一种基于5G的LDPC译码延时优化方法与流程
一种基于5g的ldpc译码延时优化方法
技术领域
1.本发明涉及无线通信技术领域,具体而言,涉及一种基于5g的ldpc译码延时优化方法。
背景技术:
2.随着移动通信技术的快速发展,爆炸性的移动数据流量增长、海量的设备链接以及不断涌现的新业务需求和应用场景,5g系统正迎来蓬勃发展时期。
3.5g nr物理层的设计是整个5g系统设计中最核心的部分,相对于lte,itu和3gpp对5g提出了更高更全面的关键性能指标要求。其中最具挑战的峰值速率、用户体验速率、时延等关键技术指标,需要通过物理层的设计来达成。
4.ofdm+mimo技术作为物理层设计的基础,采用灵活的帧结构和双工机制,同时相对于lte,在信道编码编码领域,5g nr采用了数据信道ldpc编码、控制信道polar编码的组合新技术。ldpc码相对于turbo码具有更低的编码复杂度和更低的译码时延,从而可以更好地支持大数据量的信号传输。
5.为了支持embb等应用场景,5g nr物理层关键技术中除了采用新型的信道编码技术外,更大的载波带宽以及更丰富的调制方式,将为实现5g系统的关键技术指标提供有力支撑。
6.在5g nr系统中,数据信道采用准循环ldpc(quasi-cyclic ldpc,qc-ldpc)码进行信道编解码。对于基站而言,上行pusch链路的ldpc译码性能直接决定了系统的吞吐率和误码率。
7.在5g nr中,ldpc编解码器需要支持灵活的码率和灵活的码长,通过基础矩阵和移位因子,从而支持信息块大小的灵活变化。由于5g nr需要支持多种码率,并对码长的灵活性有较高要求,ldpc码在实现复杂度上会优于其他的编码方案。
8.虽然ldpc码相对于turbo码具有可高度并行化译码的优势,但同时也会遇到硬件资源开销和低时延处理问题。同时,随着nr支持不同的应用场景,其灵活性使得ldpc码的实现复杂度也随之增加。
9.5g物理层基带处理单元作为核心部件,其性能直接关系到整个5g系统的性能。以x86、arm、fpga和asic为主要实现架构的基站设计方案,在研发成本、产业生态和性能上,各有优劣。以cpu或arm为主的多核堆叠技术架构的基站产品,可快速打入市场,研发成本较低。以fpga/asic芯片技术架构的基站产品,研发周期长,成本较高,但性能好,生命周期长。
10.为适应新型的ldpc信道编解码技术,支持基站灵活的上下行时隙配比,需进一步优化ldpc译码处理,提高ldpc译码性能,降低物理层处理时延,提高系统峰值数据速率。
11.在基于ofdm技术的5g基站物理层接收机实现时,多天线mimo和多用户接入,将导致接收机的设计实现复杂度急剧上升。同时为支持灵活的上下行时隙配比,在上行业务量峰值速率要求较高的场合,信道编解码是基带的核心部件,将消耗大量硬件资源,对于可编程逻辑电路实现带来挑战。以fpga/asic为代表的硬件实现方案,是业界设计5g基站的必要
选择。为了支持多用户多小区业务场景,pusch链路ldpc译码的高吞吐率低延时成为技术方案瓶颈。
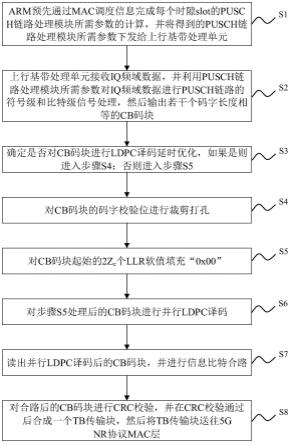
12.特别针对基带接收机信道ldpc译码处理,其性能和时延决定了整个基带单元性能。降低ldpc译码时延,提升系统上行数据速率至几个gbit/s,同时拥有低误码率ber,对ldpc译码器和整个接收机链路的设计实现带来巨大挑战。
13.因此,在满足5g系统性能指标的同时,尽可能以较低的设计复杂度满足应用需求,需从基带处理架构和信号处理算法进行布局和优化。
技术实现要素:
14.本发明旨在提供一种基于5g的ldpc译码延时优化方法,以提高ldpc译码性能、降低ldpc译码时延、提高系统峰值数据速率。
15.本发明提供的一种基于5g的ldpc译码延时优化方法,包括如下步骤:
16.s1,arm预先通过mac调度信息完成每个时隙slot的pusch链路处理模块所需参数的计算,并将得到的pusch链路处理模块所需参数下发给上行基带处理单元;
17.s2,上行基带处理单元接收iq频域数据,并利用pusch链路处理模块所需参数对iq频域数据进行pusch链路的符号级和比特级信号处理,然后输出若干个码字长度相等的cb码块;
18.s3,确定是否对cb码块进行ldpc译码延时优化,如果是则进入步骤s4;否则进入步骤s5;
19.s4,对cb码块的码字校验位进行裁剪打孔;
20.s5,对cb码块起始的2zc个llr软值填充“0x00”;
21.s6,对步骤s5处理后的cb码块进行并行ldpc译码;
22.s7,读出并行ldpc译码后的cb码块,并进行信息比特合路;
23.s8,对合路后的cb码块进行crc校验,并在crc校验通过后合成一个tb传输块,然后将tb传输块送往5g nr协议mac层。
24.进一步的,步骤s2中,所述pusch链路的符号级和比特级信号处理,包括依次完成符号级的ofdm解调、信道估计、mimo均衡、解映射和软解调,以及比特级的解扰和解速率匹配。
25.进一步的,在进行比特级的解速率匹配时,根据pusch链路处理模块所需参数,将解扰后得到的tb传输块按照解速率匹配的处理方式,分成码字长度相等的若干个码字长度相等的cb码块,每个cb码块的码字长度为n;并且在进行比特级的解速率匹配时,mac层调度根据误块率(block error rate)等指标,确认是否进行harq重传:
26.当mac层调度不开启harq重传时,物理层基带的解速率匹配模块将按照冗余版本rv=0进行处理,不会因为译码错误而重新处理某一个cb码块;
27.当mac层开启harq重传时,解速率匹配模块将根据冗余版本rv的具体值,通过重新传输某一个cb码块或通过增加校验比特的方式进行数据合并,以此提高信噪比增益,进而有利于提高ldpc译码成功率。
28.进一步的,步骤s3中,根据调制编码调度mcs、码率r、冗余版本rv、信噪比snr以及数据流量需求,来确定是否对cb码块进行ldpc译码延时优化。
29.进一步的,步骤s4包括如下子步骤:
30.s41,计算每个cb码块在进行ldpc译码前的码字总长度n
cb
:
31.n
cb
=n+2zcꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
32.其中,n为cb码块移相前的码字长度;
33.s42,计算cb码块的码字校验位长度length
paritybits
:
34.length
paritybits
=n+2z
c-k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
35.其中,zc为移位因子,k为cb码块的码字信息位长度;
36.s43,计算奇偶校验矩阵校验位的列数mb:
[0037][0038]
s44,由公式(1)~(3),得到mb与n的关系式:
[0039]
n=k+zc(mb-2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0040]
s45,计算实际的编码码率r:
[0041][0042]
s46,由公式(3)和(5)得到mb与r、k和zc的关系:
[0043][0044]
其中,计算mb时需要取整,并保证不小于4;
[0045]
s47,在调制编码方案mcs下,针对冗余版本rv=0,对解速率匹配处理输出的cb码块的校验位进行裁剪打孔,去掉尾部用“0x00”填充的llr软值后,由公式(6)计算出mb,再将计算出的mb代入公式(4),此时得到的码字长度n则为cb码块移相前并完成裁剪打孔后的码字长度n
′
。
[0046]
进一步的,步骤s5中,在对cb码块起始的2zc个llr软值填充“0x00”后,紧接着是信息为和校验位;因此送入ldpc译码的码字总长度为:
[0047]
(1)若不经过步骤s4对cb码块的码字校验位进行裁剪打孔,则送入ldpc译码的码字总长度为n
cb
=n+2zc;
[0048]
(2)若不经过步骤s4对cb码块的码字校验位进行裁剪打孔,则送入ldpc译码的码字总长度为n
cb
=n
′
+2zc。
[0049]
进一步的,步骤s5中通过设计一个状态机fsm实现对cb码块起始的2zc个llr软值填充“0x00”的操作。
[0050]
进一步的,所述状态机fsm包括四个状态:
[0051]
ilde状态:等待前级模块输入一个cb码块,并且在后级模块可接收数据时,状态进行跳转;
[0052]
read状态:读取码字长度为n或n
′
的cb码块,并对cb码块起始的2zc个llr软值填充“0x00”;
[0053]
wait状态:等待一个cb码块完成填充操作,随后进入gap状态;
[0054]
gap状态:在相邻两个cb码块的填充操作之间,通过一个延时处理时限隔离保护。
[0055]
进一步的,对cb码块起始的2zc个llr软值填充“0x00”后需要进行数据拼接:
[0056]
首先,根据cb码块的码字长度为n或n
′
以及移位因子zc计算数据拼接的相对位置:对于浮点数的llr软值,硬件处理时需要进行定点化处理;需要计算2zc/32的整数和余数,以及(n
cb-2zc)/32的余数;然后根据(n
cb-2zc)/32的余数,确定每个cb码块的数据流在传输过程中,最后一拍有效数据在32字节中的结束位置;然后根据(n
cb-2zc)/32的余数,确定数据拼接的前后2个有效时钟周期的具体位置;
[0057]
然后,根据数据拼接的相对位置进行数据拼接:当2zc/32不能整除时,将其余数数目的“0”llr值放于256bit的低位,当前时钟的cb码块的数据放于256bit的高位;后续的数据拼接,按照当前时钟的cb码块的数据放于256bit的高位,上一时钟的cb码块的数据放于256bit的低位。
[0058]
进一步的,步骤s6包括如下子步骤:
[0059]
s61,初始化:根据选择的信道模型,求解信道均衡后符号软解调后的llr软值,对所有的变量节点i,初始化软解调后的llr软值li;然后,对所有满足奇偶校验方程h
i,j
=1的i,j,设置m
j,i
=li,迭代次数iter
num
=0;定义bj表示奇偶校验矩阵h的第j个奇偶校验方程中的bit集合,ai表示第i个llr值的奇偶校验方程;
[0060]
s62,校验节点cn更新:应用下式对每个校验节点cn,计算消息e
j,i
的cn输出:
[0061]mj,i
=α
j,i
β
j,i
[0062]
α
j,i
=sign(m
j,i
)
[0063]
β
j,i
=|m
j,i
|
[0064][0065]
s63,对于i=0,1,
…
,n-1,应用下面的等式计算llr的和
[0066][0067]
s64,判断结束准则:对于i=0,1,
…
,n-1,令:
[0068][0069]
根据上式,获得判决的如果或者译码迭代次数达到设定的最大迭代次数iter
max
,则停止译码计算;否则进入s65;
[0070]
s65,变量节点vn更新:应用下式对每个变量节点vn,计算消息m
j,i
的vn输出:
[0071][0072]
iter
num
=iter
num
+1
[0073]
返回s62,继续迭代译码计算。
[0074]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0075]
1、本发明采用arm+fpga的实现架构,充分利用arm软解设计的灵活性,实现命令控制和参数计算等功能;利用fpga并行+流水处理的架构优势,实现流式数据信号的实时处
理。相比于x86和arm的bbu架构,在处理时延、峰值速率、能耗等发明,具有巨大的优势。
[0076]
2、采用便于硬件实现的5g nr接收机多路并行ldpc译码加速实现方法,一方面满足ldpc译码的低误码率性能要求,另一方面满足上行两流或四流多小区多用户应用场景对数据速率达到上1g bit/s的需求。在高阶调制和高信噪比条件下,可以较少的迭代次数实现ldpc解码。多个ldpc译码器并行处理,可将译码数据吞吐率提升数倍。
[0077]
3、本发明基于采用分层式调度的归一化最小和ldpc译码算法,在高码率、rv=0情况下,采用本权利所述的cb码块的码字校验位裁剪打孔方法,相对于直接对原码字长度译码,单个ldpc译码器针对cb码块的译码时间大大缩短,数据速率可提升3~4倍。选取合适归一化因子和ldpc译码迭代次数,可在时隙(slot)调度周期内完成ldpc译码处理,满足5g nr的小于1ms时延要求。
附图说明
[0078]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
[0079]
图1为本发明实施例中基于5g的ldpc译码延时优化方法的流程图。
[0080]
图2为本发明实施例中nr基站上行pusch处理的流程图。
[0081]
图3为本发明实施例中基图bg1的结构图。
[0082]
图4为本发明实施例中基图bg2的结构图。
[0083]
图5为本发明实施例中状态机fsm的状态转换示意图。
[0084]
图6为本发明实施例中填充操作和数据拼接的示意图。
[0085]
图7为本发明实施例中多路并行ldpc译码器的结构图。
[0086]
图8为本发明实施例中参数管理器的结构图。
[0087]
图9为本发明实施例中采用分层式调度的归一化最小和ldpc译码算法进行迭代译码的原理图(第一层计算)
[0088]
图10为本发明实施例中采用分层式调度的归一化最小和ldpc译码算法进行迭代译码的原理图(第二层计算)。
[0089]
图11为本发明实施例中奇偶校验矩阵h的结构图。
[0090]
图12为本发明实施例中ldpc译码的结构图
[0091]
图13为本发明实施例中ldpc译码的输出控制单元的结构图。
具体实施方式
[0092]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
[0093]
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通
技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0094]
实施例
[0095]
如图1所示,本实施例提出一种基于5g的ldpc译码延时优化方法,包括如下步骤:
[0096]
s1,arm预先通过mac调度信息完成每个时隙slot的pusch(physical uplink shared channel,物理上行共享信道)链路处理模块所需参数的计算,并将得到的pusch链路处理模块所需参数下发给上行基带处理单元bbu(baseband unit);
[0097]
所述pusch链路处理模块所需参数包括dmrs符号位置、调制方式qm、传输块大小tb size、速率匹配码字长度e、码率r、冗余版本rv、ldpc码字长度n、移位因子zc;这些参数将被用于pusch链路各功能单元进行具体的数字信号处理。
[0098]
s2,上行基带处理单元(通过前传cpri(common pubic radio interface)接口)接收iq频域数据,并利用pusch链路处理模块所需参数对iq频域数据进行pusch链路的符号级和比特级信号处理,然后输出若干个码字长度相等的cb码块;
[0099]
如图2所示,所述pusch链路的符号级和比特级信号处理,包括依次完成符号级的ofdm解调、信道估计、mimo均衡、解映射和软解调,以及比特级的解扰和解速率匹配。
[0100]
其中,在进行比特级的解速率匹配时,根据pusch链路处理模块所需参数(如调制编码方案mcs,传输块大小tb size、码块数c、移位因子zc、冗余版本rv等参数),将解扰后得到的tb传输块按照解速率匹配的处理方式,分成码字长度相等的若干个码字长度相等的cb码块,每个cb码块的码字长度为n。并且在进行比特级的解速率匹配时,mac层调度根据误块率(block error rate)等指标,确认是否进行harq重传:
[0101]
当mac层调度不开启harq重传时,物理层基带的解速率匹配模块将按照冗余版本rv=0进行处理,不会因为译码错误而重新处理某一个cb码块;当mac层开启harq重传时,解速率匹配模块将根据冗余版本rv的具体值,通过重新传输某一个cb码块或通过增加校验比特的方式进行数据合并,以此提高信噪比增益,进而有利于提高ldpc译码成功率。
[0102]
需要说明的是,harq重传在带来性能提升的同时,也会增加基带数字信号处理的延时,可能导致业务流量下降,因此可以根据需要选择是否开启harq重传。
[0103]
s3,确定是否对cb码块进行ldpc译码延时优化,如果是则进入步骤s4;否则进入步骤s5;
[0104]
根据调制编码调度mcs、码率r、冗余版本rv、信噪比snr以及数据流量需求等,来确定是否对cb码块进行ldpc译码延时优化。
[0105]
例如,在基于cb码块进行ldpc译码时,如果满足冗余版本rv=0、调制方式为256qam(例如,mcs》16)、信噪比snr在20db以上以及要求上行流量达到上gbit/s的数据业务流量等条件时,可对cb码块进行ldpc译码延时优化,则进行步骤s4,进而极大缩短ldpc译码处理时间,同时又能保持良好的译码性能和系统高吞吐率需求。
[0106]
s4,对cb码块的码字校验位进行裁剪打孔;具体地:
[0107]
s41,计算每个cb码块在进行ldpc译码前的码字总长度n
cb
:
[0108]ncb
=n+2zcꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0109]
其中,n为cb码块移相前的码字长度;
[0110]
s42,计算cb码块的码字校验位长度length
paritybits
:
[0111]
length
paritybits
=n+2z
c-k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0112]
其中,zc为移位因子,k为cb码块的码字信息位长度;
[0113]
s43,计算奇偶校验矩阵校验位的列数mb:
[0114][0115]
s44,由公式(1)~(3),得到mb与n的关系式:
[0116]
n=k+zc(mb-2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0117]
s45,计算实际的编码码率r:
[0118][0119]
s46,由公式(3)和(5)得到mb与r、k和zc的关系:
[0120][0121]
其中,计算mb时需要取整,并保证不小于4。在目前的5g nr技术规范中,对于基图bg1,k=22zc,mb的最大值为46;对于基图bg2,k=10zc,mb的最大值为42。对于基图bg1和基图bg2的结构,如图3和图4所示,其中,kb表示系统位的列数,对于基图bg1,kb取值为22;对于基图bg2,kb可能取值为6,8,9,10。mb表示校验位的列数,对于基图bg1,mb取值范围为4~46;对于基图bg2,mb取值范围为4~44。nb是奇偶校验矩阵h的总列数。核心矩阵具有高行重的特点,可保证ldpc译码性能。行正交有利于设计行并行或块并行的硬件实现结构,从而可提升译码速度。对于基图bg2而言,非行正交设计,对于中低码率的矩阵有较好的性能,通过矩阵扩展,可支持可靠性高的应用场景。
[0122]
s47,在调制编码方案mcs下,针对冗余版本rv=0,对解速率匹配处理输出的cb码块的校验位进行裁剪打孔,去掉尾部用“0x00”填充的llr软值后,由公式(6)计算出mb,再将计算出的mb代入公式(4),此时得到的码字长度n则为cb码块移相前并完成裁剪打孔后的码字长度n
′
。例如:某个时隙slot下的传输块tb,用基图bg1,k=8448,zc=384,r=0.8148,由公式(6)可计算出mb≈5。此时,根据公式(4),计算出cn码块移相前并完成裁剪打孔后的码字长度n
′
=8448+384
×
(5-2)=9600。因此,经过裁剪打孔校验位的llr软值,即减小cb码块的码字校验位长度,保留了有效的码字信息位和必要的码字校验位,对ldpc译码性能几乎无影响,但极大缩短了码字的长度,从而间接提升码率,减小奇偶校验矩阵h尺寸,从而减少了迭代译码的运算量,可大幅度缩短ldpc译码时间。
[0123]
s5,对cb码块起始的2zc个llr软值填充“0x00”;
[0124]
在对cb码块起始的2zc个llr软值填充“0x00”后,紧接着是信息为和校验位;因此送入ldpc译码的码字总长度为:
[0125]
(1)若不经过步骤s4对cb码块的码字校验位进行裁剪打孔,则送入ldpc译码的码字总长度为n
cb
=n+2zc;
[0126]
(2)若不经过步骤s4对cb码块的码字校验位进行裁剪打孔,则送入ldpc译码的码字总长度为n
cb
=n
′
+2zc。
[0127]
本实施例通过设计一个状态机fsm实现对cb码块起始的2zc个llr软值填充“0x00”的操作。如图5所示,所述状态机fsm包括四个状态:
[0128]
ilde状态:等待前级模块输入一个cb码块,并且在后级模块可接收数据时,状态进行跳转;
[0129]
read状态:读取码字长度为n或n
′
的cb码块,并对cb码块起始的2zc个llr软值填充“0x00”;
[0130]
wait状态:等待一个cb码块完成填充操作,随后进入gap状态;
[0131]
gap状态:在相邻两个cb码块的填充操作之间,通过一个延时处理时限隔离保护,防止逻辑时序紧张。
[0132]
进一步,对cb码块起始的2zc个llr软值填充“0x00”后需要进行数据拼接:
[0133]
首先,根据cb码块的码字长度为n或n
′
以及移位因子zc计算数据拼接的相对位置:对于浮点数的llr软值,硬件处理时需要进行定点化处理。例如,对于每个cb码块的llr软值的位宽可定义为8bit,定点格式8q2,表示为总位宽8bit,最低位是2bit的小数位,最高位是符号位。为提高ldpc译码吞吐率,ldpc译码器接口数据位宽按照256bit设计。为了便于进行数据拼接,需要计算2zc/32的整数和余数,以及(n
cb-2zc)/32的余数;然后根据(n
cb-2zc)/32的余数,确定每个cb码块的数据流在传输过程中,最后一拍有效数据在32字节中的结束位置;然后根据(n
cb-2zc)/32的余数,确定数据拼接的前后2个有效时钟周期的具体位置。
[0134]
然后,根据数据拼接的相对位置进行数据拼接:如图6所示,当2zc/32不能整除时,将其余数数目的“0”llr值放于256bit的低位,当前时钟的cb码块的数据放于256bit的高位;后续的数据拼接,按照当前时钟的cb码块的数据放于256bit的高位,上一时钟的cb码块的数据放于256bit的低位。
[0135]
s6,对步骤s5处理后的cb码块进行并行ldpc译码;
[0136]
如图7所示,本实施例中,ldpc译码器采用分层式调度的归一化最小和ldpc译码算法进行迭代译码,分时将步骤s5处理后的cb码块轮询送入多个并行的ldpc译码器进行ldpc译码,并且当译码奇偶校验通过时,允许译码过程提前结束。图中的参数管理器将tb级的参数转换为cb级参数,分发给填充2zc处理单元和多路选择器。填充2zc处理单元完成每个cb码块起始2zc个llr软值填充“0x00”并级联拼接有效llr码字信息。多路选择器模块根据当前处理的cb码块,依次轮询将cb码块送入4个ldpc译码器进行ldpc译码处理。ldpc译码器按照cb码块进行ldpc译码,输出每个cb码块的ldpc译码结果。输出控制单元将4个ldpc译码器的ldpc译码结果按照cb码块顺序进行轮询输出,传输给后级的crc校验模块。
[0137]
其中,为方便硬件逻辑处理,对高层(如5g通信中的协议栈,l2/l3)下发的校验位控制因子mb、移位因子zc、基图类型bg1或bg2等参数通过一个参数管理器进行缓存(fifo存储器)和管理,如图8所示,所述参数管理器基于cb码块进行ldpc译码参数配置。
[0138]
为便于多用户接入和管理,对于每个时隙slot调度的tb传输块,以及tb传输块内的cb码块进行指定,并分配相应的id编号(如时隙slot的id编号slot_id、tb传输块的id编号tb_id和cb码块的id编号cb_id),以便于硬件电路按照cb码块进行ldpc译码处理。
[0139]
采用分层式调度的归一化最小和ldpc译码算法的原理图如图9、图10所示,在迭代译码过程中,将校验节点分成若干组,在每一轮迭代计算时首先更新校验矩阵中的一组校验节点信息,然后更新所有和该组校验节点相邻的变量节点,接着再去更新下一组校验节点信息和与该组校验节点相邻的变量节点信息,以此类推,直到完成最后一组更新完成。本轮迭代结束后,根据检验方程和迭代次数设置,判断是否进行下一次迭代。同时,本轮迭代
更新的变量节点信息可用于下次迭代的校验节点信息更新,从而加快收敛速度,可以节约迭代次数并提高吞吐量。当校验通过或者达到最大迭代次数,可结束本次ldpc译码过程。同一时刻奇偶检验方程单元数量将决定硬件资源的消耗,所有校验节点同时参与运算以提高吞吐量的全并行ldpc译码,虽然可提高吞吐量,但硬件资源消耗巨大,对于码长和码率可变的情况,会造成硬件资源浪费。因此,采用分层式调度的归一化最小和ldpc译码算法,能够使得译码吞吐率和硬件资源消耗之间相对折中,在实践中具有可实施性。
[0140]
归一化最小和ldpc译码算法的主要计算公式如下:
[0141]
二元变量的度量用以下的对数似然比(llr)表示:
[0142][0143]
其中,l(x)提供了x的硬判决,并且模|l(x)|决定了硬判决的可靠性。
[0144]
将对数似然比llr转化为概率:
[0145][0146][0147]
从校验节点j到变量节点i的外部信息表示为对数似然比llr:
[0148][0149]
定义ldpc译码的奇偶校验矩阵h,用bj符号表示奇偶校验矩阵h的奇偶校验方程中的bit集合(每一行中1的位置集合),用ai表示第i位的奇偶校验方程(每一列中1的位置集合)。奇偶校验矩阵h的结构如图11所示,ldpc奇偶校验矩阵h由a、b、c、d、e五个子矩阵组成。子矩阵a对应系统待编码的信息比特;子矩阵b是一个具有双对角结构的方阵,对应于奇偶校验位。子矩阵b的第一列或最后一列的权重等于1,子矩阵b的最后一行有一个非零值和一个等于1的权重,如果有一个权重为1的列,那么其余的列包含一个方阵,使得第一列的权重为3。权重为3的列之后的列具有对角线结构(即主对角线和非对角线元素)。如果没有权值为1的列,子矩阵b只由一个方阵组成,使得第一列的权值为3。子矩阵c是一个全零矩阵,子矩阵d对应于单奇偶校验行,子矩阵e是基图(base graph,bg)的单位矩阵,对应于低扩展码率的校验比特。
[0150]
因此,由公式(8)~(10)可得到:
[0151][0152]
其中,
[0153]
考虑m
j,i
的符号位和大小:
[0154]mj,i
=α
j,i
β
j,i
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12-a)
[0155]
α
j,i
=sign(m
j,i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12-b)
[0156]
β
j,i
=|m
j,i
|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12-c)
[0157]
由公式(11)和(12),得到:
[0158][0159]
其中,定义为:
[0160][0161]
对于外部信息e
j,i
,从的形式上,考虑公式(13),求和中的最大值对应于最小的β
j,i
。因此,可获得下面的关系式:
[0162][0163]
由于(15)式的近似值偏大,会影响ldpc译码收敛速度,因此对该式进行修正:
[0164][0165]
其中,λ为归一化缩放因子,取值范围为0<λ≤1。本实施例中将归一化缩放因子λ基于cb码块进行动态配置,即针对每个cb码块进行ldpc译码时配置一个归一化缩放因子λ。特别地,在ldpc译码时长允许的情况下,可选择合适的单一归一化缩放因子λ对所有cb码块进行llr值进行近似缩放。在硬件实现中,对归一化缩放因子λ进行实时更新不太现实,尤其是针对5g基站上行pusch链路的信道解码处理。配置的归一化缩放因子λ的取值范围为0<λ≤1,为提升ldpc译码性能,优选将归一化缩放因子λ的值限定在0.6~0.9之间,一般默认值设为λ=0.75。在实际工程实现中,需要根据系统仿真情况,选择最合适的归一化缩放因子λ。
[0166]
于是,公式(13)可写成:
[0167][0168]
由于每个变量节点都可以连接输入信道的llr,以及每个校验节点的llr。第i位的总llr就是这两项llr的和
[0169][0170]
其中,li表示软解调后的llr软值。
[0171]
对于通信系统中的高斯白噪声(awgn)模型,接收到的第i个样本yi=x
ihi
+ni,其中ni符合独立正态分布n(0,σ2),n0是噪声密度。
[0172]
因此,容易得到信道转移概率:
[0173][0174]
其中,x∈{0,1},于是可得:
[0175][0176]
ldpc译码最终的硬判决由符号给出,判决的依据是检查是否满足奇偶校验方程以及是否达到设定的最大译码迭代次数。如果不满足,则更新m
j,i
:
[0177][0178]
因此,步骤s6中对步骤s5处理后的cb码块进行并行ldpc译码的过程包括如下步骤:
[0179]
s61,初始化:根据选择的信道模型,求解信道均衡后符号软解调后的llr软值,对所有的变量节点i,初始化软解调后的llr软值li;然后,对所有满足奇偶校验方程h
i,j
=1的i,j,设置m
j,i
=li,迭代次数iter
num
=0;定义bj表示奇偶校验矩阵h的第j个奇偶校验方程中的bit集合,ai表示第i个llr值的奇偶校验方程;
[0180]
s62,校验节点cn更新:应用下式对每个校验节点cn,计算消息e
j,i
的cn输出:
[0181]mj,i
=α
j,i
β
j,i
[0182]
α
j,i
=sign(m
j,i
)
[0183]
β
j,i
=|m
j,i
|
[0184][0185]
s63,对于i=0,1,
…
,n-1,应用下面的等式计算llr的和
[0186][0187]
s64,判断结束准则:对于i=0,1,
…
,n-1,令:
[0188][0189]
根据上式,获得判决的如果或者译码迭代次数达到设定的最大迭代次数iter
max
,则停止译码计算;否则进入s65。
[0190]
s65,变量节点vn更新:应用下式对每个变量节点vn,计算消息m
j,i
的vn输出:
[0191][0192]
iter
num
=iter
num
+1
[0193]
返回s62,继续迭代译码计算。
[0194]
在ldpc译码过程中,将校验节点分成若干组,在每一轮迭代译码中首先更新奇偶校验矩阵h中的一组校验节点cn,然后更新所有和该组校验节点相邻的变量节点vn。接着再更新下一组的cn信息和与该组相邻的vn信息,直到最后一组的cn信息和vn信息更新。由于前面已经更新的vn信息应用到本轮迭代后面的cn信息的更新过程,这样使得迭代收敛速度加快,并且可节省迭代次数,降低译码延时,提高译码的吞吐率。
[0195]
ldpc译码器吞吐率计算公式如下:
[0196][0197]
其中,n
cb
为每个cb码块在进行ldpc译码前的码字总长度;cycle为单次译码迭代时间周期;num
iter
为实际迭代次数;δ
t
为参数控制处理时间;f
clk
为ldpc译码器时钟频率;r为码率。
[0198]
ldpc译码时,主要参数有:每个cb码块在进行ldpc译码前的码字总长度n
cb
、基图bg1或bg2、用于索引移位因子zc的参数a和j、奇偶校验矩阵校验位的列数mb,最大迭代次数iter
max
等。
[0199]
其中,zc=a
×2j
,a={2,3,5,7,9,11,13,15},j={0,1,2,3,4,5,6,7}。
[0200]
并行的每个ldpc译码器的结构如图12所示,ldpc译码器包括输入控制单元、校验节点单元、llr存储分片、路由网络模块、移位网络模块和输出控制单元。输入控制单元实现ldpc译码参数的配置和数据的流控,并以一个cb码块的码字长度为处理单位传输数据帧。llr存储分片用于存储输入的信道llr值以及迭代更新后的llr值,存储分片的数目等于奇偶校验矩阵h的核矩阵的列数加1。校验节点单元的输入管脚数目等于奇偶校验矩阵最大的行重。路由网络模块将llr存储分片中经过循环移位后的llr数据输入到校验节点单元的管脚端口,校验节点单元通过读取不同组的管脚端口上的数据实现分层调度译码的功能,并通过迭代计算实现最终的译码输出。为便于ldpc译码迭代校验,移位网络模块可通过5g nr技术规范提供的pcm列表和移位因子zc值索引表,预先计算出所有只包含0和1的奇偶检验矩阵h,通过基图bg1或bg2和移位因子zc进行奇偶检验矩阵h的索引,进而完成奇偶检验。移位网络模块采用banyan网络结构,以便于支持不同的移位因子zc和硬件并行处理。检验节点存储器用于缓存每一次迭代后的检验节点值,用于下一次迭代时更新变量节点信息。输出控制单元完成数据位宽匹配和跨时钟域处理,同时将相关译码状态送出,便于监测译码器内部执行情况。
[0201]
s7,读出并行ldpc译码后的cb码块,并进行信息比特合路,由输出控制单元实现,输出控制单元的结构如图13所示,模块主要完成4个ldpc译码器按照cb码块要求轮询输出数据流,并将cb码块译码输出的信息比特进行级联输出,本质上也是一个“并串转换”和“时分复用”的设计思想。输出控制单元输出时用一个fifo存储器进行缓存,用于功能模块隔离。图13中,输入控制单元输入原始帧头信息,然后对输出的数据包长度等帧信息进行更新,并进行缓存,等待cb码块的ldpc译码结果输出,最终进行级联合路输出。读控制器用于控制4个ldpc译码器的数据和状态输出读取过程,并且实现tb块输出的数据对齐,防止不同的tb传输块之间的数据被交叉打乱,进而影响数据包的传输。cb码块数据计数器和状态计数器均为模4计数器,便于实现对4个ldpc译码器的轮询读取操作。输出选择器用来通过组帧实现cb码块的ldpc译码结果的信息比特合路,即先输出帧头,再输出一个tb传输块的所有cb码块的ldpc译码结果的信息比特集合。最后,将数据帧放入一个缓存单元中,后级的crc校验模块读取合路后的信息比特集合,进行crc校验。为了防止缓存单元溢出,将缓存单元的满状态反馈给读控制器,以此进行流控。此外,为了便于系统调试诊断,设计一个监测器,用于实时监测输出控制单元的状态,并可抓取关键信息进行在线分析诊断。
[0202]
s8,对合路后的cb码块进行crc校验,并在crc校验通过后合成一个tb传输块,然后
将tb传输块送往5g nr协议mac层。
[0203]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1