语音识别算法及芯片的制作方法
本发明涉及芯片技术领域,尤其涉及语音识别算法及芯片。
背景技术:
集成电路英语:integratedcircuit,缩写作ic;或称微电路(microcircuit)、微芯片(microchip)、晶片/芯片(chip)在电子学中是把电路(主要包括半导体设备,也包括被动组件等)小型化的方式,并时常制造在半导体晶圆表面上。
现有的芯片的算法流程复杂且流畅性差,芯片在使用的时候,不能在识别不清晰的情况下,再次对语音流进行识别,导致识别的结果与真正的意思存在偏差或歧义。为此,我们提出语音识别算法及芯片。
技术实现要素:
本发明提供语音识别算法及芯片,旨在解决现有的语音识别算法及芯片算法流程复杂且流畅性差、识别的结果与真正的意思存在偏差或歧义的问题。
本发明提供的具体技术方案如下:
本发明提供的语音识别算法及芯片,包括如下步骤:
s1、mic输入的语音先通过录音模块进行录音;
s2、通过录音模块播放录音,并进行频谱分析;
s3、频谱分析工作完成之后,对语音进行提取特征;
s4、把提取的语音特征和关键词语列表中的关键词语进行对比匹配;
s5、找出得分最高的关键词语作为识别结果输出;
s6、识别的结果如果清晰,即可传送至mcu作进一步处理,反之,如果识别的结果不清晰,则通过录音模块播放最初录制的语音进行识别。
可选的,语音识别芯片能在两种情况下给出识别结果:
1)、外部送入预定时间的语音数据后(比如8秒钟的语音数据),芯片对这些语音数据运算分析后,给出识别结果;
2)、外部送入语音数据流,语音识别芯片通过端点检测vad检测出用户停止说话,把用户开始说话到停止说话之间的语音数据进行运算分析后,给出识别结果。
可选的,对于1),可以理解为设定了一个定时录音(比如为8秒钟),芯片在8秒钟后,会停止把声音送入识别引擎,并且根据已送入引擎的语音数据计算出一个识别结果。
可选的,对于2),需要使用到vad,vad技术是在一段语音数据流中,判断出哪个时间点是人声的开始,哪个时间点是人声的结束。
可选的,判断的依据是,在背景声音的基础上有了语音发音,则视为声音的开始,而后,检测到一段持续时间的背景音(比如480毫秒),则视为人声说话结束。
本发明的有益效果如下:
1、本发明方法成熟,通过对芯片的算法进行删减、整合及创新,有效的精简了算法的流程,步骤简单明了,提高了算法的流畅性,节约时间,提高计算效率,添加了录音模块,可以在识别结果不清晰的情况下,反复对语音流播放和识别,大大提高了识别的结果与真正的意思吻合度,提高识别的准确,使用效果好。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
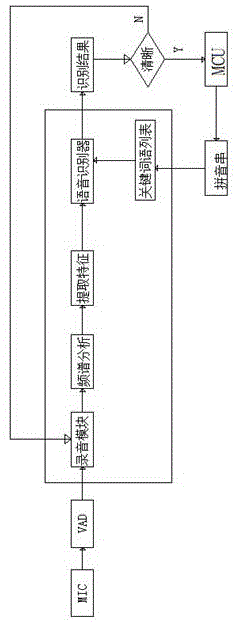
图1为本发明实施例的语音识别算法及芯片的整体结构示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
下面将结合图1对本发明实施例的语音识别算法及芯片进行详细的说明。
参考图1所示,本发明实施例提供的语音识别算法及芯片,包括如下步骤:
s1、mic输入的语音先通过录音模块进行录音;
s2、通过录音模块播放录音,并进行频谱分析;
s3、频谱分析工作完成之后,对语音进行提取特征;
s4、把提取的语音特征和关键词语列表中的关键词语进行对比匹配;
s5、找出得分最高的关键词语作为识别结果输出;
s6、识别的结果如果清晰,即可传送至mcu作进一步处理,反之,如果识别的结果不清晰,则通过录音模块播放最初录制的语音进行识别。
参照图1所示,语音识别芯片能在两种情况下给出识别结果:
1)、外部送入预定时间的语音数据后(比如8秒钟的语音数据),芯片对这些语音数据运算分析后,给出识别结果;
2)、外部送入语音数据流,语音识别芯片通过端点检测vad检测出用户停止说话,把用户开始说话到停止说话之间的语音数据进行运算分析后,给出识别结果。
参照图1所示,对于1),可以理解为设定了一个定时录音(比如为8秒钟),芯片在8秒钟后,会停止把声音送入识别引擎,并且根据已送入引擎的语音数据计算出一个识别结果。
参照图1所示,对于2),需要使用到vad,vad技术是在一段语音数据流中,判断出哪个时间点是人声的开始,哪个时间点是人声的结束。
参照图1所示,判断的依据是,在背景声音的基础上有了语音发音,则视为声音的开始,而后,检测到一段持续时间的背景音(比如480毫秒),则视为人声说话结束。
综上所述:本发明实施例提供语音识别算法及芯片,方法成熟,通过对芯片的算法进行删减、整合及创新,有效的精简了算法的流程,步骤简单明了,提高了算法的流畅性,节约时间,提高计算效率,添加了录音模块,可以在识别结果不清晰的情况下,反复对语音流播放和识别,大大提高了识别的结果与真正的意思吻合度,提高识别的准确,使用效果好。
需要说明的是,本发明为语音识别算法及芯片,部件均为通用标准件或本领域技术人员知晓的部件,其结构和原理都为本技术人员均可通过技术手册得知或通过常规实验方法获知。
显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
技术特征:
1.语音识别算法及芯片,其特征在于,包括如下步骤:
s1、mic输入的语音先通过录音模块进行录音;
s2、通过录音模块播放录音,并进行频谱分析;
s3、频谱分析工作完成之后,对语音进行提取特征;
s4、把提取的语音特征和关键词语列表中的关键词语进行对比匹配;
s5、找出得分最高的关键词语作为识别结果输出;
s6、识别的结果如果清晰,即可传送至mcu作进一步处理,反之,如果识别的结果不清晰,则通过录音模块播放最初录制的语音进行识别。
2.根据权利要求1所述的语音识别算法及芯片,其特征在于,语音识别芯片能在两种情况下给出识别结果:
1)、外部送入预定时间的语音数据后(比如8秒钟的语音数据),芯片对这些语音数据运算分析后,给出识别结果;
2)、外部送入语音数据流,语音识别芯片通过端点检测vad检测出用户停止说话,把用户开始说话到停止说话之间的语音数据进行运算分析后,给出识别结果。
3.根据权利要求2所述的语音识别算法及芯片,其特征在于,对于1),可以理解为设定了一个定时录音(比如为8秒钟),芯片在8秒钟后,会停止把声音送入识别引擎,并且根据已送入引擎的语音数据计算出一个识别结果。
4.根据权利要求2所述的语音识别算法及芯片,其特征在于,对于2),需要使用到vad,vad技术是在一段语音数据流中,判断出哪个时间点是人声的开始,哪个时间点是人声的结束。
5.根据权利要求4所述的语音识别算法及芯片,其特征在于,判断的依据是,在背景声音的基础上有了语音发音,则视为声音的开始,而后,检测到一段持续时间的背景音(比如480毫秒),则视为人声说话结束。
技术总结
本发明公开了语音识别算法及芯片,属于芯片技术领域,包括如下步骤:S1、MIC输入的语音先通过录音模块进行录音;S2、通过录音模块播放录音,并进行频谱分析;S3、频谱分析工作完成之后,对语音进行提取特征;S4、把提取的语音特征和关键词语列表中的关键词语进行对比匹配;S5、找出得分最高的关键词语作为识别结果输出。本发明方法成熟,通过对芯片的算法进行删减、整合及创新,有效的精简了算法的流程,步骤简单明了,提高了算法的流畅性,节约时间,提高计算效率,添加了录音模块,可以在识别结果不清晰的情况下,反复对语音流播放和识别,大大提高了识别的结果与真正的意思吻合度,提高识别的准确,使用效果好。
技术研发人员:蔡颖昭;凯利·麦克·西蒙;任希庆
受保护的技术使用者:安普德(天津)科技股份有限公司
技术研发日:2019.11.28
技术公布日:2020.04.28
- 还没有人留言评论。精彩留言会获得点赞!