电子设备及其控制方法与流程
本公开涉及电子设备及其控制方法,并且更具体地,涉及提供虚拟对象图像的电子设备及其控制方法。
背景技术:
随着电子技术的发展,各种类型的电子设备正在被开发和分发。
特别是,作为具有拍摄功能的便携设备,诸如智能手机、平板pc等,正在被开发和分发,对于增强现实(ar)功能的研究和开发及其使用正在增加。
增强现实可以是将虚拟对象添加到真实对象(例如,真实环境、真实对象)并提供对象的技术。
然而,在传统方法中,虚拟对象只是被添加到实时拍摄的图像中,并且存在对于在不同地点拍摄的图像,不能向用户提供与增强现实相同的体验的问题。
因此,存在增强现实图像应该被提供给用户的需要,这使得对于增强现实图像中的虚拟对象的用户交互成为可能,而不受地点的限制。
技术实现要素:
技术问题
本公开是为了解决上述需求而设计的,并且本公开的目的在于提供一种电子设备及其控制方法,该电子设备基于关于包括在所拍摄的图像中的空间的信息来添加虚拟对象。
技术解决方案
根据本公开的实施例的用于实现上述目的的电子设备包括显示器、相机、存储器和处理器,该处理器被配置为将通过相机实时捕获的视频识别为多个图像部分,并且获得与每个图像部分相对应的空间信息,将获得的空间信息映射到多个图像部分中的每一个图像部分,并且将该空间信息存储在存储器中,以及基于输入用于将虚拟对象图像添加到视频的用户命令,控制显示器基于被映射到多个图像部分中的每一个图像部分的空间信息,将虚拟对象图像添加到视频并且显示该虚拟对象图像。
这里,处理器可以获得多个图像部分中的每一个图像部分中的、关于平面空间的信息和关于相机的观看(view)方向的信息,并将这些信息存储为空间信息,基于在多个图像部分中的每一个图像部分中的、关于平面空间的信息获得用于添加虚拟对象图像的位置信息,获得形状上与关于相机的观看方向的信息相对应的虚拟对象图像,以及控制显示器基于位置信息将获得的虚拟对象图像添加到相应的图像部分并显示该虚拟对象图像。
这里,处理器可以存储关于通过加速度传感器或陀螺仪传感器中的至少一个获得的、相机的位置或姿态中的至少一个的信息,作为关于相机的观看方向的信息。
此外,处理器可以基于获得用于基于在多个图像部分当中的至少一个图像部分中获得的空间信息来添加虚拟对象图像的多个位置信息,基于虚拟对象图像先前被添加到视频的历史信息来识别多个位置信息之一。
此外,处理器可以获得其中多个图像部分的顺序基于在多个图像部分中的每一个图像部分中获得的关于相机的观看方向的信息而被重新排列的视频,并且控制显示器一起显示获得的视频和用于调整再现该获得的视频的时间点的导航条。
这里,处理器可以基于关于相机的观看方向的信息,重新排列多个图像部分的顺序,使得相机的观看方向从第一方向移动到第二方向。
此外,电子设备包括通信器,并且处理器可以控制通信器将多个图像部分和存储在存储器中的、被映射到多个图像部分中的每一个图像部分的空间信息发送到外部设备。
这里,处理器可以基于另一个虚拟对象图像基于从外部设备接收到多个图像部分和被映射到多个图像部分中的每一个图像部分的空间信息而被添加的视频,控制显示器利用包括在接收到的视频中的另一个虚拟对象图像替换虚拟对象图像并显示该另一个虚拟对象图。
此外,虚拟对象图像可以是与以不同方向或不同距离捕获3d对象图像的多个虚拟对象图像当中的空间信息相对应的虚拟对象图像。
此外,处理器可以基于输入对于包括在显示的视频中的虚拟对象图像的位置或旋转的改变中的至少一个的用户命令,获得与用户命令相对应的方向信息或距离信息中的至少一个,基于获得的信息获得多个虚拟对象图像中与用户命令相对应的虚拟对象图像,并且控制显示器显示该虚拟对象图像。
此外,处理器可以获得包括在多个图像部分中的每一个图像部分中的关于对象的信息并且将该信息存储为空间信息,获得用于基于在多个图像部分中的每一个图像部分中的关于对象的信息将虚拟对象图像添加到对象的一个区域的位置信息,以及获得形状上与关于相机的观看方向的信息相对应的虚拟对象图像,并且控制显示器基于位置信息将获得的虚拟对象图像添加到相应的图像部分,并显示该虚拟对象图像。
此外,处理器可以获得包括在多个图像部分中的每一个图像部分中的关于对象的信息和其中对象所位于的空间的形状信息,并将这些信息存储为空间信息,并且基于输入用于利用虚拟对象替换对象的用户命令,基于关于对象的信息和空间的形状信息,将虚拟对象图像与对象重叠,并显示该虚拟对象图像。
此外,处理器可以将视频应用于学习网络模型,并且获得包括在多个图像部分中的每一个图像部分中的关于对象的信息,并且关于对象的信息可以包括对象的类型、形状、大小或位置中的至少一个。
此外,处理器可以基于输入用于将另一个虚拟对象图像添加到虚拟对象图像的一个区域的用户命令,控制显示器基于关于虚拟对象图像的信息、以层叠在虚拟对象图像上的形式显示另一个虚拟对象图像。
此外,处理器可以基于输入用于移除虚拟对象图像的命令,移除虚拟对象图像,并且控制显示器在其中移除了虚拟对象图像的位置显示另一个虚拟对象图像。
此外,处理器可以控制显示器基于关于目标电子设备的信息显示包括至少一个模块图像的ui,获得与基于由用户输入在至少一个模块中选择的模块图像获得的模块型电子设备相对应的虚拟对象图像,并将虚拟对象图像添加到视频。
这里,处理器可以基于接收到用于改变包括在虚拟对象图像中的至少一个模块图像的大小、布置形式、颜色或材料中的至少一个的用户命令,基于用户命令改变虚拟对象图像。
同时,根据本公开的实施例的电子设备的控制方法包括以下步骤:将通过相机实时捕获的视频识别为多个图像部分,并且获得与每个图像部分相对应的空间信息,将获得的空间信息映射到多个图像部分中的每一个图像部分并存储该空间信息,并且基于输入用于将对象图像添加到视频的用户命令,将对象图像添加到视频,并且基于被映射到多个图像部分中的每一个图像部分的空间信息来显示对象图像。
这里,存储的步骤包括以下步骤:获得多个图像部分中的每一个图像部分中的、关于平面空间的信息和关于相机的观看方向的信息,并且存储关于平面空间的信息和关于观看方向的信息作为空间信息,并且显示的步骤包括以下步骤:基于在多个图像部分中的每一个图像部分中的、关于平面空间的信息,获得用于添加对象图像的位置信息;获得形状上与关于相机的观看方向的信息相对应的对象图像;以及基于位置信息将获得的对象图像添加到相应的图像部分,并显示该对象图像。
这里,在获得的步骤中,关于通过电子设备的加速度传感器或陀螺仪传感器中的至少一个获得的、相机的位置或姿态中的至少一个的信息可以被获得为关于观看方向的信息。
此外,显示的步骤可以包括以下步骤:基于获得用于基于在多个图像部分中的至少一个图像部分中获得的空间信息来添加对象图像的多个位置信息,基于对象图像先前被添加到视频的历史信息来识别多个位置信息之一。
此外,控制方法包括获得其中多个图像部分的顺序基于在多个图像部分中的每一个图像部分中获得的、关于相机的观看方向的信息而被重新排列的视频的步骤,并且在显示的步骤中,用于调整再现获得的视频的时间点的导航条可以与获得的视频一起显示。
这里,在获得重新排列后的视频的步骤中,可以基于关于观看方向的信息,重新排列多个图像部分的顺序,使得相机的观看方向从第一方向移动到第二方向。
此外,控制方法可以包括将多个图像部分和被映射到多个图像部分中的每一个图像部分的空间信息发送到外部设备的步骤。
此外,显示的步骤可以包括以下步骤:基于另一个对象图像基于从外部设备接收到多个图像部分和被映射到多个图像部分中的每一个图像部分的空间信息而被添加的视频,利用包括在接收到的视频中的另一个对象图像替换对象图像并显示该另一个对象图像。
此外,对象图像可以是与以不同方向或不同距离捕获3d对象图像的多个对象图像中的空间信息相对应的对象图像。
这里,显示的步骤可以包括以下步骤:基于输入对于包括在视频中的对象图像的位置改变或旋转中的至少一个的用户命令,获得与用户命令相对应的方向信息或距离信息中的至少一个,并且基于获得的信息获得多个对象图像当中与用户命令相对应的对象图像并显示该对象图像。
发明效果
根据本公开的各种实施例,可以在不受地点的限制的情况下向用户提供添加了虚拟ar对象的视频,并且对于该对象可以进行交互。此外,用户可以与另一个用户共享增强现实图像,在该增强现实图像中,在不受地点和时间的限制的情况下对ar对象的添加和修改是可能的。
附图说明
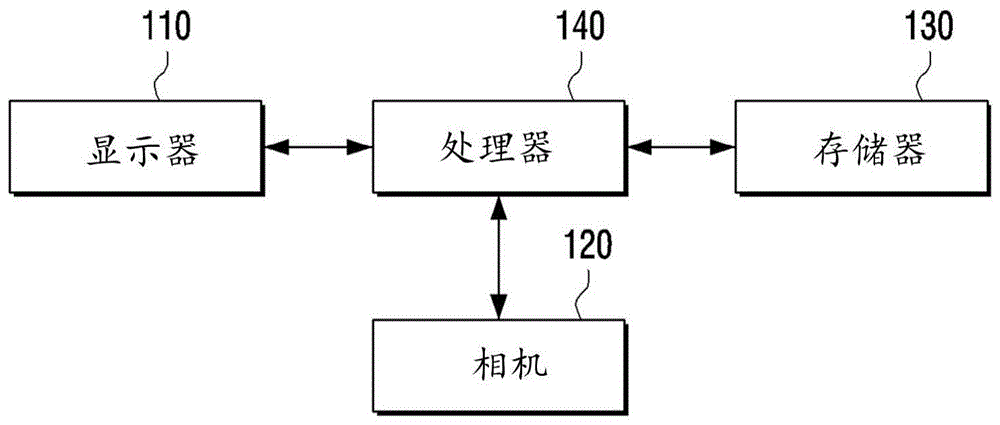
图1是示出根据本公开的实施例的电子设备的配置的框图;
图2是示出图1所示的电子设备的详细配置的框图;
图3是示出根据本公开的实施例的通过相机捕获的视频的图;
图4是示出根据本公开的实施例的空间信息的图;
图5是示出根据本公开的实施例的对象图像的图;
图6是示出根据本公开的实施例的多个位置信息的图;
图7是示出根据本公开的实施例的关于相机的观看方向的信息的图;
图8是示出根据本公开的实施例的导航条的图;
图9a是示出根据本公开的实施例的识别对象的方法的图;
图9b是示出根据本公开的实施例的添加虚拟对象图像的方法的图;
图10是示出根据本公开的实施例的多个虚拟对象图像的图;
图11是示出根据本公开的实施例移除虚拟对象图像的情况的图;
图12是示出根据本公开的实施例的替换对象的方法的图;
图13是示出根据本公开的实施例的对象和虚拟对象图像的交互的图;
图14是示出根据本公开的另一个实施例的对象图像的图;
图15是示出根据本公开的实施例的对象图像的位置或旋转的改变的图;
图16是示出根据本公开的实施例的获得虚拟对象图像的方法的图;
图17是示出根据本公开的实施例的虚拟对象图像的图;
图18是示出根据本公开的另一个实施例的对象的图;
图19是示出根据本公开的另一个实施例的虚拟对象图像的图;以及
图20是示出根据本公开的实施例的电子设备的控制方法的流程图。
具体实施方式
在下文中,将参考附图详细描述本公开。
作为在本公开的实施例中使用的术语,考虑到在本公开中描述的功能,尽可能地选择了当前广泛使用的通用术语。然而,这些术语可以根据在相关领域工作的本领域技术人员的意图、先前的法院判决或新技术的出现而改变。此外,在特定情况下,存在由申请人自己指定的术语,并且在这种情况下,将在本公开的相关描述中详细描述术语的含义。因此,本公开中使用的术语应当基于术语的含义和本公开的整体内容来定义,而不仅仅是基于术语的名称来定义。
在本说明书中,诸如“具有”、“可以具有”、“包括”和“可以包括”的表述应该被解释为表示存在这样的特性(例如:诸如数值、函数、操作和组件的元素),并且这些表述不意图排除附加特性的存在。
此外,“a和/或b的至少一个”应该被解释为“a”或“b”或者“a和b”中的任何一个。
此外,本说明书中使用的表述“第一”、“第二”等可用于描述各种元素,而不管其顺序和/或重要性。此外,这样的表达仅用于将一个元素与另一个元素区分开来,并不意图限制这些元素。
同时,本公开中一个元素(例如:第一元素)与另一个元素(例如:第二元素)是“(可操作地或通信地)耦合/耦合到”或“连接到”另一个元素(例如:第二元素)的描述应该被解释为包括一个元素直接耦合到另一个元素的情况,以及一个元素通过又一个元素(例如:第三元素)耦合到另一个元素的情况。
此外,单数表达包括复数表达,除非在上下文中被明显不同地定义。此外,在本公开中,诸如“包括”和“由……组成”的术语应被解释为表示存在说明书中描述的特性、数量、步骤、操作、元素、组件或其组合,但不预先排除添加其他特征、数量、步骤、操作、元素、组件或其组合中的一个或多个的存在或可能性。
此外,在本公开中,“模块”或“部件”执行至少一个功能或操作,并且可以被实现为硬件或软件、或者硬件和软件的组合。此外,多个“模块”或“部件”可以被集成到至少一个模块中,并且被实现为至少一个处理器(未示出),除了需要被实现为特定硬件的“模块”或“部件”。
同时,在本说明书中,术语“用户”可以指使用电子设备的人或使用电子设备的设备(例如:人工智能电子设备)。
在下文中,将参考附图更详细地描述本公开的实施例。
图1是示出根据本公开的实施例的电子设备的配置的框图。
电子设备100可以被实现为配备有显示功能的设备,诸如tv、智能手机、平板pc、pmp、pda、膝上型pc、智能手表、头戴式显示器(hmd)、近眼显示器(ned)等。电子设备100可以包括用于提供显示功能的各种形式的显示器。
然而,根据本公开的各种实施例可以通过没有配备显示功能的电子设备来实现。例如,向外部设备提供图像的各种类型的电子设备(诸如,蓝光播放器、数字多功能盘(dvd)播放器、流式内容输出设备、机顶盒等)可以实现本公开的各种实施例。作为另一个示例,各种形式的家用电器(诸如扬声器、冰箱、洗衣机、空调、空气净化器、各种物联网设备等)显然可以实现本公开的各种实施例。在下文中,为了便于解释,将基于电子设备100是配备有相机120的用户终端设备的假设进行解释。
参考图1,电子设备100包括显示器110、相机120、存储器130和处理器140。
显示器110可以提供可以通过电子设备100提供的各种内容屏幕。这里,内容屏幕可以包括各种内容(诸如图像、运动图像、文本、音乐等)、应用执行屏幕、图形用户界面(gui)屏幕等。
显示器110可以被实现为各种形式的显示器,诸如液晶显示器(lcd)、有机发光二极管(oled)显示器、等离子体显示面板(pdp)、墙壁、微型led等。在显示器110内部,可以以诸如a-sitft、低温多晶硅(ltps)tft、有机tft(otft)、背光单元等形式实现的驱动电路也可以被包括在一起。同时,显示器110也可以被实现为与触摸传感器、柔性显示器、3d显示器等相结合的触摸屏。
此外,根据本公开的实施例的显示器110不仅可以包括输出图像的显示面板,还可以包括容纳显示面板的边框。特别地,根据本公开的实施例的边框可以包括用于检测用户交互的触摸传感器(未示出)。
具体地,显示器110可以显示通过相机120实时捕获的视频(例如,实时观看图像)、虚拟对象图像被添加到图像的增强现实(ar)图像、或者根据处理器140的控制由处理器140基于如下所述的图像等获得的图像。这里,虚拟对象图像可以被称为ar对象、虚拟对象等,但是在下文中,为了便于解释,一般将其称为虚拟对象图像。
根据本公开的实施例的电子设备100可以在其前表面或后表面上包括至少一个相机120。
相机120是能够捕获静止图像或运动图像的设备,并且其可以包括一个或多个图像传感器(例如,前表面传感器或后表面传感器)、镜头、图像信号处理器(isp)和闪光灯(例如,led、氙灯等)。
根据本公开的实施例的相机120可以根据处理器140的控制来捕获任何目标(subject),并将捕获的数据发送到处理器140。根据处理器140的控制,捕获的数据显然可以存储在存储器130中。这里,可以以各种方式调用捕获的数据,诸如图片、图像、静止图像、运动图像等。但是在下文中,为了便于解释,一般将其称为图像。同时,显然,根据本公开的各种实施例的图像可以指除了通过相机120捕获的实时观看图像之外的、从外部设备和外部服务器接收的图像、存储在存储器130中的图像等。
根据本公开的实施例,处理器140可以通过显示器110来显示基于通过相机120捕获的视频的增强现实屏幕。
存储器130存储各种数据,诸如用于操作电子设备100的操作系统(o/s)软件模块、各种多媒体内容等。
特别地,存储器130可以根据处理器140的控制,存储从通过相机120捕获的视频获得的各种信息。稍后将对存储在存储器130中的各种信息进行详细解释。
处理器140可以被实现为处理数字信号的数字信号处理器(dsp)、微处理器和时间控制器(tcon)。然而,本公开不限于此,并且处理器140可以包括中央处理单元(cpu)、微控制器单元(mcu)、微处理单元(mpu)、控制器、应用处理器(ap)、图形处理单元(gpu)、或通信处理器(cp)以及arm处理器中的一个或多个,或者可以由术语定义。此外,处理器140可以被实现为其中存储了具有处理算法的片上系统(soc)或大规模集成电路(lsi)、或者是以现场可编程门阵列(fpga)的形式的。处理器140可以通过执行存储在存储器中的计算机可执行指令来执行各种功能。
根据本公开的实施例的处理器140可以将通过相机120实时捕获的视频识别为多个图像部分。将参考图3对此进行解释。
图3是示出根据本公开的实施例的通过相机捕获的视频的图。
参考图3,相机120可以根据处理器140的控制来捕获真实对象,并将其发送到处理器140。这里,真实对象(例如,家具、家用电器、墙面、背景等)可以指目标。
根据本公开的实施例的处理器140可以通过显示器110显示通过相机120实时捕获的视频10。此外,处理器140显然可以存储视频10。然后,处理器140可以将视频10识别为多个图像部分。
这里,图像部分可以指通过单个帧、预定数量的帧中的至少一个或通过预定时间来划分视频10的部分。作为示例,处理器140可以以预定数量的帧单元划分视频10,并获得第一到第n图像部分。可以以各种方式设置预定数量。例如,处理器140可以以24、30或60个帧单元识别图像部分。然而,这仅仅是示例,并且本公开不一定限于此。
作为另一个示例,处理器140可以以预定时间单元划分视频10,并获得第一到第n图像部分。例如,处理器140可以以10秒为单位识别图像部分。如果视频10是每秒60帧(60fps),则处理器140可以以600个帧单元划分视频10,并获得第一到第n图像部分。然而,这仅仅是示例,并且本公开不一定限于此。
根据本公开的实施例的处理器140可以获得与图像部分相对应的空间信息。这里,空间信息可以指图像部分中关于平面空间的信息和关于相机的观看方向的信息。将参考图4描述与图像部分相对应的空间信息。
图4是示出根据本公开的实施例的空间信息的图。
根据本公开的实施例的处理器140可以获得图像部分中关于平面空间的信息20-1和关于相机120的观看方向的信息20-2,并将这些信息存储为空间信息20。
根据本公开的实施例的处理器140可以假定图像部分中的平面空间。例如,根据空间相干性,构成平面空间的多个点可以在彼此相邻的同时存在。处理器140可以通过使用彼此相邻的任何点来假定图像部分中的平面空间。处理器140可以识别彼此相邻的任何点是否存在于相同平面上,并且基于识别结果获得关于平面空间的信息20-1。
例如,处理器140可以通过使用彼此相邻(或者,在阈值内间隔开)的第一至第三点来识别图像部分中的特定空间是否是平面空间。如果根据识别结果,特定空间是平面空间,则处理器140可以基于第一至第三点获得平面方程的系数a、b、c和d。处理器140可以基于以下公式1获得平面方程作为关于平面空间的信息20-1。
公式1
ax+by+cz+d=0
这里,a、b和c是指示平面的方向的法向量,并且d可以是包括第一至第三点的平面和相机120之间的距离。然而,这仅仅是示例,并且关于平面空间的信息20-1可以是各种形式的。例如,显然,处理器140可以基于获得图像的特征信息的机器学习模型来分析图像部分,并且根据分析结果获得关于平面空间的信息20-1。
根据本公开的实施例的处理器140可以获得图像部分中关于相机120的观看方向的信息20-2。
根据本公开的实施例,关于相机120的观看方向(或观看角)的信息20-2可以指与从相机120接收到的实时视频相对应的相机120朝向的方向、相机120的角度、相机120的位置、或相机120的姿态中的至少一个。参考图4,可以了解,相机120在从左向右移动,然后再次从右向左移动的同时捕获目标,并且以特定的角度或姿态捕获目标。
根据本公开的实施例,电子设备100可以包括加速度传感器或陀螺仪传感器中的至少一个。根据实施例,处理器140可以基于至少一个传感器的感测结果,获得所有方向(例如,360度)当中、与相机120朝向的观看方向(或者,电子设备100朝向的方向)相对应的特定角度(例如,所有方向360度当中的15度),作为关于观看方向的信息20-2。同时,通过感测结果获得的特定角度可以被称为相机120的姿态、倾斜角度等,但在下文中,为了便于解释,一般将其称为相机120的姿态。
作为另一个示例,处理器140可以基于感测结果获得电子设备100(或相机120)的当前位置,作为关于观看方向的信息20-2。
作为又一个示例,处理器140可以利用相机120获得真实对象,通过传感器(例如,gps传感器)获得电子设备100的当前位置的位置信息(例如,纬度/经度信息),并且通过至少一个传感器获得传感器信息(诸如倾斜/重力等)。
同时,这仅仅是示例,并且本公开不限于此。例如,显然,电子设备100可以基于gps传感器、基于位置的服务(lbs)方法、从外部设备接收到的位置信息或方向信息、数字罗盘等来获得关于相机120的观看方向的信息20-2。
回到图1,根据本公开的实施例的处理器140可以将获得的空间信息映射到多个图像部分中的每一个图像部分,并且将其存储在存储器130中。
根据本公开的实施例,处理器140可以识别存在于与相机120的观看方向(例如,与相机120朝向的观看相同的方向、相同的角度或相同的姿态)在同一条线上的平面空间,将关于平面空间的信息20-1与关于相机120的观看方向的信息20-2一起映射到相应的图像部分,并存储这些信息。参考图4,处理器140可以将特定视频10和与其相对应的关于平面空间的信息20-1和关于相机120的观看方向的信息20-2进行映射,并存储这些信息。同时,基于关于观看方向的信息20-2是相机120的注视(gaze)的移动方向的假设示出图4,但是这仅仅是示例,并且本公开不限于此。例如,显然,关于观看方向的信息20-2可以包括存在于视频中、与相机120的观看方向在同一条线上(或直线上)的目标的坐标信息、点信息等。
如果输入了用于将虚拟对象图像添加到视频10的用户命令,则根据本公开的实施例的处理器140可以基于被映射到多个图像部分中的每一个图像部分的空间信息将虚拟对象图像添加到视频,并通过显示器110显示图像。将参考图5对此进行详细解释。
图5是示出根据本公开的实施例的虚拟对象图像的图。
参考图5,由用户选择的虚拟对象图像30可以被添加到视频10。这里,虚拟对象图像30可以指与由用户选择的家用电器、家具等相对应的图像。根据本公开的实施例的处理器140可以提供用户可以添加到视频10的虚拟对象图像30的列表,并且将列表中与用于选择的用户命令相对应的虚拟对象图像30添加到视频10。然而,这仅仅是示例,并且本公开不限于此。例如,处理器140可以显示各种形式的ui(例如,搜索窗口等),通过该ui,用户可以选择特定对象(例如,家用电器或家具),并将与根据用户命令选择的对象相对应的虚拟对象图像30添加到视频10。
参考图5,处理器140可以获得被映射到多个图像部分中的每一个图像部分的关于平面空间的信息20-1和关于观看方向的信息20-2。然后,处理器140可以基于多个图像部分中的每一个图像部分中关于平面空间的信息20-1来获得用于添加虚拟对象图像30的位置信息。例如,处理器140可以不将虚拟对象图像30覆盖在视频10的任何区域上,而是基于关于平面空间的信息20-1将虚拟对象图像30添加到视频10内部的多个目标当中的特定目标的平面空间。这里,特定对象的平面空间可以指前述位置信息。
然后,处理器140可以获得形状上与关于观看方向的信息20-2相对应的虚拟对象图像30。例如,处理器140可以获得以不同方向或不同距离捕获3d虚拟对象图像的多个虚拟对象图像当中、与关于观看方向的信息20-2相对应的虚拟对象图像30。作为示例,如果与相机120朝向的观看方向、角度或姿态相对应的虚拟对象图像30是对象的右侧表面图或左侧表面图,则处理器140可以获得多个虚拟对象图像30当中的右侧表面图或左侧表面图,并将该图添加到视频10。作为另一个示例,如果与相机120朝向的观看方向、角度或姿态相对应的虚拟对象图像30是正表面图,则处理器140可以获得对象的正表面图作为虚拟对象图像30,并将该图添加到视频10。
具体地,根据本公开的实施例的处理器140可以基于3d网格数据形式的3d虚拟对象图像获得虚拟对象图像30。作为获得3d网格数据的方法,首先,可以通过扫描等为3d建模的对象生成多个网格。然后,可以为形成3d对象形状的表面的面生成多边形网格。这里,网格是指包括面、节点(顶点)和边的封闭结构。例如,网格可以由三角形组成,并且显然地,其也可以由诸如四边形、五边形等的多边形组成。如果给定网格的尺寸或面积,则可以根据建模的形状自动地形成约几十到几万个网格。此外,可以通过网格的这种生成方式将对象建模为3d形状,并且可以通过利用该3d形状来获得与各种观看方向相对应的虚拟对象图像30。网格数据可以包括能够表示包括面、节点(顶点)和边的网格的信息。例如,网格数据可以包括一个网格的每个节点的坐标,并且如果处理器140可以获知每个节点的坐标,则处理器140可以通过参考每个节点的坐标来获得与观看3d网格模型(例如,虚拟对象)的角度相对应的虚拟对象图像30。此外,处理器140可以基于3d对象图像来识别要添加到视频的3d虚拟对象的形式和尺寸。作为示例,处理器140可以将3d网格数据中的特定节点定义为绝对坐标系的原点(0,0,0),计算每个节点的位置,并识别3d虚拟对象的形式和尺寸。例如,随着节点之间的距离变远,每个节点的坐标的绝对值可以增加,并且处理器140可以基于绝对值来识别3d虚拟对象的形式(或形状)和尺寸。
显然,如上所述的3d网格数据可以被预先存储在电子设备100中、或者可以通过与服务器执行通信来接收、或者可以在电子设备100本身中生成。处理器140可以基于相机120朝向的观看方向、从与所选对象相对应的3d网格数据获得虚拟对象图像30。同时,网格数据形式的3d虚拟对象图像仅仅是示例,并且本公开不一定限于此。例如,显然,处理器140可以从以不同方向和不同距离捕获对象的多个2d图像中获得与相机120的观看方向相对应的虚拟对象图像30、或者基于生成并输出虚拟对象图像30的神经网络算法获得与相机120的观看方向相对应的虚拟对象图像30。在下文中,为了便于解释,将基于3d虚拟对象图像是网格数据形式的假设进行解释。
同时,在图5中,基于处理器140通过显示器110显示视频10’的假设进行了解释,该视频10’是虚拟对象图像30被添加到通过相机120实时捕获的视频10中的图像,但是本公开不一定限于此。例如,显然,处理器140可以显示视频10’,该视频10’是虚拟对象图像30基于存储在存储器130中的空间信息20、在不同于捕获到视频10的地点被添加到视频10的图像。
虚拟对象图像30不像在传统技术中那样仅仅覆盖在视频10的特定区域上,而是根据本公开的实施例的处理器140可以基于存储在存储器130中的图像部分和被映射到图像部分的空间信息、将虚拟对象图像30添加到相应的图像部分。
回到图1,如果基于在多个图像部分当中的至少一个图像部分中获得的空间信息20获得了用于添加虚拟对象图像30的多个位置信息,则处理器140可以基于虚拟对象图像先前被添加到视频10的历史信息来识别多个位置信息之一。将参考图6对此进行详细解释。
图6是示出根据本公开的实施例的多个位置信息的图。
参考图6,处理器140可以基于多个图像部分中的每一个图像部分中关于平面空间的位置信息20-1来获得用于添加虚拟对象图像30的位置信息。例如,处理器140可以基于关于平面空间的位置信息20-1来识别视频中的多个平面空间,并且将多个平面空间当中的第一平面空间和第二平面空间识别为用于添加虚拟对象图像30的位置信息。处理器140可以将虚拟对象图像30添加到识别出的位置信息中的任何一个。
如果获得了用于添加虚拟对象图像30的多个位置信息,则根据本公开的实施例的处理器140可以基于虚拟对象图像先前被添加的历史信息来识别多个位置信息中的任何一个。然后,处理器140可以将虚拟对象图像30添加到识别出的位置信息。
参考图6,处理器140可以基于图像部分中关于平面空间的位置信息20-1,将第一桌上的平面空间识别为第一位置信息40-1,并且将第二桌上的平面空间识别为第二位置信息40-2。然后,处理器140可以获得任何一个位置信息,其中虚拟对象图像先前被添加在第一位置信息40-1和第二位置信息40-2之间。例如,如果存在显示了虚拟对象图像先前被添加到与第一位置信息40-1相对应的第一桌的增强现实屏幕的历史,则处理器140可以基于这样的历史信息获得第一位置信息40-1和第二位置信息40-2之间的第一位置信息40-1,并将虚拟对象图像30添加到获得的第一位置信息40-1。同时,这仅仅是示例,并且本公开不限于此。
作为另一个示例,如果基于图像部分中关于平面空间的位置信息20-1来识别用于添加虚拟对象图像30的多个位置信息,则处理器140可以识别多个位置信息当中、与最大区域的平面空间相对应的位置信息。作为又一个示例,处理器140可以基于地板平面识别与位于大于或等于阈值的高度处的平面空间相对应的位置信息。然后,处理器140可以将虚拟对象图像30添加到识别出的位置信息。
回到图1,处理器140可以获得视频,其中基于在多个图像部分中的每一个图像部分中获得的关于相机120的观看方向的信息20-2,重新排列多个图像部分的顺序,并且显示视频和用于调整再现所获得的视频的时间点的导航条。将参考图7和图8对此进行详细解释。
图7是示出根据本公开的实施例的关于相机的观看方向的信息的图。
在视频10中,相机120的移动方向可以不是恒定的,诸如从左到右(或者从右到左)或从上到下(或者从下到上)。此外,在捕获期间,视频10的抖动可能由于相机120的抖动而发生。由用户自由捕获的视频10可能不具有特定方向性。
参考图7,当相机120从第一方向移动到第二方向,然后再次移动到第一方向时,可以捕获到视频。
根据本公开的实施例的处理器140可以获得视频,其中基于关于相机120的观看方向的信息20-2来重新排列多个图像部分的顺序。作为示例,可以假设视频10包括第一至第七图像部分的情况。处理器140可以基于关于观看方向的信息20-2来识别第一至第四图像部分具有从第一方向移动到第二方向的方向性,并且第五至第七图像部分具有从第二方向移动到第一方向的方向性。将参考图8描述处理器140获得多个图像部分的顺序被重新排列的视频的详细实施例。
图8是示出根据本公开的实施例的导航条的图。
根据本公开的实施例的处理器140可以重新排列多个图像部分,使得相机120的观看的移动方向具有基于关于观看方向的信息20-2的特定方向性。
例如,如图7所示,如果在第一到第七时间点中的每一个时间点捕获的静止图像(或具有预定数量的帧的图像)是按照捕获时间的顺序排列的,则相机120的观看方向从左向右移动,然后再次向左移动。然而,如图8所示,处理器140可以获得视频,其中在第一至第七时间点的每一个时间点捕获的静止图像被重新排列,以具有基于关于观看方向的信息20-2的特定方向性。例如,处理器140可以获得图像以第一、第七、第二、第六、第三、第五和第四图像部分的顺序被重新排列的视频。然而,这仅仅是示例,并且根据本公开的各种实施例的处理器140显然可以获得多个图像部分根据各种标准被重新排列的视频。例如,处理器140可以重新排列多个图像部分,使得它们具有基于地板平面从上向下移动的方向性、或者重新排列多个图像部分,使得它们具有从下向上移动的方向性。
根据本公开的实施例的处理器140可以显示用于调整与视频一起再现重新排列后的视频的时间点的导航条40。这里,处理器140可以基于多个重新排列后的图像部分具有的特定方向性来生成和显示导航条40。例如,如果方向性是从左到右,则处理器140可以生成水平形式的导航条,并且如果方向性是从上到下,则处理器140可以生成垂直形式的导航条。然而,这仅仅是示例,并且本公开不限于此。例如,如果其顺序被重新排列的多个图像部分具有所有方向上的360度的方向性,则处理器140显然可以生成并显示圆形形式的导航条。
根据本公开的实施例的处理器140显然可以显示引导ui,该引导ui在通过相机120捕获视频期间引导移动方向。这里,引导ui是引导使得相机120从第一方向移动到第二方向的引导ui,并且对于根据引导ui捕获的视频,相机120的观看的移动方向可以具有特定方向性。
回到图1,根据本公开的实施例的处理器140可以获得关于包括在多个图像部分的每一个图像部分中的对象的信息,并将该信息存储为空间信息20。然后,处理器140可以基于关于多个图像部分中的每一个图像部分中的对象的信息来获得用于将虚拟对象图像30添加到对象的一个区域的位置信息。将参考图9a和图9b描述处理器140识别对象并将虚拟对象图像30添加到对象的方法。
图9a是示出根据本公开的实施例的识别对象的方法的图。
参考图9a,根据本公开的实施例的处理器140可以识别包括在多个图像部分中的每一个图像部分中的对象50,并获得关于对象50的信息。作为示例,处理器140可以将视频应用于学习网络模型,并且获得关于包括在多个图像部分中的每一个图像部分中的对象50的信息。例如,学习网络模型50可以识别包括在多个图像部分中的每一个图像部分中的对象50的类型。然后,学习网络模型50可以基于识别出的对象50的类型来识别对象50的形式或尺寸中的至少一个。作为示例,学习网络模型50可以包括关于对象50的信息,该信息包括多个对象50中的每一个对象的形式或尺寸信息中的至少一个。学习网络模型可以基于与识别出的对象50相对应的、关于对象50的信息来识别对象50的形式或尺寸中的至少一个。这里,对象50的形式是根据对象50和外部之间的边界表面定义的对象50的示意形状、形式等,并且对象50的形式可以指长方体、立方体、圆形、椭圆形等。对象50的尺寸可以包括基于对象的宽度(或水平长度)、高度和深度的w*h*d(mm)信息。这里,长度单位显然不限于毫米,并且对象50的尺寸显然可以基于各种单位(诸如英寸(in)、英尺(ft)等)来表示。
参考图9a,学习网络模型可以识别包括在多个图像部分中的每一个图像部分中的对象50的类型是洗衣机,并且获得关于该洗衣机的信息,该信息包括洗衣机的形式或尺寸中的至少一个。例如,学习网络模型可以将长方体识别为洗衣机的形式,并且获得关于定义长方体尺寸的宽度、高度和深度的信息作为对象50的尺寸信息。
这里,学习网络模型可以是基于多个样本图像训练的卷积神经网络模型(cnn)。这里,cnn是具有为图像处理、语音处理、对象识别等设计的特殊连接结构的多层神经网络。具体地,cnn可以通过对包括在输入视频中的像素进行预处理,以各种方式对视频进行滤波,并辨识视频的特征。作为示例,cnn可以辨识包括在视频中的对象的类型、形式或尺寸中的至少一个。同时,学习网络模式显然不限于cnn。例如,显然,图像处理设备100可以使用基于各种神经网络(诸如递归神经网络(rnn)、深度神经网络(dnn)、生成式对抗网络(gan)等)的学习网络模型。
作为另一个示例,根据本公开的实施例的处理器140可以分析多个图像部分中的每一个图像部分,并且获得对象50的外部信息。例如,处理器140可以基于对象50的外边缘线来识别对象50的2d形状。然后,处理器140可以识别以不同观看方向或不同距离捕获对象50的多个2d图像当中与识别出的2d形状的相似度大于或等于阈值的2d图像。然后,处理器140可以基于识别出的2d图像来识别包括在视频中的对象50的类型、形式或尺寸中的至少一个。
作为示例,参考图9a,如果基于包括在视频中的对象50的外边缘线将2d形状识别为菱形,则处理器140可以识别对象50与在相机120的观看方向、角度或姿态中识别出的菱形具有大于或等于阈值的相似性。如果识别出的对象50是洗衣机,则处理器140可以获得包括该洗衣机的形式和尺寸的信息。
此外,根据本公开的实施例的处理器140可以识别对象50的位置。作为示例,处理器140可以将视频应用于学习网络模型并识别空间的形式,并且识别对象50的位置。例如,学习网络模型可以基于围绕空间的墙面或位于空间中的家具、台阶、家用电器、门槛等来识别空间的面积、尺寸、形状等,并且识别对象50的位置。
然后,根据本公开的实施例的处理器140可以基于多个图像部分中的每一个图像部分中的对象50的位置信息来获得用于将虚拟对象图像30添加到对象50的一个区域的位置信息。然后,处理器140可以获得形状上与关于相机120的观看方向的信息相对应的虚拟对象图像30,并且基于位置信息将获得的虚拟对象图像30添加到相应的图像部分,并且提供图像。
图9b是示出根据本公开的实施例的添加虚拟对象图像的方法的图。
参考图9b,处理器140可以基于关于对象50的信息来识别虚拟对象图像30可以被添加到的区域。例如,处理器140可以基于包括在关于对象50的信息中的对象50的形式来获得用于添加虚拟对象图像30的位置信息。如图9b所示,处理器140可以基于洗衣机的长方体形式来识别将虚拟对象图像30添加到上端是可能的。然后,处理器140可以获得形状上与关于相机120的观看方向的信息相对应的虚拟对象图像30,并且基于位置信息将获得的虚拟对象图像添加到相应的图像部分。电子设备100可以通过一个视频提供空间中存在的对象50和虚拟对象图像30。同时,添加的虚拟对象图像30的位置、尺寸等显然可以根据用户命令而改变。例如,如图9b所示,虚拟对象图像30的位置不固定到对象50的上侧,并且其根据用户操纵显然可以位于空间底部上的平面空间中。
同时,处理器140可以基于包括在关于对象50的信息中的对象50的尺寸来调整虚拟对象图像30的尺寸,并将该图像添加到图像部分。根据本公开的实施例的处理器140可以基于位置信息和3d网格数据来重新调整虚拟对象图像30的尺寸,并添加图像。作为示例,如果根据用于添加虚拟对象图像30的位置信息确定识别出的对象50的面积小于虚拟对象图像30的尺寸,则处理器140可以基于位置信息调整虚拟对象图像30的尺寸并将图像添加到图像部分。同时,这仅仅是示例,并且虚拟对象图像30的尺寸不一定必须被重新调整为使得尺寸变得更小。例如,处理器140可以基于对象50的尺寸和基于网格数据的3d虚拟对象的尺寸,将虚拟对象图像30的尺寸调整为与对象50的实际尺寸成比例,并将图像添加到图像部分。
回到图1,如果输入了用于将另一个虚拟对象图像添加到虚拟对象图像30的一个区域的用户命令,则根据本公开的实施例的处理器140可以基于关于虚拟对象图像30的信息控制显示器110以层叠在虚拟对象图像上的形式显示另一个虚拟对象图像。将参考图10对此进行详细解释。
图10是示出根据本公开的实施例的多个虚拟对象图像的图。
参考图10,处理器140可以向视频添加多个虚拟对象图像。例如,在虚拟对象图像30被添加到图像部分之后,处理器140可以根据用户命令将另一个虚拟对象图像30’添加到图像部分。在这种情况下,处理器140可以基于关于虚拟对象图像30的信息将另一个虚拟对象图像30’添加到图像部分。这里,关于虚拟对象图像30的信息可以指与虚拟对象图像30相对应的3d虚拟对象的网格数据。处理器140可以基于3d虚拟对象的网格数据识别虚拟对象图像30的形式、尺寸等,并且在将另一个虚拟对象图像30’添加到图像部分时,处理器140可以考虑虚拟对象图像30的形式和尺寸。这里,虚拟对象图像30的尺寸可以指虚拟对象图像30的高度、宽度和深度。
如图10所示,处理器140可以基于虚拟对象图像30的尺寸,在距离底部与虚拟对象图像30的高度一样远的位置添加另一个虚拟对象图像30’。通过提供其中虚拟对象图像30和另一个虚拟对象图像30’交互的视频,处理器140可以向用户提供好像虚拟对象图像30和另一个虚拟对象图像30’实际存在的视频。
回到图1,如果输入了用于移除虚拟对象图像30的命令,则根据本公开的实施例的处理器140可以移除虚拟对象图像30。然后,处理器140可以调整以层叠在虚拟对象图像30上的形式添加的另一个虚拟对象图像30’的位置。将参考图11对此进行详细解释。
图11是示出根据本公开的实施例移除虚拟对象图像的情况的图。
参考图11,处理器140可以根据用户命令移除被添加到图像部分的虚拟对象图像30。如图10所示,如果接收到用于移除以层叠在虚拟对象图像30上的形式添加的另一个虚拟对象图像30’的命令,则处理器140可以移除另一个虚拟对象图像30’并维持虚拟对象图像30。
作为另一个示例,如果接收到用于移除位于另一个虚拟对象图像30’的下部的虚拟对象图像30的命令,则处理器140可以移除虚拟对象图像30,然后调整另一个虚拟对象图像30’的位置。由于处理器140基于关于虚拟对象图像30的信息添加了另一个虚拟对象图像30’,并且在距离底部与虚拟对象图像30的高度一样远的位置添加了另一个虚拟对象图像30’,所以处理器140可以根据用于移除虚拟对象图像30的命令来识别用于添加另一个虚拟对象图像30’的新的位置信息。
作为示例,处理器140可以基于关于对象50的信息和关于平面空间的信息20-1,重新获得用于调整另一个虚拟对象图像30’的位置的位置信息。然后,处理器140可以基于重新获得的位置信息来调整另一个虚拟对象图像30’的位置。同时,如果重新获得了多个位置信息,则处理器140可以识别最小化与多个位置信息当中、另一个虚拟对象图像30’所位于的先前位置信息的差的一个位置信息。作为示例,参考图11,处理器140可以获得对象50的一个区域和底部上的平面空间的一个区域作为位置信息。然后,由于位置从用x、y和z轴定义的另一个虚拟对象图像30’的位置坐标值到底部上的平面空间的一个区域的移动只需要改变一个轴(例如,y轴)的位置坐标值,这与位置到对象50的一个区域的移动不同,所以处理器140可以将另一个虚拟对象图像30’移动到底部上的平面空间的一个区域。处理器140可以控制显示器110在移除了对象图像30的位置中显示另一个对象图像30’。
作为另一个示例,如果在虚拟对象图像30和另一个虚拟对象图像30’层叠的同时输入用于移除虚拟对象图像30的命令,则处理器140可以基于物理引擎提供好像虚拟对象图像30’根据重力落到底部上的平面空间的视觉反馈。
回到图1,根据本公开的实施例的处理器140可以获得包括在多个图像部分中的每一个图像部分中的关于对象50的信息以及关于对象50所位于的空间的形式的信息,并且将这些信息存储为空间信息20,并且如果输入了用于利用虚拟对象替换对象50的用户命令,则处理器140可以基于关于对象50的信息和关于空间的形式的信息将虚拟对象图像30与对象50重叠,并显示图像。将参考图12对此进行详细解释。
图12是示出根据本公开的实施例的替换对象的方法的图。
参考图12,根据本公开的实施例的处理器140可以分析多个图像部分,并获得关于对象50所位于的空间的形式的信息。作为示例,处理器140可以将多个图像部分应用于学习网络模型,并识别空间的形式。这里,关于空间的形式的信息可以包括基于围绕空间的墙面或位于空间中的家具、台阶、家用电器、门槛等的空间的面积、尺寸和形状信息。
然后,如果输入了用于利用3d虚拟对象替换包括在图像部分中的对象50的用户命令,则根据本公开的实施例的处理器140可以基于关于对象50的信息将虚拟对象图像30与对象50重叠并显示图像。
这里,处理器140可以基于关于空间的形式的信息,防止在穿过除了对象50之外的墙面和门槛的同时添加虚拟对象图像30。同时,根据本公开的实施例的处理器140可以基于3d虚拟对象的信息(即,网格数据)获得关于3d虚拟对象的形式和尺寸的信息。然后,如果3d虚拟对象的尺寸大于对象50的尺寸,则处理器140可以将与3d虚拟对象相对应的虚拟对象图像30与对象50重叠,并显示图像,如图12的上部所示。同时,虚拟对象图像30的位置和尺寸可以根据用户输入而明显改变。
作为另一个示例,如果对象50的尺寸大于3d虚拟对象的尺寸,则处理器140可以将与3d虚拟对象相对应的虚拟对象图像30与对象50的一个区域重叠,并显示图像,如图12的下部所示。
图13是示出根据本公开的实施例的对象和虚拟对象图像的交互的图。
参考图13,根据本公开的实施例的处理器140可以使用用于添加虚拟对象图像30的深度数据。这里,深度数据可以指相机120和对象50之间的距离数据。根据本公开的实施例的电子设备100中提供的相机120可以包括深度相机。根据实施例的深度相机可以通过使用飞行时间(tof)方法来测量光在发射后被反射回来的时间。然后,处理器140可以基于测量的tof计算相机120和对象50之间的距离。然后,处理器140可以获得每个对象50的深度数据。
作为另一个示例,处理器140可以通过相机120获得多个图像,分析多个图像,并且识别位于离相机120较近距离的对象或者位于较远距离的对象。作为又一个示例,处理器140显然可以将学习网络模型应用于视频,并且识别包括在视频中的对象和相机120之间的距离,并且获得深度数据。
根据本公开的实施例的处理器140可以执行控制,使得虚拟对象图像30的部分不是基于深度数据、通过显示器110来提供的。作为示例,如果基于深度数据识别出添加虚拟对象图像30的位置比对象50更远,则处理器140可以提供虚拟对象图像30的一个区域被对象50覆盖的效果。例如,处理器140可以通过首先渲染位于远距离的虚拟对象图像30,然后渲染位于近距离的对象50以与虚拟对象图像30重叠,来提供视频。根据本公开的实施例的处理器140可以基于深度数据识别对象之间的距离信息以及相机120和对象之间的距离信息,并且根据基于此的遮挡掩模,位于距相机120较远距离的对象可以首先被绘制,然后位于较近距离的对象逐个覆盖,并且可以添加虚拟对象图像30,使得虚拟对象图像30的部分被对象覆盖。
回到图1,根据本公开的实施例的电子设备100可以包括通信器(未示出)。将参考图2对通信器进行详细解释。
根据本公开的实施例的处理器140可以控制通信器将存储在存储器130中的多个图像部分和被映射到多个图像部分中的每一个图像部分的空间信息发送到外部设备。
如果从外部设备接收到基于多个图像部分和被映射到多个图像部分中的每一个图像部分的空间信息添加了另一个虚拟对象图像的视频,则根据本公开的实施例的处理器140可以控制显示器利用包括在接收到的视频中的另一个虚拟对象图像来替换虚拟对象图像,并显示该另一个虚拟对象图像。将参考图14对此进行详细解释。
图14是示出根据本公开的另一个实施例的虚拟对象图像的图。
根据本公开的各种实施例的处理器140可以将在图像部分中获得的空间信息20存储在存储器130中、或者将空间信息20发送到外部设备。处理器140可以将虚拟对象图像30添加到存储在存储器130中的视频10,而不是添加到基于空间信息20、通过相机120实时捕获的视频10,并且向用户提供类似增强现实的效果。
根据本公开的实施例,如果外部设备基于从电子设备100接收到的视频10和空间信息20将另一个虚拟对象图像30’添加到视频10,则处理器140可以从外部设备接收关于另一个虚拟对象图像30’的信息,并且基于关于另一个虚拟对象图像30’的信息将另一个虚拟对象图像30’添加到视频10。
参考图14,如果从外部设备接收到添加了另一个虚拟对象图像30’的视频,则处理器140可以利用另一个虚拟对象图像30’替换虚拟对象图像30并显示该另一个虚拟对象图像30’。
根据本公开的实施例的处理器140可以通过通信器执行与外部设备的通信,并且共享添加了虚拟对象图像30的视频10’。如果在外部设备中,虚拟对象图像30被改变为另一个虚拟对象图像30’,则处理器140可以利用另一个虚拟对象图像30’替换虚拟对象图像30,并显示视频10’。作为另一个示例,处理器140可以显示通知ui,该通知ui通知在外部设备中选择了另一个虚拟对象图像30’。作为又一个示例,处理器140可以以pip模式在显示器110上显示视频10和正在外部设备上显示的另一个虚拟对象图像30’。
回到图1,如果输入了用于改变包括在显示的视频10’中的虚拟对象图像30的位置或旋转中的至少一个的用户命令,则根据本公开的实施例的处理器140可以获得与用户命令相对应的方向信息或距离信息中的至少一个,基于获得的信息,获得多个虚拟对象图像当中与用户命令相对应的虚拟对象图像30,并控制显示器110显示该虚拟对象图像30。将参考图15对此进行详细解释。
图15是示出根据本公开的实施例的虚拟对象图像的位置或旋转的改变的图。
参考图15,根据本公开的实施例的处理器140可以基于关于平面空间的信息20-1获得用于添加虚拟对象图像30的位置信息,并且获得形状上与关于观看方向的信息20-2相对应的虚拟对象图像30。同时,可以假设需要对获得的虚拟对象图像30位置、方向等进行详细调整的情况。
如果输入了用于改变虚拟对象图像30的位置或旋转中的至少一个的用户命令,则根据本公开的实施例的处理器140可以获得以不同方向或不同距离捕获3d虚拟对象图像的多个虚拟对象图像当中、与用户命令相对应的虚拟对象图像30,并将该图像添加到视频10。
图16是示出根据本公开的实施例的获得虚拟对象图像的方法的图。
根据本公开的实施例的处理器140可以基于关于目标电子设备的信息来控制显示器110显示包括至少一个模块图像的ui。
然后,处理器140可以基于由用户输入在至少一个模块当中选择的模块图像来获得模块型电子设备,并且获得与所获得的模块型电子设备相对应的虚拟对象图像30。这里,虚拟对象图像30可以是与模块型电子设备相对应的ar对象。模块可以指用于提供电子设备的各种功能当中的功能的独立组件,并且模块型电子设备可以指包括单个模块或至少两个模块的电子设备。
作为示例,处理器140可以基于关于目标电子设备的信息来识别可以被选择的多个模块。这里,关于目标电子设备的信息可以包括关于电子设备的类型的信息、可以根据模型名称选择的多个模块图像、可以添加的多个功能以及可以移除的多个功能。
然后,处理器140可以基于根据用户输入在至少一个模块图像当中选择的至少一个模块图像来获得与模块型电子设备相对应的虚拟对象图像30。这里,每个模块可以具有不同的尺寸、功能和形式。同时,显然,关于目标电子设备的信息可以被预先存储在电子设备100中、或者可以从外部服务器被接收。
例如,如果目标电子设备被假设为冰箱,则处理器140可以识别可以在冰箱中被选择的多个模块。这里,多个模块中的每一个模块可以被分成与冷藏室、冷冻室和温度转换室相对应的模块。此外,与冷藏室相对应的模块可以根据尺寸或形式中的至少一个被分成第一到第n冷藏室。
作为另一个示例,与冷冻室相对应的模块可以根据尺寸或形式中的至少一个被分成第一至第n冷冻室。
参考图16,处理器140可以获得与模块型电子设备相对应的虚拟对象图像30,该虚拟对象图像30包括根据用户输入、在与多个模块中的每一个模块相对应的模块图像中选择的第一冷藏室30-1、第二冷藏室30-2、第一冷冻室30-3和第一温度转换室30-4。
同时,根据本公开的实施例,基于处理器140提供可以基于关于目标电子设备的信息来选择的模块,并且获得与包括根据用户输入所选择的至少一个模块的模块型电子设备相对应的虚拟对象图像30的情况的假设进行了解释,但是本公开显然不限于此。例如,显然,处理器140可以获得与模块型电子设备相对应的虚拟对象图像30,该模块型电子设备包括其尺寸和形式是根据用户输入以各种方式定义的至少一个模块。
作为另一个示例,处理器140可以通过提供与目标电子设备相对应的基本图像,并且根据用户输入改变尺寸或形式中的至少一个,或者添加模块,来明显地获得虚拟对象图像30。例如,如果模块型电子设备是冰箱,则处理器140可以通过提供包括第一冷藏室30-1和第二冷藏室30-2的基本图像,并且根据用户输入改变第一冷藏室30-1和第二冷藏室30-2中的至少一个的尺寸或形式,或者添加第一冷冻室30-3,来明显地获得虚拟对象图像30。
同时,目标电子设备不限于冰箱,并且目标电子设备显然可以包括显示设备、诸如空调的空气调节设备、诸如洗衣机的各种类型的家用电器、诸如在产品制造过程中使用的工业机器人的智能机器等。例如,处理器140可以获得与包括第一显示模块和第二显示模块的显示设备相对应的虚拟对象图像30。这里,第一显示器和第二显示器中的每一个的尺寸或形式中的至少一个显然可以根据用户输入而改变。
参考图16,处理器140可以获得与包括用户所期望的模块的模块型电子设备、或定制的模块型电子设备相对应的虚拟对象图像30。
然后,根据本公开的实施例的处理器140可以提供用于改变模块型电子设备的颜色、材料等的ui。参考图16,如果接收到用于改变包括在虚拟对象图像中的至少一个模块图像的颜色或材料中的至少一个的用户命令,则处理器140可以基于用户命令改变虚拟对象图像30。当显示其中颜色或材料中的至少一个根据用户命令被改变的虚拟对象图像30时,用户可以检查其颜色、材料等被定制的模块型电子设备。这里,颜色和材料可以指被应用于模块型电子设备的主体的颜色和材料。例如,如果模块型电子设备是冰箱,则冰箱可以包括其前表面打开的主体、形成在主体内部并且其中食物被冷藏和/或保存的储藏室、以及打开或关闭主体的打开的前表面的门。处理器140可以根据用户输入改变门的颜色和材料。然而,这仅仅是示例,并且处理器140显然可以根据用户输入改变储藏室的颜色和材料。
参考图16,根据本公开的实施例的处理器140可以限制性地提供用户可以基于关于目标电子设备的信息而选择的颜色和材料。作为示例,如果模块型电子设备是冰箱,则处理器140可以提供白色、木炭色和薄荷色作为可以选择的颜色,并且提供金属、消光玻璃(mattingglass)和光泽玻璃(glossyglass)作为可以选择的材料。然而,根据本公开的实施例提及的详细颜色和材料仅仅是示例,并且显然可以提供各种颜色和材料。
作为另一个示例,显然,处理器140可以提供ui,通过该ui,用户可以没有限制地选择用户想要的各种颜色和材料,并且获得应用了根据用户输入而选择的颜色和材料的虚拟对象图像30。
参考图16,在由多个模块组成的模块型电子设备中,处理器140可以获得其中与用户输入相对应的颜色被应用于多个模块中的每一个模块的虚拟对象图像30。例如,处理器140可以获得虚拟对象图像30,在该虚拟对象图像30中,白色被应用于第一冷藏室30-1和第二冷藏室30-2,木炭色被应用于第一冷冻室30-3,并且薄荷色被应用于第一温度转换室30-4。作为另一个示例,处理器140显然可以获得虚拟对象图像30,在该虚拟对象图像30中,相同的颜色被应用于第一冷藏室30-1和第二冷藏室30-2、第一冷冻室30-3和第一温度转换室30-4。
然后,根据本公开的实施例的处理器140可以将虚拟对象图像30添加到视频10。根据本公开的实施例的处理器140可以根据针对虚拟对象图像30的用户输入在视频10的一个区域中定位虚拟对象图像30。
作为另一个示例,处理器140显然可以将虚拟对象图像30和视频10应用于学习网络模型,并且识别其中虚拟对象图像30在视频10内可以位于的区域,并且在该区域中定位虚拟对象图像30。
根据本公开的实施例的处理器140可以提供请求模块型电子设备的订单(order)的功能。作为示例,处理器140可以将虚拟对象图像30添加到视频10,并且在视频10内包括“订单”按钮。如果接收到针对该按钮的用户输入,处理器140可以将关于虚拟对象图像30的信息发送到外部服务器。这里,外部服务器可以指模块型电子设备的制造商。显然,关于虚拟对象图像30的信息可以包括根据用户输入而选择的模块、颜色和材料,或者根据用户输入而改变的尺寸、形式等。
根据本公开的另一个实施例的处理器140可以基于模块型电子设备的类型或模型名称来识别是否可以生产根据用户输入而获得的模块型电子设备。作为示例,根据模块型电子设备的模型名称,可以添加的功能、可以选择的模块数量等可能存在限制。处理器140可以向外部服务器发送关于虚拟对象图像30的信息,并且从外部服务器接收关于制造商是否可以生产与虚拟对象图像30相对应的模块型电子设备的信息。作为另一个示例,处理器140显然可以自己识别是否可以生产与虚拟对象图像30相对应的模块型电子设备。
根据本公开的实施例,如果识别出不能生产根据虚拟对象图像30的模块型电子设备,则处理器140可以向虚拟对象图像30应用并提供视觉反馈。例如,处理器140可以模糊虚拟对象图像30、或者将红色背景颜色应用于虚拟对象图像30。然而,这仅仅是示例,显然可以提供各种视觉反馈,诸如警告弹出窗口或听觉反馈。
图17是示出根据本公开的实施例的虚拟对象图像的图。
参考图17中的(a),处理器140可以基于关于目标电子设备的信息来识别可以添加或移除的多个功能,并且获得与其中根据用户输入添加或移除了一些功能的模块型电子设备相对应的虚拟对象图像30。
作为示例,如果假设目标电子设备为冰箱,则冰箱可以包括打开或关闭其中冷藏和/或保存食物的储藏室的前表面的门。如果在可以添加的多个功能当中选择了显示器30-5,则根据本公开的实施例的处理器140可以在将显示器30-5布置在门上与用户输入相对应的位置的同时,获得虚拟对象图像30。作为另一个示例,处理器140可以在以与用户输入相对应的尺寸布置显示器30-5的同时,获得虚拟对象图像30。作为又一个示例,参考图17,处理器140显然可以获得与冰箱相对应的虚拟对象图像30,在该虚拟对象图像30中,根据用户输入添加或移除了净水功能。
参考图17中的(b),如果根据用户输入在多个模块当中选择了左上部中的冷藏室模块、左下部中的冷藏室模块和右部中的冷冻室模块,则处理器140可以获得与包括所选模块相对应的冰箱的虚拟对象图像30。然后,处理器140显然可以根据用户输入改变每个模块的布置形式、尺寸、颜色、材料等。
图18是示出根据本公开的实施例的对象的图。
参考图18,根据本公开的实施例的处理器140可以识别包括在视频10中的对象50。作为示例,处理器140可以识别包括在视频10中的对象50的类型或模型名称中的至少一个。例如,处理器140可以将视频10应用于学习网络模型,并且识别包括在视频10中的对象50的类型或模型名称中的至少一个。作为另一个示例,处理器140显然可以从用户输入获得包括在视频10中的对象50的类型或模型名称。
然后,处理器140可以根据用户输入、基于关于所识别出的类型或模型名称的信息来识别可添加的功能、可移除的功能、可选择的颜色或可选择的材料等。参考图18,处理器140可以识别包括在视频10中的洗衣机,并且基于关于所识别出的洗衣机的信息(例如,洗衣机的模型名称)识别可以选择的颜色或可以选择的材料中的至少一个。然后,处理器140可以将根据用户输入而选择的颜色或材料中的至少一个应用于对象50并显示视频10。
图19是示出根据本公开的另一个实施例的虚拟对象图像的图。
参考图19,虚拟对象图像30显然可以对应于除了模块型电子设备之外的模块型家具、室内墙面、室内附件、家居用品等。
作为示例,处理器140可以获得与家具相对应的虚拟对象图像30,其中尺寸、形式、颜色或材料中的至少一个是根据用户输入定义的。然后,处理器140可以将虚拟对象图像30添加到视频10。
作为另一个示例,处理器140可以基于关于模块型家具的信息来识别可以被选择的多个模块。这里,模块可以指最小单位的独立组件,其可以作为家具执行功能,并且模块型家具可以指包括单个模块或至少两个模块的家具。例如,五列模块型橱柜可以是包括五个独立的一列橱柜的家具。处理器140可以获得与模块型家具相对应的虚拟对象图像30,该模块型家具包括根据用户输入在多个模块当中选择的模块。
参考图19,处理器140可以获得与模块型家具相对应的虚拟对象图像30,该模块型家具包括根据用户输入选择的第一储藏室家具至第n储藏室家具。然后,处理器140可以提供可以改变每个模块的颜色或材料的ui。
然后,处理器140可以将应用了根据用户输入的颜色或材料的虚拟对象图像30添加到视频10,并提供视频10。这里,可以由用户选择的颜色或材料可以基于关于模块型家具的信息而受到限制。作为示例,处理器140可以从外部服务器接收关于模块型家具的信息,并且关于模块型家具的信息可以包括关于可以在模块型家具中选择的多个模块的信息、关于可以选择的颜色的信息、关于可以选择的材料的信息等。处理器140可以仅显示可以基于该信息而选择的颜色或材料。
处理器140显然可以根据用户输入改变包括在模块型家具中的模块的尺寸或布置形式。
根据本公开的实施例的处理器140可以提供请求模块型家具的订单的功能。作为示例,处理器140可以将虚拟对象图像30添加到视频10,并且在视频10内包括“订单”按钮。如果接收到针对该按钮的用户输入,处理器140可以将关于虚拟对象图像30的信息发送到外部服务器。这里,外部服务器可以指模块型家具的制造商。显然,关于虚拟对象图像30的信息可以包括根据用户输入而选择的模块、颜色和材料,或者根据用户输入而改变的尺寸、布置形式等。
图2是示出图1所示的电子设备的详细配置的框图。
参考图2,根据本公开的实施例的电子设备100可以包括显示器110、相机120、存储器130、处理器140、通信器150和用户界面160。在图2所示的组件当中,关于与图1所示的组件重叠的组件,将省略详细说明。
存储器130可以被实现为包括在处理器140中的内部存储器,诸如rom(例如,电可擦除可编程只读存储器(eeprom))、ram等,或者被实现为与处理器140分离的存储器。在这种情况下,存储器130可以以嵌入在电子设备100中的存储器的形式实现、或者以能够根据对存储的数据的使用而附接到电子设备100或从电子设备100拆卸的存储器的形式实现。例如,在用于驱动电子设备100的数据的情况下,该数据可以被存储在嵌入在电子设备100中的存储器中,并且在用于电子设备100的扩展功能的数据的情况下,该数据可以被存储在可以附接到电子设备100或从电子设备100拆卸的存储器中。同时,在存储器嵌入在电子设备100中的情况下,存储器可以被实现为易失性存储器(例如,动态ram(dram)、静态ram(sram)、或同步动态ram(sdram)等)、或者非易失性存储器(例如:一次性可编程rom(otprom)、可编程rom(prom)、可擦除可编程rom(eprom)、电可擦除可编程rom(eeprom)、掩膜型rom、闪存rom、闪存存储器(例如:nand闪存或nor闪存等)、硬盘驱动器或固态硬盘(ssd))中的至少一个。在可以附接到电子设备100或从电子设备100拆卸的存储器的情况下,存储器可以以诸如存储卡(例如,紧凑型闪存(cf)、安全数字(sd)、微型安全数字(micro-sd)、迷你安全数字(mini-sd)、极限数字(xd)、多媒体卡(mmc)等)、可以连接到usb端口的外部存储器(例如,usb存储器)等形式实现。
处理器140通过使用存储在存储器130中的各种程序来控制电子设备100的整体操作。
具体地,处理器140包括ram141、rom142、主cpu143、第一接口144-1至第n接口144-n和总线145。
ram141、rom142、主cpu143和第一到第n接口144-1到144-n可以通过总线145互连。
在rom142中,存储用于系统引导等的指令集等。当输入开启指令并供电时,主cpu143根据存储在rom142中的指令将存储在存储器130中的o/s复制到ram141中,并通过执行o/s来引导系统。当引导完成时,主cpu143将存储在存储器130中的各种应用程序复制到ram141中,并通过执行复制到ram141中的应用程序来执行各种操作。
主cpu143访问存储器130,并通过使用存储在存储器130中的o/s来执行引导。然后,主cpu143通过使用存储在存储器130中的各种程序、内容数据等来执行各种操作。
第一接口144-1至第n接口144-n与前述各种组件连接。接口之一可以是通过网络与外部设备连接的网络接口。
同时,处理器140可以执行图形处理功能(视频处理功能)。例如,处理器140可以通过使用操作部分(未示出)和渲染部分(未示出)来生成包括各种对象(如图标、图像和文本)的屏幕。这里,操作部分(未示出)可以基于接收到的控制命令来操作属性值,诸如坐标值、形状、尺寸和颜色,通过这些属性值根据屏幕的布局来显示每个对象。然后,渲染部分(未示出)可以基于在操作部分(未示出)处操作的属性值,生成包括对象的、各种布局的屏幕。此外,处理器140可以执行各种图像处理,诸如视频数据的解码、缩放、噪声滤波、帧速率转换和分辨率转换。
同时,处理器140可以执行对音频数据的处理。具体地,在处理器140处,可以执行各种处理,诸如音频数据的解码或放大、噪声滤波等。
通信器150是根据各种类型的通信方法执行与各种类型的外部设备的通信的组件。通信器150包括wi-fi模块151、蓝牙模块152、红外通信模块153和无线通信模块154等。这里,每个模块可以以至少一个硬件芯片的形式实现。
处理器140可以通过使用通信器150来执行与各种类型的外部设备的通信。这里,外部设备可以包括如tv的显示设备、如机顶盒的图像处理设备、外部服务器、如遥控器的控制设备、如蓝牙扬声器的音频输出设备、照明设备、如智能吸尘器和智能冰箱的家用电器、如iot家庭管理器的服务器等。
wi-fi模块151和蓝牙模块152分别通过使用wi-fi方法和蓝牙方法来执行通信。在使用wi-fi模块151和蓝牙模块152的情况下,首先发送和接收诸如ssid和会话密钥的各种类型的连接信息,并且通过使用该信息来执行通信的连接,此后可以发送和接收各种类型的信息。
红外通信模块153根据通过使用可见光和毫米波之间的红外线将数据无线地发送到近场的红外数据协会(irda)技术执行通信。
无线通信模块154可以包括至少一个通信芯片,该通信芯片根据各种无线通信协议来执行通信,各种无线通信协议诸如除了上述通信方法之外的zigbee、第三代(3g)、第三代合作伙伴计划(3gpp)、长期演进(lte)、高级lte(lte-a)、第四代(4g)、第五代(5g)等。
除上述之外,通信器150可以包括局域网(lan)模块、以太网模块或有线通信模块中的至少一个,其通过使用成对电缆、同轴电缆或光纤电缆等来执行通信。
根据本公开的实施例,通信器150可以使用相同的通信模块(例如,wi-fi模块)以用于与外部设备(如遥控器)和外部服务器通信。
根据本公开的另一个实施例,通信器150可以使用不同的通信模块(例如,wi-fi模块)以用于与外部设备(如遥控器)和外部服务器通信。例如,通信器150可以使用以太网模块或wi-fi模块中的至少一个以用于与外部服务器通信、或者使用bt模块以用于与外部设备(如遥控器)通信。然而,这仅仅是示例,并且在与多个外部设备或外部服务器通信的情况下,通信器150可以使用各种通信模块当中的至少一个通信模块。
用户界面160可以被实现为如按钮、触摸板、鼠标和键盘的设备,或者被实现为能够执行上述显示功能和操纵输入功能两者的触摸屏。这里,按钮可以是形成在诸如电子设备100的主体的外部的前表面部分或侧表面部分、后表面部分等的任何区域中的各种类型的按钮,诸如机械按钮、触摸板、滚轮等。
根据本公开的实施例的电子设备100可以包括输入/输出接口(未示出)。输入/输出接口可以是高清晰度多媒体接口(hdmi)、移动高清晰度链路(mhl)、通用串行总线(usb)、显示端口(dp)、thunderbolt、视频图形阵列(vga)端口、rgb端口、d-超小型(d-sub)或数字视觉接口(dvi)中的任何一个的接口。
输入/输出接口可以输入和输出音频信号或视频信号中的至少一个。
取决于实现方式示例,输入/输出接口可以包括仅输入和输出音频信号的端口和仅输入和输出视频信号的端口作为单独的端口、或者被实现为输入和输出音频信号和视频信号两者的一个端口。
电子设备100可以被实现为不包括显示器的设备,并且将图像信号发送到单独的显示设备。
同时,电子设备100可以从包括麦克风的外部设备接收用户语音信号。在这种情况下,接收到的用户语音信号可以是数字语音信号,但是取决于实现方式示例,接收到的用户语音信号可以是模拟语音信号。作为示例,电子设备100可以通过诸如蓝牙和wi-fi等的无线通信方法接收用户语音信号。这里,外部设备可以被实现为遥控设备或智能手机。
电子设备100可以向外部服务器发送语音信号,以用于从外部设备接收的语音信号的语音辨识。
在这种情况下,用于与外部设备和外部服务器通信的通信模块可以被实现为一个模块、或者被实现为单独的模块。例如,通信模块可以通过使用蓝牙模块与外部设备通信,并且通过使用以太网调制解调器或wi-fi模块与外部服务器通信。
同时,根据实现方式示例,电子设备100还可以包括调谐器和解调部分。
调谐器(未示出)可以通过调谐由用户选择的信道或通过天线接收到的射频(rf)广播信号中所有预存储的信道来接收rf广播信号。
解调部分(未示出)可以接收在调谐器处转换的数字if(dif)信号并解调该信号,以及执行信道解调等。
扬声器(未示出)可以是不仅输出在输入/输出接口处处理的各种音频数据,而且输出各种通知声音或语音消息等的组件。
同时,电子设备100还可以包括麦克风(未示出)。麦克风是用于接收用户语音或其他声音的输入并将它们转换成音频数据的组件。
麦克风(未示出)可以在激活状态下接收用户的语音。例如,麦克风可以形成为被集成到电子设备100的上侧或前表面方向、侧表面方向等的集成类型。麦克风可以包括各种组件,诸如以模拟形式收集用户语音的麦克风、放大所收集的用户语音的放大器电路、对放大的用户语音进行采样并将用户语音转换成数字信号的a/d转换电路、从转换的数字信号中移除噪声分量的滤波电路等。
图20是示出根据本公开的实施例的电子设备的控制方法的流程图。
在根据本公开的实施例的电子设备的控制方法中,在操作s2010中,将通过相机实时捕获的视频识别为多个图像部分,并且获得与多个图像部分中的每一个图像部分相对应的空间信息。
然后,在操作s2020中,获得的空间信息被映射到多个图像部分中的每一个图像部分,并被存储。
然后,如果输入了用于将虚拟对象图像添加到视频的用户命令,则在操作s2030中,虚拟对象图像基于被映射到多个图像部分中的每一个图像部分的空间信息被添加到视频,并被显示。
这里,存储操作s2020可以包括获得多个图像部分中的每一个图像部分中的、关于平面空间的信息和关于相机的观看方向的信息,并将关于平面空间的信息和关于观看方向的信息存储为空间信息的操作。显示操作s2030包括以下操作:基于多个图像部分中的每一个图像部分中的、关于平面空间的信息来获得用于添加虚拟对象图像的位置信息;获得形状上与关于相机的观看方向的信息相对应的虚拟对象图像;以及将获得的虚拟对象图像添加到相应的图像部分并基于位置信息显示该虚拟对象图像。
在根据本公开的实施例获得关于相机的观看方向的信息的操作中,可以获得关于通过电子设备的加速度传感器或陀螺仪传感器中的至少一个获得的、相机的位置或姿态中的至少一个的信息作为关于相机的观看方向的信息。
根据本公开的实施例的显示操作s2030可以包括以下操作:基于获得用于基于在多个图像部分当中的至少一个图像部分中获得的空间信息来添加虚拟对象图像的多个位置信息,基于虚拟对象图像先前被添加到视频的历史信息来识别多个位置信息之一。
根据本公开的实施例的控制方法可以包括获得视频的操作,在该视频中基于在多个图像部分中的每一个图像部分中获得的关于观看方向的信息来重新排列多个图像部分的顺序,并且在显示操作s2030中,用于调整再现获得的视频的时间点的导航条可以与获得的视频一起显示。
这里,在获得其中多个图像部分的顺序被重新排列的视频的操作中,基于关于观看方向的信息,多个图像部分的顺序可以被重新排列,使得相机的观看方向从第一方向移动到第二方向。
根据本公开的实施例的控制方法可以包括将多个图像部分和被映射到多个图像部分中的每一个图像部分的空间信息发送到外部设备的操作。
此外,显示操作s2030可以包括以下操作:基于另一个虚拟对象图像基于从外部设备接收到多个图像部分和被映射到多个图像部分中的每一个图像部分的空间信息而被添加的视频,利用包括在接收到的视频中的另一个虚拟对象图像替换虚拟对象图像并显示该另一个虚拟对象图像。
根据本公开的实施例的虚拟对象图像可以是与以不同方向或不同距离捕获3d对象图像的多个虚拟对象图像当中的空间信息相对应的虚拟对象图像。
这里,显示操作s2030可以包括以下操作:基于输入对于包括在视频中的虚拟对象图像的位置或旋转的改变中的至少一个的用户命令,获得与用户命令相对应的方向信息或距离信息中的至少一个,基于获得的信息获得多个虚拟对象图像当中、与用户命令相对应的虚拟对象图像并显示该虚拟对象图像。
根据本公开的实施例的存储操作s2020可以包括获得包括在多个图像部分中的每一个图像部分中的关于对象的信息,并将该信息存储为空间信息的操作,并且显示操作s2030可以包括以下操作:获得用于基于在多个图像部分中的每一个图像部分中的关于对象的信息将虚拟对象图像添加到对象的一个区域的位置信息,以及获得形状上与关于相机的观看方向的信息相对应的虚拟对象图像,并基于位置信息将获得的虚拟对象图像添加到相应的图像部分并且显示该虚拟对象图像。
根据本公开的实施例的存储操作s2020可以包括获得包括在多个图像部分中的每一个图像部分中的关于对象的信息和其中对象所位于的空间的形状信息,并将这些信息存储为空间信息的操作,并且在显示操作s2030中,如果输入了用于利用虚拟对象替换对象的用户命令,则虚拟对象图像可以基于关于对象的信息和空间的形状信息与对象重叠并被显示。
这里,根据本公开的实施例的控制方法可以包括将视频应用于学习网络模型并获得包括在多个图像部分中的每一个图像部分中的关于对象的信息的操作,并且关于对象的信息可以包括对象的类型、形状、大小或位置中的至少一个。
此外,在显示操作s2030中,如果输入用于将另一个虚拟对象图像添加到虚拟对象图像的一个区域的用户命令,则可以控制显示器基于关于虚拟对象图像的信息、以层叠在虚拟对象图像上的形式显示另一个虚拟对象图像。此外,根据本公开的实施例的控制方法可以包括以下操作:基于输入用于移除虚拟对象图像的命令,移除虚拟对象图像,以及在其中移除了虚拟对象图像的位置显示另一个虚拟对象图像。
同时,根据本公开的前述各种实施例的方法可以以能够安装在传统电子设备上的应用的形式来实现。
此外,根据本公开的前述各种实施例的方法可以仅利用传统电子设备的软件升级或硬件升级来实现。
此外,本公开的前述各种实施例可以通过电子设备上提供的嵌入式服务器或者电子设备或显示设备中的至少一个的外部服务器来执行。
同时,根据本公开的实施例,上述各种实施例可以被实现为包括存储在机器可读存储介质中的指令的软件,这些指令可以由机器(例如:计算机)读取。机器是指调用存储在存储介质中的指令的设备,并且可以根据所调用的指令进行操作,并且设备可以包括根据前述实施例的电子设备(例如:电子设备a)。在指令由处理器执行的情况下,处理器可以自己或者通过使用在其控制下的其他组件来执行与该指令相对应的功能。指令可以包括由编译器或解释器生成或执行的代码。机器可读的存储介质可以以非暂时性存储介质的形式提供。这里,术语“非暂时性”仅指存储介质不包括信号,并且是有形的,但是不指示数据是半永久地还是临时地存储在存储介质中。
此外,根据本公开的实施例,根据前述各种实施例的方法可以在被包括在计算机程序产品中的同时被提供。计算机程序产品可以作为商品在卖方和买方之间进行交易。计算机程序产品可以以机器可读存储介质(例如:光盘只读存储器(cd-rom))的形式分发、或者通过应用商店(例如:playstoretm)在线分发。在在线分发的情况下,计算机程序产品的至少一部分可以至少暂时存储在存储介质(诸如制造商的服务器、应用商店的服务器或中继服务器的存储器)中、或者被暂时生成。
此外,根据上述各种实施例的每个组件(例如,模块或程序)可以由单个实体或多个实体组成,并且可以省略上述子组件当中的一些子组件,或者不同的子组件还可以包括在各种实施例中。可替代地或附加地,一些组件(例如:模块或程序)可以被集成到一个实体中,以在集成之前执行由每个组件执行的相同或相似的功能。根据各种实施例,由模块、程序或另一个组件执行的操作可以顺序地、并行地、重复地或以启发式方式执行,或者至少一些操作可以以不同的顺序被执行、省略或者不同的操作可以被添加。
此外,尽管已经示出和描述了本公开的优选实施例,但是本公开不限于上述特定实施例,并且显而易见的是,在不脱离如所附权利要求所要求保护的本公开的主旨的情况下,本公开所属技术领域的普通技术人员可以做出各种修改。此外,这种修改不应被解释为独立于本公开的技术思想或前景。
- 还没有人留言评论。精彩留言会获得点赞!