一种自动捕捉和追踪说话者的方法
本发明涉及声音与图像信息融合技术领域,特别是一种自动捕捉和追踪说话者的方法。
背景技术:
目前在普通的视频通话系统中,摄像头的位置和方向都是固定的,为了取得理想的视频通话效果,通话的双方或者多方必须在指定的范围内面向摄像头,以方便摄像头捕捉影像。然而,在实际使用中,往往存在一些应用场景,无法满足这个要求,例如:
(1)视频通话的一方无法掌握视频通话的知识。例如未成年的儿童和留守的老人,老人们由于掌握知识所限,无法掌握视频通话的操作要领。儿童天性好动,无法固定地呆在一个固定的位置。而针对这两类群体的视频通话却往往是比较迫切的需求。
(2)通话的一方本身就是处于运动状态,无法固定在一个确定的位置。比如通过远程视频通话进行授课的讲师、大堂的智能接待机器人迎接的客人等等。
(3)通话的一方不是单独的一个人,而是一群人。比如围在一个会议桌周围进行视频会议的小组。发言在小组成员之间切换,视频通话系统需要根据发言人的不同切换摄像头镜头,追踪发言人的声音和影像。
针对上述问题,通常的解决方案是通过手动或者遥控的方式来旋转摄像头,最终使镜头对准发言人,达到最好的视频通话效果。该方案首先需要增加额外的人力来进行这一项操作。其次,人工调节的速度慢,精度差,很难快速地捕捉发言人、跟上发言人切换的节奏。
技术实现要素:
为了解决上述问题,本发明提出了一种自动捕捉和追踪说话者的方法,通过声源定位和视觉识别,自动捕捉和追踪说话者,以使摄像头自动调整到使说话者位于摄像图像中心位置,实现摄像头自动调整并提高调整精度。
为了实现上述目的,本发明提供了一种自动捕捉和追踪说话者的方法,其特征在于,包括以下步骤:
(1)麦克风阵列收集外部声音信号并发送给中央处理器,中央处理器实时分析所述声音信号是否有有效声音输入,如果有有效声音输入则进入步骤(2),麦克风阵列包括多个麦克风;
(2)判断声音信号是否为人声信号,如果是非人声信号则返回步骤(1),如果是人声信号则进入步骤(3);
(3)采用声源定位算法分析出声音所在的方位,根据声音所在方位计算出摄像头模组的旋转角度,并根据旋转角度给旋转台发送控制指令,摄像头模组安装在旋转台上,旋转台可带动摄像头模组旋转;
(4)旋转台根据控制指令调整摄像头模组的位置,摄像头模组在调整位置的过程中,捕捉视频数据并发送给中央处理器,中央处理器采用人脸识别算法实时分析捕捉的画面中是否捕捉到人脸,如果捕捉到人脸,则进入步骤(5);
(5)中央处理器实时判断捕捉到的人脸图像是否达到最优,如果不是,则给旋转台发送控制指令,旋转台根据控制指令调整摄像头模组位置,不断地判断是否达到最优和调整摄像头模组,直至判断捕捉到的人脸图像达到最优。
本发明提供的进行自动捕捉和追踪的方法,通过麦克风阵列定位和人工智能视觉识别技术相结合,无需人工操作,就能够自动快速有效地定位视频通话中的当前说话者,使摄像头镜头始终能够快速地捕捉和追踪当前说话者,捕捉和追踪准确,精度高。在接收到声音后,除了判断音量大小外,还会对声音进行识别,识别出声音是人声后才会启动声音定位,声音的识别度更高,定位更准确、更快速。旋转台能够根据控制指令精确调整摄像头模组的位置,摄像头模组能主动、快速地寻找说话者,能精确捕捉到说话者的人脸并居中。
附图说明
图1为本发明自动捕捉和追踪说话者系统的结构示意图;
图2为麦克风阵列、摄像头模组和旋转台的位置关系示意图;
图3为自动捕捉和追踪说话者的方法的流程示意图。
下面结合附图对本发明作进一步详细说明。
具体实施方式
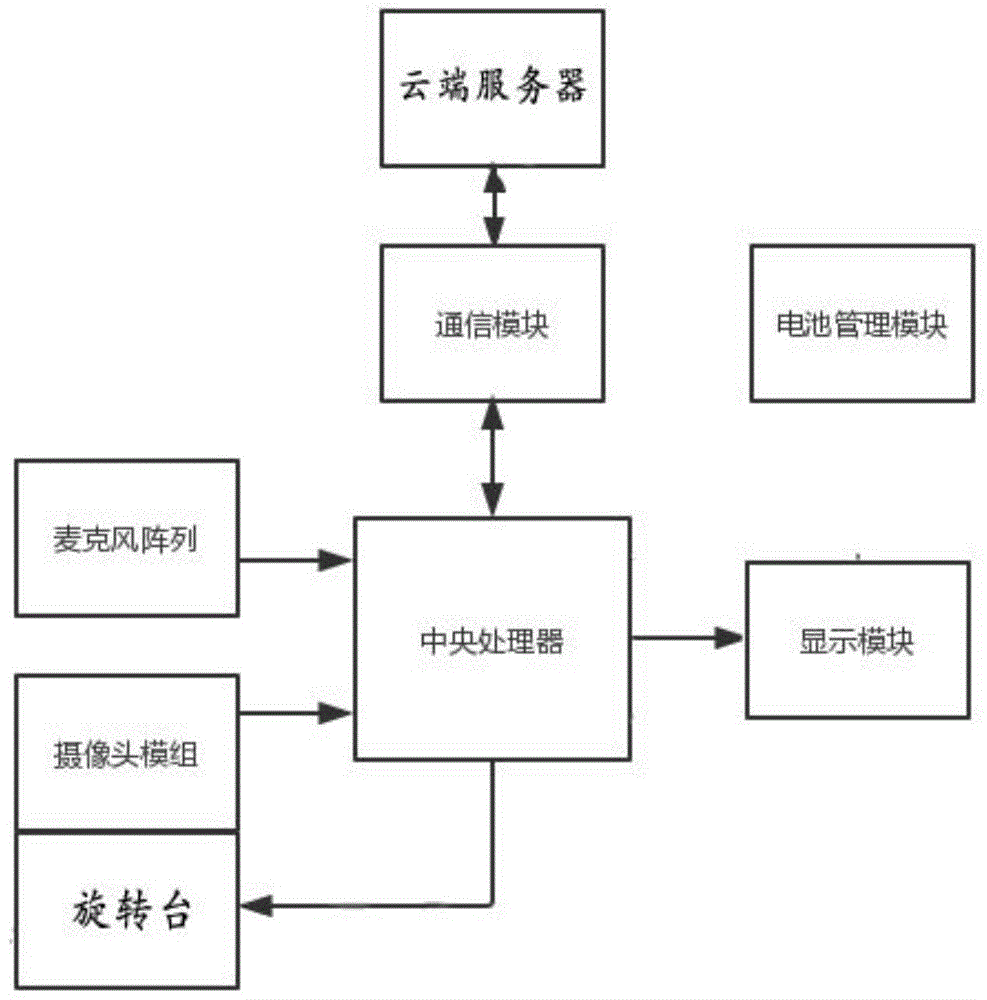
参见图1,自动捕捉和追踪说话者的装系统包括麦克风阵列、摄像头模组、中央处理器、显示模块、通信模块、电池管理模块和旋转台。
麦克风阵列包括多个(3个或3个以上)麦克风,麦克风采集声音信号,并将声音信号发送给中央处理器。所有麦克风各自独立地采集声音信号,且沿中心轴旋转对称布置在同一平面上,该中心轴垂直于该平面,相邻两个麦克风与中心轴的夹角相等。图2是麦克风阵列的一个较佳实施例,该阵列中有3个麦克风,3个麦克风1在同一个水平面上呈品字形排列,沿中心轴旋转对称布置,该中心轴线为垂线,相邻两个麦克风1与中心轴的夹角为120度。
摄像头模组2包含镜头、图像传感器和isp图像处理器,isp图像处理器也可以集成在中央处理器中。摄像头模组采集视频数据,并把采集的视频数据发送给中央处理器、显示模块和视频通话的其他通话终端,视频数据用于智能视觉识别和视频通话。摄像头模组设置在旋转台上,旋转台可以控制摄像头模组多角度旋转。参见图2,旋转台包括台架21、垂直转动轴22、转向控制电机23、水平转动轴24和俯仰角控制电机25。垂直转动轴22的旋转轴线为垂线,台架21设置在垂直转动轴22上,垂直转动轴22由转向控制电机23驱动旋转,从而带动台架21旋转。水平转动轴24、俯仰角控制电机25和摄像头模组2设置在台架21上,水平转动轴24的旋转轴线为水平线,水平转动轴24由俯仰角控制电机25驱动旋转,从而带动摄像头模组2旋转,实现摄像头模组2的仰俯角调整。转向控制电机23和俯仰角控制电机25均与中央处理器连接,受中央处理器控制,转向控制电机23可以控制摄像头模组的转向,使其指向当前视频通话的说话者;俯仰角控制电机25可以控制摄像头模组的仰俯角,确保当前视频通话的说话者处于摄像头捕捉的视频画面的正中央,达到最好的视频通话效果。在本实施例中,转向控制电机23和俯仰角控制电机25均采用步进电机,中央处理器通过脉冲信号控制电机。本实施例垂直转动轴的旋转轴线不限于垂线,水平转动轴的旋转轴线也不限于水平线,只要使垂直转动轴和水平转动轴的旋转方向不相同,即二者的旋转轴不共线也不平行,就可以实现摄像头模组多角度的调整。旋转台还可以是能够控制摄像头模组多角度旋转的其他结构。旋转台根据控制指令调整摄像头模组的位置,控制摄像头模组转向指定的位置。
本实施例垂直转动轴的旋转轴线为垂线,水平转动轴的旋转轴线为水平线,多个麦克风在水平面上沿中心轴旋转对称布置,垂直转动轴与中心轴共轴。这就使得多个麦克风与摄像头模组之间的位置相对确定,采用时延声源定位方法计算声源的方位时,能够建立起比较单价的数学模型,简化计算。
中央处理器(cpu)是整个系统的数据处理中心和控制中心,对接收到的声音信号进行识别并计算出摄像头模组的旋转角度,根据旋转角度给旋转台发送控制指令。中央处理器对接收到的视频数据采用人脸识别算法实时分析捕捉的画面中是否捕捉到人脸,并实时判断捕捉到的人脸图像是否达到最优。
显示模块用于视频通话,同时,会在显示模块中显示摄像头捕捉的视频,并在智能识别后提示识别效果,反馈给视频通话的说话者。
电池管理模块包含电池、电池充放电管理电路。该模块对电池的充放电进行管理,给系统的用于给麦克风阵列、摄像头模组、中央处理器、显示模块、俯仰角控制电机和转向控制电机提供稳定可靠的电源。配备该模块后,系统可以便携移动或者自行移动,消除电源线对装通置便携性的限制。
系统还包括通信模块和云端服务器。通信模块用于中央处理器与云端服务器和其他通话终端之间进行通信。在本实施例中,通信模块使用wifi技术,系统通过wifi连接到互联网,与云端服务器交换数据,与其他通话终端之间进行视频通话。通信模块也可以通过蜂窝移动网络、蓝牙或以太网与云端服务器进行通信。系统通过通信模块和云端服务器,能够达到最好的视频通话效果,并能够快速实时地追踪发言人。
上述系统实现的自动捕捉和追踪说话者的方法,包括以下步骤。
(1)系统开启后,麦克风阵列处于声音监听状态,收集外部声音信号并发送给中央处理器。由于环境噪声的存在,需要实时分析判断接收到的当前的声音信号是有效的声音输入还是周围的环境噪声,如果有有效声音输入则进入步骤(2)。在本实例中,采用最小值控制递归平均(mcra)算法来估计抑制噪声,采用最小均方自适应(lms)算法来增强语音信号。当经过这两个算法处理后的声音信号音量大于指定阀值时,即可认定声音输入有效。这两个算法比较成熟,运算量比较小,同时要求运算实时进行。本实例中将算法的实现放在中央处理器中运行。
(2)判断声音信号是否为人声信号,如果是非人声信号则返回步骤(1),麦克风阵列继续监听,如果是人声信号则进入步骤(3)。本实施例采用梅尔倒频谱(mfc)人声识别算法,将步骤(1)中的声音信号与通用人声模型进行匹配,判断声音信号是否为人声信号。由于该算法运算量较大,并且需要不断地改进、升级。本实例中由云端服务器运行该算法,通用人声模型存放在云端服务器上,中央处理器将步骤(1)处理后的声音数据通过通信模块上传到云端服务器,云端服务器运行该算法后再把人声识别结果通过通信模块发送给中央处理器。也可以由中央处理器运行该算法,通用人声模型也可存放在中央处理器上。
(3)启动声源定位算法,分析出声音所在的方位,中央处理器根据对声音所在方位的分析结果计算摄像头模组的旋转角度,根据旋转角度给旋转台发送控制指令,摄像头模组安装在旋转台上,旋转台可带动摄像头模组旋转。本实施例中,具体为把控制指令发送给转向控制电机和俯仰角控制电机。本实例采用达到时延声源定位方法计算出声源的方位,先计算声音达到麦克风阵列的各个麦克风的时延差,然后结合麦克风的空间布局,通过几何算法计算出声源的空间位置。这种方法的好处是计算量比较小,在近场语音、单一声源的情况下定位准确性比较高。在本实例中,麦克风阵列有三个麦克风,声源到达这三个麦克风的时刻是不相同的。通过比较三个麦克风的声音数据,可以计算出声音到达三个麦克风的时刻差,再结合三个麦克风的空间位置差异,通过几何算法,就可以定位出声源的空间位置。
在本实例中,声源定位算法在中央处理器中运行。声源定位算法也可以由云端服务器运行,中央处理器将步骤(2)处理后的声音数据通过通信模块上传到云端服务器,云端服务器运行该算法后再把处理结果通过通信模块发送给中央处理器。
(4)旋转台根据控制指令调整摄像头模组的位置,使得摄像头模组的摄像头转到步骤(3)中定位出的声源的空间位置,摄像头模组在调整位置的过程中,铺捉视频数据并发送给中央处理器。中央处理器通过人脸识别算法实时处理摄像头模组发送过来的视频数据,分析摄像头捕捉的画面中是否捕捉到人脸,如果铺捉到人脸,则进入步骤(5),如果没有铺捉到人脸,则继续调整摄像头模组。视频数据同时发送给显示模块和视频通话的其他通话终端。
本次实施例中人脸识别算法采用基于局部二值模式的人脸识别算法。由于传统的基于局部二值模式的人脸识别算法运算量较大、识别速度慢、识别准确度一般。在本次实例中根据实际情况对该算法进行了改进,在传统算法基础上加入了深度学习、神经卷积网络技术。在本实施例中,由于对计算的实时性要求比较高,人脸识别算法在中央处理器运行,该算法需要的数据和模型优选通过通信模块从云端服务器更新获取。
中央处理器在判断视频中是否捕捉到人脸前,先对视频数据进行光纤补偿和光照归一化预处理。
(5)中央处理器实时判断捕捉到的人脸图像是否达到最优,如果不是,则给旋转台发送控制指令,旋转台根据指令调整摄像头模组位置,不断地判断是否达到最优和调整摄像头模组,直至判断捕捉到的人脸图像居中并达到最优。
在该步骤中,还可以对说话者的身份进行自动识别。在人脸图像调整到最优之后,对人脸数据进行特征提取,然后将特征数据上传到云端服务器,由云端服务器对人脸进行身份识别,然后由云端服务器将身份识别的结果返回给中央处理器。
(6)判断视频通话是否结束,如果未结束,则返回步骤(1),麦克风阵列继续监听。这样在说话者变更或者说话者位置发生变化时,能够重新定位和追踪说话者,达到最佳的视频通话效果。
本发明通过麦克风阵列定位和人脸识别技术相结合,无需人工操作,就能够自动快速有效地定位视频通话中的当前说话者,使摄像头镜头始终能够快速地捕捉和追踪当前说话者,捕捉和追踪准确,精度高。在接收到声音后,除了判断音量大小外,还会对声音进行识别,识别出声音是人声后才会启动声音定位,声音的识别度更高,定位更准确、更快速。旋转台能够根据控制指令精确调整摄像头模组的位置,摄像头模组能主动、快速地寻找说话者,能精确捕捉到说话者的人脸并居中。
- 还没有人留言评论。精彩留言会获得点赞!