环境音频表示和相关联的渲染的制作方法
本申请涉及用于声场相关的环境音频表示和相关联的渲染的装置和方法,但不排他地涉及用于音频编码器和解码器的环境音频表示。
背景技术:
mpeg正在将沉浸式媒体技术标准化为mpeg-i。这包括用于各种虚拟现实(vr)、增强现实(ar)或混合现实(mr)用例的方法。mpeg-i分为三个阶段:阶段1a、阶段1b和阶段2。这些阶段的特征在于如何考虑3d空间中所谓的自由度。阶段1a和阶段1b考虑3dof和3dof+用例,而阶段2允许至少显著无限制的6dof。
在3d空间中,总共有六个自由度来定义用户可以在所述空间中移动的方式。此运动分为两类:旋转运动和平移运动(每个具有三个自由度)。旋转运动足以实现简单的vr体验,用户可以转动头部(俯仰、偏摆和翻滚)以从静态点或沿自动移动的轨迹来体验该空间。平移运动意味着用户还可以改变渲染的位置,即按照其意愿沿x、y和z轴移动。自由视点的ar/vr体验既允许旋转运动也允许平移运动。如上所述,通常使用术语3dof、3dof+和6dof讨论各种自由度和相关体验。3dof+介于3dof和6dof之间,它允许用户进行一些受限的运动,例如,3dof+可以认为是实现受限的6dof,其中用户坐着但可以将其头部朝各个方向倾斜。
参数化空间音频处理属于音频信号处理领域,其中使用一组参数描述声音的空间方面。例如,在从麦克风阵列进行参数化空间音频捕获时,型且有效的选择是从麦克风阵列信号中估计一组参数,例如,频带中声音的方向以及在频带中捕获的声音的方向性部分和非方向性部分之间的比率。众所周知,这些参数很好地描述了麦克风阵列位置处的捕获声音的感知空间特性。相应地,这些参数可以用于空间声音的合成,用于双耳式耳机,用于扬声器或其他格式,例如全景声(ambisonics)。
方向性的或基于对象的6dof音频通常能被很好地理解。它对许多类型的生产内容特别有效。然而,实时捕获或实时捕获和生产内容的组合需要更多特定于捕获的方法,这些方法通常至少不是完全基于对象的。例如,可以使用至少针对环境信号捕获和表示的参数化分析,来考虑全景声(foa/hoa)捕获或沉浸式捕获。这些格式对于表示6dof环境中的已有传统内容也很有价值。此外,基于移动的捕获对于用户生成的沉浸式内容可能变得越来越重要。这种捕获通常会生成参数化音频场景表示。因此,一般而言,基于对象的音频不足以覆盖所有用例、捕获中的可能性以及传统音频内容的利用。
技术实现要素:
根据第一方面,提供一种装置,包括用于以下的模块:定义至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联,并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向性范围相关联,其中,所述至少一个环境分量表示被配置为通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来被用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
所述方向性范围可定义角度范围。
所述至少一个环境音频表示还可包括以下项目中的至少一个:最小距离阈值,在该最小距离阈值之上,所述至少一个环境分量表示被配置为被用于渲染所述环境音频信号;最大距离阈值,在该最大距离阈值之下,所述至少一个环境分量表示被配置为被用于渲染所述环境音频信号;以及距离加权函数,其通过基于所述至少一个环境音频表示和所述收听者位置和/或方向处理所述相应扩散背景音频信号,来被用于通过6自由度或增强的3自由度渲染器来渲染所述环境音频信号。
所述用于定义至少一个环境音频表示的模块还可用于:获取第一麦克风阵列捕获的至少两个音频信号;分析所述至少两个音频信号以确定至少一个能量参数;获取与音频源相关联的至少一个接近音频信号;以及从所述至少一个能量参数中去除与所述至少一个接近音频信号相关联的方向性音频分量,以生成所述至少一个参数。
所述模块还可用于基于所述第一麦克风阵列捕获的所述至少两个音频信号以及所述至少一个接近音频信号来生成所述至少一个相应扩散背景音频信号。
所述用于生成所述至少一个相应扩散背景音频信号的模块还可用于以下至少一个:对所述第一麦克风阵列捕获的所述至少两个音频信号进行缩混;从所述第一麦克风阵列捕获的所述至少两个音频信号中选择至少一个音频信号;以及对所述第一麦克风阵列捕获的所述至少两个音频信号进行波束成形。
根据第二方面,提供一种装置,包括用于以下的模块:获取至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联,并且进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向性范围相关联;获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向;以及通过基于所述至少一个参数以及在所述6自由度或增强的3自由度音频场内的收听者位置和/或取向来处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号。
所述用于获取在6自由度或增强的3自由度音频场内所述至少一个收听者位置和/或取向的模块还可用于以下至少一个:基于所述6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向以及限定位置参数确定所述音频场内相对于所述限定位置的收听者位置,其中,用于通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向来处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号的模块还可用于以下中的至少一个:基于由所述音频场内的收听者位置相对于所述限定位置定义的距离在最小距离阈值之上来渲染所述环境音频信号;基于所述音频场内的收听者位置相对于所述限定位置定义的距离在最大距离阈值之下来渲染所述环境音频信号;以及基于应用于由所述音频场内所述收听者位置相对于所述限定位置定义的距离的距离加权函数来渲染所述环境音频信号。
所述用于获取在6自由度或增强的3自由度音频场内所述至少一个收听者位置和/或取向的模块还可用于基于所述6自由度或增强的3自由度音频场内的至少一个收听者位置以及限定位置参数来确定所述音频场内相对于所述限定位置的收听者位置,其中,用于通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号的模块还可用于基于相对于所述限定位置的收听者位置和/或取向在所述方向性范围内来渲染所述环境音频信号。
根据第三方面,提供一种方法,包括:定义至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联,并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向范围相关联,其中,所述至少一个环境分量表示被配置为通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
所述方向性范围可定义角度范围。
所述至少一个环境音频表示还可包括以下项目中的至少一个:最小距离阈值,在该最小距离阈值之上,所述至少一个环境分量表示被配置为被用于渲染所述环境音频信号;最大距离阈值,在该最大距离阈值之下,所述至少一个环境分量表示被配置为被用于渲染所述环境音频信号;以及距离加权函数,其通过基于所述至少一个环境音频表示以及收听者位置和/或方向来处理所述相应扩散背景音频信号,来被用于通过所述6自由度或增强的3自由度渲染器渲染所述环境音频信号。
定义至少一个环境音频表示还包括:获取第一麦克风阵列捕获的至少两个音频信号;分析所述至少两个音频信号以确定至少一个能量参数;获取与音频源相关联的至少一个接近音频信号;以及从所述至少一个能量参数中去除与所述至少一个接近音频信号相关联的方向音频分量,以生成所述至少一个参数。
所述方法还可包括基于由第一麦克风阵列捕获的所述至少两个音频信号和所述至少一个接近音频信号来生成所述至少一个相应扩散背景音频信号。
生成至少一个相应扩散背景音频信号还可包括至少以下之一:对所述第一麦克风阵列捕获的所述至少两个音频信号进行缩混;从所述第一麦克风阵列捕获的所述至少两个音频信号中选择至少一个音频信号;以及对所述第一麦克风阵列捕获的所述至少两个音频信号进行波束成形。
根据第四方面,提供一种方法,包括:获取至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并且进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向性范围相关联;获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向;以及通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号。
获取在6自由度或增强的3自由度音频场内所述至少一个收听者位置和/或取向还可包括基于所述6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向以及限定位置参数确定所述音频场内相对于所述限定位置的收听者位置,其中,通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号还可包括以下至少一个:基于由所述音频场内的收听者位置相对于所述限定位置定义的距离在最小距离阈值之上来渲染所述环境音频信号;基于由所述音频场内的收听者位置相对于所述限定位置定义的距离在最大距离阈值之下来渲染所述环境音频信号;以及基于应用于由所述音频场内的收听者位置相对于所述限定位置定义的距离的距离加权函数,来渲染所述环境音频信号。
获取在6自由度或增强的3自由度音频场内所述至少一个收听者位置和/或取向还可包括以下至少一个:基于所述6自由度或增强的3自由度音频场内的至少一个收听者位置以及限定位置参数来确定所述音频场内相对于所述限定位置的收听者位置,其中,通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号还可包括:基于相对于所述限定位置的收听者位置和/或取向在所述方向性范围内来渲染所述环境音频信号。
根据第五方面,提供一种装置,包括至少一个处理器和至少一个包括计算机程序代码的存储器,所述至少一个存储器和所述计算机程序代码被配置为与所述至少一个处理器一起致使所述装置至少:定义至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联,并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向性范围相关联,其中,所述至少一个环境分量表示被配置为通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来被用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
所述方向性范围可定义角度范围。
所述至少一个环境音频表示还可包括以下项目中的至少一个:最小距离阈值,在该最小距离阈值之上,所述至少一个环境分量表示被配置为被用于渲染所述环境音频信号;最大距离阈值,在该最大距离阈值之下,所述至少一个环境分量表示被配置为用于渲染所述环境音频信号;以及距离加权函数,其通过基于所述至少一个环境音频表示和所述收听者位置和/或方向处理所述相应扩散背景音频信号,来被用于通过6自由度或增强的3自由度渲染器来渲染所述环境音频信号。
被致使所述定义至少一个环境音频表示的装置还可以被致使:获取第一麦克风阵列捕获的至少两个音频信号;分析所述至少两个音频信号以确定至少一个能量参数;获取与音频源相关联的至少一个接近音频信号;以及从所述至少一个能量参数中去除与所述至少一个接近音频信号相关联的方向音频分量,以生成所述至少一个参数。
还可使所述装置:基于由第一麦克风阵列捕获的所述至少两个音频信号和所述至少一个接近音频信号来生成所述至少一个相应扩散背景音频信号。
被致使生成所述至少一个相应扩散背景音频信号的装置还可被致使进行以下操作中的至少一个:对所述第一麦克风阵列捕获的所述至少两个音频信号进行缩混;从所述第一麦克风阵列捕获的所述至少两个音频信号中选择至少一个音频信号;以及对所述第一麦克风阵列捕获的所述至少两个音频信号进行波束成形。
根据第六方面,提供一种装置,包括至少一个处理器和至少一个包括计算机程序代码的存储器,所述至少一个存储器和所述计算机程序代码被配置为与所述至少一个处理器一起致使所述装置至少:获取至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联,并且进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向性范围相关联;获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向;以及通过基于所述至少一个参数以及在所述6自由度或增强的3自由度音频场内的收听者位置和/或取向来处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号。
被致使在6自由度或增强的3自由度音频场内获取所述至少一个收听者位置和/或取向的装置还可被致使:基于所述6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向以及限定位置参数确定所述音频场内相对于所述限定位置的收听者位置,其中,被致使通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向来处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号的装置还可以被致使执行以下操作中的至少一个:基于由所述音频场内的收听者位置相对于所述限定位置定义的距离在最小距离阈值之上来渲染所述环境音频信号;基于所述音频场内的收听者位置相对于所述限定位置定义的距离在最大距离阈值之下来渲染所述环境音频信号;以及基于应用于由所述音频场内所述收听者位置相对于所述限定位置定义的距离的距离加权函数来渲染所述环境音频信号。
被致使在6自由度或增强的3自由度音频场内获取所述至少一个收听者位置和/或取向的装置还可被致使进行以下操作中的至少一个:基于所述6自由度或增强的3自由度音频场内的至少一个收听者位置以及限定位置参数来确定所述音频场内相对于所述限定位置的收听者位置,其中,被致使通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号的装置还可被致使基于相对于所述限定位置的收听者位置和/或取向在所述方向性范围内来渲染所述环境音频信号。
根据第七方面,提供一种装置,包括:定义电路,被配置为定义至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向范围相关联,其中,所述至少一个环境分量表示被配置为通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
根据第八方面,提供一种装置,包括:获取电路,被配置为获取至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及针对音频场内限定位置的方向范围相关联;所述获取电路被配置为获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向;以及渲染电路,被配置为通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号。
根据第九方面,提供一种包括指令的计算机程序(或包括程序指令的计算机可读介质),该指令用于使装置至少执行以下操作:定义至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联,其中,所述至少一个环境分量表示被配置为用于通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
根据第十方面,提供一种包括指令的计算机程序(或包括程序指令的计算机可读介质),该指令用于使设备至少执行以下操作:获取至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联;获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向;以及通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号。
根据第十一方面,提供一种非暂时性计算机可读介质,其包括用于使设备执行至少以下操作的程序指令:定义至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联,其中,所述至少一个环境分量表示被配置为通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
根据第十二方面,提供一种非暂时性计算机可读介质,其包括用于使装置执行至少以下操作的程序指令:获取至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联;获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向;以及通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号。
根据第十三方面,提供一种装置,包括用于定义至少一个环境音频表示的模块,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联,其中,所述至少一个环境分量表示被配置为通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
根据第十四方面,提供一种装置,包括用于获取至少一个环境音频表示的模块,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联;用于获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向的模块;以及用于通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号的模块。
根据第十五方面,提供一种计算机可读介质,其包括用于使装置执行至少以下操作的程序指令:定义至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联,其中,所述至少一个环境分量表示被配置为通过基于所述至少一个环境音频表示以及收听者位置和/或方向处理所述相应扩散背景音频信号,来用于通过6自由度或增强的3自由度渲染器来渲染环境音频信号。
根据第十六面,提供一种计算机可读介质,其包括用于使设备执行至少以下操作的程序指令:获取至少一个环境音频表示,所述环境音频表示包括至少一个相应扩散背景音频信号和至少一个参数,所述至少一个参数与所述至少一个相应扩散背景音频信号相关联并进一步与至少一个频率范围或所述频率范围的至少一部分、至少一个时间段或所述时间段的至少一部分以及音频场内限定位置的方向范围相关联;获取6自由度或增强的3自由度音频场内的至少一个收听者位置和/或取向;以及通过基于所述至少一个参数以及所述6自由度或增强的3自由度音频场内的收听者位置和/或取向处理所述至少一个相应扩散背景音频信号,来渲染至少一个环境音频信号。
一种装置,包括装用于执行如上所述的方法的动作的模块。
一种装置,被配置为执行如上所述的方法的动作。
一种计算机程序,包括程序指令,用于使计算机执行如上所述的方法的。
一种计算机程序产品,其存储在介质上并可以使装置执行本文所述的方法。
一种电子设备,其可以包括如本文所述的装置。
一种芯片组,其可以包括如本文所述的装置。
本申请的实施例旨在解决与现有技术相关联的问题。
附图说明
为了更好地理解本申请,现在将通过示例的方式参考附图,其中:
图1示意性地示出了适于实现一些实施例的装置的系统;
图2示出了适于实现一些实施例的用于6dof音频的实时捕获系统;
图3示出了基于音频对象和环境音频表示的示例6dof音频内容;
图4示意性地示出了根据一些实施例的在时间和频率子帧上的环境分量表示(acr);
图5示意性地示出了根据一些实施例的环境分量表示(acr)确定器;
图6示出了根据一些实施例的环境分量表示(acr)确定器的操作的流程图;
图7示意性地示出了非方向性和方向性环境分量表示(acr)的示例;
图8示意性地示出了多声道方向性环境分量表示(acr)的示例;
图9示意性地示出了在6dof渲染位置处的环境分量表示(acr)组合;
图10示意性地示出了根据一些实施例的可以应用于渲染器的环境分量表示(acr)组合的建模;以及
图11示出了适于实现所示装置的示例设备。
具体实施方式
以下进一步详细描述用于在实现平移的沉浸式系统中提供音频的有效表示的合适的装置和可能的机制。
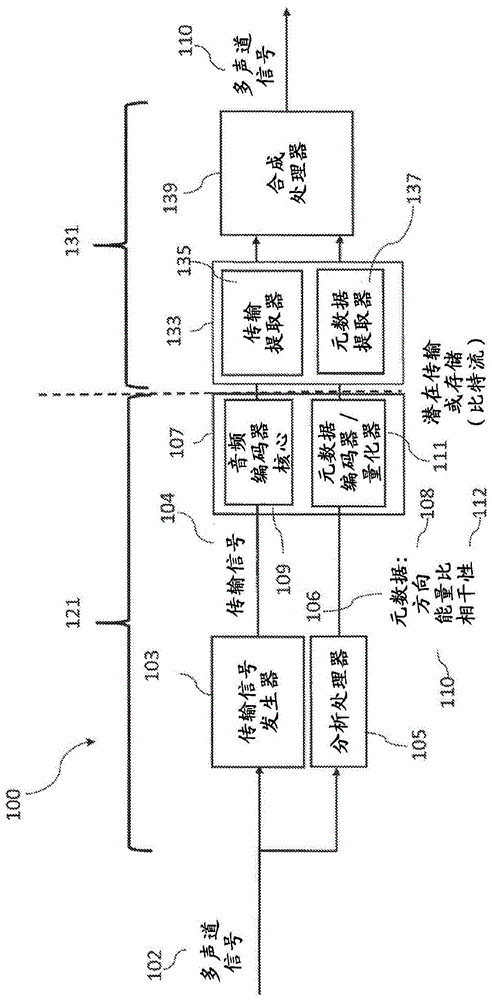
关于图1,其示出了用于实现音频捕获和渲染的示例装置和系统。系统100显示为具有“分析”部分121和“合成”部分131。“分析”部分121是从接收多声道扬声器信号到对元数据和传输信号编码的部分,而“合成”部分131是从对编码的元数据和传输信号解码到呈现重新生成的信号的部分(以多声道扬声器形式为例)。
系统100和“分析”部分121的输入是多声道信号102。在以下示例中,描述了麦克风声道信号输入,但是可以在其他实施例中实现任何合适的输入(或合成多声道)格式。例如,在一些实施例中,空间分析器和空间分析可以在编码器外部实现。例如,在一些实施例中,可以将与音频信号相关联的空间元数据作为单独的比特流提供给编码器。在一些实施例中,空间元数据可以被提供为一组空间(方向)索引值。
多声道信号被传递到传输信号发生器103和分析处理器105。
在一些实施例中,传输信号发生器103被配置为接收多声道信号,并生成包括确定数量的声道的合适的传输信号并输出传输信号104。例如,传输信号发生器103可以被配置为生成多声道信号的2音频声道缩混。所述确定的声道数量可以是任何合适的声道数量。在一些实施例中,传输信号发生器被配置为以其他方式(例如通过波束成形技术)来选择或组合输入音频信号到确定数量的声道,并将它们作为传输信号输出。
在一些实施例中,传输信号发生器103是可选的,并且多声道信号以与该示例中的传输信号相同的方式、未经处理地被传输到编码器107。
在一些实施例中,分析处理器105还被配置为接收多声道信号并分析信号以生成与多声道信号相关联并因此与传输信号104相关联的元数据106。分析处理器105可以被配置为生成元数据,该元数据可以包括针对每个时频分析间隔的方向参数108、能量比参数110以及相干参数112(在一些实施例中,还包括扩散性参数)。在一些实施例中,方向参数、能量比参数和相干参数(以及扩散参数)可以被认为是空间音频参数。换句话说,空间音频参数包括旨在表征由多声道信号(或通常两个或更多个回放音频信号)创造的声场的参数。
在一些实施例中,不同频带中的所生成参数可能不同。因此,例如,在频带x中,所有参数都被生成和发送,而在频带y中,仅其中一个参数被生成和发送,而此外,在频带z中,没有参数被生成或发送。在一个实例中,可以是对于某些频带,例如最高频带,出于感知原因,不需要某些参数。传输信号104和元数据106可以被传递给编码器107。
在一些实施例中,空间音频参数可以被分组或分离为方向性和非方向性(例如,扩散)参数。
编码器107可以包括音频编码器核心109,其被配置为接收传输(例如,缩混)信号104并生成这些音频信号的合适的编码。在一些实施例中,编码器107可以是计算机(运行存储在存储器和至少一个处理器上的合适的软件),或者是利用例如fpga或asic的特定设备。可以使用任何合适的方案来实现编码。编码器107还可以包括元数据编码器/量化器111,其被配置为接收元数据并输出信息的编码或压缩形式。在一些实施例中,在图1中虚线所示的传输或存储之前,编码器107可以进一步交织、多路复用到单个数据流或将元数据嵌入到编码的缩混信号内。可以使用任何合适的方案来实现复用。
在解码器侧,接收到的或检索到的数据(流)可以由解码器/解复用器133接收。解码器/解复用器133可以对编码流进行解复用,并将音频编码流传递给传输提取器135,传输提取器135被配置为对音频信号解码以获得传输信号。类似地,解码器/解复用器133可以包括元数据提取器137,元数据提取器137被配置为接收编码的元数据并生成元数据。在一些实施例中,解码器/解复用器133可以是计算机(运行存储在存储器和至少一个处理器上的合适的软件),或者是利用例如fpga或asic的特定设备。
解码的元数据和传输音频信号可以被传递给合成处理器139。
系统100的“合成”部分131还示出了合成处理器139,其被配置为接收传输信号和元数据,并基于传输信号和元数据以任何合适的格式重新创建呈多声道信号110形式(根据使用情况,这些格式可以是多声道扬声器格式,或者在某些实施例中,可以是任何合适的输出格式,例如用于耳机监听的双耳信号或全景声信号)的合成空间音频。
因此,总而言之,首先将系统(分析部分)配置为接收多声道音频信号。
然后,系统(分析部分)被配置为生成合适的传输音频信号(例如,通过选择或缩混一些音频信号声道)。
然后,系统被配置为对传输信号和元数据进行编码以用于存储/传输。
此后,这个系统可以存储/发送编码的传输信号和元数据。
系统可以检索/接收编码的传输信号和元数据。
然后,系统被配置为从编码的传输信号和元数据参数中提取传输信号和元数据,例如,对编码的传输信号和元数据参数进行解复用和解码。
系统(合成部分)被配置为基于提取的传输音频信号和元数据来合成输出的多声道音频信号。
基于对象的6dof音频通常能被很好地理解。它对许多类型的生产内容特别有效。实时捕获、或将实时捕获和生产内容结合在一起。例如,实时捕获可能需要更多特定于捕获的方法,这些方法通常至少不是完全基于对象的。例如,可以使用产生参数化表示的全景声(foa/hoa)捕获或沉浸式捕获。这些格式对于表示6dof环境中的已有传统内容也很有价值。此外,基于移动的捕获对于用户生成的沉浸式内容可能变得越来越重要。这种捕获通常会生成参数化音频场景表示。因此,一般而言,基于对象的音频不足以覆盖所有用例、捕获中的可能性以及传统音频内容的利用。
常规的参数内容捕获基于传统的3dof用例。
尽管方向分量可以由方向参数来表示,但是对环境(扩散)信号的关联参数处理可以以不同的方式进行并以如本文所述的实施例中所示的方式来实现。例如,这允许在针对3dof和6dof系统的渲染中将基于对象的音频用于音频源并将环境表示用于环境信号。
本文描述的实施例以这样的方式定义和表示声场的环境方面,使得用户相对于渲染器的平移能够被考虑以允许有效和灵活的实现方式和内容设计。否则,需要将环境信号再生成为几个基于对象的音频流,或者更可能地,再生成为声道床或至少一个全景声表示。这通常会增加音频信号的数量,并因此增加与环境音频相关联的比特率,这是不希望的。
通常描述点源(尽管它们可以具有大小)的传统的基于对象的音频不适合提供环境音频。
多声道床(例如5.1)限制了环境对用户运动的适应性,并且foa/hoa也面临类似的问题。另一方面,提供适应性,例如通过基于用户位置混合几种这种表示,不必要地增加了比特率,并且还潜在地增加了复杂性。
如本文更详细讨论的概念是对音频场景、音频环境以及音频能量表示的定义和确定。环境音频能量表示可以用于表示“非方向性”声音。
在以下公开中,该表示被称为环境分量表示(acr)或环境音频表示。它特别适用于6dof媒体内容,但可以更广泛地用于3dof和3dof+系统以及任何合适的空间音频系统中。
如本文中更详细所示,acr参数可用于定义虚拟环境(例如6dof环境)中的采样位置,并且还可以被组合以渲染在用户的给定位置(x、y、z)处的环境音频。基于acr的环境渲染可以依赖于或者独立于旋转。
在一些实施例中,为了组合几个acr以进行环境渲染,每个acr可以至少包括最大有效距离,但是也可以包括最小有效距离。因此,可以例如针对acr位置和用户位置之间的距离范围来定义每个acr渲染。
在一些实施例中,可以为6dof空间中的位置定义单个acr,并且可以基于至少描述扩散能量比(可以表示为“1-方向能量比”或在某些情况下表示为“1-(方向能量比+剩余能量”)的时频元数据,其中剩余能量不是扩散的也不是方向性的,例如麦克风噪声)。该方向性表示很重要,因为实际波形信号在高级处理(例如对捕获阵列信号进行声源分离)之后也可以包括方向性分量。因此,在一些实施例中,尽管acr元数据的主要目的是提供非方向性的扩散声音,但acr元数据也可以包括方向性分量。
在一些实施例中,就当从不同角度“看到/听到”时它可以具有不同的环境而言,acr参数(如上所述,其主要描述“非方向性声音”)可以进一步包括方向性信息。不同的角度是指相对于acr位置(以及旋转,至少在提供方向性信息的情况下)的角度。
在一些实施例中,acr可以包括一个以上的时频(tf)元数据集,该元数据集可以涉及以下至少一项:
不同的缩混或传输信号(acr的一部分)
缩混或传输信号的不同组合(acr的一部分)
相对于acr的渲染位置距离
相对于acr的渲染朝向
至少一个缩混或传输信号的相干特性
例如,在一些实施例中,通过为一个acr定义具有一个以上音频源的场景图,可以实现与所述信号/方面有关的一个以上的时频(tf)元数据集合。
在一些实施例中,acr可以是自包含的环境描述,使其贡献适用于6dof媒体场景中的用户位置(渲染位置)处的总体渲染。
因此,考虑到整个6dof音频环境,可以将声音分为非方向性部分和方向性部分。因此,虽然将acr用于环境表示,但可以针对突出的声音源(提供“方向性声音”)添加基于对象的音频。
本文所描述的实施例可以在用于3dof/6dof音频的音频内容捕获和/或音频内容创建/创作工具箱中实现,作为对音频编解码器的(3dof/6dof音频场景的至少一部分的)参数化输入表示,或者作为音频编码器和编码位流中的(编码模型的一部分的)参数化输入表示,或者在3dof/6dof音频渲染设备和软件中实现。
因此,这些实施例单独地或组合地覆盖了如图1所示的端到端系统的几个部分。
关于图2示出了用于mpeg-i6dof音频的合适的实时捕获装置301的系统视图。至少一个麦克风阵列302(在该示例中也实现vr相机)用于记录场景。另外,至少一个特写麦克风,在该示例中是麦克风303、305、307和309(可以是单声道、立体声或者阵列麦克风),用于记录至少一些重要的声源。由特写麦克风303、305、307和309捕获的声音可以通过空气304传播到麦克风阵列。在一些实施例中,来自麦克风的音频信号(流)被传输给服务器308(例如,通过网络306)。服务器308可以被配置为执行对准和其他处理(例如,声源分离)。阵列302或服务器308还执行空间分析并输出用于所捕获的6dof场景的音频表示。
在一些录音设置中,直接从声源(例如电吉他)馈送的相应信号可以代替或伴随特写麦克风信号中的至少一个。
在该示例中,音频场景的音频表示311包括音频对象313(在该示例中表示mx个音频对象)和至少一个环境分量表示(acr)315。整个6dof音频场景表示由音频对象组成,因此,acr被馈送到mpeg-i编码器。
编码器322输出符合标准的比特流。
在一些实施例中,acr实现方式可以包括一个(或多个)音频声道和相关联的元数据。在一些实施例中,acr表示可以包括声道床和相关联的元数据。
在一些实施例中,在合适的(mpeg-i)音频编码器中生成acr表示。然而,在一些实施例中,任何合适格式的音频编码器都可以实现acr表示。
图3示出了3dof/6dof音频(或者通常为媒体)场景中的用户。图的左侧示出了示例实现方式,其中用户401体验基于对象的音频(此处表示为位于用户401左侧的音频对象1403、位于用户401前方的音频对象2405以及位于用户401右侧的音频对象3407)和环境分量音频(此处表示为an,其中n=5、6、8、9,在图3中显示为a5402、a6404、a8408和a9406)的组合。
图3进一步显示了并行的传统基于声道的家庭影院音频,例如7.1扬声器配置(或图3右手侧所示的7.0,因为未显示lfe声道或重低音扬声器)。此时,图3显示了用户411和中央声道413、左声道415、右声道417、左环绕声道419、右环绕声道421、左后环绕声道423和右后环绕声道425。
尽管基于对象的音频的作用与其他6dof模型中的相同,但图3的图示描述了环境分量或环境音频表示的示例功能。当用户在6dof场景中移动时,环境分量表示(acr)的目标在于将随位置和时间变化的环境创建为取决于用户位置的“虚拟扬声器设置”。换句话说,从聆听体验的角度来看,环境(通过组合环境分量而创建)应始终以一定的非特定距离出现在用户周围。因此,根据该模型,用户无需进入场景中“基于场景的音频(sba)点”的直接邻近区域或确实精确的位置来听到它们。因此,在如本文所述的实施例中,可以从围绕用户的acr点构建环境(并且在一些实施例中,分别基于acr位置和用户之间的距离大于或小于确定距离阈值来开启和关断acr点)。类似地,在如本文所述的一些实施例中,可以根据用户的移动基于适当的权重来组合环境分量。
因此,在一些实施例中,音频输出的环境分量可以被创建为有效acr的组合。
因此,在一些实施例中,渲染器被配置为获取(例如,接收、检测或确定)关于哪些acr是有效的并且当前正在对用户当前位置(和旋转)处的环境渲染做出贡献的信息。
在一些实施例中,渲染器可以确定至少一个最接近用户位置的acr。在其他一些实施例中,渲染器可以确定不与用户位置重叠的至少一个最接近的acr。该搜索可以是例如最小数量的最接近acr、或用于与用户位置的最佳扇区匹配的固定数量的acr或任何其他合适的搜索。
在一些实施例中,环境分量表示可以是非方向性的。然而,在其他一些实施例中,环境分量表示可以是方向性的。
关于图4,示出了示例性环境分量表示。
参数化空间分析(例如,用于包括移动的通用多麦克风捕获的空间音频编码spac或元数据辅助的空间音频或masa,用于一阶全景声foa捕获的方向性音频编码dirac)通常将音频场景(通常是在单个位置采样)考虑为方向性分量非方向性或扩散声音的组合。
可以根据适当的时频(tf)表示来执行参数化空间分析。在图4的示例情况下,音频场景(实际移动设备)捕获基于20毫秒的帧503,其中该帧被分为4个5ms时间子帧,分别为500、502、504和506。此外,频率范围501被分成5个子带511、513、515、517和519,如t子帧510所示。因此,每个20ms的tf更新间隔可以提供20个tf子帧或图块(4×5=20)。在一些实施例中,可以使用任何其他合适的tf分辨率。例如,实际实现方式可以将24个或者甚至32个子带分别用于总共96个(4×24=96)或128个(4×32=128)个tf子帧或图块。另一方面,在某些情况下,时间分辨率可能较低,因此相应地降低了tf子帧或图块的数量。
图5示出了根据一些实施例的示例acr确定器。在该示例中,acr确定器配置有麦克风阵列(或捕获阵列)601,其被配置为捕获可以对其执行空间分析的音频。然而,在一些实施例中,acr确定器被配置为以其他方式接收或获得音频信号(例如,通过合适的网络或无线通信系统接收)。此外,尽管在该示例中,acr确定器被配置为通过麦克风阵列获取多声道音频信号,但是在一些实施例中,所获取的音频信号具有任何合适的格式,例如,全景声(一阶和/或更高阶的全景声)或一些其他捕获的或合成音频格式。在一些实施例中,可以采用如图1所示的系统来捕获音频信号。
acr确定器还包括空间分析器603。空间分析器603被配置为接收音频信号并且确定参数,例如针对每个时频(tf)子帧或图块的至少方向以及方向性和非方向性能量参数。在一些实施例中,空间分析器603的输出被传递到方向性分量去除器605和声源分离器604。
在一些实施例中,acr确定器还包括特写捕获元件602,其被配置为捕获近源(例如,音频场景内的乐器演奏者或扬声器)。来自特写捕获元件602的音频信号可以被传递该声源分离器604。
在一些实施例中,acr确定器包括声源分离器604。声源分离器604被配置为接收来自特写捕获元件602和空间分析器603的输出,并从分析结果中识别方向性分量(特写分量)。然后可以将这些分量传递给方向性分量去除器605。
在一些实施例中,acr确定器包括方向性分量去除器605,该方向性分量去除器605被配置为从空间分析器603的输出中去除例如由声源分离器604确定的方向性分量。以这种方式,有可能去除方向性分量,并且可以将非方向性分量用作环境信号。
因此,在一些实施例中,acr确定器可以包括环境分量发生器607,环境分量发生器607被配置为接收方向性分量去除器605的输出并生成合适的环境分量表示。在一些实施例中,这可以是非方向性acr的形式,其包括阵列音频捕获的缩混和能量的时频参数化描述(或多少能量是环境的——例如能量比值)。在一些实施例中,可以根据任何合适的方法来实现该生成。例如,通过应用非方向性能量的沉浸式语音和音频服务(ivas)元数据辅助空间音频(masa)合成。在这样的实施例中,方向性部分(能量)被跳过。此外,在一些实施例中,当创建内容或生成合成环境表示时(并且与如本文所述的捕获环境内容相比较),环境能量可以是所有环境分量表示信号。换句话说,在合成生成的版本中,环境能量值可以始终为1.0。
关于图6,其示出了根据一些实施例的如图5所示的acr确定器的示例操作。
因此,在一些实施例中,该方法包括获取音频场景(例如,通过使用捕获阵列)如图6通过步骤701所示。
此外,如图6通过步骤701所示,获取音频场景的特写(或方向性)分量(例如,通过使用特写捕捉麦克风)。
通过音频捕获装置或其他方式获得音频场景音频信号之后,然后对音频信号进行空间分析以生成合适的参数,如图6通过步骤703所示。
此外,获得音频场景的特写分量之后,然后将这些信号与音频场景音频信号一起处理,以进行声源分离,如图6通过步骤704所示。
确定声源之后,可以将它们应用于音频场景音频信号,以除去方向性分量,如图6通过步骤705所示。
以及,去除方向性分量之后,该方法然后可以生成环境音频表示,如图6通过步骤707所示。
在一些实施例中,acr确定器可以被配置为确定或生成方向性环境分量表示。在这样的实施例中,acr确定器被配置为生成acr参数,该acr参数包括与环境部分相关联的额外方向性信息。在一些实施例中,方向性信息可以涉及这样的扇区,对于给定的acr该扇区可以是固定的或者在每个tf子帧中该扇区是变化的。在一些实施例中,扇区的数量、每个扇区的宽度、每个扇区对应的增益或能量比因此可以针对每个tf子帧而变化。此外,在一些实施例中,一个帧被单个子帧覆盖,即,该帧包括一个或多个子帧。在一些实施例中,该帧是一个时间段,并且在一些实施例中,该时间段可以被划分成部分,acr可以与该时间段或该时间段的至少一部分相关联。
关于图7,其示出了非方向性acr和方向性acr的示例。图7的左手侧显示了非方向性acr801时间子帧示例。非方向性acr子帧示例801包括5个频率子带(或子帧)803、805、807、809和811,每个均具有关联的音频和参数。可以理解,在一些实施例中,频率子带的数量可以是时变的。此外,在一些实施例中,整个频率范围被单个子带覆盖,即,该频率范围包括一个或多个子带。在一些实施例中,频率范围或频带可以被划分成部分,acr可以与频率范围(频带)或频率范围的至少一部分相关联。
在图7的右手侧,显示了方向性acr时间子帧示例821。方向性acr时间子帧示例821以类似于非方向性acr的方式包括5个频率子带(或子帧)。每个频率子帧还包括一个或多个扇区。因此,例如,频率子带803可以表示为三个扇区821、831和841。这些扇区中的每一个还可以由关联的音频和参数表示。与扇区有关的参数通常是时变的。此外,可以理解,在一些实施例中,频率子带的数量也可以是时变的。
注意,可以将非方向性acr视为方向性acr的特殊情况,其中仅使用一个扇区(具有360度宽度和单个能量比)。因此,在一些实施例中,acr可以基于时变参数值在非方向性和方向性之间切换。
在一些实施例中,方向性信息描述了从相对于acr的特定方向所体验的每个tf图块的能量。例如,通过旋转acr或用户在acr上来回走动所体验的。
因此,例如,当使用方向性acr来描述6dof场景环境时,基于用户位置的随时间和位置变化的环境信号能够被生成为做贡献的环境分量。在这方面,时间变化可以是扇区或有效距离范围的变化之一。在一些实施例中,这是根据方向而不是距离来考虑的。有效地,在一些实施例中,可以假定扩散场景能量不取决于与场景中的(任意)对象样点有关的距离。
关于图8示出了多声道方向性acr示例。方向性acr包括三个tf元数据描述901、903和905。两个或更多个tf元数据描述可以涉及例如至少以下一项:
-不同的缩混信号(acr的一部分)
-缩混信号(acr的一部分)的不同组合
-相对于acr的渲染位置距离
-相对于acr的渲染取向
-至少一个下混信号的相干特性
特别是,本文将进一步详细讨论多声道acr和用户与acr“位置”之间的渲染距离的影响。
当考虑方向性信息时,采用多声道表示可能特别有用。任意数量的声道可以被使用,并且可以每额外声道地提供额外的优势。在图8中,例如,三个tf元数据901、903和905均覆盖所有方向。存在一种可能性,即相对于acr位置的方向可以造成例如声道的不同组合(根据tf元数据)。
在其他一些实施例中,相对于acr的方向可以选择使用(至少两个)声道中的哪个(至少一个)。在这样的实施例中,通常使用单独的元数据,或者替代地,所述选择可以至少部分地基于与每个声道有关的扇区元数据。然而,在一些实施例中,声道选择(或组合)可以是例如从n个声道中选择m个“最响的扇区”(其中m≤n并且其中“最响亮”被定义为最高的扇区能量比或最高的扇区能量结合信号能量和能量比)。
在一些实施例中,在acr元数据描述中可以定义针对渲染距离的阈值或范围。例如,可能存在一个acr最小或最大距离,或者存在一个距离范围,在该距离范围内acr被考虑用于渲染,或者是“激活”或打开的(类似地,acr不被考虑用于渲染,或者是“无效”或关闭的)。
在一些实施例中,该距离信息可以是方向特定的,并且可以指至少一个声道。因此,在一些实施例中,acr可以是自包含的环境描述,其适用于6dof媒体场景中的用户位置(渲染位置)处的总体渲染。
在一些实施例中,acr声道中的至少一个及其相关联的元数据可以定义嵌入式音频对象,其作为acr的一部分并提供方向性渲染。这样的嵌入式音频对象可以与标记一起使用,以使渲染器能够应用“正确”的渲染(渲染为声源而不是扩散声)。在一些实施例中,该标记还用于发信号通知所嵌入的音频对象仅支持音频对象属性的子集。例如,通常可能不希望考虑到环境元素表示以用于在场景中移动。尽管在一些实施例中,这可以被实现。因此,这通常会使所嵌入的音频对象的位置“静止”,并且例如,阻止用户与所述音频对象或音频源间的至少某些形式的交互。
关于图9示出了在6dof场景中的不同渲染位置处的示例用户(表示为位置posn)。例如,用户最初可能在位置pos01020处,然后沿着经过位置pos11021和pos21022并在pos31023处结束的线在音频场景中移动。在此示例中,使用三个acr提供6dof场景中的环境音频。第一acr1011位于位置a1001,第二acr1013位于位置b1003,第三acr1015位于位置c1005。
在此示例中,对于场景中所有已定义的acr,都有一个已定义的“最小有效距离”,在该“最小有效距离”内,渲染期间不使用acr。类似地,在一些实施例中,额外地或替代地,存在一个最大有效距离,在该最大有效距离外,渲染期间不使用acr。
例如,如果最小有效距离为零,则用户可能位于音频场景内acr正上方的某个位置,而acr将有助于环境渲染。
在一些实施例中,渲染器被配置为基于周围acr(acr相对于用户的相对位置)的星座以及到周围acr的距离,确定将形成在每个用户位置处的整体渲染的环境信号的环境分量表示的组合。
在一些实施例中,所述确定可以包括两个部分。
在第一部分中,渲染器被配置为确定哪个acr对当前渲染作贡献。例如,该acr可以选择是相对于用户的“最近”acr,或者可以基于acr是否在定义的有效范围内或其他范围内进行选择。
在第二部分中,渲染器被配置对贡献进行组合。在一些实施例中,所述组合可以基于绝对距离。例如,如果有两个等距放置的acr,则贡献被平均分。在一些实施例中,渲染器被配置为在确定对环境音频信号的贡献时进一步考虑“方向性”距离。换句话说,在一些实施例中,渲染点表现为“重心”。然而,由于环境音频能量是扩散的或非方向性的(尽管acr可能是方向性的),所以这是一个可选方面。
通过在最小或最大有效距离上平滑化有效和无效acr之间的任何过渡,可以在渲染器中实现获得根据6dof内容环境中渲染位置的平滑/现实演变的总环境信号。例如,在一些实施例中,随着用户越来越靠近acr最小有效距离,渲染器可以逐渐减小该acr的贡献。因此,这样的acr在达到最小相对距离过程中将平稳地停止贡献。
例如,在图9的场景中,在用户位于位置pos01020处时尝试渲染音频信号的渲染器可以在仅使用来自acrb1013和acrc1015的环境贡献的渲染环境音频信号。这是由于渲染位置pos0在对于acra1001的最小有效距离阈值之内。
此外,在用户位于位置pos11021处时尝试渲染音频信号的渲染器可以配置为基于所有三个acr渲染环境音频信号。此外,该渲染器可以被配置为基于它们到渲染位置的相对距离来确定贡献。
这也可以应用于在用户位于位置pos21022时尝试渲染音频信号的渲染器(其中环境音频信号基于所有三个acr)。
然而,渲染器可以配置为在用户位于位置pos31023时仅基于acrb1013和acrc1015渲染环境音频信号,而忽略来自acra的环境贡献,因为位于a1001的acra距离pos31023相对较远,acrb和acrc被认为在acra的主要方向上占主导地位。换句话说,渲染器可以被配置为确定acra的相对贡献可以在阈值以下。在其他实施例中,渲染器可以配置为即使在pos31023也考虑acra提供的贡献。例如,当pos3至少接近acrb的最小有效距离时。
注意,在各种实施方式中,基于acr位置元数据的精确选择算法可以不同。此外,在一些实施例中,渲染器确定可以基于acr的类型。
在一些实施例中,渲染器可以被配置为分别确定相对于渲染位置运动的方向和垂直方向ax和bx,其中x=a,b,c:
ax=disxcosαx,并且
bx=disxsinαx
并根据这些因素确定贡献。在这样的实施例中,可以为acr提供两个维度,但是也可以在三个维度上考虑环境分量。
在一些实施例中,渲染器被配置为考虑相对贡献,例如,使得考虑方向性分量(ax和bx)或使得仅考虑绝对距离。在提供方向性acr的一些实施例中,考虑了方向性分量。
在一些实施例中,渲染器被配置为基于绝对距离或方向性距离分量的倒数(例如,acr在最大有效距离内)来确定acr的相对重要性。在如上所述的一些实施例中,渲染器可以采用关于最小有效距离(以及类似地,最大有效距离)的平滑缓冲或滤波。例如,缓冲距离可以定义为最小有效距离的两倍,在距离内,相对于缓冲区距离对acr的相对重要性进行了缩放。
如前所述,acr可以包括一个以上的tf元数据集合。每个集合可以例如涉及不同的缩混信号或缩混信号集合(属于所述acr)或它们的不同组合。
关于图10,其示出了一些实施例的示例实现方式,作为一种实用的6dof实现方式,该实现方式以针对一个acr的一个以上音频源定义场景图。
在图10所示的示例中,显示了acr和其他音频对象(适用于在渲染器中实现)组合的建模。以音频场景树1110的形式示出了该组合的建模。示出的音频场景树1110用于示例音频场景1101。示出的音频场景1101包括两个音频对象,第一音频对象1103(例如,可以是一个人)和第二音频对象1105(例如,可以是汽车)。音频场景还可以包括两个环境分量表示,第一acr,acr1,1107(例如,车库内的环境表示)和第二acr,acr2,1109(例如,车库外的环境表示)。
当然,这是示例音频场景,并且可以使用任何适当数量的对象和acr。
在该示例中,acr11107包括三个音频源(信号),这些音频源对所述环境分量的渲染有贡献(其中可以理解,这些音频源不对应于方向性音频分量,并且也不是例如点源。从音频输入或信号的其提供整体声音(信号)1119中的至少一部分的意义上讲,这些是源)。例如,acr11107可以包括第一音频源1113、第二音频源1115和第三音频源1117。因此,如图10所示,可以有在三个解码器实例处接收到的三个音频信号,提供第一音频源1113的音频解码器实例11141、提供第二音频源1115的音频解码器实例21143和提供第三音频源1117的音频解码器实例31145。由音频源1113、1115和1117形成的acr声音1119传递给渲染呈现器1123,其输出到用户1133。在某些实施例中,可以基于相对于acr11107位置的用户位置来形成该acr声音1119。此外,基于用户位置,可以确定acr11107或acr21109是否对环境有贡献以及它们的相对贡献。
关于图11示出了可以用作分析或合成设备的示例电子设备。该设备可以是任何合适的电子设备或装置。例如,在一些实施例中,设备1400是移动设备、用户设备、平板计算机、计算机、音频回放装置等。
在一些实施例中,设备1400包括至少一个处理器或中央处理单元1407。处理器1407可以被配置为执行各种程序代码,诸如本文所述的方法。
在一些实施例中,设备1400包括存储器1411。在一些实施例中,至少一个处理器1407耦合到存储器1411。存储器1411可以是任何合适的存储装置。在一些实施例中,存储器1411包括程序代码部分,用于存储可在处理器1407上实现的程序代码。此外,在一些实施例中,存储器1411可以进一步包括用于存储数据的存储数据部分,该数据为例如根据本文所述的实施例已经处理或将要处理的数据。每当需要时,处理器1407可以通过存储器-处理器耦合来检索存储在程序代码部分内的已实现程序代码和存储在存储数据部分的数据。
在一些实施例中,设备1400包括用户接口1405。在一些实施例中,用户接口1405可以耦合到处理器1407。在一些实施例中,处理器1407可以控制用户接口1405的操作并从用户接口1405接收输入。在一些实施例中,用户接口1405可以使用户能够通过例如小键盘向设备1400输入命令。在一些实施例中,用户接口1405可以使用户能够从设备1400获取信息。例如,用户接口1405可以包括显示器,其被配置为向用户显示来自设备1400的信息。在一些实施例中,用户接口1405可以包括触摸屏或触摸接口,该触摸屏或触摸接口既能够使信息被输入到设备1400,又能够向用户显示设备1400的信息。在一些实施例中,用户接口1405可以是用于与如本文所述的位置确定器通信的用户接口。
在一些实施例中,设备1400包括输入/输出端口1409。在一些实施例中,输入/输出端口1409包括收发器。在这样的实施例中,收发器可以耦合到处理器1407,并且被配置为使得能够通过例如无线通信网络与其他装置或电子设备进行通信。在一些实施例中,收发器或任何合适的收发器或发射和/或接收装置可以被配置为通过有线或有线耦合与其他电子设备或装置通信。
收发器可以通过任何合适的已知通信协议与另外的装置进行通信。例如,在一些实施例中,收发器可以使用合适的通用移动电信系统(umts)协议、诸如ieee802.x的无线局域网(wlan)协议、诸如蓝牙的合适的短程射频通信协议、或红外数据通信路径(irda)。
收发器输入/输出端口1409可以被配置为接收信号,并且在一些实施例中,被配置为通过处理器1407执行合适的代码来确定参数,如本文所述。此外,设备可以生成合适的缩混信号和参数输出,以发送给合成设备。
在一些实施例中,装置1400可以用作合成设备的至少一部分。这样,输入/输出端口1409可以被配置为接收缩混信号,以及在一些实施例中,如本文所述在捕获设备或处理设备处确定的参数,并通过处理器1407执行合适的代码来生成合适的音频信号格式输出。输入/输出端口1409可以耦合到任何合适的音频输出,例如耦合到多声道扬声器系统和/或耳机(其可以是头戴式或非头戴式耳机)或类似的音频输出。
通常,本发明的各种实施例可以以硬件或专用电路,软件,逻辑或其任何组合来实现。例如,一些方面可以以硬件来实现,而其他方面可以以可以由控制器、微处理器或其他计算设备执行的固件或软件来实现,但本发明不限于此。尽管本发明的各个方面可以被图示和描述为框图、流程图或使用一些其他图形表示,但是众所周知,本文所述的这些框、装置、系统、技术或方法可以以硬件、软件、固件、专用电路或逻辑、通用硬件或控制器、或其他计算设备、或其某种组合来实现,以上为非限制性示例。
本发明的实施例可以由计算机软件来实现,该计算机软件可由移动设备的数据处理器执行,例如在处理器实体中,或者由硬件执行,或者由软件和硬件的组合执行。进一步地,在这一点上,应该注意的是,如图中的逻辑流程的任何方框可以表示程序步骤,或者互连的逻辑电路、方框和功能,或者程序步骤和逻辑电路、方框和功能的组合。软件可以存储在诸如存储芯片或在处理器内实现的存储块之类的物理介质上,诸如硬盘或软盘之类的磁性介质上,以及诸如dvd及其数据变体cd之类的光学介质上。
存储器可以是适合于本地技术环境的任何类型,并且可以使用任何适当的数据存储技术来实现,例如基于半导体的存储设备、磁存储设备和系统、光学存储设备和系统、固定存储器和可移动存储器。数据处理器可以是适合本地技术环境的任何类型,并且可以包括通用计算机、专用计算机、微处理器、数字信号处理器(dsp)、专用集成电路(asic)、门级电路中的一个或多个和基于多核处理器架构的处理器,以上作为非限制性示例。
可以在诸如集成电路模块的各种组件中实践本发明的实施例。集成电路的设计总体上是高度自动化的过程。复杂而功能强大的软件工具可用于将逻辑级设计转换为易于在半导体衬底上蚀刻和形成的半导体电路设计。
程序,例如由加利福尼亚州山景城的synopsys,inc.和加利福尼亚州圣何塞的cadencedesign提供的程序,可以通过完善的设计规则以及预先存储的设计模块库自动对导体进行布线并在半导体芯片上定位组件。一旦完成了半导体电路的设计,就可以将标准化电子格式(例如,opus、gdsii等)的设计结果传送到半导体制造设施或“fab”以进行制造。
以上通过示例性和非限制性示例提供了本发明示例性实施例的完整和有益的描述。然而,当结合附图和所附权利要求书阅读时,鉴于以上所述,各种修改和变型对于相关领域的技术人员而言将变得显而易见。但是,本发明的教导的所有这些和类似的修改仍将落入所附权利要求书所限定的本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!