一种序列合成周期预测模型的构建方法及其应用与流程
本发明属于分子生物学及生物信息学,具体涉及一种序列合成周期预测模型的构建方法及其应用。
背景技术:
1、生物技术和信息技术的结合,基因合成技术以超摩尔定律的速度普及,基因合成作为生命科学的基础,在生物医药、疾病研究等多个领域得到应用,市场需求持续攀升。基因合成不依赖于序列模板,而是在体外化学人工合成双链dna,合成片段相对较长可达kb级别,基因合成在流程上是一个不断设计、改造、验证、修正的试错过程。目前,大多商业化dna合成公司通常采用柱式合成法,即基于四步法亚磷酰胺化学合成方法,在固相上进行寡核苷酸合成。这些寡核苷酸通常可以合成多达100nt~200nt,错误率在0.5%或以下,每个单体耦合效率通常可达99%。
2、目前,大多数的基因合成是通过外包服务的模式,由基因合成公司代为设计合成的,随着基因合成需求的日益增长,客户对于交付时间有了更明确的要求。但是待合成的基因序列不仅长度不同,其合成难度也各不相同,很难准确的预估序列的合成周期,基因合成公司通常是依据多年的合成经验,给客户提供大致的交付周期。
3、如cn111192629a公开了一种基因序列难度分析模型,该模型使用机器学习中常用的几种回归算法构建定量预测模型,选取一定量的已知序列进行训练,最终输入序列中提取的特征,即可预估基因序列的难度,以预测待测基因的合成周期。但其用于训练模型的基因序列数据量有限,导致模型不够准确;序列特征只考虑了序列gc含量,没有考虑at含量和at富集情况,且只考虑了重复序列的长度,虽然也考虑了正向和反向重复占序列总长度与重复覆盖区的比例,但其核心仍然是长度,并没有考虑重复序列与序列中位置的关联关系,而重复序列出现的位置可能会影响序列合成难度;此外,只使用传统机器学习回归算法,难以处理大规模复杂数据。
技术实现思路
1、针对现有技术的不足和实际需求,本发明提供一种序列合成周期预测模型的构建方法及其应用,所述方法可以对不同复杂度的基因序列合成周期进行预测,操作简单,准确率高,有利于基因合成的统筹安排,提高合成效率。
2、为达上述目的,本发明采用以下技术方案:
3、第一方面,本发明提供一种序列合成周期预测模型的构建方法,包括:
4、选取若干已知序列,所述已知序列包括已知不同长度、不同合成周期的基因序列;
5、对所述已知序列进行序列特征提取,将提取的序列特征与所述已知序列作为数据库的训练数据;
6、将所述训练数据,利用深度学习中的embedding技术、transformer模型和两个神经网络建立序列合成周期预测模型。
7、在深度学习中,embedding是一种常用技术,它可以将离散型的输入特征映射为连续的向量表示,以便神经网络理解和处理,从而提高模型的表现。
8、transformer是一种用于处理序列数据的深度学习模型,最初由vaswani等人在2017年提出。传统的序列模型,如循环神经网络(rnn)或卷积神经网络(cnn),在处理长序列时存在一些问题,如梯度消失、梯度爆炸等。相比之下,transformer模型采用了一种完全不同的思路,它不使用循环或卷积,而是使用注意力机制(attention mechanism)来处理输入序列。该机制也是模仿人脑的信息处理过程,即将有限的注意力集中到重点信息上,从而节省资源,快速获得有效信息。与传统的序列模型相比,transformer模型具有如下优点:支持并行计算,因而可以提高计算效率;支持长序列建模,能够同时考虑序列中的所有元素,因而提高模型准确率;具有较好的泛化性能,已在机器翻译和文本生成等任务上取得了较好的效果。
9、优选地,所述神经网络包括linear神经网络和dense神经网络。
10、优选地,所述linear神经网络包含4个线性变换层,所述dense神经网络包含3个线性变换层。
11、优选地,所述序列特征包括碱基类型、序列重复情况、at/gc富集情况、序列长度、总重复序列得分、at富集分、gc富集分以及最长重复子序列长度。
12、第二方面,本发明提供第一方面所述的构建方法构建得到的预测模型在预测基因序列合成周期中的应用。
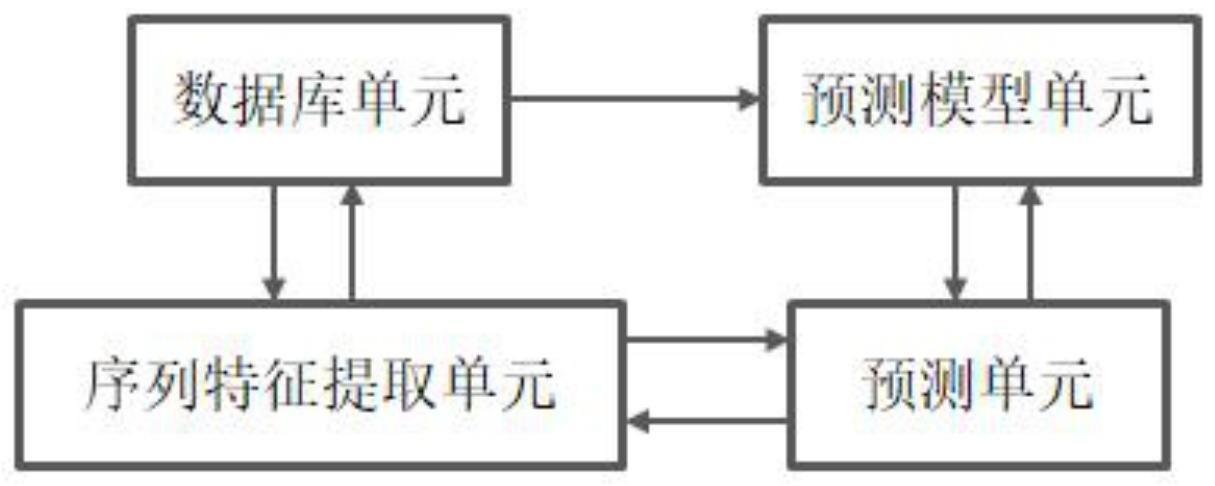
13、第三方面,本发明提供一种序列合成周期预测装置,包括:
14、序列特征提取单元,用于对已知序列进行序列特征提取;除了为预测模型单元准备训练数据外,还需要为预测单元提供服务;
15、数据库单元,用于获取已知不同长度、不同合成周期的基因序列和经过序列特征提取单元处理后获取的序列特征信息,划分为训练集和测试集;这些数据将被输入预测模型单元,以训练模型参数,形成最终的预测模型;
16、预测模型单元,用于训练数据库单元中的训练集数据,构建预测模型;
17、预测单元,用于输入待测序列,调用序列特征提取单元和预测模型单元,预测序列的合成周期。
18、优选地,所述预测模型单元包括:linear子单元、embedding子单元、encoder子单元、dense子单元和represent子单元。
19、优选地,所述embedding子单元包括两层结构,第一层使用pytorch中的embedding类,第二层将embedding的结果相加,然后使用pytorch中的nn.layernorm实现层归一化。
20、pytorch是一个基于torch的python开源机器学习库,提供了大量的工具和接口,可以用于构建各种深度学习模型,包括卷积神经网络、循环神经网络、变分自编码器等。此外,pytorch还提供了许多高级功能,如自动微分、分布式训练等,使得深度学习变得更加容易和高效。
21、与现有技术相比,本发明具有以下有益效果:
22、本发明提供的序列合成周期预测模型的构建方法,用于构建序列数据库的不同长度、不同合成周期的序列大于20000条,且都来源于真实的业务案例,因此有助于构建更准确的预测模型;本发明在提取序列特征时,综合考虑了gc和at的含量与各自在序列中的富集情况,对非重复序列、普通重复序列和最长重复序列所在的位置赋予不同的数值,这样既区分了不同的重复情况,又记录并关联了重复位置与重复情况,进一步提高了预测模型的准确率;本发明使用了深度学习中的优秀模型,不仅可以处理大规模数据,而且可以使用分布式计算提升训练速度。
技术特征:
1.一种序列合成周期预测模型的构建方法,其特征在于,包括:
2.根据权利要求1所述的构建方法,其特征在于,所述神经网络包括linear神经网络和dense神经网络。
3.根据权利要求2所述的构建方法,其特征在于,所述linear神经网络包含4个线性变换层,所述dense神经网络包含3个线性变换层。
4.根据权利要求1所述的构建方法,其特征在于,所述序列特征包括碱基类型、序列重复情况、at/gc富集情况、序列长度、总重复序列得分、at富集分、gc富集分以及最长重复子序列长度。
5.一种如权利要求1-4任一项所述的构建方法构建得到的预测模型在预测基因序列合成周期中的应用。
6.一种序列合成周期预测装置,其特征在于,包括:
7.根据权利要求6所述的预测装置,其特征在于,所述预测模型单元包括:linear子单元、embedding子单元、encoder子单元、dense子单元和represent子单元。
8.根据权利要求7所述的预测装置,其特征在于,所述embedding子单元包括两层结构,第一层使用pytorch中的embedding类,第二层将embedding的结果相加,然后使用pytorch中的nn.layernorm实现层归一化。
技术总结
本发明公开了一种序列合成周期预测模型的构建方法及其应用,所述方法包括选取若干已知不同长度、不同合成周期的基因序列,对所述已知序列进行序列特征提取,将提取的序列特征与所述已知序列作为数据库的训练数据,然后利用深度学习中的Embedding技术、Transformer模型和两个神经网络建立序列合成周期预测模型。本发明所述方法可以对不同复杂度的基因序列合成周期进行预测,操作简单,准确率高,有利于基因合成的统筹安排,提高合成效率。
技术研发人员:庞逍逸,蔡晓辉,申姝茵,杨平
受保护的技术使用者:苏州泓迅生物科技股份有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!