一种基于网络异常流量识别的入侵检测方法与流程
本发明涉及如何提高入侵检测系统性能领域,是一种流量异常入侵检测方法。
背景技术:
近年来,智能设备用户数量迅速增加,导致网络流量大幅上升,同时也带来了一些安全问题,如各种已知和未知的网络攻击。入侵检测系统(ids)是检测攻击的最佳方法之一,因为它涉及一个软件或硬件系统,可以跟踪、评估和检测内部和外部的活动。巨大的数据对入侵检测系统的性能产生了不利影响,并且在其流量中发现的冗余和不相关的信息也是入侵检测系统性能差的原因。因此,如何提高入侵检测系统的性能成为亟待解决的问题。
流量异常入侵检测方法早已受到研究者们的关注,已经提出了几种方法来提高入侵检测系统的性能,其中包括特征选择方法和优化技术。采用特征选择技术,通过选择最相关的特征来修剪大数据集中的高维数据,以避免在构建入侵检测系统模型时遇到维数灾难。所选特征是原始数据集的子集,用于简化模型构建,以便通过减少训练时间来提高执行时间。采用优化算法可以实现用一种简单的方法来解决复杂的问题,主要包括基于群体的算法、进化算法和基于轨迹的算法,通过优化模型参数或改进模型函数使模型在性能上达到更好的效果。上述方法在处理大量流量数据时有时会存在计算资源不足的情况,因此出现了处理效率低下的问题。
技术实现要素:
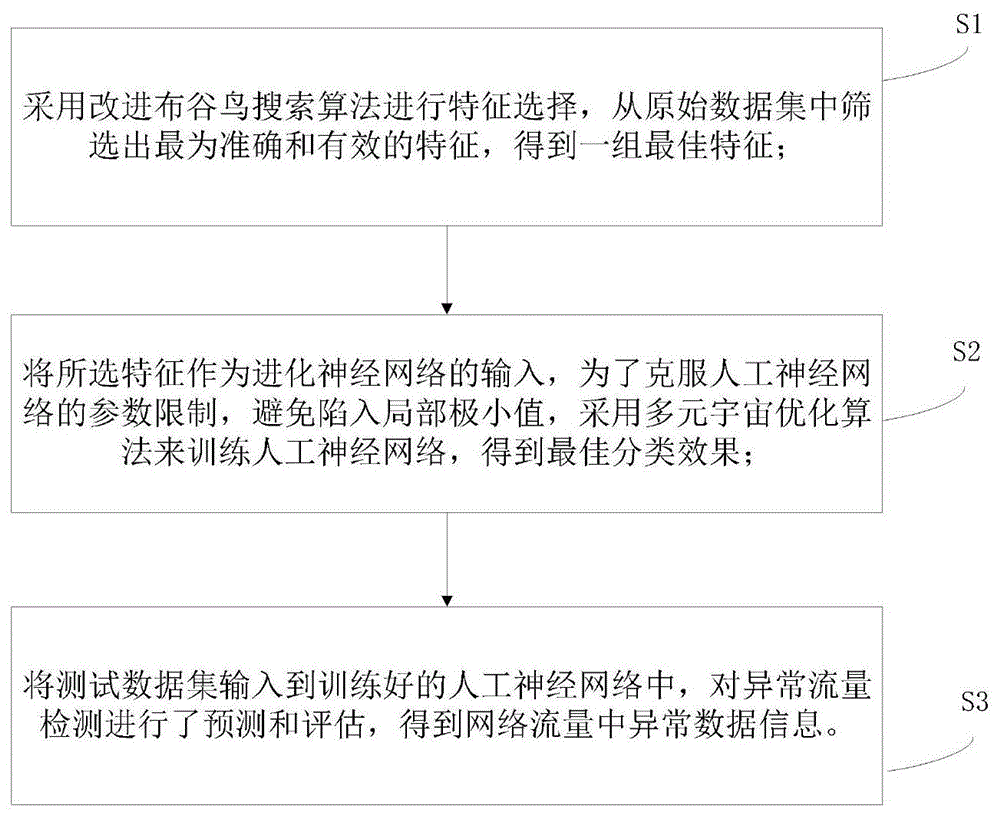
本发明针对近年来智能设备用户数量迅速增加导致网络流量大幅上升,巨大的数据对入侵检测系统的性能产生了不利影响,并且流量中的冗余和不相关信息导致入侵检测系统性能差的问题,提出一种基于网络异常流量识别的入侵检测方法。首先,采用改进布谷鸟搜索算法进行特征选择,从原始数据集中筛选出最为准确和有效的特征,作为一组最佳特征。然后,将所选特征作为进化神经网络的输入,为了克服人工神经网络的参数限制,避免陷入局部极小值,采用多元宇宙优化算法来训练人工神经网络,得到最佳分类效果。最后,将测试数据集输入到训练好的人工神经网络中,对异常流量检测进行了预测和评估,构建了基于特征选择和进化神经网络的高效异常入侵检测模型。
本发明的目的是由以下技术方案来实现的:一种基于网络异常流量识别的入侵检测方法,它包括以下步骤:
s1,采用改进布谷鸟搜索算法(csa)进行特征选择,从原始数据集中筛选出最为准确和有效的特征,得到一组最佳特征。
s2,将所选特征作为进化神经网络的输入,为了克服人工神经网络的参数限制,避免陷入局部极小值,采用多元宇宙优化算法(mvo)来训练人工神经网络(ann),得到最佳分类效果。
s3,将测试数据集输入到训练好的人工神经网络中,对异常流量检测进行了预测和评估,得到网络流量中异常数据信息。
进一步地,所述s1具体包括:
s11,利用改进布谷鸟搜索算法对解决方案进行排序,并在后期处理结果和可视化时找到当前的最佳结果。
s12,根据数据集中模糊的数据的特征将数据集x划分为c个簇后筑巢,并在它们之间选择最好的一个,把蛋放在造好的巢里。
进一步地,所述s12具体包括:
利用突变随机改变巢,保持最佳的解决方案,并根据错误值和分类的准确性显示最佳的巢。利用遗传算法变异算子来创造更多的空间和更多样化的解。为此,将突变与改进布谷鸟搜索算法相结合,考虑两个步骤:巢的随机选择、蛋的随机选择。
进一步地,所述s2具体包括:
s21,将选定的特征作为输入信息维度的训练特征发送到ann模块,该模块计划为具有单个输入层,一个隐藏层和一个输出层体系结构的多层感知器(mlp)。人工神经网络包括高度互连的并行处理组件,并将多个输入分配到一组预期的输出。ann-mlp分类是具有已知类别标签的监督学习。求和函数的结果通过传递或激活函数传递。
s22,通过将权重转移到mvo模块来执行此训练。mvo算法由三种宇宙观组成:白洞,黑洞和虫洞,它们是形成宇宙的一部分。这三个概念构成了mvo算法背后的思想,该算法通过黑洞,白洞和虫洞提供了动力学和宇宙相互作用的模拟。在优化过程中,每个宇宙值与其通货膨胀率保持一致,并通过使用轮盘赌轮作为白洞来标识选定的宇宙值。
s23,针对每个单独的表现返回最终适应度值,该最终适应度值基于训练数据集进行测量。优化过程始于因子的创建和初始化,例如总体大小以及上下限。之后,根据上下限将宇宙值随机初始化为一组。计算各个宇宙的相应适应度值,以描述最佳潜在通货膨胀率。然后,在单个迭代中,宇宙中的高膨胀率对象倾向于通过白洞或黑洞迁移到包含低膨胀率的宇宙。因此,单个宇宙中的物体会通过虫洞随机进入最佳宇宙。最终,最佳宇宙在操作完成时形成。
进一步地,建立特征选择和进化神经网络的异常入侵检测模型,所述s3具体包括:
s31,将输入从测试数据集中输入到经过训练的ann中;
s32,根据预期的输出,可以将ann测试过程视为与任何目标类最接近的匹配,以作为估计输出,识别出网络流量中异常数据信息。
进一步地,所述s31具体包括:
用训练方法优化神经网络的目标是找到神经网络突触权重并减少代表神经网络功能成本的均方误差(mse)。通过生成解决方案总体,mvo算法在假定每个宇宙都被视为随机生成的解决方案总体中的一个个体的前提下初始化优化过程。训练方法旨在找到正确的值,减少错误并获得最大的分类精度。
进一步地,所述s32具体包括:
根据预期的输出,可以将ann测试过程视为与任何目标类最接近的匹配,以作为估计输出,mvo中的所有个体都是包含ann层之间的连接权重的向量,计算每个人的对象数,在建议的mvo训练算法中,mse主要用作成本函数,根据计算结果,得到网络流量中异常数据信息。
本发明的一种基于网络异常流量识别的入侵检测方法,解决了传统入侵检测方法在面对大量流量数据出现的效率低下问题。分析了特征选择和进化神经网络方法都可以提高入侵检测系统的性能,将这两种方法结合起来,建立了一个高效的基于异常的入侵检测系统。实验结果表明,一种基于网络异常流量识别的入侵检测方法在对异常流量的检测率、误报率和执行时间方面都有较大提升,可以有效处理海量连续型流量监测数据,具有更广泛的适用性。
附图说明
图1为一种流量异常入侵检测方法流程图;
图2为改进布谷鸟搜索算法流程图;
图3为人工神经网络简单架构图;
图4为不同算法识别准确率对比图;
图5为不同算法时间效率对比图。
具体实施方式
参照图1,一种基于网络异常流量识别的入侵检测方法作详细描述,包括如下步骤:
1)从数据集中分离出最优特征。
(1.1)csa是一种改进布谷鸟搜索算法,模仿了布谷鸟的自然行为,即某些布谷鸟“专性寄生”在其他宿主鸟类的巢中产卵。研究人员使用了三条规则来定义csa,以便将其作为一种计算机算法来实现:
a)产下优质蛋的最佳巢穴,将会传给下一代;
b)已有多个预先确定的宿主巢,布谷鸟产蛋的识别概率pa∈(0,1);
c)当这种情况发生时,鸡蛋要么被移走,要么被抛弃,然后再建一个新的;
对于上述规则,csa以下方式实现:巢中的单个蛋代表候选解。因此,一只布谷鸟可以在一个巢中只产一枚蛋,而通常每个巢中可以有几个蛋的溶液。csa负责生成新颖且可能更优的解决方案,以替代当前人群中不合适的解决方案。对解决方案的质量进行评估,并根据需要最大化的问题的目标函数进行解决。最后一个估计规则pa称为“切换概率”,它决定了最坏的宿主巢何时被一个新的随机生成的巢取代。这个因素提供了csa过程两部分的平衡,即勘探和开发。因此,过度的开采会导致早期的收敛,而过多的探索会减缓收敛。在生成布谷鸟i的新解时,采用式(1)进行levy飞行。
其中:α>0表示根据问题的尺度分配步长。通常情况下,α=1可以用来表示时间。∈符号是一个入口乘法。通常,levy航班安排的是随机行走,然而,它们的随机步数是由方程(2)中提供的大步数的levy分布得到的,该分布具有无限的均值和无限的方差。
levy~u=t-λ(2)
基于上述三种规则,算法中展示了csa技术的关键步骤,即基于特征选择和进化神经网络的高效异常入侵检测方法。
(1.2)考虑到csa是用来生成新的和潜在的解的,目标函数在评估解和用其他已有解替代它们时起着重要的作用。适应度函数(评估函数)表示给定的解决方案如何更接近期望问题的最终解决方案。为此,由于模糊c均值(fcm)聚类的优点,我们将其作为本研究的目标函数。根据fcm,必须根据数据集的特征将数据集x划分为c个簇。这些数据必须转换成模糊的。成员函数定义的模糊表示μ方程:
模糊c均值聚类的一个广泛使用的目标函数是加权组内误差平方和,它用于定义受限优化问题,如式(4)所述:
地点:1≤m≤∞,m是任意的实数高于1,uij加入集群中的ξ的程度是j,xi是采用的i分量记录数据,cj集群的中心,||xi-cj||是任何规范声明任何测量数据和中心之间的相似之处。通过重复优化目标函数,通过公式(5)和(6)分别更新隶属度uij和聚类中心cj来实现模糊划分:
聚类优化的目标是在迭代过程的帮助下找到最优聚类质心。fcm作为一种有效的目标函数被应用于布谷鸟搜索适应度函数中,可以增强搜索结果中最优质心的定位,并对匹配随机数的种群中发现的巢的适应度进行评估。首先,布谷鸟算法在所有特征中选取几个特征。然后,使用fcm算法来确定各参数的可取性。fcm在布谷鸟搜索中的应用过程如图2所示。
(1.3)由于cs算法在某些情况下具有较快的收敛速度,所以它的搜索空间较小。该方法应在保证收敛性的前提下,增加搜索空间,并达到最优响应。
因此,在本发明中,利用遗传算法变异算子来创造更多的空间和更多样化的解。为此,将突变与布谷鸟搜索算法相结合,考虑两个步骤:
a)巢的随机选择。
b)蛋的随机选择。
传统的cs在巢中每次只考虑一个蛋,使用levyflight。突变被定义为“在遗传算法中改变染色体上的一个或多个基因值,使其从初始状态改变”。“这可能会给基因库增加一个全新的基因价值。突变也被定义为“基因搜索的一个重要组成部分,因为它有助于防止种群陷入任何局部最优。”如前所述,布谷鸟的蛋会模仿宿主鸟的蛋。为了解释这种行为,算法中包含了一个突变算子,以反映布谷鸟卵基因的突变行为,以提高它们的生产力。因此,使用这种策略可以保留高质量的鸡蛋,而拒绝低质量的鸡蛋。在突变过程中,当随机选择的新的布谷鸟蛋优于旧的布谷鸟蛋时,新的布谷鸟蛋就会取代旧的布谷鸟蛋。这种方法可确保在下一代中始终维护最佳候选解决方案。为了丰富种群的多样性,随机选择巢进行突变,如式(7)所示。
mi=xi+r(xbest-xworse)(7)
其中xi代表第i个巢的位置,xbest和xworse代表代群体中最好和最差的个体。同样,r在0到1的范围内生成。利用突变结合最好的和最差的个体来保证种群的多样性。如果突变个体得到提升,它将取代当前个体,从而产生新的布谷鸟种群x=(x1,…,xd)t。
对于性能评估,将测量所选属性的准确性。改进的基于突变和模糊c均值的布谷鸟搜索算法可以解决传统布谷鸟搜索在特征子集选择中对特征质量评价效果较好的缺点。特征选择的过程从生成、巢数、pα等参数的创建和初始化开始,并通过征兵飞行随机得到一只布谷鸟。然后用模糊c均值聚类计算误差函数。然后,筑巢,并在它们之间选择最好的一个。把蛋放在造好的巢里。计算pα,利用突变随机改变巢。然后,保持最佳的解决方案,并根据错误值和分类的准确性显示最佳的巢,这些选择的特征被用作使用mvo-ann执行的分类部分的输入。
2)基于mvo-ann的信息维度特征训练方法,如图3所示。
(2.1)将选定的特征作为输入信息维度的训练特征发送到ann模块。
(2.1.1)该模块计划为具有单个输入层,一个隐藏层和一个输出层体系结构的多层感知器(mlp)。根据基于异常的检测将数据分类为攻击和正常,就选择了具有二进制分类和一个隐藏层的著名算法多层感知器(mlp);
(2.1.2)人工神经网络包括高度互连的并行处理组件,并将多个输入分配到一组预期的输出。ann-mlp分类是具有已知类别标签的监督学习。mlp是一类前馈-一种人工神经网络,至少包括三层:输入,输出和隐藏层。通常,每个输入都乘以与网络匹配的权重,它们的总和就是一个加权和函数;
(2.1.3)求和函数的结果通过传递或激活函数传递。图3为人工神经网络的简单结构。如公式(8)所示,将总函数计算为乘积,初始权重和附加偏差。
反向传播(bp)是用于在监督模式下训练ann的熟悉的训练算法。在人工神经网络的结构中存在众多因素是实现该系统的主要问题。特别是,bp-ann可能会进入局部最小值,这会对正确分配ann结构的能力产生负面影响。因此,不使用反向传播算法,而是在ann中使用了多元宇宙优化器(mvo)来调整权重并最小化误差函数。
(2.2)通过将权重转移到mvo模块来执行此训练。
(2.2.1)mvo算法由三种宇宙观组成:白洞,黑洞和虫洞,它们是形成宇宙的一部分。这三个概念构成了mvo算法背后的思想,该算法通过黑洞,白洞和虫洞提供了动力学和宇宙相互作用的模拟。在mvo中,通货膨胀率与适应度相对应,而术语“时间”与迭代平行。以下规则逐项适用于任何优化过程。
①通货膨胀率越高,存在白洞的可能性越大。
②较低的通货膨胀率表示存在黑洞的可能性更大。
③最好的宇宙是物体随机穿过虫洞的结果。
(2.2.2)在宇宙之间交换对象时,拥有一个对象的宇宙将从较高的通货膨胀率发送到其他较低的通货膨胀率。此外,具有较低膨胀率的宇宙会从较好的宇宙中获得额外的对象,从而使其处于稳定状态,从而成为具有较高膨胀率的最佳宇宙。在优化过程中,每个宇宙值与其通货膨胀率保持一致,并通过使用轮盘赌轮作为白洞来标识选定的宇宙值。
行进距离率(tdr)和虫洞存在概率(wep)是两个主要系数,分别是公式(9)和(10)。
其中p表示开发因子;l是现有迭代,l表示最高迭代次数。在所有迭代中,都会提高wep和tdr,以在探索/本地搜索中围绕最佳收益的宇宙获得更高的准确性。
(2.2.3)mvo算法的一般步骤如下所示:
a)初始化mvo的参数:lb,ub。
b)根据ub和lb创建一组随机universe。
c)计算每个宇宙的相应通货膨胀率(适应度)。
d)计算wep值。
e)在universe之间交换对象。
f)每个universe中的对象都会传送到最佳universe。
g)如果不满足结束条件,请转到步骤c)。
h)返回到目前为止形成的最好的宇宙。
(2.3)针对每个单独的表现返回最终适应度值,该最终适应度值基于训练数据集进行测量。优化过程始于因子的创建和初始化,例如总体大小以及上下限。之后,根据上下限将宇宙值随机初始化为一组。计算各个宇宙的相应适应度值,以描述最佳潜在通货膨胀率。然后,在单个迭代中,宇宙中的高膨胀率对象倾向于通过白洞或黑洞迁移到包含低膨胀率的宇宙。因此,单个宇宙中的物体会通过虫洞随机进入最佳宇宙。最终,最佳宇宙在操作完成时形成。
3)建立特征选择和进化神经网络的异常入侵检测模型。
(3.1)将输入从测试数据集中输入到经过训练的ann中。
(3.1.1)用训练方法优化神经网络的目标是找到神经网络突触权重并减少代表神经网络功能成本的mse。通过生成解决方案总体,mvo算法在假定每个宇宙都被视为随机生成的解决方案总体中的一个个体的前提下初始化优化过程。
(3.1.2)问题的衡量表明解决方案的规模,mvo个人的描绘和设计是ann培训中的重要考虑因素。
(3.1.3)ann培训中的每个人都反映了ann结构的所有权重和偏见。训练方法旨在找到正确的值,减少错误并获得最大的分类精度。
(3.2)根据预期的输出,可以将ann测试过程视为与任何目标类最接近的匹配,以作为估计输出。
(3.2.1)mvo中的所有个体都是包含ann层之间的连接权重的向量。如公式(11)所示,计算每个人的对象数:
indvnbr=(n*m)+(2*m)+1(11)
(3.2.2)在建议的mvo训练算法中,mse主要用作成本函数。可以使用公式(12)计算mse:
其中,input表示输入的实际网络流量数据,而output表示输出的近似值,tn是流量数据集中采集的频率。
发明人研究分析了一种基于网络异常流量识别的入侵检测方法(csa&mvo-ann),首先,利用改进布谷鸟模糊算法(csa)来选择最佳的特征子集,然后将最佳特征子集输入到mvo-ann模型中进行训练,最后根据得到的检测模型识别异常流量信息。采用已知数据集nsl-kdd进行了验证,首先从41个特征中选出22个特征作为最优特征子集,然后将其输入到mvo-ann模型中查看异常入侵检测系统的性能。为了证明csa&mvo-ann方法的有效性,在不同比例的数据集下,通过对比随机森林(randomforest,rf)、lm-bp算法、支持向量机(svm)、鸽群优化算法(pigeoninspiredoptimization,pio)等算法对异常流量的检测,分别测量了检测的准确率和时间效率,不同算法识别准确率对比结果如图4所示,时间效率对比结果如图5所示。结果表明,该方法的性能优于以上几种算法,它在检测准确率和执行时间方面显示了更好和更稳健的结果。
- 还没有人留言评论。精彩留言会获得点赞!