孤独症康复课程记录方法、装置、电子设备及存储介质与流程
本发明涉及人工智能技术,适用于医疗健康领域,尤其涉及一种基于多模态数据采集与分析的孤独症康复课程记录方法、装置、设备及介质。
背景技术:
1、孤独症康复课堂上,老师对患有孤独症的学生进行康复训练时,需手动记录学生的上课表现,如学生的回答正确与否、有无哭闹、有无安心听课等,并根据所述记录评估学生的整体状态。但实际上,尤其对于孤独症的学生,在不同的场景和交互条件下,是否表现兴趣、表现对人关注、表现与人互动的意愿、和情绪的稳定性等,对于评估孤独症学生的整体状态是相当重要的。对于孤独症学生一般不擅长表达情绪,人为评估记录存在主观、不准确等问题。
技术实现思路
1、本发明提供一种孤独症康复课程记录方法、装置、电子设备及存储介质,其主要目的在于提高孤独症康复课程记录的客观、准确性。
2、为实现上述目的,本发明提出一种孤独症康复课程记录方法,包括:
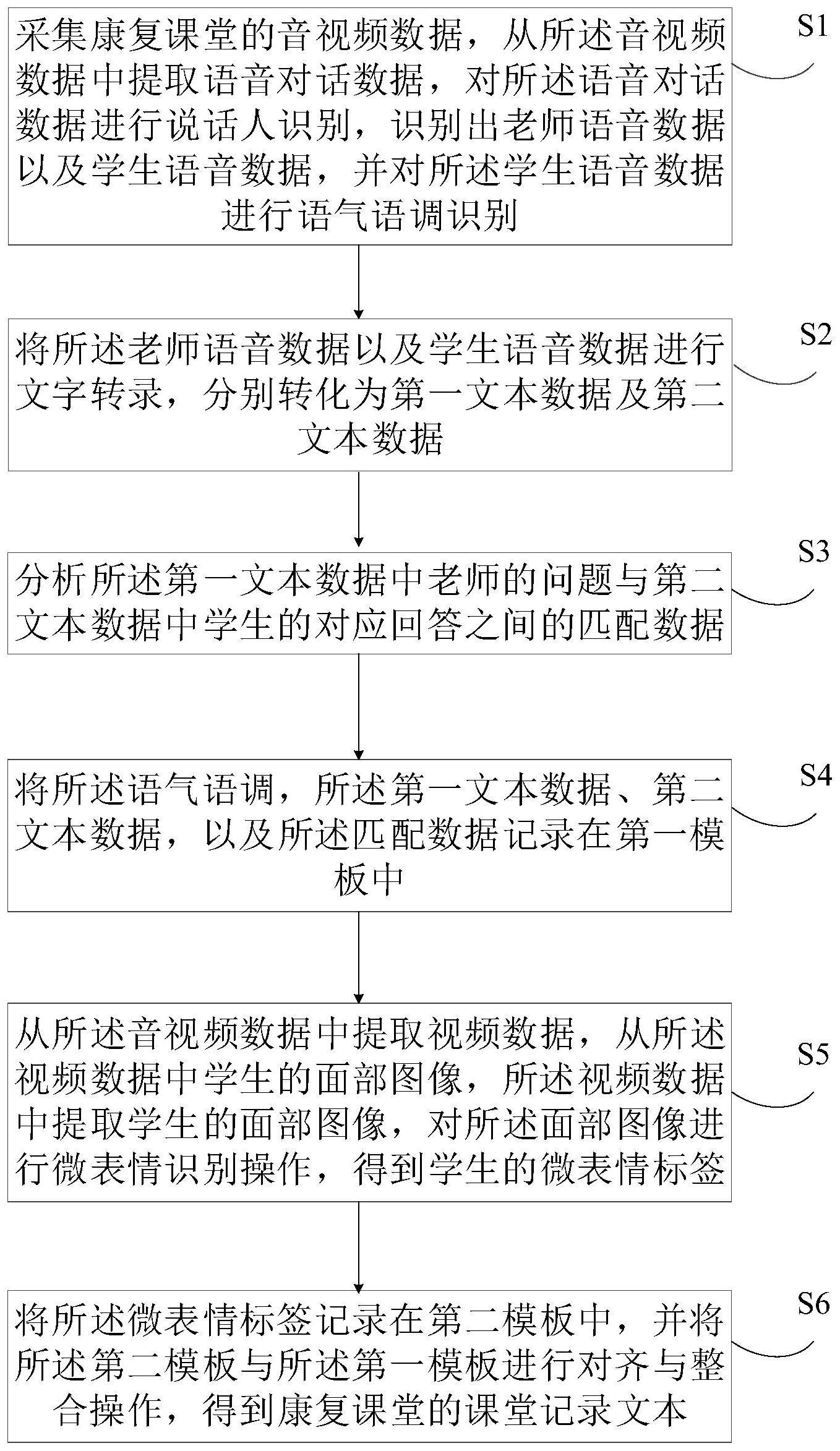
3、采集康复课堂的音视频数据,从所述音视频数据中提取语音对话数据,对所述语音对话数据进行说话人识别,识别出老师语音数据以及学生语音数据,并对所述学生语音数据进行语气语调识别;
4、将所述老师语音数据以及学生语音数据进行文字转录,分别转化为第一文本数据及第二文本数据;
5、分析所述第一文本数据中老师的问题与第二文本数据中学生的对应回答之间的匹配数据;
6、将所述语气语调,所述第一文本数据、第二文本数据,以及所述匹配数据记录在第一模板中;
7、从所述音视频数据中提取视频数据,从所述视频数据中提取学生的面部图像,对所述面部图像进行微表情识别操作,得到学生的微表情标签;
8、将所述微表情标签记录在第二模板中,并将所述第二模板与所述第一模板进行对齐与整合操作,得到康复课堂的课堂记录文本。
9、可选地,所述对所述语音对话数据进行说话人识别,识别出老师语音数据以及学生语音数据,包括:
10、通过声纹识别技术,采集所述语音对话数据中的声音信号特征,所述声音信号特征包括频率、幅度、声调、语速、语音节奏特征;
11、根据所述声音信号特征进行语音聚类;
12、根据所述语音聚类,利用预先训练的分类器,从所述音视频数据中识别出老师语音数据以及学生语音数据。
13、可选地,所述对所述学生语音数据进行语气语调识别,包括:
14、提取所述学生语音数据的频率、能量、时域特征;
15、通过预构建的分类器,利用所述频率、能量、时域特征,判断所述学生语音数据的语气语调。
16、可选地,所述分析所述第一文本数据中老师的问题与第二文本数据中学生的对应回答之间的匹配数据,包括:
17、从所述第一文本数据中提取出问题文本,及从所述第二文本数据中提取出回答文本,按照时间戳将所述问题文本及回答文本组成多个问答文本对;
18、选择其中一个问答文本对,对选择的所述问答文本对中的问题文本以及回答文本进行分词,并将分词后的问题文本拼接成问题序列以及将对应的分词后的回答文本拼接成回答序列;
19、将所述问题序列及回答序列分别输入预先训练的bert模型,获取bert模型最后一层输出的隐藏状态,得到问题序列的隐藏状态及回答序列的隐藏状态;
20、将所述问题序列的隐藏状态及回答序列的隐藏状态进行余弦相似度计算,得到相似度计算结果;
21、判断是否存在没有选择的问答文本对?
22、若存在没有选择的问答文本对,则返回上述的选择其中一个问答文本对的步骤;
23、若不存在没有选择的问答文本对,则根据所述相似度计算结果,生成所述第一文本数据及第二文本数据之间问答的匹配数据。
24、可选地,所述根据所述相似度计算结果,生成所述第一文本数据及第二文本数据之间问答的匹配数据,包括:
25、当所述相似度计算结果大于或等于预设的阈值,判断所述问答文本对中的问题文本以及回答文本相匹配;
26、当所述相似度计算结果小于预设的阈值,则判断所述问答文本对中的问题文本以及回答文本不匹配;
27、汇总所有问答文本对的匹配结果,得到所述第一文本数据及第二文本数据之间问答的匹配数据。
28、可选地,所述对所述面部图像进行微表情识别操作,包括:
29、从所述面部图像中提取关键帧,并从所述关键帧中检测出人脸区域;
30、将人脸区域输入se_resnet网络进行端到端的微表情识别,输出学生的微表情标签。
31、可选地,所述第一模板中包括时间戳、问题标号和答案匹配与否、回答问题时的语气语调的数据项,以及所述第二模板中包括学生的微表情标签、时间戳的数据项,所述将所述第二模板与所述第一模板进行对齐与整合操作,得到康复课堂的课堂记录文本,包括:
32、按照时间戳将所述第二模板中学生的微表情标签与所述第一模板中学生的回答匹配与否的数据进行对齐与整合,得到康复课堂的课堂记录文本。
33、为了解决上述问题,本发明还提供一种孤独症康复课程记录装置,所述装置包括:
34、语气语调识别模块,用于采集康复课堂的音视频数据,从所述音视频数据中提取语音对话数据,对所述语音对话数据进行说话人识别,识别出老师语音数据以及学生语音数据,并对所述学生语音数据进行语气语调识别;
35、问题匹配分析模块,用于将所述老师语音数据以及学生语音数据进行文字转录,分别转化为第一文本数据及第二文本数据,分析所述第一文本数据中老师的问题与第二文本数据中学生的对应回答之间的匹配数据;
36、记录模块,用于将所述语气语调,所述第一文本数据、第二文本数据,以及所述匹配数据记录在第一模板中;
37、微表情识别模块,用于从所述音视频数据中提取视频数据,从所述视频数据中提取学生的面部图像,对所述面部图像进行微表情识别操作,得到学生的微表情标签;
38、所述记录模块,还用于将所述微表情标签记录在第二模板中,并将所述第二模板与所述第一模板进行对齐与整合操作,得到康复课堂的课堂记录文本。
39、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
40、存储器,存储至少一个计算机程序;及
41、处理器,执行所述存储器中存储的计算机程序以实现上述所述的孤独症康复课程记录方法。
42、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的孤独症康复课程记录方法。
43、本发明实施例提出的孤独症康复课程记录方法,使用多模态数据采集与分析技术,实时得到学生的情绪和语气等变化,减少老师在进行课程记录时的主观性和信息遗漏问题,提供更客观、更准确的记录和评估结果。因此,本发明实施例提高了孤独症康复课程记录的客观、准确性。
技术特征:
1.一种孤独症康复课程记录方法,其特征在于,所述方法包括:
2.如权利要求1所述的独症康复课程记录方法,其特征在于,所述对所述语音对话数据进行说话人识别,识别出老师语音数据以及学生语音数据,包括:
3.如权利要求1所述的孤独症康复课程记录方法,其特征在于,所述对所述学生语音数据进行语气语调识别,包括:
4.如权利要求1所述的孤独症康复课程记录方法,其特征在于,所述分析所述第一文本数据中老师的问题与第二文本数据中学生的对应回答之间的匹配数据,包括:
5.如权利要求4所述的孤独症康复课程记录方法,其特征在于,所述根据所述相似度计算结果,生成所述第一文本数据及第二文本数据之间问答的匹配数据,包括:
6.如权利要求1所述的孤独症康复课程记录方法,其特征在于,所述对所述面部图像进行微表情识别操作,包括:
7.如权利要求1所述的孤独症康复课程记录方法,其特征在于,所述第一模板中包括时间戳、问题标号和答案匹配与否、回答问题时的语气语调的数据项,以及所述第二模板中包括学生的微表情标签、时间戳的数据项,所述将所述第二模板与所述第一模板进行对齐与整合操作,得到康复课堂的课堂记录文本,包括:
8.一种孤独症康复课程记录装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括:
10.一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述的孤独症康复课程记录方法。
技术总结
本发明涉及人工智能技术,揭露一种孤独症康复课程记录方法、装置、设备以及介质。所述方法包括:从康复课堂的音视频数据中识别出老师语音数据以及学生语音数据,对学生语音数据进行语气语调识别;将老师语音数据以及学生语音数据分别转化为第一文本数据及第二文本数据;分析第一文本数据中老师的问题与第二文本数据中学生的对应回答之间的匹配数据;从所述音视频数据中提取学生的面部图像,对所述面部图像进行微表情识别操作,得到学生的微表情标签;根据所述语气语调,第一文本数据、第二文本数据,匹配数据以及微表情标签,得到康复课堂的课堂记录文本。本发明可以提高孤独症康复课程记录的客观性、准确性。
技术研发人员:郭阳鸣,姚佑达
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!