一种提升生物炭制备工艺及性能预测效果的系统
本发明属于生物炭预测,具体涉及一种提升生物炭制备工艺及性能预测效果的系统。
背景技术:
1、生物炭是一种由生物质经过热解制得的炭材料,具有高度多孔性、高比表面积、高吸附性能等优点,在环保、能源、农业等多个领域具有广泛的应用前景,其中具体包括水体污染治、土壤改良、温室气体减排等方面。近年来,随着生物炭研究的深入,其制备工艺和性能得到了不断优化和提升。然而,生物炭的制备和应用仍存在一些技术瓶颈,如制备过程中的热解条件的控制、生物炭的表面改性等,这些问题的解决对于提升生物炭的性能和扩大其应用领域具有重要意义。
2、随着生物炭研究的深入,机器学习技术在生物炭领域的应用也日益广泛。生物炭的制备工艺和性能优化涉及到大量的数据和复杂的工艺过程,传统的方法往往难以准确预测和控制。而机器学习技术可以实现对大量数据的分析和学习,建立预测模型,实现对生物炭结构和性能的精确预测和控制。然而,如何建立更为准确的模型是亟需解决的问题。这需要我们不断探索和研究更为先进的机器学习算法和技术,以适应生物炭领域的复杂性和不确定性。
3、目前现有技术存在以下问题:
4、(1)现有生物炭领域所建立的相关模型都是基于有标签数据建模,忽略了大量无标签数据,以至于模型的泛化性能较低很难投入到实际应用中;
5、(2)现有模型的预测精度有待提升,同时模型的稳定性也有待提高;
6、(3)现有增强模型泛化性的方法,由于未考虑数据种类分布,导致预测模型存在偏向性。
技术实现思路
1、解决的技术问题:针对上述技术问题,本发明提供了一种提升生物炭制备工艺及性能预测效果的系统,具有预测精度高、应用范围广的特点。
2、技术方案:一种提升生物炭制备工艺及性能预测效果的系统,包括:
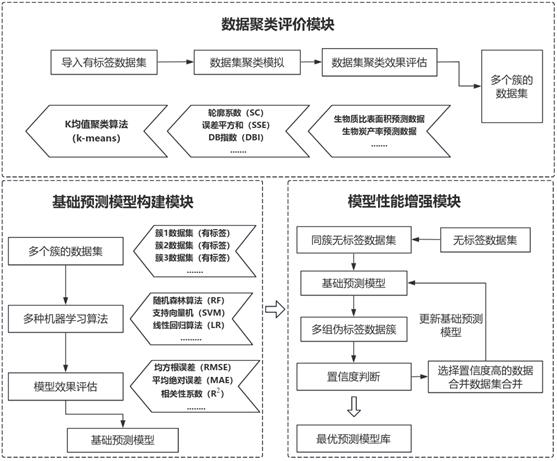
3、数据聚类评价模块,用于:导入有标签生物炭性能预测数据集,对有标签生物炭性能预测数据集使用聚类算法进行聚类处理,使用聚类算法评价指标,评估在多个簇下的不同模型的聚类效果,得到多个簇下的有标签数据集;
4、基础预测模型构建模块,用于:对多个簇下的有标签数据集使用多种机器学习回归算法建立预测模型,对预测模型进行性能评价筛选出基础预测模型;
5、模型性能增强模块,用于:导入无标签数据集,判断无标签数据集所属的簇类别,得到同簇无标签数据集,将同簇无标签数据集分批次代入基础预测模型,得到伪标签数据集,对伪标签数据集进行置信度判断,并选择置信度高的伪标签数据更新基础预测模型,循环前述过程直至所有无标签数据集全部筛选完成,得到最优预测模型库。
6、优选的,对有标签生物炭性能预测数据集使用聚类算法进行聚类处理中,所述聚类算法采用k-means算法,公式如下:
7、
8、其中xi为第i个样本,ci是xi是所属的簇,代表簇对应的中心,n为样本总数。
9、优选的,所述聚类算法评价指标包括:轮廓系数、误差平方和和db指数。
10、优选的,所述多种机器学习回归算法包括:随机森林算法、支持向量机和线性回归算法。
11、优选的,对预测模型进行性能评价筛选出基础预测模型中,性能评价包括:r2、rmse和mae,筛选方式为:选择性能评价效果最优的预测模型作为基础预测模型。
12、优选的,判断无标签数据集所属的簇类别中,判断公式为:k(c)=argminjdist(xnew,cj),其中,xnew是无标签数据点,dist(·)使用的是欧氏距离,argminj表示找到使得距离最小的簇中心的索引j。
13、优选的,所述置信度判断的公式如下:
14、
15、其中yi为数据真实值,h(xi)和h'(xi)分别为初始回归模型和更新了伪标签后的回归模型,δxu为置信度因子,当δxu大于零时则属于高置信度标签,用于更新基础预测模型。
16、优选的,所述最优预测模型库由多个簇下的数据共同构建而成,最优预测模型个数与簇个数相同。
17、有益效果:本发明可以提高生物炭材料领域机器学习模型的预测效果;本发明通过引入统计学聚类思想,能够有效解决无标签数据过少、数据分布不均匀导致的模型泛化性低的问题,适用范围更广。
技术特征:
1.一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,包括:
2.根据权利要求1所述的一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,对有标签生物炭性能预测数据集使用聚类算法进行聚类处理中,所述聚类算法采用k-means算法,公式如下:
3.根据权利要求1所述的一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,所述聚类算法评价指标包括:轮廓系数、误差平方和和db指数。
4.根据权利要求1所述的一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,所述多种机器学习回归算法包括:随机森林算法、支持向量机和线性回归算法。
5.根据权利要求1所述的一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,对预测模型进行性能评价筛选出基础预测模型中,性能评价包括:r2、rmse和mae,筛选方式为:选择性能评价效果最优的预测模型作为基础预测模型。
6.根据权利要求1所述的一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,判断无标签数据集所属的簇类别中,判断公式为:k(c)=argminjdist(xnew,cj),其中,xnew是无标签数据点,dist(·)使用的是欧氏距离,argminj表示找到使得距离最小的簇中心的索引j。
7.根据权利要求1所述的一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,所述置信度判断的公式如下:
8.根据权利要求1所述的一种提升生物炭制备工艺及性能预测效果的系统,其特征在于,所述最优预测模型库由多个簇下的数据共同构建而成,最优预测模型个数与簇个数相同。
技术总结
本发明公开了一种提升生物炭制备工艺及性能预测效果的系统,包括:数据聚类评价模块,用于得到多个簇下的有标签数据集;基础预测模型构建模块,用于筛选出基础预测模型;模型性能增强模块,用于导入无标签数据集,判断无标签数据集所属的簇类别,得到同簇无标签数据集,将同簇无标签数据集分批次代入基础预测模型,得到伪标签数据集,对伪标签数据集进行置信度判断,并选择置信度高的伪标签数据更新基础预测模型,循环前述过程直至所有无标签数据集全部筛选完成,得到最优预测模型库。本发明提高了生物炭领域基础预测模型的预测精度,解决了由于未考虑数据种类分布导致预测模型存在偏向性的问题。
技术研发人员:唐登勇,丁旭,唐文轩,曹骏杰,余承章,程世杰
受保护的技术使用者:南京信息工程大学
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!