300以重建“薄”对象(例如,厚度低于预定值的对象)的曲面。
示例性方法可以包括首先检测具有薄对象的区域。然后,可以将薄对象的点沿法线方向在与其原始位置的预定接近度(也称为小距离)内移动。接下来,可以使用psr方法来求解平移的点云。
对于薄对象的点云,具有逆法线的点(这些点通常位于薄对象的两侧上)可以位于八叉树的同一体素处(1302)。通常将位于同一体素中的点的贡献求平均,这可能导致无法使用psr方法来构建曲面。
在一些实施方式中,方法1300可以包括以下步骤。识别(1304)具有薄对象的区域并将其沿法线方向移动,以使具有逆法线的点变成位于不同的体素处。具体地,可以执行八叉树划分。每个体素可以包括位于该体素内的多个点。
对于这些点中的每一对,如果法线的内部产生小于预定义的阈值(这可能意味着法线的角度大于该预定义的阈值),则将点对(point-pair)中的点标记为需要移动的点。
然后可以将已识别出需要移动的每个点在可由用户指定或由计算机系统自动计算出的邻近度内沿法线方向进行移动。例如,邻近度可以为体素的最小边缘长度。
在点被移动之后,然后可以使用psr方法(1308)基于移动后的点云来构建(1310)曲面网格。
低比特率的3d动态重建和传输
尽管动态3d重建技术不断发展,但仍然缺少支持实时重建和低比特流传输的强健技术。一些现有的方法(例如,融合4d(fusion4d)方法)只能提供2gbps的比特率,因此无法通过因特网(internet)进行流传输。
由于实时重建的约束,降低比特率的关键可能在于构建性能好、复杂度低的网格参数化模块、纹理化模块和压缩模块。
网格参数化是用于将3d网格投影到2d平面上的过程,其保持原始连接且每个面的失真较小。传统上,在具有不同类型的复杂模型的应用中,网格参数化需要大量复杂的计算和优化。一些现有的方法(例如,microsoft的uvaltas方法)需要长达十秒的时间才能生成正常大小的网格(例如,具有20000个面的网格)的uv坐标,这对于基于因特网(internet-based)的实时流传输应用是不令人满意的。
本发明中描述的技术可以提供以下技术优势。首先可以通过实施计算管线和并行计算来处理网格,而不导致明显的质量损失,从而实现更高的性能。其次,随着3d重建技术的快速发展,重建模型的精度已显著提高,从而使其是可选择的以按照先前的实现方式进行复杂的计算(诸如相机和模型微调)。减少或消除这些可选步骤可以进一步提高流传输性能。
图14为示出根据一些实施方式的用于低比特率的3d动态重建和传输的示例性方法1400的流程图。
可以使用多个相机(例如,相机1402a、1402b……以及1402n)来生成原始视频流。使用深度计算、对应关系计算、分段、和先前计算(例如,1404a、1404b……和1404n),可以将包括在每个视频流中的数据融合在一起,并可以根据融合的数据来重建(1406)网格。
然后可以应用(1408)网格跟踪以产生尽可能多的拓扑一致的网格。然后可以应用网格参数化(1410)、纹理化(1412)和网格压缩(1414)。
图15为示出根据一些实施方式的用于网格参数化的示例性工作流程1500的框图。工作流程1500可以包括以下步骤:采样、划分、片段清理(segmentclean)、参数化和封装。
在一些实施方式中,首先在网格曲面上执行(1502)非均匀采样。在卷曲的(例如凹凸不平的或非平坦的)区域上采样更多的点(1504)可以产生平滑的盘状片段,这可以产生更好的参数化结果。
至于划分部分(1506),基于每个平面(facet)到采样点的距离和到采样平面的距离来对该平面进行分类。在划分之后,收集片段,并将未连接的分量进行分离。执行进一步的清理步骤,以移除具有复杂几何形状的部分(例如,自交点、流形面和环形区域)。
然后将各个片段参数化。如果无法对某个片段进行参数化,则将该片段视为复杂的网格,并通过对该片段重复步骤1504、1506和1508将其分解为更简单的片段。复杂网格的总数通常很小,因此可以以高速完成参数化。然后可以使用贪心算法(greedyalgorithm)将生成的图表封装到单个图中。
下面更详细地描述示例性网格参数化过程。
采样:可以使用类似于快速网格抽取的算法对网格上的点进行采样。可以将网格划分成具有多细节层次(levelsofdetails,lods)的均匀栅格,从而形成树形结构。在从上到下的每个细节层次中,计算量化误差以测量栅格内三角形的复杂度。如果误差值小于预定义的阈值(或者它是最后一个细节层次),则将一个采样点放置在栅格内。否则,计算栅格内的每个子栅格的量化误差,以确定是否满足所述预定义的阈值。
以这些方式,基于曲面区域的复杂度来选择非均匀的采样点。可以使用误差阈值来控制采样点的数量。此外,可以优化算法以在gpu上并行执行。
划分:可以基于采样点划分网格。对于网格上的每个三角形,使用从三角形的顶点到采样点的距离(p2p距离)和从采样点到三角形的平面的距离(p2f距离)两者来将所有的三角形分类到一个相应的采样点。
计算p2f距离以使划分的结果更平坦,从而获得更好的参数化性能。在一些实施方式中,使用kd-tree(kd树)为每个三角形选择预定义数量(例如,8个)的最近的采样点(p2p距离),然后比较所选择的p2f距离。也可以优化划分算法以在gpu上并行执行。
分段:一些划分的片段可能包含复杂的几何形状,因此需要进一步划分,而其它划分的片段足够小且简单,以便可以将它们合并以形成更大的片段。
可以使用联合查找(union-find)算法来既识别复杂的片段又识别简单的片段。例如,网格中的每个三角形都标记有唯一标签(仅与其自身联合)。对于每条边,考虑每侧上的两个平面,当且仅当在分段过程中将这两个平面划分成同一片段时,这两个平面的联合才被合并。再次使用相同的联合,如果(1)两个片段都很小并且(2)产生的这两个片段的法线矢量大于预定义的阈值,则合并这两个片段。
参数化:可以应用最小二乘保角映射(leastsquareconformalmapping,lscm)来计算每个片段的2d坐标。如果一片段在该步骤失败,则将其发送回以进行重新采样和重新划分,直到可以对新片段进行参数化为止。在一些实施方式中,如果满足以下条件中的任一条件,则可以认为片段的参数化失败:
■从lscm返回的拟合误差大于预定义的阈值;或者
■得到的2d坐标产生重叠(这可以使用opengl渲染管线进行检测)。
将图表封装到一个图中:该过程可以包括预计算过程和排列过程。
示例性预计算过程可以如下:
■在3d空间中(所有平面的总和)相对于每个图表的片段面积重新调整每个图表;
■根据每个图表的坐标在每个图表周围生成紧密的边界框;
■如果边界框的宽度大于其高度,则旋转该边界框;以及
■根据图表的面积从大到小将图表排在队列中。
示例性排列过程可以如下:
■从队列(该队列在预计算过程中产生)中选择一个或多个图表以形成最终图的第一行;
■将所选择的图表从左到右一个接一个地紧密排列而没有重叠;所选择的图表总数可以设置为所选图表总数平方根的一半;并且最终图的宽度受第一行的长度限制,且没有图表放置在最终图之外;
■更新所有封装的图表的边界框的轮廓,并更新图表队列直到队列为空,这意味着完成了排列过程;
■计算轮廓上的最小间隙:
●如果队列中存在一个图表,其边界框的较小宽度适合所述间隙,则将该图表放置在该间隙中并重复“排列所选择的图表”;
●如果没有图表可以适合所述间隙,则用其相邻的图表来填充该间隙并重复“排列所选择的图表”;
■将最终图的高度设置为等于轮廓的高度;计算所有顶点的最终坐标;以及相应地更新原始网格。
图16为示出根据一些实施方式的用于进行纹理化的示例性方法1600的流程图。
如下所述,方法1600不要求配置相机。在一些实施方式中,总共使用8到20个分辨率为2048*2048的相机来覆盖足够多的对象位置。为了捕获对象的细节,可以使用长焦距镜头以提供高频分量。精确的相机校准和同步以及高质量的色彩一致性和白平衡可以产生改善的结果。
方法1600可以包预处理步骤(1602),以便提供快速的计算结果。预处理可以包括:
■加载相机捕获的3d模型和rgb图像;
■使用外部矩阵和内部矩阵为每个相机计算深度图;
■将双边过滤器应用于深度图;以及
■基于过滤后的深度图计算深度的梯度图。
纹理化可以并行执行。在一些实施方式中,对于最终纹理图中的每个像素,使用gpu并行计算其颜色,如下:
■计算每个相机的权重,包括:
○计算像素对应的位置的法线(例如,像素的法线)与相机方向之间的角度(1604)。如果该角度大于90度,则将权重设置为零;
○计算像素对应的位置的深度(1606)。如果深度大于投影到相机的深度图上的位置的值(以及在一些实现方式中,偏差较小,例如1毫米),则将权重设置为零;以及
○将位置投影到梯度图上并确定其位置,这可以包括:
●在半径为10个像素的邻域中进行搜索(1608)。如果大于特定阈值(1cm)的值多于十个,则将权重设置为零;
●在半径介于10个像素和30个像素之间的邻域中进行搜索。如果没有大于阈值(1cm)的值,则将权重设置为像素的法线与相机方向之间的角度的余弦值;
●如果存在大于阈值的值,则确定到这些值的最短距离(称为d1),将权重设置为像素的法线与相机方向之间的角度的余弦值乘以因子s1(1610):
●如果像素位于相应相机的边界(40像素以内),则将乘以额外的因子s2(1612):
d2为到最近的图像边界的距离;以及
方法1600可以包括颜色混合步骤。最终颜色是基于相机rgb的混合结果产生的,该混合结果由上述计算的权重进行加权。如果使用长焦距相机,则应仅考虑其高频分量。可以应用通用4*4的高通滤波器来提取高频分量。
方法1600可以包括后处理步骤,例如图像修复步骤。例如,对于序列中每个帧,使用3d重建方法生成网格。将网格的颜色保存在相应的uv纹理图中。将纹理图从网格展开并分成多个图集。可以从场景的彩色照片中获得不完整的纹理图,将被遮盖的部分保留为“未知”。
时域图像修复可能需要将网格序列分成多组。每组可以包括一个或多个连续的帧。将组中的网格以相同的方式展开,以便将同一组中所有uv纹理图的相同位置的像素映射到正被重建的对象的同一部分。
然后可以根据针对每个组如下计算时域图像修复图案和时域图像修复蒙版。
对于纹理图中的每个像素,如果该像素在组中的所有帧中都是已知的或者在组中的所有帧中都是未知的,则在蒙版中将该像素标记为“假(false)”,这意味着不对该像素进行图像修复。
否则,在蒙版中将像该素标记为“真(true)”,并且可以对该像素进行图像修复;将所有已知帧的平均颜色存储在该组的图像修复图案中。也可以使用中间颜色或其它方法而不是平均颜色来确定图像修复颜色。
还可以在将时域图像修复图案应用于帧之前执行空域图像修复。示例性空域图像修复过程如下:
可以使用对纹理图进行下采样(这可以是可选的)以减少空域图像修复所需要的时间;
在3d网格的展开期间,一些顶点在纹理图中可以具有多个对应的uv。对于这些顶点,如果一些对应的纹理像素被标记为已知,一些标记为未知,则用已知像素的平均颜色填充未知像素;
将2d图像修复算法(例如,telea算法)应用于纹理图的每个图集上。图像修复限于一个图集内部。因此,在对像素进行图像修复时,所有参考像素均选自于同一图集,并且将不属于该图集的像素视为未知的;
重复展开过程和图像修复过程,直到没有更多像素可以进行图像修复;
扫描纹理图中的图集的边缘像素。在展开过程中,将图集边缘映射到网络上的纹理边界。对于从真实对象生成的闭合网格,每个边缘必定存在于2个不同的三角形中。图集的所述边缘对应于图集的另一边缘,并且对于图集的每个边缘像素,可以在纹理图中定位相应像素。如果边缘像素最初未知,并且在上述步骤中被修复,则将该边缘像素的颜色设置为其自身和其对应像素的平均颜色;
在展开过程之前,将未知的且不是图集边缘像素的所有像素标记为“未知(unkown)”,并重复上述图像修复过程;以及
如果进行了下采样处理,则对图像修复结果进行上采样,然后将图像修复区域从上采样后的纹理粘贴到原始纹理。
然后将时域图像修复图案应用于每帧的空域图像修复的输出。对于每个帧,识别在空域图像修复之前未知的且在相应组的时域图像修复蒙版中标记为“真”的所有像素。对于这些识别出的像素,应用泊松编辑方法(poissoneditingmethod)将颜色从时域图像修复图案混合到空域图像修复纹理图,以产生输出帧。
填充:可以将最终纹理图中的图表扩展具有边界颜色的10-30个像素。根据一些实施方式,示例性边界因子扩展1700在图17中示出。
图18为示出根据一些实施方式的用于低比特率的3d动态重建和传输的示例性计算系统1800的框图。在图18中所示且由如其它附图中的相同附图标记标识的那些部件(例如,用户设备120a-用户设备120d)的部件可以提供与那些部件相同或相似的功能。计算设备1810可以包括采样模块514、划分模块516、片段清理模块518以及参数化模块520。
计算设备1810可以执行参照图14-图17描述的低比特率的3d动态重建和传输功能中的一者或多者。
在移动设备上的移动混合现实内容的生成、显示和交互
增强现实(augmentedreality,ar)技术可以应用在移动设备上。例如,用户可以激活智能手机的相机,并且如果相机捕获了桌子,则用户可以以图形方式在桌子上放置卡通人物或彩虹。合成图像呈现为卡通人物或彩虹存在于现实世界中就像桌子的存在方式一样。
然而,生成具有动态内容(例如,不断做出动作的卡通人物)的ar内容或者与这类ar内容交互可能在技术上具有挑战性。
在本发明中,提供了捕获3d全息图/模型以使得能够创建3d动态混合现实内容的技术以及用于显示混合现实内容并用于使用户能够与所显示的内容进行交互的技术。
可以以至少两种方式来创建3d动态混合现实内容:性能捕获和运动捕获及重定目标。当执行运动捕获时,尤其是在创建模型时,可以提供两种不同的方式:自动装配预扫描3d模型以及使用单个图像或视频来拟合现有的模型。
图19为示出根据一些实施方式的用于在移动设备上进行混合现实内容处理的示例性方法1900的流程图。
如图所示,全身重建可以建立全身模型,然后进行骨骼装配(1902a、1904a和1906a);手部重建可以建立手部模型,然后进行手部装配(1902b、1904b、1906b);面部重建可以建立面部模型,然后进行面部装配(1902c、1904c和1906c);以及头发重建可以建立头发模型,然后进行头发装配(1902d、1904d和1906d)。通过使用自动装配方法,可以装配身体。也可以构建用户的手、面部和头发。
在构建这些模型后,可以使用基于icp的方法将这些模型配准并缝合在一起,以生成具有装配的身体、面部、手部和头发的t型(t-pose)人体模型。
图20为示出根据一些实施方式的用于在移动设备上进行混合现实内容呈现和交互的示例性方法2000的流程图。
方法2000(数据驱动的方法)使用单个图像或视频来拟合现有的模型。可以提供数据库,该数据库提供已经被装配的拓扑一致的3d人体模型。该数据库支持线性模型,因此通过更改一些参数可以调整模型的高度或重量。基于所述数据库,通过分析照片或视频,可以估算出人体、衣服、面部表情、手部和头发的参数。可以将这些参数作为输入提供给数据库,以生成具有装配的身体、面部、手部、衣服和头发的t型人体模型。通过这种方法生成的模型更具卡通性。
图21为示出根据一些实施方式的用于在移动设备上进行混合现实内容呈现和交互的示例性方法2100的流程图。
方法2100是一种动作说明方法,除了方法1900和方法2000之外,还可以使用方法2100。如图21所示,方法2100包括骨骼跟踪、表情跟踪、手部跟踪和头发跟踪。
图22为示出根据一些实施方式的用于在移动设备上呈现混合现实内容的示例性方法2200的流程图。
在将3d全息图放置(2204)在一些平面上之前,方法2200使用slam算法(2202)来生成整体空间的稀疏3d图。在步骤2206处,将3d动态全息图显示在移动设备上。
图23a为示出根据一些实施方式的用于与移动设备上呈现的混合现实内容交互的示例性方法2300的流程图。
方法2300可以使用slam算法来获得稀疏的3d图并将3d全息图放置到初始位置。然后,可以提供三种类型的交互:触摸屏交互、相机交互和对象交互。
触摸屏交互支持用户的单指触摸、多指触摸、用于设置路线和选择列表的触摸等,以控制全息图人物沿特定路线从一个位置到另一位置的移动。
相机交互是指当用户移动移动设备(例如,智能手机)时并且无论相机捕获的场景如何改变,全息图将保持在相机捕获的场景的中心。
对象交互可以包括检测在相机捕获的场景中发生的碰撞。当检测到另一对象正在从侧面方向或从顶部到底部进入场景时,方法2100可以产生全息图人物对此的反应。此外,该方法还支持高级动作(诸如抓取3d全息图人物)。
图23b为示出根据一些实施方式的用于与移动设备上的混合现实内容进行交互的示例性方法2304b的流程图。
图23c为示出根据一些实施方式的用于与移动设备上的混合现实内容进行交互的示例性方法2304a的流程图。
图23d为示出根据一些实施方式的用于与移动设备上的混合现实内容进行交互的示例性方法2304c的流程图。
图24为示出根据一些实施方式的用于与移动设备上的混合现实内容进行交互的示例性方法2400的流程图。
在方法2400中,智能手机的相机可以检测到人脸和另一对象。基于检测到的对象,该方法可以估计周围环境,例如用户是在餐厅(如果检测到约束椅)还是在教室(如果检测到书桌和黑板)。
在了解了周围环境之后,可以生成与周围环境有关的全息图。例如,在检测到有一个装有牛奶的杯子之后,可以生成跳入牛奶的全息图人物。再例如,在检测到用户正在伸出她的左手之后,可以生成看起来就像是爬到用户的左手上的猴子的全息图。
图形化地移除全息图中显示的头戴式耳机
头戴式显示器(head-mounteddisplay,hmd)技术发展中的技术进步已使全息通信具有更宽的视场(fieldofview,fov)、更高的分辨率和更低的延迟。然而,无论是虚拟现实hmd还是增强现实hmd都会遮挡用户头部或面部的至少一部分,使得在全息通信中重建用户的头部或面部的整体困难且低效。
在本发明中描述的技术可以图形化地修改全息图以从全息图中移除用户佩戴的hmd,从而使得用户的面部在全息图中可见。
为此可以实施两个特征。第一个特征是以3d对用户的面部建模,并预先针对每个眼睛方向生成纹理图。第二个特征是在检测到用户的眼睛方向、用户的面部和hmd的位置后,将用户的头部或面部的被hmd遮挡的部分用为透明hmd替换,并根据用户的眼睛方向显示用户的面部或头部。
图25为示出用于移除全息图中显示的头戴式耳机并使用户的面部可见的示例性方法2500的流程图。方法2500在执行时可以提供参照第一个特征描述的功能。
在步骤2502中,使用rgb-d传感器创建佩戴hmd的用户的3d模型。作为2502的一部分,用户在面向rgb-d传感器时可以显示一个或多个不同的面部表情;可以基于在2502中收集的用户的面部数据建立3d模型。
在2504中,针对用户的每个眼睛方向提取纹理图。作为该步骤的一部分,用户注视屏幕,并且该屏幕可以一次(例如从上到下以及从左到右)显示一个小点。用户保持头部不动,同时尝试跟踪小点的不同位置。
每当屏幕上显示小点时,用户都可以将她的眼睛转向小点,并且rgb-d相机将会拍摄用户眼睛的rgb图像和深度图像。在一些实施方式中,可以在大约100个不同的屏幕位置上显示该点,以便覆盖用户可以将其眼睛转向的足够多的方向。
在步骤2506中,基于在rgb图像中所示的用户的面部上检测到的深度图像和界标,可以使用icp算法将2d图像配准到3d模型。然后可以生成用于用户的每个眼睛方向的纹理图。
在步骤2508中,3d模型可以提供用户的眼睛方向和相应的纹理图之间的一个或多个链接。
图26为示出用于移除全息图中显示的头戴式耳机并使用户的面部可见的示例性方法2600的流程图。方法2600当执行时,可以提供参照第二特征描述的功能。
hmd可以跟踪用户的眼睛方向(2602);然后可以将用户的眼睛方向(2604)提供给3d模型。可以在连续的帧之间检测并跟踪在每个帧中的用户的眼睛方向,以在两个帧之间产生变形场。
还可以检测用户的嘴部的位置和hmd的位置(分别为2608和2616)。这可以通过使用机器学习算法或深度学习算法训练嘴部检测器和hmd检测器来进行。
使用icp算法,可以将单独的离线建模的人脸和hmd(例如,通过执行方法2500产生的)配准到全身模型。然后,根据用户面部的表情,离线建模的人脸解决了表情,从而相应地改变表情。
之后,可以从全身模型上图形化地移除用户的面部和hmd,并且可以将离线建模的面部模型和hmd模型放置在相同的位置。在一些实施方式中,在线建模的面部可以具有眼睛区域周围的纹理,而离线建模的hmd模型可以是透明的。
注意,离线系统和在线系统之间的纹理颜色可以不同。可以执行激情融合(passionintegration)以修正纹理的颜色但保留细节。最后,系统可以输出具有其纹理的全身模型(不包括面部和hmd)、以及面部模型和纹理及hmd的位置的信息。
一个示例性icp算法可以如下。可以构建如下能量函数:
e=ωgeg+ωcec+ωtet
eg为点云配准项:
m为当前帧的变换矩阵,b为用户特定的混合形状,wexp,i为帧i的表情权重的矢量,vk为混合形状下部面部顶点的索引且vk为目标点云中对应的最近点,以及p(,)测量了它们的点面距离。
ec为纹理配准项:
f为可以看到面部下部的所有相机的集合,vj为相机j中所有可见顶点的集合,gj为相机j中顶点vk的投影的图像梯度,t(vk)为纹理图像中的顶点vk的图像梯度。
et为时域平滑项:
图27示出了四个图像,这四个图像包括两个示出用户佩戴头戴式耳机设备(例如,hmd)的图像2702和图像2704,以及两个经图形化修改的示出用户没有头戴式耳机设备的图像2706和图像2708。
如图像2702和图像2704所示,用户的面部或头部的至少一部分被该用户所佩戴的hmd遮挡。
相反,在将参照方法2500和方法2600所描述的技术应用于图像2702和图像2704之后,hmd被图形化地移除并用透明部分替换,从而使得被hmd遮挡的用户的面部部分可见。
尽管图3、图4和图8分别示出了“用户设备300”、“远程服务器400”、“计算设备800”,但是图3、图4和图8旨在更多地作为可以存在于计算机系统中的各种特征的功能描述,而不是本发明所描述的实现方式的结构示意。在实践中,并且如本领域普通技术人员所认识的,可以将分开示出的项进行组合,并且可以将一些项分开。
对于在本文中描述为单个实例的部件、操作或结构可以提供复数个实例。最后,各种部件、操作和数据存储之间的边界在某种程度上是任意的,并且在特定示例性配置的上下文中示出了特定操作。功能的其它分配是可预期的,并且可以落入(一个或多个)实施方式的范围内。一般地,在示例性配置中呈现为分开部件的结构和功能可以实现为组合的结构或部件。类似地,呈现为单一部件的结构和功能可以实现为分开的部件。这些和其它变型、修改、添加和改进都落入(一个或多个)实施方式的范围内。
还将理解,尽管术语“第一”、“第二”等在本文中可以用于描述各种元件,但是这些元件不应受到这些术语的限制。这些术语仅用于区分一个元件和另一个元件。例如,第一相机可以称为第二相机,类似地,第二相机可以称为第一相机,而不改变描述的含义,只要所有“第一相机”的出现的都被一致性地重命名并且所有“第二相机”的出现都被一致性地重命名。第一相机和第二相机都是相机,但是它们不是同一相机。
本文中使用的术语仅出于描述特定实施方式的目的,且并不旨在限制权利要求。如在实施方式和所附权利要求的描述中所使用的,单数形式“一”和“该”也意图包括复数形式,除非上下文另有明确指示。还将理解,如本文所使用的术语“和/或”是指并涵盖一个或多个相关联的列出项的任一和所有可能的组合。还将理解,当在本说明书中使用术语“包括”和/或“包含”时,是指存在所陈述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或添加一个或多个其它特征、整数、步骤、操作、元件、部件、和/或其组合。
如本文中所使用的,术语“如果”根据上下文可以被解释为意指“当……时”或“一旦”或“响应于确定”或“根据确定”或“响应于检测到”,所陈述的先决条件为真。类似地,短语“如果确定(所陈述的先决条件为真)”或“如果(所陈述的先决条件为真)”或“当……时(所陈述的先决条件为真)”根据上下文,可以被解释为意指“一旦确定”或“响应于确定”或“根据确定”或“一旦测到”或“响应于检测到”,所陈述的先决条件为真。
上述描述包括体现示例性实施方式的示例性系统、方法、技术、指令序列和计算机机器程序产品。出于说明的目的,阐述了许多具体细节以便提供对本发明主题的各种实施方式的理解。然而,对于本领域技术人员来说将显而易见的是,可以在没有这些具体细节的情况下实践本发明主题的实施方式。一般地,没有详细示出公知的指令实例、协议、结构和技术。
出于说明的目的,已经参照具体实施方式描述了上述说明书。然而,上述示例性讨论并非旨在穷举或将实施方式限制为所公开的精确形式。鉴于上述教导,许多修改和变型是可行的。选取并描述实施方式是为了最佳地解释原理及其实际应用,从而使本领域的其它技术人员能够最好地利用实施方式并对各种实施方式进行各种修改以适用于预期的特定用途。
- 还没有人留言评论。精彩留言会获得点赞!