一种基于混合波束成形的毫米波移动边缘计算系统中计算效率优化方法
技术领域:
本发明属于移动通信领域,涉及移动通信系统的资源分配方法,尤其是涉及一种基于混合波束成形的毫米波移动边缘计算系统中计算效率优化方法。
背景技术:
:
在即将到来的第五代移动通信(5g)中,网络平均吞吐速率、传输时延、系统安全将会得到显著的提高,同时将更加注重用户体验,比如对虚拟现实、3d、交互式游戏等新兴移动业务的支撑能力。在这一背景下,移动边缘计算(mec,mobileedgecomputing)有望成为5g及未来通信中的一项关键技术,这是因为mec技术能实现更低的延迟,为移动设备节省能源,支持内容感知计算,增强移动应用程序的隐私和安全性等。mec的基本概念首先被欧洲电信标准化协会于2014年提出,它被定义为“在靠近移动用户的无线接入网络内提供信息技术和云计算能力”的新平台,用户通过将计算任务卸载到附近的mec服务器上进行计算,可以显著降低网络开销和执行延迟。随着mec技术的相关理论和实践的不断成熟,融合mec技术与其他通信领域的新型技术成为了近些年来学术界的研究趋势之一。
一方面,不同于传统的正交多址接入(oma,orthogonalmultipleaccess)技术,如时分多址和频分多址技术,功率域非正交多址(noma,non-orthogonalmultipleaccess)技术(以下简称noma)通过复用功率域来实现对同一正交资源块的高效利用,可以进一步提高系统通信容量、用户接入数量、频谱效率等。另一方面,毫米波(mmwave,millimeter-wave)通信由于毫米波频段内丰富的频谱资源而成为一种备受期待的频谱开发方案。mmwave通信相比传统移动通信具有以下几个优点:1)超高带宽:mmwave通信的频段范围为30-300ghz,其中可用频谱资源丰富;2)元件尺寸小:mmwave的波长较短,为毫米级别,适合部署大型天线阵列;3)窄波束:相同的天线尺寸下相比微波频段可以封装更多的天线元件,使得形成的波束可以更窄,有利于探测雷达等应用的发展。
基于以上讨论,本发明研究了一个基于混合波束成形的毫米波移动边缘计算系统中计算效率优化方法,将毫米波通信中的混合波束成形技术和noma应用于mec系统中,建立该系统的计算效率优化问题,以提高上述系统的计算效率和保证用户公平性。
技术实现要素:
:
针对基于混合波束成形的移动边缘计算系统,本发明旨在提高该系统的计算效率以及保证用户的公平性,通过联合优化基站的混合波束成形和每个用户的本地资源分配来最大化所有用户的计算效率的最小值,提出了一种基于惩罚非精确块坐标下降的计算效率优化算法来获得计算有效的资源分配方案。
本发明所采用的技术方案有:一种基于混合波束成形的毫米波移动边缘计算系统中计算效率优化方法,其特征在于:步骤如下:
步骤s1:建立基于混合波束成形(hbf)的毫米波移动边缘计算(mec)系统,该系统由u个单天线用户和一个与高性能mec服务器相连的基站组成,用户和基站之间的信道建模为窄带块衰落毫米波信道,基站采用hbf构架,配有n根天线、nrf条射频链路、n个功率放大器、nnrf个移相器和ns条数据流,且每根天线通过一个功率放大器和nrf个移相器连接到所有射频链路上。基站的hbf由模拟波束成形(abf)矩阵和数字波束成形(dbf)矩阵组成,其中的abf矩阵需要满足恒模约束。为了获得更高的多路复用增益,假设ns=nrf,且所有用户分成g组,每组对应一条独立的数据流,即g=ns。采用部分卸载模式,用户使用非正交多址接入(noma)协议上传其计算任务到基站的mec服务器上;
步骤s2:为了提高计算效率以及保证用户公平性,建立基于最大-最小公平性准则的计算效率优化问题,其优化目标为最大化所有用户的计算效率中的最小值,优化变量为基站的abf矩阵和dbf矩阵以及每个用户的发射功率和本地中央处理器(cpu)频率,其中计算效率被定义为用户的计算比特数与能耗的比值,其中用户的计算比特数包括用户的本地计算比特数以及卸载计算比特数;
步骤s3:引入辅助变量和等式约束给出步骤s2中计算效率优化问题的等价问题,并且采用罚函数法进一步得到对应的惩罚问题;
步骤s4:针对步骤s3中的惩罚问题,利用非精确块坐标下降(ibcd)法将该惩罚问题分解成多个子问题并使用majorization-minimization算法和连续凸逼近(sca)算法求解对应的子问题,最后提出了一种可行的计算效率优化算法来获得相应的计算有效的资源分配方案,并给出该算法的收敛性和计算复杂度分析。
本发明具有如下有益效果:本发明基于混合波束成形的毫米波移动边缘计算系统中计算效率优化方法,所提算法具有多项式时间复杂度,能有效提高系统的计算效率以及保证用户之间的公平性。该方法根据优化问题的内在结构,引入辅助变量和等式约束获得上述优化问题的等价惩罚形式,提出了一种基于惩罚非精确块坐标下降的计算效率优化算法,最终获得计算有效的资源分配方案。
附图说明:
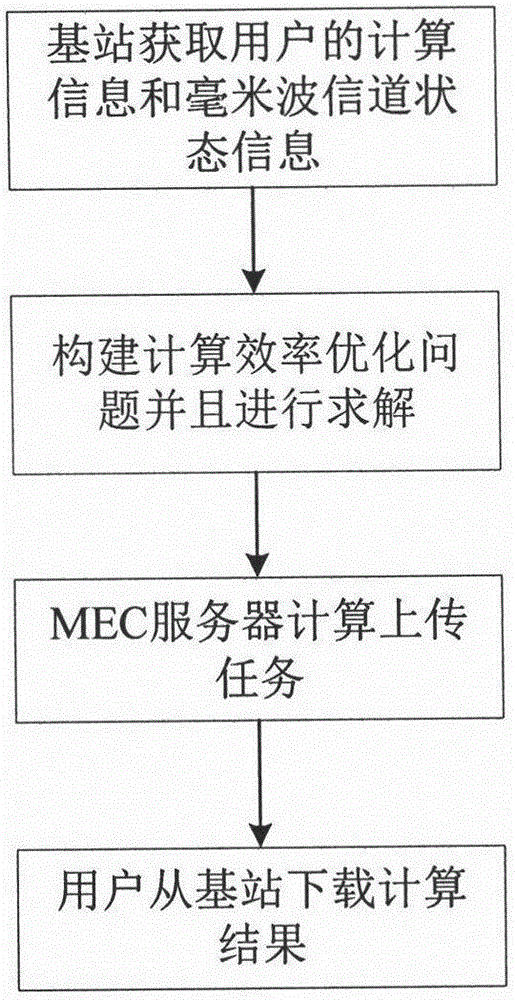
图1为本发明实施例中系统的流程图;
图2为本发明实施例中系统的模型图;
图3为本发明实施例中所提出的非正交多址接入(noma)方案与频分多址接入(fdma)方案的仿真曲线图。
图4为本发明实施例中所提出的部分卸载方案与其他两种对比方案的仿真曲线图;
具体实施方式:
下面结合附图对本发明作进一步的说明。
一、系统模型
本发明基于混合波束成形(hbf)的毫米波移动边缘计算(mmwave-mec)系统中计算效率优化方法中涉及的系统模型如图2所示,该系统由u个单天线用户和一个与高性能移动边缘计算(mec)服务器相连的毫米波基站组成,其中基站采用全连接式hbf构架,配有n根天线、nrf条射频链路、n个功率放大器和nnrf个移相器,且每根天线通过一个功率放大器和nrf个移相器连接到所有射频链路上。基站的hbf由模拟波束成形(abf)矩阵
其中n为基站的接收天线数,lg,k为非视距(nlos)路径数,
其中
考虑多用户卸载计算阶段中所有用户采用非正交多址接入(noma)协议向基站发送各自计算任务的数据信号,则基站经过hbf处理且执行用户分组后第g组
其中
其中
上述系统中
二、基于最大-最小公平性原则的计算效率优化问题建模及求解过程
为了提高上述mmwave-mec系统的计算效率以及保证用户公平性,根据最大-最小公平性准则,针对基站的dbf矩阵d和abf矩阵a以及每个用户的发射功率pg,k和本地cpu频率fg,k进行联合优化,建立计算效率优化问题如下:
其中,约束c1表示基站的abf矩阵a的恒模约束,约束c2表示基站的sic的解码约束,约束c3表示每个用户的计算比特速率约束,
其中定义集合
接下来通过求解问题(7)来等价地求解问题(6),为了处理等式约束c8,采用罚函数法在(7)目标函数中添加一个二次惩罚项来惩罚违反c8的不可行点,得到问题(7)的惩罚形式如下。
其中,
1)固定
2)固定
问题(9)可利用mm(majorization-minimization)算法进行求解。首先令a=[a1,...,an]h,其中
其中
其中
其中
3)固定{d,a}求解
问题(13)可通过连续凸逼近(sca)来近似求解。进一步地,非凸约束
因此问题(13)可近似为如下凸优化问题:
令
基于上述分析,本发明提出了一种基于惩罚ibcd的计算效率优化方法。
现考虑毫米波noma移动边缘计算系统,所有用户均匀分布在距基站10m至30m范围内,每个用户的毫米波信道的参数设置为:毫米波载波频率fc=28ghz,los路径估计精度ρlos=1,los路径数量为1,los的路径损耗指数αlos=2,nlos路径数量为3,nlos的路径损耗指数αnlos=2.92,nlos路径估计精度ρnlos=1。此外,噪声功率谱密度n0=-174dbm,系统带宽2mhz;最小计算比特速率
图3比较了部分卸载模式的maxmince/maxmincb方案下noma和fdma的计算效率,其中maxmince和maxmincb分别指最大化所有用户的最小计算效率和最大化所有用户的最小计算比特数。对于fdma,所有用户被分成g组,其用户分组策略与noma的相同,同一组中的用户执行频分多址接入且分配的带宽相同。从图3可以看出,第一,因为noma中的用户占用的是相同的频域资源,相应的频谱效率高于fdma,即noma的卸载计算效率高于fdma,所以maxmince和maxmincb方案下noma的计算效率都显著优于fdma,印证了noma在上述mmwave-mec系统中的有效性;第二,当pmax较小时,maxmince和maxmincb方案的计算效率十分相近,即两者具有类似相应的资源分配策略,但随着pmax的增加,maxmince方案的计算效率趋于平稳,而maxmincb方案的计算效率呈现下降趋势,因为maxmincb方案旨在最大化所有用户的最小计算比特数,其计算比特数虽在提升但却消耗了更多的功耗,导致了其计算效率的下降。
图4比较了三种不同计算模式(即本地计算模式、部分卸载模式和全部卸载模式)的计算效率性能。从图4中可以看到部分卸载模式和全部卸载模式的计算效率远高于本地计算模式,表明毫米波和noma的应用使得用户的卸载计算效率得到了很大提升,所以将基于noma的mmwave通信技术应用于mec系统是有益的。而且相比全部卸载模式,部分卸载模式具有更高的计算效率,这是因为部分卸载模式可以对系统的本地计算和卸载计算的资源分配比例进行动态调整以适应信道状态。此外,部分卸载模式与全部卸载模式的计算效率较为接近,说明了部分卸载模式的卸载方案偏向于将计算任务全部上传到mec服务器上。
综上所述,本发明提出的计算效率优化方法能够获得有效提高基于混合波束成形的毫米波移动边缘计算系统的计算效率以及保证用户的公平性,同时方法实现的步骤较为简单,具有多项式时间复杂度较低,效果显著。这充分说明了本发明提出的基于混合波束成形的毫米波移动边缘计算中计算效率优化方法的有效性
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下还可以做出若干改进,这些改进也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!