一种镍基高温合金低周疲劳寿命预测方法及系统
1.本发明涉及低周疲劳寿命预测技术领域,更具体的说是涉及一种基于ga-rf算法的镍基高温合金低周疲劳寿命预测方法及系统。
背景技术:
2.镍基高温合金综合性能优良,被广泛应用于石化、能源、航空航天等领域,如燃气轮机叶片、发电设备重要零部件、航空发动机核心部件等。服役条件下环境苛刻,合金承受载荷日益复杂如高温、高压、高载荷等,在工作过程中构件易造成低周疲劳损伤。因此在高温下的合金寿命预测是材料科学和工程领域的一个重要课题。高温下构件的失效寿命可能受到许多因素的影响,传统的预测方法是基于manson-coffin模型或是经验模型,通常需要花费大量的时间进行疲劳实验和建模,并且不能描述特征因子与疲劳寿命之间的非线性交互关系。人工神经网络、支持向量机、随机森林等人工智能方法为疲劳寿命预测提供了新的思路,它可以整合不同类型的特征因子,并构建模型来模拟特征因子与疲劳寿命之间的关系,克服传统模型的局限性。
3.基于随机森林算法的镍基高温合金低周疲劳寿命预测方法其关键步骤是特征因子的筛选和超参数的调整,目前因子筛选方法主要有相关系数法、逐步回归法和全子集回归法等,能够很好的反映单个因子与预测目标之间的相关关系。人工调整超参数需要耗费大量的时间,因此如何减少回归模型的训练时间成本,保证模型的精度,快速准确地预测镍基高温合金低周疲劳寿命,是本领域技术人员亟需解决的问题。
技术实现要素:
4.有鉴于此,本发明提供了一种基于ga-rf算法的镍基高温合金低周疲劳寿命预测方法及系统。
5.为了实现上述目的,本发明提供如下技术方案:
6.一种基于ga-rf算法的镍基高温合金低周疲劳寿命预测方法,包括以下步骤:
7.步骤1、获取初始数据集,所述初始数据集中包括若干个输入特征和镍基高温合金低周疲劳寿命,其中若干个输入特征为自变量,镍基高温合金低周疲劳寿命为因变量;
8.步骤2、对初始数据集中若干个所述输入特征进行特征筛选,得到特征筛选后的初始数据集;
9.步骤3、将特征筛选后的初始数据集划分为训练集和测试集;
10.步骤4、使用所述训练集,基于随机森林和遗传算法,构建ga-rf回归预测模型;
11.步骤5、使用所述测试集测试所述ga-rf回归预测模型的可靠性,直到预测精度达到预设条件,得到最终ga-rf回归预测模型;
12.步骤6、使用所述最终ga-rf回归预测模型对目标镍基高温合金进行低周疲劳寿命预测。
13.可选的,所述步骤1中,若干个输入特征中包括三类,分别为合金化学成分、热处理
工艺参数、疲劳实验参数。
14.可选的,所述步骤2中,对若干个所述输入特征进行特征筛选的方法为:
15.步骤2.1、计算每个输入特征和镍基高温合金低周疲劳寿命之间的皮尔逊相关系数pcc;
16.步骤2.2、计算每个输入特征和镍基高温合金低周疲劳寿命之间的最大信息系数mic;
17.步骤2.3、分别将所述皮尔逊相关系数pcc和最大信息系数mic进行排序,得到皮尔逊相关系数pcc序列和最大信息系数mic序列;
18.步骤2.4、删除皮尔逊相关系数pcc序列中最小值对应的输入特征,以及最大信息系数mic序列中最小值对应的输入特征,得到特征筛选后的输入特征集合,进而得到特征筛选后的初始数据集。
19.可选的,所述步骤2.1中,皮尔逊相关系数pcc的计算方法为:
[0020][0021]
其中,xi为输入特征,i=1,2,...,n,n表示输入特征的个数;y为输出值,即镍基高温合金低周疲劳寿命;表示输入特征xi与镍基高温合金低周疲劳寿命y之间的皮尔逊相关系数pcc;cov表示协方差,σ表示标准差。
[0022]
可选的,所述步骤2.2中,最大信息系数mic的计算方法为:
[0023][0024]
其中,xi为输入特征,i=1,2,...,n,n表示输入特征的个数;y为输出值,即镍基高温合金低周疲劳寿命;mic[xi,y]表示输入特征xi与镍基高温合金低周疲劳寿命y之间的最大信息系数mic,;p(xi,y)为输入特征xi与镍基高温合金低周疲劳寿命y之间的联合概率分布;p(xi)表示输入特征xi的边缘概率分布,p(y)表示镍基高温合金低周疲劳寿命y的边缘概率分布;b为经验值。
[0025]
可选的,所述步骤4中,使用所述训练集,基于随机森林和遗传算法,构建ga-rf回归预测模型的方法为:
[0026]
使用遗传算法迭代优化随机森林的超参数,所述超参数包括决策树个数和决策树最大深度,同时在超参数迭代优化过程中训练随机森林模型,基于种群个体适应度值,确定ga-rf回归预测模型。
[0027]
可选的,所述步骤4的具体过程为:
[0028]
步骤4.1、设置遗传算法参数;
[0029]
步骤4.2、随机初始化种群,产生种群基因型,每一个种群个体的基因型为一串二进制编码,代表随机森林决策树个数和决策树最大深度;
[0030]
步骤4.3、依据每个种群个体的基因型所代表的随机森林决策树个数和决策树最大深度,训练随机森林模型,得到与种群个体数量相同的随机森林模型;
[0031]
步骤4.4、计算每个随机森林模型的可决系数r2,作为对应的种群个体的适应度值;
[0032]
步骤4.5、判断是否达到预设迭代次数或优化目标,若是,则输出当代中适应度值最大的种群个体以及对应的随机森林模型,作为ga-rf回归预测模型,同时结束循环迭代,若否,则进入步骤4.6;
[0033]
步骤4.6、对种群进行选择、交叉、变异操作,并返回步骤4.2。
[0034]
可选的,所述步骤4.3中训练随机森林模型的具体过程为:
[0035]
步骤4.3.1、随机抽取样本:从训练集中采取有放回随机抽取样本,得到决策树的训练数据集;
[0036]
步骤4.3.2、随机抽取特征:从决策树的训练数据集中随机选取若干个特征,选择最佳分割属性作为节点建立cart决策树;
[0037]
步骤4.3.3、重复步骤4.3.1至步骤4.3.2,建立若干棵cart决策树,共同构成随机森林;
[0038]
步骤4.3.4、以所有cart决策树的预测结果均值,作为最终预测结果。
[0039]
可选的,所述步骤5中,选取可决系数r2作为模型可靠性测试依据。
[0040]
一种基于ga-rf算法的镍基高温合金低周疲劳寿命预测系统,包括:
[0041]
初始数据集获取模块,用于获取初始数据集,所述初始数据集中包括若干个输入特征和镍基高温合金低周疲劳寿命,其中若干个输入特征为自变量,镍基高温合金低周疲劳寿命为因变量;
[0042]
特征筛选模块,用于对初始数据集中若干个所述输入特征进行特征筛选,得到特征筛选后的初始数据集;
[0043]
数据集划分模块,用于将特征筛选后的初始数据集划分为训练集和测试集;
[0044]
模型构建模块,用于使用所述训练集,基于随机森林和遗传算法,构建ga-rf回归预测模型;
[0045]
模型测试模块,用于使用所述测试集测试所述ga-rf回归预测模型的可靠性,直到预测精度达到预设条件,得到最终ga-rf回归预测模型;
[0046]
预测模块,用于使用所述最终ga-rf回归预测模型对目标镍基高温合金进行低周疲劳寿命预测。
[0047]
经由上述的技术方案可知,本发明提供了一种基于ga-rf算法的镍基高温合金低周疲劳寿命预测方法及系统,与现有技术相比,具有以下有益效果:
[0048]
利用皮尔逊相关系数及最大信息系数进行特征筛选,选取针对低周疲劳寿命的决定性特征;并使用遗传算法进行超参数调整,随机森林算法的回归性能获得了显著提升,而且模型的训练时间也在可接受范围内,适应度快速向最佳适应度值靠近,且不易陷入局部最优解。
[0049]
本发明所构建的ga-rf回归预测模型具有良好的全局搜索能力,可以快速地将解空间中的全体解搜索出,而不会陷入局部最优解的快速下降陷阱;并且利用其内在并行性,可以方便地进行分布式计算,能够快速得到最佳的训练参数,提高模型的准确度,实现高精度高效率的低周疲劳寿命预测,克服了以往传统模型中只能以单一变量为研究对象的局限性,为材料科学和工程领域中提供了一种疲劳数据分析辅助手段。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0051]
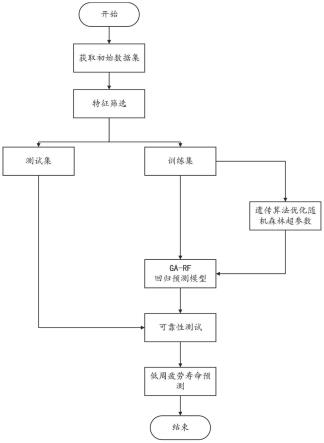
图1为本发明的方法流程示意图;
[0052]
图2为本发明实施例数据集中镍基高温合金低周疲劳数据分布图;
[0053]
图3为本发明实施例中皮尔逊相关系数计算结果示意图;
[0054]
图4为本发明实施例中最大信息系数计算结果示意图;
[0055]
图5为本发明中遗传算法优化超参数流程图;
[0056]
图6为本发明随机森林训练流程图;
[0057]
图7为本发明模型迭代30次过程中适应度值变化示意图;
[0058]
图8为迭代30次后模型预测结果示意图;
[0059]
图9为本发明模型迭代50次过程中适应度值变化示意图;
[0060]
图10为迭代50次后模型预测结果示意图;
[0061]
图11为本发明系统模块示意图。
具体实施方式
[0062]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0063]
本发明实施例公开了一种基于ga-rf算法的镍基高温合金低周疲劳寿命预测方法,如图1所示,包括以下步骤:
[0064]
步骤1、获取初始数据集。
[0065]
在本实施例中,如图2所示,镍基高温合金低周疲劳数据共83组,呈现出很大的离散性,因此确定与目标变量相关的输入特征。输入特征的选择应基于物理机制和实验观察,并且与目标变量无关的特征需要忽略以减少计算量,最终提取的共18个,分为三类,(1)合金化学成分组成:包括ni、cr、nb、mo、ti、al、c、co、fe、w、si共11个特征;(2)热处理工艺参数:包括solutiontemperature(热处理温度),solution time(热处理温度),aging processing(时效处理)共3个特征;(3)疲劳实验参数:包括total strain(总应变),plastic strain(塑性应变),stress ratio(应力比)及experimental temperature(实验温度)共4个特征。
[0066]
提取每一次实验的输出值,即因变量,最终确定为镍基高温合金低周疲劳寿命。
[0067]
步骤2、对初始数据集中若干个所述输入特征进行特征筛选,具体步骤为:
[0068]
步骤2.1、分别计算18个输入特征和镍基高温合金低周疲劳寿命之间的皮尔逊相关系数pcc:
[0069]
[0070]
其中,xi为输入特征,i=1,2,...,n,n表示输入特征的个数,在本实施例中n取18;y为输出值,即镍基高温合金低周疲劳寿命;表示输入特征xi与镍基高温合金低周疲劳寿命y之间的皮尔逊相关系数pcc;cov表示协方差,σ表示标准差。如图3所示,计算值在-1到1之间,大于0表示正相关,小于0表示负相关,ρ
x,y
的绝对值越大,表示线性相关性越强。
[0071]
步骤2.2、分别计算18个输入特征和镍基高温合金低周疲劳寿命之间的最大信息系数mic:
[0072][0073]
其中,xi为输入特征,i=1,2,...,n,n表示输入特征的个数;y为输出值,即镍基高温合金低周疲劳寿命;mic[xi,y]表示输入特征xi与镍基高温合金低周疲劳寿命y之间的最大信息系数mic,;p(xi,y)为输入特征xi与镍基高温合金低周疲劳寿命y之间的联合概率分布;p(xi)表示输入特征xi的边缘概率分布,p(y)表示镍基高温合金低周疲劳寿命y的边缘概率分布;b为经验值,通常取数据总量的0.6。
[0074]
如图4所示,计算值为0-1之间,值越大表示非线性相关性越强。
[0075]
步骤2.3、分别将所述皮尔逊相关系数pcc和最大信息系数mic进行排序,得到皮尔逊相关系数pcc序列和最大信息系数mic序列。
[0076]
步骤2.4、删除皮尔逊相关系数pcc序列中最小值对应的输入特征,以及最大信息系数mic序列中最小值对应的输入特征,在本实施例中删除的输入特征为cr与stress ratio,得到特征筛选后的输入特征集合,进而得到特征筛选后的初始数据集。
[0077]
步骤3、将特征筛选后的初始数据集划分为训练集和测试集,数据集划分的方法为随机划分,划分比例为0.85:0.15,随机种子参数为40。
[0078]
步骤4、使用所述训练集,基于随机森林和遗传算法,构建ga-rf回归预测模型。
[0079]
使用遗传算法迭代优化随机森林的超参数,所述超参数包括决策树个数和决策树最大深度,同时在超参数迭代优化过程中训练随机森林模型,基于种群个体适应度值,确定ga-rf回归预测模型,参见图5,具体步骤如下:
[0080]
步骤4.1、设置遗传算法参数:设置种群大小pop,选择算子为轮盘赌,交叉概率pc和变异概率pm,繁殖代数x和染色体长度为10。
[0081]
步骤4.2、根据种群数量随机初始化种群,产生种群基因型,每一个种群个体的基因型为一串二进制编码,代表随机森林决策树个数和决策树最大深度;
[0082]
步骤4.3、依据每个种群个体的基因型所代表的随机森林决策树个数和决策树最大深度,训练随机森林模型,得到与种群个体数量相同的随机森林模型;
[0083]
步骤4.4、计算每个随机森林模型的可决系数r2,作为对应的种群个体的适应度值。
[0084]
可决系数r2计算公式为:
[0085][0086]
式中,yi是真实值,是真实值的均值,为预测值。
[0087]
以此计算种群中每个个体的适应度值。
[0088]
步骤4.5、判断是否达到预设迭代次数或种群中最佳个体的适应度值达到预设条件,若是,则输出当代中适应度值最大的种群个体以及对应的随机森林模型,作为ga-rf回归预测模型,同时结束循环迭代,若否,则进入步骤4.6;
[0089]
步骤4.6、对种群进行选择、交叉、变异操作,并返回步骤4.2。
[0090]
选择:在适应度计算完成后,根据确定的选择算子挑选作为父代的个体,染色体基因的适应度值越大,则该染色体个体被选中的几率就越大。
[0091]
交叉:随机选择两个个体和一个[0,1]之间的随机数r1,当r1<pc时发生交叉,交叉位也是随机的。
[0092]
变异:与交叉一样,生成一个随机数r2,当r2<pm时发生变异。变异就是在随机的基因位上将数值进行改变,进而产生一个新的个体。
[0093]
步骤4.3中训练随机森林模型的具体过程参见图6:
[0094]
步骤4.3.1、随机抽取样本:假设训练集共有m个对象的数据,采取有放回(boostrap)随机抽取n个样本,每一次取出的样本不完全相同,这些样本组成了决策树的训练数据集;
[0095]
步骤4.3.2、随机抽取特征:假设每个样本数据都有k个特征,从所有特征中随机地选取k(k《=k)个特征,选择最佳分割属性作为节点建立cart决策树,决策树成长期间k的大小始终不变(在python中构造随机森林模型的时候,默认取特征的个数k是k的平方根,即);
[0096]
步骤4.3.3、重复步骤4.3.1至步骤4.3.2,建立m棵cart决策树,这些树都要完全的成长且不被修剪,共同构成了随机森林;
[0097]
步骤4.3.4、以所有cart决策树的预测结果的平均值,作为最终预测结果。
[0098]
通过上述过程,基于遗传算法训练得到的随机森林模型,即为ga-rf回归预测模型。
[0099]
其中随机森林超参数包括:
[0100]
n_estimators:森林中树的个数。这个参数是典型的模型表现与模型效率成反比的影响因子。本模型初始数目为20;
[0101]
criterion:度量分裂的标准。可选值:“mse”,均方差;“mae”,平均绝对值误差,默认值为mse;
[0102]
max_features:这个参数用来训练每棵树时需要考虑的最大特征个数,超过限制个数的特征都会被舍弃,默认为auto。可填入的值有:int值,float(特征总数目的百分比),“auto”/“sqrt”(总特征个数开平方取整),“log2”(总特征个数取对数取整);
[0103]
max_depth:integer或者none。树的最大深度,如果none,节点扩展直到所有叶子是纯的或者所有叶子节点包含的样例数小于min_samples_split,本模型初始值为2;
[0104]
min_samples_split:分裂内部节点需要的最少样例数。int(具体数目),float(数目的百分比),默认值为2;
[0105]
min_samples_leaf:叶子节点上应有的最少样例数。int(具体数目),float(数目的百分比)。默认值为1;
[0106]
max_leaf_nodes:最大叶节点数,通过限制最大叶子节点数,可以防止过拟合,默
认是“none”;
[0107]
min_impurity_split:节点划分最小不纯度。这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点。默认值为1e-7;
[0108]
min_impurity_decrease:一个阈值,表示一个节点分裂的条件是:如果这次分裂纯度的减少大于等于这这个值。默认值为0;
[0109]
bootstrap:构建树是不是采用有放回样本的方式。默认值为“true”;
[0110]
oob_score:交叉验证相关的属性。默认值为“false”;
[0111]
n_jobs:设定fit和predict阶段并列执行的任务个数,默认值为“none”;
[0112]
random_state:如果是int数值表示它就是随机数产生器的种子.本模型设置为42;
[0113]
verbose:控制构建数过程的冗长度;默认值为“none”;
[0114]
warm_start:当设置为true,重新使用之前的结构去拟合样例并且加入更多的估计器到组合器中,默认值为“false”。
[0115]
需要说明的是,上述随机森林的优化参数为决策树的个数(n_estimators)与决策树的最大深度(max_depth),因此随机数种子设置为42,其余参数均为默认值。
[0116]
步骤5、使用所述测试集测试所述ga-rf回归预测模型的可靠性,直到预测精度达到预设条件,得到最终ga-rf回归预测模型。
[0117]
本实施例中,在测试集上使用该初始样本集训练的模型预测的镍基高温合金低周疲劳寿命与实际值之间的可决系数为0.7959。
[0118]
当经过初始种群为30,迭代30次优化后的模型可决系数为0.9574,其迭代过程如图7所示,在测试集上测试模型的可靠性,其预测结果如图8所示;当经过初始种群为30,迭代50次优化后的模型可决系数为0.9608,其迭代过程如图9所示,在测试集上测试模型的可靠性,其预测结果如图10所示。
[0119]
可见,上述实施例通过实验证明了经过ga的优化,随机森林算法的回归性能获得了显著提升,而且模型的训练时间也在可接受范围内。适应度在前10次迭代中就快速向最佳适应度值靠近,且不易陷入局部最优解。
[0120]
步骤6、使用所述最终ga-rf回归预测模型对目标镍基高温合金进行低周疲劳寿命预测。
[0121]
在另一实施例中还公开一种基于ga-rf算法的镍基高温合金低周疲劳寿命预测系统,参见图11,包括:
[0122]
初始数据集获取模块,用于获取初始数据集,所述初始数据集中包括若干个输入特征和镍基高温合金低周疲劳寿命,其中若干个输入特征为自变量,镍基高温合金低周疲劳寿命为因变量;
[0123]
特征筛选模块,用于对初始数据集中若干个所述输入特征进行特征筛选,得到特征筛选后的初始数据集;
[0124]
数据集划分模块,用于将特征筛选后的初始数据集划分为训练集和测试集;
[0125]
模型构建模块,用于使用所述训练集,基于随机森林和遗传算法,构建ga-rf回归预测模型;
[0126]
模型测试模块,用于使用所述测试集测试所述ga-rf回归预测模型的可靠性,直到预测精度达到预设条件,得到最终ga-rf回归预测模型;
[0127]
预测模块,用于使用所述最终ga-rf回归预测模型对目标镍基高温合金进行低周疲劳寿命预测。
[0128]
对于实施例公开的系统模块而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0129]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
[0130]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1