一种肝硬化标志物的模型构建方法与流程
本发明涉及医疗领域,尤其涉及一种肝硬化标志物的模型构建方法。
背景技术:
1、早期肝硬化病人通过病因治疗(如乙肝病毒治疗),生活习惯改善(如酒精性脂肪肝导致的早期肝硬化)等可以有效阻止肝硬化的恶性发展或逆转肝脏损伤以达到长期生存甚至治愈的效果。因此肝硬化的早发现早预防早治疗,防止疾病进展,避免临床失代偿性并发症的出现是肝硬化治疗的基本原则。但由于肝脏具有较强的代偿性,早期肝硬化往往并不表现出明显的临床症状,而到了症状较明显时,往往已到了肝硬化晚期。因此发现早期肝硬化的诊断标志物具有良好的临床意义及应用价值。
2、临床上用于确诊肝硬化的手段主要依靠超声影像并由肝穿刺进行确诊。超声诊断的灵敏度较低,而肝穿刺对患者的肝脏有损伤,存在风险,不易推广,导致很多患者直到肝硬化失代偿期才被确诊。最近有研究发现血清的ha、cg、pⅲnp、pcⅲ、cⅳ和ln等在肝硬化病人中升高,但由于其敏感度与特异性有待提高,目前尚未被临床采用作为早期肝硬化的指标;因此急需发现新的早期肝硬化标志物。
技术实现思路
1、针对上述技术中存在的不足之处,本发明提供一种肝硬化标志物的模型构建方法,通过进行全基因组测序,进行对比后获得标志物信息,然后进行相关的模型训练,得到最佳检测模型,在后续的处理过程中只需要将标志物片段分布信息输入到检测模型内即可快速判断受检者肝硬化情况。
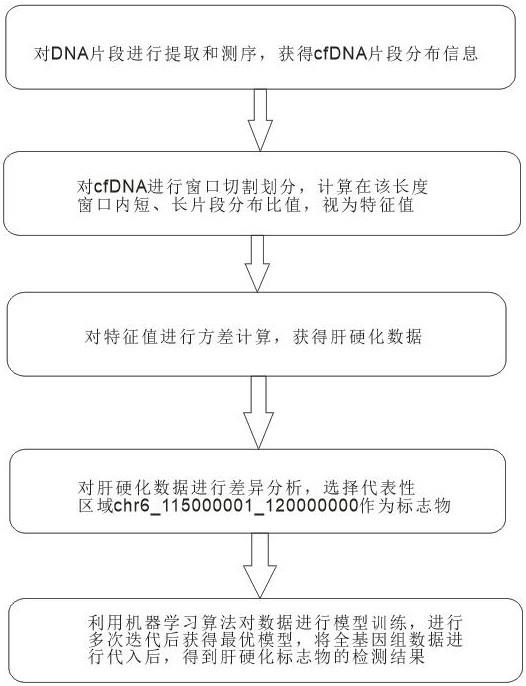
2、为实现上述目的,本发明公开了一种肝硬化标志物的模型构建方法,包括以下步骤:
3、s1:对dna片段进行提取和测序,获得cfdna片段分布信息;
4、s2:对cfdna进行长度窗口切割划分,计算在该长度窗口内短、长片段分布比值,视为特征值;
5、s3:对特征值进行方差计算,获得肝硬化数据;
6、s4:对肝硬化数据进行差异分析,选择代表性区域chr6_115000001_120000000作为标志物;
7、s5: 利用机器学习算法对数据进行模型训练,进行多次迭代后获得最优模型,将全基因组数据进行代入后,得到肝硬化标志物的检测结果。
8、作为优选,在步骤s1中,首先提取肝硬化人群血浆中游离dna,进行文库建立,并进行全基因组测序,得到原始的下机数据;将下机数据中的低质量、短序列、接头区域的数据去除,得到过滤后数据,获得cfdna片段分布信息。
9、作为优选,在步骤s2中,对人类参考基因组和cfdna进行5mbp长度窗口的切割划分,计算所有样品每个5mb窗口内短片段与长片段的分布比值,视为一个特征值。
10、作为优选,在步骤s3中,对正常人群的片段分布特征值进行方差计算,并且按照从小到大进行排序,以3/4位的值作为阈值,大于该阈值的肝硬化样品定义为肝硬化类似肿瘤,反之定义为肝硬化类似正常,获得相关的肝硬化数据。
11、作为优选,在步骤s4中,对相关的肝硬化数据进行计算差异倍数,最终选择差异大,有代表区域chr6_115000001_120000000作为标志物。
12、作为优选,在步骤s5中,提取肝硬化样品在染色体chr6_115000001_120000000区域片段分布信息,计算得到特征值,利用机械学习算法xgboots对数据进行模型训练和验证,计算模型灵敏度和特异性;通过多次迭代学习后,得到最优模型。
13、本发明的有益效果是:与现有技术相比,本发明提供的肝硬化标志物的模型构建方法,通过利用肝硬化患者和健康人员进行基因序列的测定,然后进行相同的窗口划分处理,通过对健康人员进行数据处理后得到用于划分肝硬化的阈值,然后将该阈值代入至肝硬化患者的数据处理过程中,从而筛选得到了标志物chr6_115000001_120000000;然后进行算法构建模型,进行多次迭代训练,从而获得最佳的肝硬化标志物模型,在后续的处理过程中只需将相关的标志物片段分布信息代入到该模型内,就能反馈出受检者肝硬化情况。
技术特征:
1.一种肝硬化标志物的模型构建方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的肝硬化标志物的模型构建方法,其特征在于,在步骤s1中,首先提取肝硬化人群血浆中游离dna,进行文库建立,并进行全基因组测序,得到原始的下机数据;将下机数据中的低质量、短序列、接头区域的数据去除,得到过滤后数据,获得cfdna片段分布信息。
3.根据权利要求1所述的肝硬化标志物的模型构建方法,其特征在于,在步骤s2中,对人类参考基因组和cfdna进行5mbp长度窗口的切割划分,计算所有样品每个5mb窗口内短片段与长片段的分布比值,视为一个特征值。
4.根据权利要求1所述的肝硬化标志物的模型构建方法,其特征在于,在步骤s3中,对正常人群的片段分布特征值进行方差计算,并且按照从小到大进行排序,以3/4位的值作为阈值,大于该阈值的肝硬化样品定义为肝硬化类似肿瘤,反之定义为肝硬化类似正常,获得相关的肝硬化数据。
5.根据权利要求1所述的肝硬化标志物的模型构建方法,其特征在于,在步骤s4中,对相关的肝硬化数据进行计算差异倍数,最终选择差异大,有代表区域chr6_115000001_120000000作为标志物。
6.根据权利要求1所述的肝硬化标志物的模型构建方法,其特征在于,在步骤s5中,提取肝硬化样品在染色体chr6_115000001_120000000区域片段分布信息,计算得到特征值,利用机器学习算法xgboots对数据进行模型训练和验证,计算模型灵敏度和特异性;通过多次迭代学习后,得到最优模型。
技术总结
本发明公开了一种肝硬化标志物的模型构建方法,通过利用肝硬化患者和健康人员进行基因序列的测定,然后进行相同的窗口划分处理,通过对健康人员进行数据处理后得到用于划分肝硬化的阈值,然后将该阈值代入至肝硬化患者的数据处理过程中,从而筛选得到了标志物chr6_115000001_120000000;然后进行算法构建模型,进行多次迭代训练,从而获得最佳的肝硬化标志物模型,在后续的处理过程中只需将相关的受检者chr6_115000001_120000000处片段分布信息代入到该模型内,就能反馈受检者的肝部信息,为专业医生提供信息支持。
技术研发人员:崔品,周小舟
受保护的技术使用者:深圳市睿法生物科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!