一种基于KNN的网络攻击检测属性权重分析方法
本发明属于网络攻击检测技术领域,涉及一种基于knn的网络攻击检测属性权重分析方法。
背景技术:
随着互联网的快速发展和广泛普及,网络入侵的种类与数量越来越多,网络入侵事件出现得更加频繁。在互联网信息时代中,计算机处理信息的能力加快,同时越来越多的网络攻击针对公众的个人信息情况,这种网络攻击造成了社会经济损失和个人心理恐慌,个人和企业以及政府越来越重视网络安全。而网络攻击中常见的攻击方式是分布式拒绝服务攻击,即ddos攻击。
ddos是当今互联网最重要的威胁之一。ddos攻击是指攻击者通过控制多台计算机,向攻击目标发送大量持续地请求,使攻击目标无法回应合法用户正常访问资源的请求,给攻击目标带来巨大的损失。ddos攻击的对象主要是网站和服务器,通过消耗服务器的资源,其中包括cpu、内存和网络带宽等。此外,ddos也可以对网络基础设施进行攻击,通过巨大的攻击流量,其中包括路由器、交换机等,可以导致攻击目标所在的网络性能大幅下降甚至瘫痪。
ddos攻击的原理可以理解为,攻击者通过黑客手段将网络上的大量计算机劫持并控制,对目标发起攻击。因而,这种攻击也被称作分布式攻击。常见的攻击方式有三种:第一种是synflood攻击,利用tcp协议的三次握手,由于请求ip地址是假冒的,第三次握手包一直得不到确认,服务器一直处于半连接的状态,直到将等待队列塞满,服务器无法提供正常服务;第二种是udpflood攻击,利用udp的无连接性,通过发送大量udp小包使攻击目标无法提供正常服务;第三种是cc攻击,一般用于网站攻击,通过发送数据包使网站无法正常访问。
想要更好的规范网络安全,需要对ddos数据集进行分析。分析数据集中的属性对网络安全的作用,可以获得目标网络中是否发生的ddos攻击。常见的ddos数据集有caidaddosattack2007,cic-ids2018,kdd等等。以kddcup99为例,是一个用来从正常连接中监测非正常连接的数据集。数据集中有41个属性和一个标签列。41个属性可分为tcp连接的基本特征;tcp连接的内容特征;基于时间的网络流量统计特征,使用2秒的时间窗;基于主机的网络流量统计特征,主机特征,用来评估持续时间在两秒钟以上的攻击。由于kddcup99存在类别不均衡的问题,nsl-kdd是kddcup99数据集的重采样版本。研究者需要根据自己的实际需要和目的选择合适的属性进行预处理,再选择合适的算法进行分析。大多数研究者采用的数据集具有数据量小,属性少等特点,选择部分属性结合传统的方法就可以满足要求。但是随着科技的进步,5g技术的出现以及物联网和人工智能等技术的逐渐发展,数据集规模越来越大,属性越来越多,再使用传统的数据处理方法就会出现一系列的问题包括处理速度慢、效率低、得到的信息量少。
技术实现要素:
本发明的目的是提供一种基于knn的网络攻击检测属性权重分析方法,解决了现有方法数据处理速度慢、得到的信息量少的问题。
本发明所采用的技术方案是,一种基于knn的网络攻击检测属性权重分析方法,具体按照以下步骤实施:
步骤1,下载ddos数据集,记为样本a;
步骤2,对步骤1得到的样本a进行处理,转化为后缀名为.csv格式文件,命名为样本一;
步骤3,将步骤2得到的样本一中的标签列进行0,1分类;
步骤4,将经步骤3得到的样本二进行预处理,得到样本五;
步骤5,将步骤4得到的样本五划分为训练集和测试集,将训练集输入knn模型进行训练,并调整可调参数,得到训练好的knn模型,将测试集输入训练好的knn模型进行测试,查看准确率。
本发明的特征还在于,
步骤2的具体过程为:对步骤1得到的样本a通过只读的形式打开文件,去掉样本a中每一行的空格,再利用分隔符对字符串进行切片,转化为后缀名为.csv格式文件,命名为样本一。
步骤3的具体过程为:
步骤3.1,从步骤2得到的样本一中挑选出protocal是tcp,攻击类型是dos和正常的数据,并将正常数据的标签列设置为1,dos攻击的标签列设置为0,命名为样本二;
步骤3.2,统计步骤3.1得到的样本二中正常流量和异常流量的数目,并借助matplotlib.pyplot可视化显示柱状图。
步骤4的具体过程为:
步骤4.1,将步骤3得到的样本二,通过pandas函数读入,并去掉步骤2中的分隔符,得到样本三;
步骤4.2,将步骤4.1得到的样本三,通过shape查看行数,取前60%行作为样本四;
步骤4.3,对步骤4.2得到的样本四每一属性命名,并按列进行归一化处理;
步骤4.4,对步骤4.3处理后的样本四依次选择每一个属性和标签列分别记为x和y,对x转化为二维数组并命名为x,y转化为一维数组并命名为y,x和y拼接成样本五。
步骤5的具体过程为:
步骤5.1,明确knn模型中weights和leaf_size参数的数值;
步骤5.2,将步骤4得到的样本五划分为训练集和测试集,将训练集输入knn模型进行训练,并将n_neighbors按照整数自定义范围依次取值,在自定义范围中准确率最高的,即为最优knn模型;
步骤5.3,将步骤5.2中的测试集输入最优knn模型中进行测试,查看准确率。
步骤5.2中,训练集和测试集的样本量比为7:3。
本发明的有益效果是,本发明一种基于knn的网络攻击检测属性权重分析方法,针对ddos数据集进行攻击检测,选择部分属性进行分析,借助机器学习knn模型进行每个属性准确率分析,快速选择准确率最高的部分属性,能够及时检测是否发生ddos攻击,具有很强的参考性,并且数据处理速度快、得到的信息量全面。
附图说明
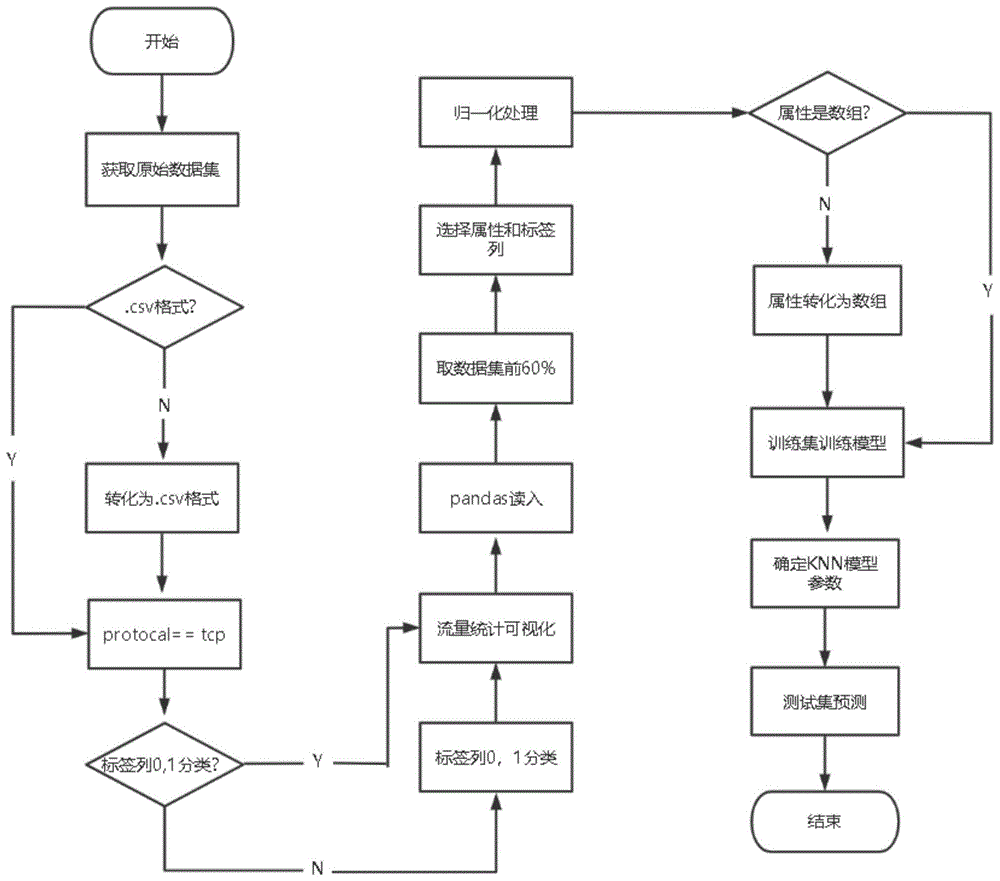
图1是本发明一种基于knn的网络攻击检测属性权重分析方法中的算法流程图;
图2是本发明一种基于knn的网络攻击检测属性权重分析方法中统计样本二中正常流量和异常流量柱状图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明提供一种基于knn的网络攻击检测属性权重分析方法,如图1所示,具体按照以下步骤实施:
步骤1,下载ddos数据集,记为样本a;
步骤2,对步骤1得到的样本a通过只读的形式打开文件,去掉样本a中每一行的空格,再利用分隔符对字符串进行切片,转化为后缀名为.csv格式文件,命名为样本一;
步骤3,将步骤2得到的样本一中的标签列进行0,1分类;
步骤3.1,从步骤2得到的样本一中挑选出protocal是tcp,攻击类型是dos和正常的数据,并将正常数据的标签列设置为1,dos攻击的标签列设置为0,命名为样本二;
步骤3.2,统计步骤3.1得到的样本二中正常流量和异常流量的数目,并借助matplotlib.pyplot可视化显示柱状图;
步骤4,将经步骤3得到的样本二进行预处理,得到样本五;
步骤4.1,将步骤3得到的样本二,通过pandas函数读入,并去掉步骤2中的分隔符,得到样本三;
步骤4.2,将步骤4.1得到的样本三,通过shape查看行数,取前60%行作为样本四;
步骤4.3,对步骤4.2得到的样本四根据ddos数据集官方介绍进行每一属性命名,并按列进行归一化处理;
步骤4.4,对步骤4.3处理后的样本四依次选择每一个属性和标签列分别记为x和y,对x转化为二维数组并命名为x,y转化为一维数组并命名为y,x和y拼接成样本五;
步骤5,将步骤4得到的样本五划分为训练集和测试集,训练集和测试集的样本量比为7:3,将训练集输入knn模型进行训练,并调整可调参数,得到训练好的knn模型,将测试集输入训练好的knn模型进行测试,查看准确率;
步骤5.1,明确knn模型中weights和leaf_size参数的数值;
步骤5.2,将步骤4得到的样本五划分为训练集和测试集,将训练集输入knn模型进行训练,并将n_neighbors按照整数自定义范围依次取值,在自定义范围中准确率最高的,即为最优knn模型;
步骤5.3,将步骤5.2中的测试集输入最优knn模型中进行测试,查看准确率,通过准确率了解knn模型预测效果,以及时检测到是否发生ddos攻击。
实施例
步骤1,下载ddos数据集kdd99(dataminingandknowledgediscoverycup1999dataset),记为样本a;
步骤2,对步骤1得到的样本a通过只读的形式打开文件,去掉样本a中每一行的空格,再利用分隔符对字符串进行切片,转化为后缀名为.csv格式文件,命名为样本一;
步骤3.1,从步骤2得到的样本一中挑选出protocal是tcp的数据,攻击类型是dos和正常的数据,并将正常数据的标签列设置为1,dos攻击的标签列设置为0,命名为样本二;
步骤3.2,统计步骤3.1得到的样本二中正常流量和异常流量的数目,并借助matplotlib.pyplot可视化显示柱状图,如图2所示,从图2中可以看出,横坐标显示包括正常流量、异常流量以及总流量,纵坐标是各流量具体的数目,则正常流量的数目为768670,异常流量的数目为1074241,总流量的数目为1842911;
步骤4.1,将步骤3得到的样本二,通过pandas函数读入,并去掉步骤2中的分隔符,得到样本三;
步骤4.2,将步骤4.1得到的样本三,通过shape查看行数,取前60%行作为样本四;
步骤4.3,对步骤4.2得到的样本四41个根据数据集官方介绍进行属性命名,并按列进行归一化处理,第42列命名为attack_type;
步骤4.4,对步骤4.3处理后的样本四并依次选择count,same_srv_rate,dst_host_serror_rate,dst_host_srv_serror_rate四个属性和attack_type列分别记为x和y,对x转化为二维数组并命名为x,y转化为一维数组并命名为y,x和y拼接成样本五;
步骤5.1,明确knn模型中weights和leaf_size参数的数值,weights取值有uniform和distance,两种取值预测准确率结果非常接近影响,leaf_size在29和30以后预测准确率趋势趋于平缓,本实施例去weights='uniform',leaf_size=30;
步骤5.2,将步骤4得到的样本五划分为训练集和测试集,训练集和测试集的样本量比为7:3,将训练集输入knn模型进行训练,n_neighbors=5,得到训练好的knn模型,查看准确率,准确率为0.9981128890282283,运行时间为1340.890951秒;
步骤5.3,将步骤5.2中的测试集输入训练好的knn模型中进行测试,查看准确率。
运行时间的表达为:假如经步骤3得到的样本二有n个样本,而且每个样本的特征为d维的向量,为了做预测需要循环所有的训练样本,时间复杂度为o(n)。另外,当我们计算两个样本之间距离的时候,这个复杂度就依赖于样本的特征维度,则时间复杂度为o(d);属性每次只选择一个,时间复杂度为o(1),把循环样本的过程看做是外层循环,计算样本之间距离看作是内层循环,所以时间复杂度为o(n*1),预测d个属性,所以总的时间复杂度为o(n*d)。
对照例
步骤4.4,对步骤4.3处理后的样本四并随机选择num_shells,num_root,dst_host_srv_diff_host_rate,srv_diff_host_rate四个属性和attack_type列分别记为x和y,对x转化为二维数组并命名为x,y转化为一维数组并命名为y,x和y拼接成样本六;
步骤5.2,将步骤4得到的样本六划分为训练集和测试集,训练集和测试集的样本量比为7:3,将训练集输入knn模型进行训练,n_neighbors=5,得到训练好的knn模型,查看准确率,准确率为0.8638808165824601,运行时间为3248.227169秒;
其余步骤和实施例相同。
由此可以看出,本发明实施例准确率相比对照例随机选取四个属性提高15.528%,运行时间比提高58.719%。借助机器学习knn模型分别预测ddos攻击属性准确率,对于研究者来说可以快速选择准确率最高的部分属性,及时检测到是否发生ddos攻击,具有很强的参考性。
- 还没有人留言评论。精彩留言会获得点赞!