培养基成分优化的方法及装置与流程
本发明涉及培养基有效成分筛选领域,具体而言,涉及一种培养基成分优化的方法及装置。
背景技术:
1、正交试验设计,是指研究多因素多水平的一种试验设计方法。根据正交性从全面试验中挑选出部分有代表性的点进行试验,这些有代表性的点具备均匀分散、齐整可比的特点。正交试验设计的主要工具是正交表,试验者可根据试验的因素数、因素的水平数以及是否具有交互作用等需求查找相应的正交表,再依托正交表的正交性从全面试验中挑选出部分有代表性的点进行试验,可以实现以最少的试验次数达到与大量全面试验等效的结果。
2、现有培养基成分筛选的方法,多基于生物研发人员的经验,查阅相关文献,在培养基中加入对细胞生长、表达有用的成分。之后再通过正交试验设计以及单因素实验分析来确定最终的成分。然而,正交试验设计中,当试验涉及的因素在3个或3个以上,并且因素之间存在相互作用时,试验工作量会变得很大甚至难以实施。
3、机器学习是人工智能的一个分支。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法,包括了支持向量回归(svr)、决策树、梯度提升树(boosting类算法,gbdt)、随机森林、多层感知机(mlp)等方法。机器学习考虑培养基中的各个成分,然后通过建立不同的模型对数据进行拟合。机器学习最大的优点是不需要专家经验,可以利用已有的试验结果进行建模,给出准确的预测。进行一定的训练之后,机器学习即可计算出最优培养基的配比以及特征(成分)重要性。由于利用机器学习进行预测,需要基于大量的试验数据,而在实际生产中,进行大量的试验数据(至少需要10倍于特征数量的样本数量,在深度学习中,样本数量通常以数万计的)收集需要较高的时间成本以及经济成本。
4、由此可见,目前的培养基有效成分的筛选方法要么存在忽略培养基中各个因素之间的相互作用,要么需要大量培养试验导致成本高,效率低的问题。
技术实现思路
1、本发明的主要目的在于提供一种培养基成分优化的方法及装置,以解决现有技术中的培养基优化时间周期长、成本高的问题。
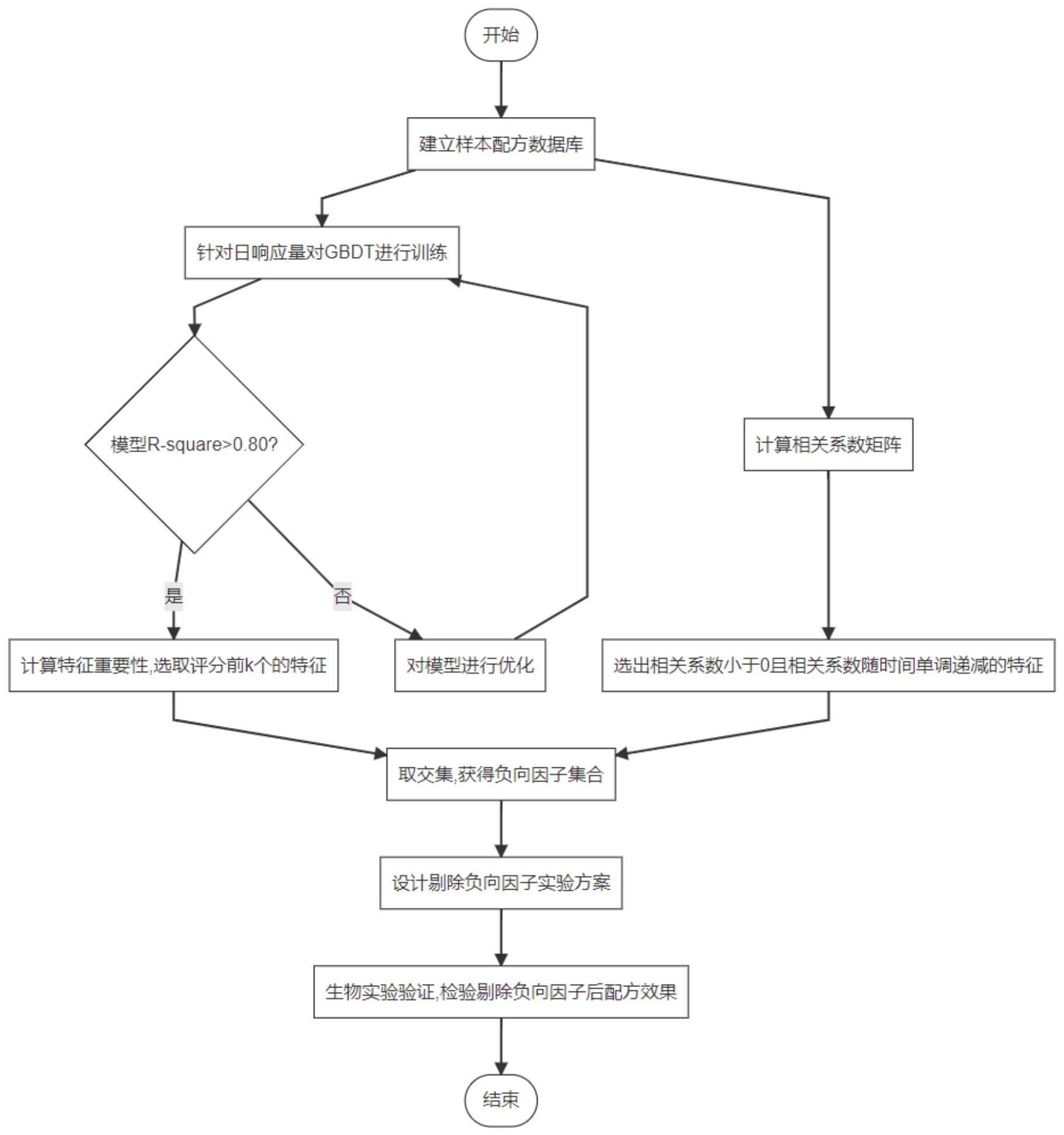
2、为了实现上述目的,根据本发明的一个方面,提供了一种培养基成分优化的方法,该方法包括:以培养基各成分为输入特征,以日响应量为目标值,建立机器学习模型,并计算相关系数;计算各个输入特征的特征重要性,挑出特征重要性评分的前k项,归为第一集合;将所有对日响应量为负相关系数的成分记为负向因子,并将所有负向因子归为第二集合;取第一集合与第二集合的交集,获得负向因子集合;从培养基成分集合中剔除一个或多个负向因子集合中的成分,得到优化后的培养基成分。
3、进一步地,日响应量包括如下至少一种:细胞表达量、细胞密度及细胞活率;优选地,机器学习模型为回归分析模型,优选地,相关系数的计算方法包括偏最小二乘法或pearson相关系数。
4、进一步地,将所有对日响应量为负相关系数的成分记为负向因子,并将所有负向因子归为第二集合包括:挑选负相关系数随时间单调递减的负向因子,归为第二集合。
5、进一步地,将样本数据集划分为第一响应量数据集与第二响应量数据集,其中,第一响应量数据集的日响应量高于第二响应量数据集中相应的日响应量;在第一响应量数据集与第二响应量数据集中计算各个输入特征与日响应量的相关系数矩阵;根据相关系数矩阵,筛选出所有相关系数小于0且随时间单调递减的成分,记为第二集合;优选地,将响应量排在前20%~30%的样本数据划为第一响应量数据集,其余划分为第二响应量数据集。
6、进一步地,得到优化后的培养基成分后,该方法还包括实验验证的步骤;优选地,按照如下至少一种方式从培养基成分集合中剔除负向因子集合,1)从培养基成分集合中删除负向因子集合中的所有成分;2)将负向因子集合中的成分逐个从培养基成分中删除;3)根据已知信息从负向因子集合中去除已知必需成分,得到更新后的负向因子集合,从培养基成分集合中删除更新后的负向因子集合中的所有成分。
7、为了实现上述目的,根据本发明的第二个方面,提供了一种培养基成分优化的装置,该装置包括:模型建立模块,被设置为以培养基成分集合为输入特征,以日响应量为目标值,建立机器学习模型,并计算相关系数;重要特征挑选模块,被设置为计算各个输入特征的特征重要性,并挑出特征重要性评分的前k项,归为第一集合;负向因子挑选模块,被设置为将所有对日响应量为负相关系数的成分记为负向因子,并将所有负向因子归为第二集合;交集模块,被设置为取第一集合与第二集合的交集,获得负向因子集合;剔除模块,被设置为从培养基成分集合中剔除一个或多个负向因子集合中的成分,得到优化后的培养基成分。
8、进一步地,日响应量包括如下至少一种:细胞表达量、细胞密度及细胞活率;优选地,机器学习模型为回归分析模型,优选地,相关系数的计算方法包括偏最小二乘法或pearson相关系数。
9、进一步地,负向因子挑选模块包括:数据集划分模块,被设置为将样本数据集划分为第一响应量数据集与第二响应量数据集,其中,第一响应量数据集的日响应量高于第二响应量数据集中相应的日响应量;相关系数矩阵计算模块,被设置为在第一响应量数据集与第二响应量数据集中计算各个输入特征与日响应量的相关系数矩阵;筛选模块,被设置为根据相关系数矩阵,筛选出所有相关系数小于0且随时间单调递减的成分,记为第二集合;优选地,将日响应量排在前20%~30%的样本数据划为第一响应量数据集,其余划分为第二响应量数据集。
10、进一步地,装置还包括实验验证模块,被设置为从培养基成分集合中剔除负向因子集合后,对优化后的培养基成分进行生物实验,测量优化后的培养基成分的日响应量,从而确定最终的负向因子。
11、进一步地,剔除模块包括如下至少一种剔除子模块,剔除子模块1,被设置为从培养基成分集合中删除负向因子集合中的所有成分;剔除子模块2,被设置为将负向因子集合中的成分逐个从培养基成分中删除;剔除子模块3,被设置为根据已知信息从负向因子集合中去除已知必需成分,得到更新后的负向因子集合,从培养基成分集合中删除更新后的负向因子集合中的所有成分。
12、根据本发明的第三个方面,提供了一种计算机可读存储介质,计算机可读存储介质包括存储的程序,其中,在程序运行时控制存储介质所在设备执行上述任一种培养基成分优化的方法。
13、根据本发明的第四个方面,提供了一种处理器,处理器用于运行程序,其中,程序运行时执行上述任一种培养基成分优化的方法。
14、应用本发明的技术方案,通过在机器学习对各培养基成分特征重要性计算的基础之上,结合相关性分析的相关方法,剔除对培养效果起到负相关作用的成分,此外,通过机器学习模型中的特征重要性筛选,还能考虑到培养基中不同成分之间的相互作用,能提高成分筛选的准确性,从而在小样本的场景下也能得到比较好的效果。通过采用本申请的机器学习方法对数据进行建模分析,缩短了培养基优化的研发周期,减少重复试验。
技术特征:
1.一种培养基成分优化的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述日响应量包括如下至少一种:细胞表达量、细胞密度及细胞活率;
3.根据权利要求1所述的方法,其特征在于,将所有对所述日响应量为负相关系数的成分记为负向因子,并将所有所述负向因子归为第二集合包括:挑选所述负相关系数随时间单调递减的所述负向因子,归为所述第二集合。
4.根据权利要求3所述的方法,其特征在于,
5.根据权利要求1所述的方法,其特征在于,得到优化后的培养基成分后,所述方法还包括实验验证的步骤;
6.一种培养基成分优化的装置,其特征在于,所述装置包括:
7.根据权利要求6所述的装置,其特征在于,所述日响应量包括如下至少一种:细胞表达量、细胞密度及细胞活率;
8.根据权利要求6所述的装置,其特征在于,所述负向因子挑选模块包括:
9.根据权利要求6所述的装置,其特征在于,所述装置还包括实验验证模块,被设置为从所述培养基成分集合中剔除所述负向因子集合后,对优化后的培养基成分进行生物实验,测量优化后的所述培养基成分的日响应量,从而确定最终的负向因子。
10.根据权利要求6所述的装置,其特征在于,所述剔除模块包括如下至少一种剔除子模块,
11.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括存储的程序,其中,在所述程序运行时控制所述存储介质所在设备执行权利要求1至5中任意一项所述的培养基成分优化的方法。
12.一种处理器,其特征在于,所述处理器用于运行程序,其中,所述程序运行时执行权利要求1至5中任意一项所述的培养基成分优化的方法。
技术总结
本发明提供了一种培养基成分优化的方法及装置。该方法包括以培养基各成分为输入特征,以日响应量为目标值,建立机器学习模型并计算相关系数;计算各个输入特征的特征重要性,挑出特征重要性评分的前k项归为第一集合;将所有对日响应量为负相关系数的成分记为负向因子并将所有负向因子归为第二集合;取第一集合与第二集合的交集获得负向因子集合;从培养基成分集合中剔除一个或多个负向因子集合中的成分,得到优化后培养基成分。此发明通过机器学习对各培养基成分特征重要性计算,考虑到培养基中不同成分之间的相互作用,结合相关性分析的相关方法剔除负相关作用的成分,提高成分筛选的准确性,实现小样本量优化,缩短研发周期,减少重复试验。
技术研发人员:陈亮,张博睿,陈红,胡志鹏,梁国龙
受保护的技术使用者:深圳太力生物技术有限责任公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!