一种基于甲基化差异预测样本来源的方法及装置与流程
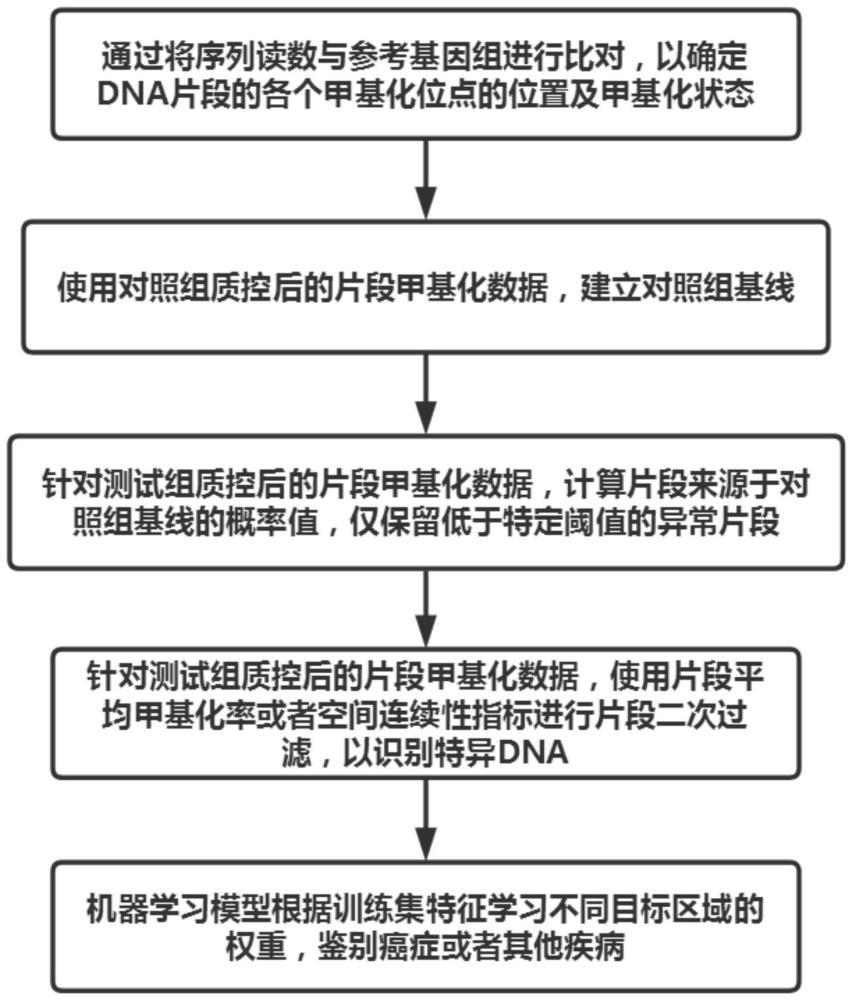
本发明涉及生物信息学领域,具体涉及一种基于甲基化差异预测样本来源的方法及装置。
背景技术:
1、循环细胞游离肿瘤dna(ctdna)的识别被日渐认为是可以用于检测,诊断,监测癌症的一种无创液体活检的重要诊断工具。并且dna甲基化被公认为在调控基因表达过程中发挥着重要的作用。使用全基因组甲基化测序(例如,全基因组亚硫酸氢盐定序(wgbs),全基因组酶转化测序(gm-seq))的dna甲基化图谱可以识别出具有疾病/癌症特异甲基化模式的ctdna分子标记。然而,本领域仍需要灵敏度更高、特异性更好的识别特定甲基化模式的改良方法,以检测、诊断、监测如癌症等疾病。
技术实现思路
1、根据第一方面,在一实施例中,提供一种基于甲基化差异预测样本来源的方法,包括:
2、甲基化状态获取步骤,包括获取待测样本的甲基化测序数据中的甲基化状态;
3、片段分析步骤,包括使用选自对照组基线概率算法、平均甲基化率算法、空间连续性算法中的至少一种分析待测样本测序数据中片段的甲基化状态;
4、预测步骤,包括根据对照组基线数据,预测待测样本来源于患病个体或对照组个体,或者预测待测样本来源于患病个体的概率。
5、根据第二方面,在一实施例中,提供一种基于甲基化差异预测样本来源的装置,包括:
6、甲基化状态获取模块,用于获取待测样本的甲基化测序数据中的甲基化状态;
7、片段分析模块,用于使用选自对照组基线概率算法、平均甲基化率算法、空间连续性算法中的至少一种分析待测样本测序数据中片段的甲基化状态;
8、预测模块,用于根据对照组基线数据,预测待测样本来源于患病个体或对照组个体,或者预测待测样本来源于患病个体的概率。
9、根据第三方面,在一实施例中,提供一种基于甲基化差异预测样本来源的装置,包括:
10、存储器,用于存储程序;
11、处理器,用于通过执行所述存储器存储的程序以实现如第一方面任意一项的方法。
12、根据第四方面,在一实施例中,提供一种计算机可读存储介质,所述介质上存储有程序,所述程序能够被处理器执行以实现如第一方面任意一项的方法。
13、依据上述实施例的一种基于甲基化差异预测样本来源的方法及装置,该方法有效提高特异dna识别的准确性。
技术特征:
1.一种基于甲基化差异预测样本来源的方法,包括:
2.如权利要求1所述的方法,其特征在于,预测步骤中,根据待测样本中片段的对照组基线概率值与预设阈值的大小关系,预测该片段是否为异于对照组个体的异常片段。
3.如权利要求1所述的方法,其特征在于,预测步骤中,若待测样本中片段的对照组基线概率值低于预设阈值,则预测该片段为异于对照组个体的片段,反之,则预测该片段为来源于对照组个体的片段。
4.如权利要求1所述的方法,其特征在于,预测步骤中,所述对照组基线数据包括区域内每2个、3个或n个相邻cpg位点对应的平均甲基化率,n为>3的自然数;
5.如权利要求1所述的方法,其特征在于,片段分析步骤中,包括使用对照组基线概率值算法分析待测样本测序数据中片段的甲基化状态。
6.如权利要求1所述的方法,其特征在于,片段分析步骤中,包括使用a)对照组基线概率算法,以及b)平均甲基化率算法、空间连续性算法中的至少一种,分析待测样本测序数据中片段的甲基化状态。
7.如权利要求1所述的方法,其特征在于,片段分析步骤中,对照组基线概率的计算公式如下:
8.如权利要求1所述的方法,其特征在于,片段分析步骤中,空间连续性的计算公式如下:
9.如权利要求1所述的方法,其特征在于,片段分析步骤中,根据待测样本测序数据的片段中甲基化的cpg位点个数与总cpg位点个数的占比计算得到片段平均甲基化率。
10.如权利要求1所述的方法,其特征在于,在片段分析步骤使用片段平均甲基化率算法、空间连续性算法、对照组基线概率算法中的至少一种分析片段的甲基化状态后,预测步骤中,根据待测样本测序数据中如下信息中的至少一种:1)目标区域的所有片段的平均甲基化率,2)目标区域的所有片段的空间连续性,3)目标区域的特异dna片段占比;预测待测样本来源于患病个体或对照组个体,或者预测待测样本来源于患病个体的概率;
11.如权利要求1所述的方法,其特征在于,预测步骤中,使用模型预测待测样本来源于患病个体或对照组个体,或者预测待测样本来源于患病个体的概率;
12.如权利要求1所述的方法,其特征在于,根据待测样本输入特征判断该样本来自患病个体的概率值,将所述概率值与预设概率阈值进行比较,判断该待测样本是否来自于患病个体。
13.如权利要求1所述的方法,其特征在于,分析步骤中,使用片段平均甲基化率算法、空间连续性算法、对照组基线概率算法中的至少一种分析片段的甲基化状态后,预测步骤中,使用目标区域的所有片段的平均甲基化率、空间连续性指标中的至少一种的平均值作为特征,或者使用识别的特异dna片段占比作为特征构建预测模型,预测待测样本所属个体是否患有疾病,或所患的疾病的概率。
14.如权利要求1所述的方法,其特征在于,预测步骤中,计算目标区域内每条保留的异常片段的片段平均甲基化率与空间连续性,将其预处理为横坐标为每个目标区域的平均甲基化率或者空间连续性代表的甲基化水平,纵坐标为每个样本的二维矩阵,构建预测模型。
15.如权利要求1所述的方法,其特征在于,预测步骤中,若目标区域为疾病低甲基化区域,则仅保留空间连续性大于预设阈值或者片段平均甲基化率小于预设阈值的片段,使用该疾病特异低甲基化的共甲基化片段计数在所有质控合格的甲基化片段计数中的占比构建模型,将其预处理为横坐标为每个目标区域的特异dna占比,纵坐标为每个样本的二维矩阵,构建预测模型;
16.如权利要求1所述的方法,其特征在于,预测步骤中,所述患病个体所患疾病包括癌症或其他疾病;
17.一种基于甲基化差异预测样本来源的装置,其特征在于,包括:
18.一种基于甲基化差异预测样本来源的装置,其特征在于,包括:
19.一种计算机可读存储介质,其特征在于,所述介质上存储有程序,所述程序能够被处理器执行以实现如权利要求1~16任意一项所述的方法。
技术总结
一种基于甲基化差异预测样本来源的方法及装置,该方法包括甲基化状态获取步骤,包括获取待测样本的甲基化测序数据中的甲基化状态;片段分析步骤,包括使用选自对照组基线概率算法、平均甲基化率算法、空间连续性算法中的至少一种分析待测样本测序数据中片段的甲基化状态;预测步骤,包括根据对照组基线数据,预测待测样本来源于患病个体或对照组个体,或者预测待测样本来源于患病个体的概率。该方法有效提高特异DNA(包括但不限于组织特异DNA、细胞特异DNA、肿瘤特异DNA或疾病特异DNA识别)的准确性。
技术研发人员:黄毅,刘高彤,刘青峰,李俊,易鑫,杨玲
受保护的技术使用者:深圳吉因加医学检验实验室
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!