一种基于DNA条形码技术的基因组原生动物污染物检测方法
本发明属于基因组污染序列的鉴定及污染物种分析查找领域,具体涉及一种基于dna条形码技术的基因组原生动物污染物检测方法。
背景技术:
1、原生动物是一组高度多样化的真核生物,在几乎所有生态系统中都起着关键作用。许多原生动物是可引起动物或植物疾病的致病性寄生虫,对原生动物是否对基因组进行污染检测有利于针对原生动物采取措施,保障环境安全及动植物健康安全。
2、dnabarcode序列是一条某个物种所特有且稳定遗传的dna序列,位于物种特定基因组区域,通常长度为几百个碱基,可用于识别和区分不同的生物物种,对物种继续快速准确的鉴定。目前,dnabarcode技术已广泛用于生物多样性研究、环境监测、食品安全检测、医学诊断等领域。
3、现有检测基因组中的原生动物污染是基于不同技术方法,包括基于k-mers的比对、微生物分类法及机器学习等方法,但此类方法都是对未经过组装的高通量测序reads进行污染检测,并不针对一致性contigs序列。
4、依据k-mers精确比对等方法针对大量数据突出了时间长,需要大量计算资源及假阳性高等缺点,不利于原生动物污染物的检测。由此,亟需一种能快速、准确检测基因组中存在的原生动物污染的方法。
技术实现思路
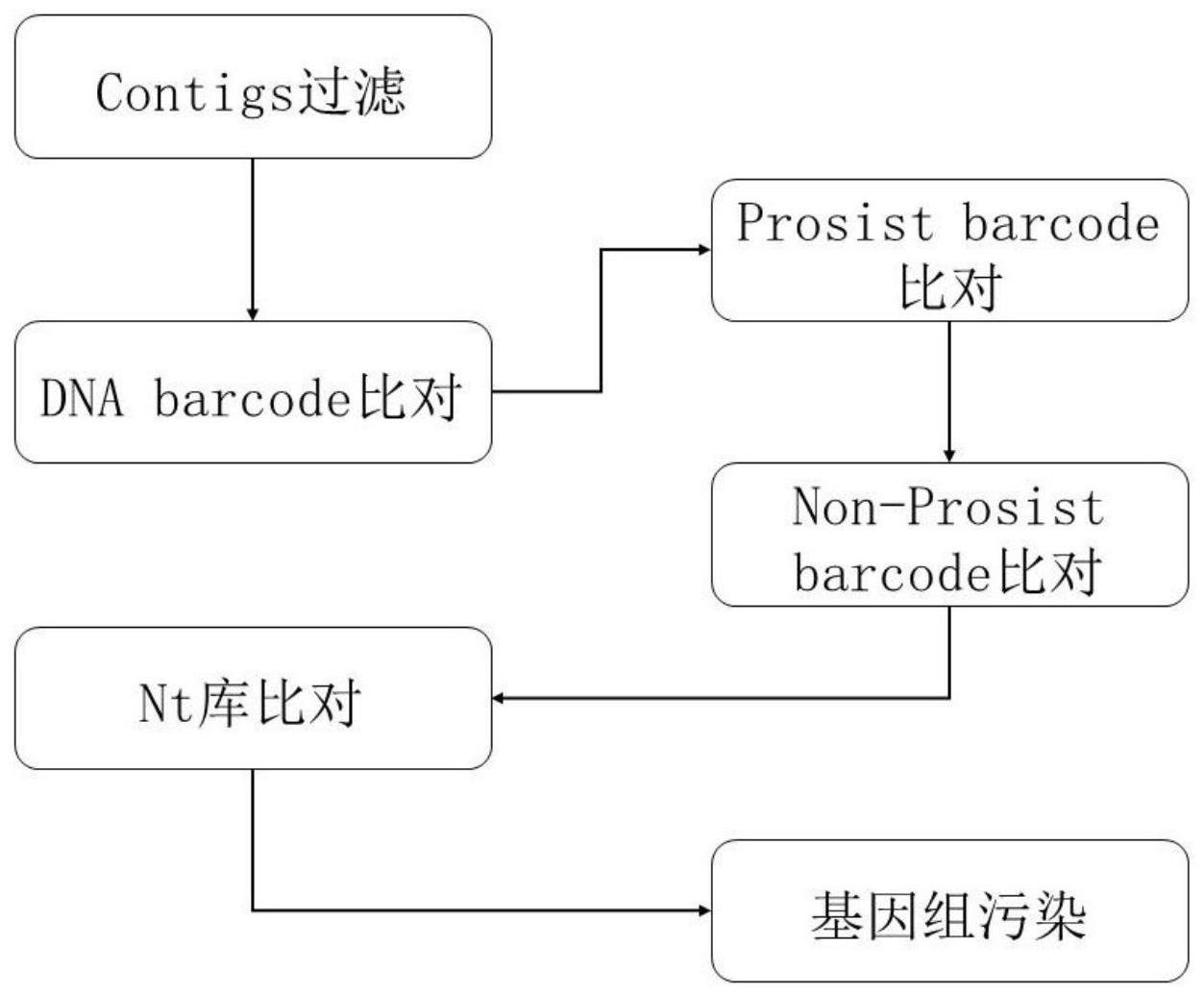
1、为解决以上现有技术存在的问题,本发明提出了一种基于dna条形码技术的基因组原生动物污染物检测方法,该方法包括:
2、s1:获取待检测的dna序列数据,对待检测的dna序列数据进行过滤,得到第一dna序列数据;
3、s2:将第一dna序列数据与原生生物dna序列进行对比,筛选出与原生生物dna序列相对应的序列以及该序列的比对分值,将筛选出的序列作为第二dna序列数据;
4、s3:将第二dna序列数据与非原生生物dna序列数据进行对比,筛选出与非原生生物dna序列数据未对比上的dna序列数据或比对分值小于s2中对应分值的序列得到第三dna序列数据;
5、s4:将第三dna序列与genbank数据库子库nt数据库进行序列比对,选出最优比对结果,对最高分值的比对上的序列进行判断,如果是原生生物,则为基因组数据存在的原生生物污染序列数据。
6、优选的,对待检测的dna序列数据进行过滤包括:确定dna序列数据的长度,将contigs的长度大于100000bp的dna序列数据进行过滤,保留contigs小于100000bp的数据。
7、优选的,将第一dna序列数据与原生生物dna序列进行对比包括:
8、步骤1:获取原生生物dna barcode序列数据,根据原生生物dnabarcode序列数据构建第一数据库;
9、步骤2:将第一dna序列数据进行长度过滤,将长度小于100000bp的dna与数据库中的序列进行比对,得到初始匹配结果;
10、步骤3:对初始匹配结果的dna短片段进行扩展;
11、步骤4:重复步骤2~步骤3,直到所有的dna片段比对完成;
12、步骤5:设置比对阈值evalue,计算所有比对后的dna片段的相似性得分,将相似性得分与设置的比对阈值evalue进行对比,将小于比对阈值evalue的序列删除,并根据相似性得分进行排序,得到第二dna序列。
13、进一步的,对原生生物dnabarcode序列数据构建数据库包括:采用哈希表的索引算法将原生生物dnabarcode序列数据中的dna序列进行拆分,得到dna片段;将dna片段作为键值存储在哈希表,得到第一数据库。
14、进一步的,设置的比对阈值evalue为1e-5。
15、进一步的,相似性得分计算公式为:
16、m0,0=0
17、
18、score=∑mi,j-co-dg
19、其中,m0,0为初始碱基对得分;mi,j为第i,j位碱基的比对得分;mi,j-1为与当前位置碱基水平方向相邻的碱基比对得分;mi-1,j为与当前位置碱基垂直方向相邻的碱基比对得分;ds(i),t(i)为表示序列s的第i个碱基与序列t的第j个碱基的比对分值;ds(i),0表示序列s的第i个碱基与空位的比对分值;d0,t(j)表示空位与序列t的第j个碱基的比对分值;c表示gaps的数量;o表示空位罚分;d表示延伸gaps的长度;g表示延伸gaps的空位罚分。
20、优选的,将第二dna序列数据与非原生生物dna序列数据进行对比包括:获取非原生生物dnabarcode序列数据,根据非原生生物dnabarcode序列数据构建第二数据库;将第二dna序列数据与第二数据库中的非原生生物dna序列数据比对,通过将大于比对阈值evalue的dna片段过滤,并去除第一dna序列中比对上非原生生物dna序列的数据,且比对分值大于第一dna序列比对分值的数据,得到第三dna序列。
21、优选的,将第三dna序列与genbank数据库子库nt数据库进行序列比对包括:将第三dna序列数据与nt库进行序列序列比对,通过将小于比对阈值evalue的dna序列进行删除,得到初始对比序列;计算所有初始对比序列的bitsocre分数值,根据bitsocre分数值比对上的数据据库序列的信息确定污染物种,得到最终结果。
22、进一步的,bitsocre分数值的计算公式为:
23、
24、其中,score表示为相似性得分;λ与k均表示为karlin-alts-chul统计量。
25、本发明的有益效果:
26、本发明通过三种基因组污染筛选策略对dna序列数据进行筛选,从而降低污染识别假阳性,提高检测的准确性;本发明基于dnabarcode方法检测污染物,dnabarcode序列是一条某个物种所特有且稳定遗传的dna序列,本发明通过识别鉴定基因组种存在的dnabarcode序列,确定是否含有污染及其污染物种,降低运算时间及资源消耗;本发明通过三种筛选策略,显著减少非污染序列数据量,保留污染序列,显著降低运算时间及资源消耗。
技术特征:
1.一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,包括:
2.根据权利要求1所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,对待检测的dna序列数据进行过滤包括:确定dna序列数据的长度,将contigs的长度大于100000bp的dna序列数据进行过滤,保留contigs小于100000bp的数据。
3.根据权利要求1所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,将第一dna序列数据与原生生物dna barcode序列进行对比包括:
4.根据权利要求3所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,对原生生物dnabarcode序列数据构建数据库包括:采用哈希表的索引算法将原生生物dnabarcode序列数据中的dna序列进行拆分,得到dna片段;将dna片段作为键值存储在哈希表,得到第一数据库。
5.根据权利要求3所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,设置的比对阈值evalue为1e-5。
6.根据权利要求3所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,相似性得分计算公式为:
7.根据权利要求1所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,将第二dna序列数据与非原生生物dna序列数据进行对比包括:获取非原生生物dnabarcode序列数据,根据非原生生物dnabarcode序列数据构建第二数据库;将第二dna序列数据与第二数据库中的非原生生物dna序列数据比对,通过将大于比对阈值evalue的dna片段过滤,并去除第一dna序列中比对上非原生生物dna序列,且比对分值大于第一dna序列比对分值的数据,得到第三dna序列。
8.根据权利要求1所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,将第三dna序列与genbank数据库子库nt数据库进行序列比对包括:将第三dna序列数据与nt库进行序列序列比对,通过将小于比对阈值evalue的dna序列进行删除,得到初始对比序列;计算所有初始对比序列的bitsocre分数值,根据bitscore分数值比对上的数据据库序列的信息确定污染物种,得到最终结果。
9.根据权利要求8所述的一种基于dna条形码技术的基因组原生动物污染物检测方法,其特征在于,bitsocre分数值的计算公式为:
技术总结
本发明属于基因组污染序列的鉴定及污染物种分析查找领域,具体涉及一种基于DNA条形码技术的基因组原生动物污染物检测方法,包括:获取待检测的DNA序列数据;采用三种基因组污染筛选策略对DNA序列数据进行筛选,将筛选出的DNA序列数据与Genbank数据库子库nt数据库进行序列比对,选出最优比对结果;其中三种基因组污染筛选策略分别为contigs长度筛选、与原生生物DNA序列进行对比以及与非原生生物DNA序列数据;本发明通过三种基因组污染筛选策略对DNA序列数据进行筛选,从而降低污染识别假阳性,提高检测的准确性。
技术研发人员:谢家政,张毅
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!