上下文感知的基于硬件的语音活动检测的制作方法
上下文感知的基于硬件的语音活动检测
1.相关申请的交叉引用
2.本技术要求于2020年5月29日提交的美国临时专利申请no.16/888,522的利益和优先权,其全部内容通过援引纳入于此。
3.引言
4.本公开的各方面涉及功率高效语音活动检测,尤其涉及用于执行上下文感知的基于硬件的语音活动检测的系统和方法。
5.语音活动检测一般是由电子设备实现以激活设备或设备的一些功能的功能。例如,它可允许人向电子设备(诸如智能扬声器、移动设备、可穿戴设备等)给予命令,而不直接与该设备物理地交互。语音活动检测常常被实现为电子设备中的“常开”功能以使其效用最大化。不幸的是,常开功能需要常开软件和/或硬件资源,这进而导致常开功率使用。移动电子设备、物联网(iot)设备等对此类常开功率要求特别敏感,因为它们缩短了电池寿命并且消耗了系统的其他有限资源,诸如处理能力。
6.常规地,由于常规实现的性能限制,语音活动检测已经被实现为高准确度、高功率功能、或低准确度、低功率功能。例如,由于对移动应用的严格功率、性能和面积考虑,语音活动检测在移动设备中常常被实现为低准确度、低功率功能。不幸的是,此类低准确度实现常常让用户受挫,并且想要更好的设备性能。
7.相应地,需要的是用以执行高准确度、低功率语音活动检测的系统和方法。
8.简要概述
9.某些实施例提供了一种用于执行语音活动检测的方法,该方法包括:从电子设备的音频源接收音频数据;使用基于硬件的特征生成器基于所接收的音频数据来生成多个模型输入特征;向基于硬件的语音活动检测模型提供该多个模型输入特征;从该基于硬件的语音活动检测模型接收输出值;以及基于该输出值来确定该音频数据中的语音活动的存在。
10.附加实施例提供了一种被配置成用于执行语音活动检测的处理系统,该处理系统包括:存储器,该存储器包括计算机可执行指令;一个或多个处理器,该一个或多个处理器被配置成执行这些计算机可执行指令并使该处理系统:从音频源接收音频数据;使用基于硬件的特征生成器基于所接收的音频数据来生成多个模型输入特征;向基于硬件的语音活动检测模型提供该多个模型输入特征;从该基于硬件的语音活动检测模型接收输出值;以及基于该输出值来确定该音频数据中的语音活动的存在。
11.附加实施例提供了一种包括计算机可执行指令的非瞬态计算机可读介质,这些计算机可执行指令在由处理系统的一个或多个处理器执行时使该处理系统执行用于执行语音活动检测的方法,该方法包括:从电子设备的音频源接收音频数据;使用基于硬件的特征生成器基于所接收的音频数据来生成多个模型输入特征;向基于硬件的语音活动检测模型提供该多个模型输入特征;从该基于硬件的语音活动检测模型接收输出值;以及基于该输出值来确定该音频数据中的语音活动的存在。
12.附加实施例提供了一种处理设备,该处理设备包括:用于从电子设备的音频源接
收音频数据的装置;用于使用基于硬件的特征生成器基于所接收的音频数据来生成多个模型输入特征的装置;用于向基于硬件的语音活动检测模型提供该多个模型输入特征的装置;用于从该基于硬件的语音活动检测模型接收输出值的装置;以及用于基于该输出值来确定该音频数据中的语音活动的存在的装置。
13.以下描述和相关附图详细阐述了一个或多个实施例的某些解说性特征。
14.附图简述
15.附图描绘了该一个或多个实施例的某些方面,并且因此不被认为限制本公开的范围。
16.图1描述了上下文感知的基于硬件的示例语音活动检测系统。
17.图2描绘了特征生成器的示例实施例。
18.图3描绘了多通道最小统计(mcms)语音活动检测(vad)电路的高级框图。
19.图4描绘了用于语音活动检测模型的示例推断信号流。
20.图5描绘了用于音频数据中的上下文检测的示例采样方法。
21.图6描绘了用于执行基于硬件的语音活动检测的示例方法。
22.图7描述了用于执行基于硬件的语音活动检测的示例处理系统。
23.为了促成理解,在可能之处使用了相同的附图标记来指定各附图共有的相同要素。构想一个实施例的要素和特征可有益地纳入其他实施例而无需进一步引述。
24.详细描述
25.本公开的各方面提供了用于以比常规方法更高的准确度和更低的功率使用来执行语音活动检测的装置、方法、处理系统和计算机可读介质。
26.语音活动检测一般指电子设备为了执行一些功能而对人类语音进行的区分。例如,许多消费电子设备使用语音活动检测(诸如通过特定关键词的识别)来“唤醒”设备、查询设备,并使该设备执行各种其他功能。语音活动检测还可被用于更复杂的功能性,诸如“远场”语音检测(例如,来自跨房间放置的移动设备)、用户身份验证(例如,通过语音签名)、其他音频输出期间的语音检测(例如,在设备上播放音乐时检测语音命令或者在智能助理正在讲话时检测中断命令)、以及复杂噪声环境中的语音交互(诸如在移动交通工具内)。这些仅仅是几个示例,并且许多其他示例也是可能的。
27.像电子设备上的各种其他处理任务一样,语音活动检测需要功率和专用硬件和/或软件来运作。此外,语音活动检测一般被实现为“常开”功能以使其对具有语音激活式功能性的电子设备的用户的效用最大化。对于始终被插入的设备,常开语音活动检测功能性的功率使用主要是效率考虑,但是对于具有常开语音活动功能性的功率敏感的设备(例如,移动电子设备、物联网设备等),考虑更为复杂。例如,来自常开功能的功率使用可能限制此类设备的运行时间,并且降低用于其他系统处理需求的容量。此外,与语音活动检测相关的硬件可能消耗移动电子设备内的芯片上的宝贵且有限的空间,这些空间随后无法被用于其他功能性。
28.一般存在两种类型的语音活动检测实现:基于硬件的语音活动检测以及基于软件的语音活动检测。
29.基于硬件的语音活动检测一般使用硬件实现的电路来分析传入音频信号以探知语音存在,诸如通过使用用于信噪比(snr)检测的电路系统。不幸的是,常规基于硬件的语
音活动检测对于非固定音频信号展现出不良的准确度(例如,高假阳率和假阴率)。因此,此类实现往往具有对传入音频(例如,噪声)的类型非常敏感的性能,并且由此跨不同的噪声环境中不规则地执行(诸如在安静的房间中、在繁忙的街道上、或在移动的交通工具中,仅列举几个示例)。此外,即使当传入音频信号具有高snr时,常规基于硬件的系统仍由于高度非固定的噪声环境而遭受不良的准确度(例如,就假阳率和假阴率而言)。
30.基于软件的语音活动检测一般使用软件实现的模型来分析传入音频信号以探知语音存在。例如,各种基于软件的预处理步骤可生成机器学习模型(诸如深度神经网络模型)的输入数据,该模型随后被用来通过推断检测音频信号中的语音。虽然基于软件的语音活动检测系统实现比常规基于硬件的系统高的准确度,大部分原因是由于它们运行最先进的、可重新训练的检测模型的能力,但是它们需要更复杂、更功率渴求的处理硬件,诸如专用数字信号处理器(dsp)、机器学习加速器、人工智能处理核等。即使使用标准处理单元来运行基于软件的模型,也比常规基于硬件的语音活动检测系统生成显著更高的功率使用。由此,基于软件的高功率语音活动检测系统一般不是功率敏感的设备(诸如移动电子设备和其他边缘处理设备)的理想选项。
31.本文中所描述的实施例通过利用基于硬件的语音活动检测设计克服了常规解决方案的缺点,该设计包括高效的特征压缩前端,该特征压缩前端供应高效的基于硬件的机器学习模型后端。
32.特别地,本文中所描述的实施例使用快速傅立叶变换(fft)来生成紧凑型多频带特征向量,这进而实现基于多频带最小统计(例如,噪声本底确定)的多频带信噪比(snr)确定。与输出大得多(例如,512频带)的常规基于软件的方法相比,使用紧凑型fft输出(例如,16频带(或点或通道)输出)实现更小的模型大小以及更小的数据大小,这减少了物理(硬件)模型实现空间、存储器要求和功率要求。
33.此外,本文中所描述的实施例使用基于硬件的机器学习模型后端,这实现比常规基于硬件的snr阈值检测方案更强健的语音活动检测。
34.此外,本文中所描述的实施例实现上下文感知以进一步提高语音检测准确度。在一些实施例中,上下文感知允许确定特定背景噪声类型,因此类型特定的模型参数可被加载到基于硬件的机器学习模型后端,以提高语音活动检测准确度。
35.由此,本文中所描述的实施例实现了两种常规解决方案类型中的最佳;即,硬件实现级功率效率的软件实现级准确度。
36.上下文感知的基于硬件的示例语音活动检测系统
37.图1描述了上下文感知的基于硬件的示例语音活动检测系统100。
38.系统100从电子系统中的音频源接收音频信号(例如,从模拟麦克风接收pcm音频数据、从数字麦克风接收pdm高清音频等)。例如,音频信号可由电子设备(诸如移动电子设备、智能家用设备、物联网(iot)设备、或其他边缘处理设备)的一个或多个麦克风生成。
39.所接收的音频信号由特征生成器104处理。特征生成器104可以例如是硬件实现的傅立叶变换,诸如快速傅立叶变换(fft)功能或电路。傅立叶变换一般是用于将信号的时域表示(诸如所接收的音频信号)解构成频域表示的函数。频域表示可包括所接收的音频信号中以变化的频率存在的电压或功率。关于图2更详细地描述了特征生成器104的示例实施例。值得注意的是,在其他实施例中可使用其他或附加形式的特征生成。
40.然后,由特征生成器104从来自音频源102的音频信号生成的特征由上下文检测器106处理。在该示例中,上下文可指预定义或预先表征的音频环境,诸如安静的房间、繁忙的街道、办公环境、飞行器和汽车、购物中心、音乐会等。在一些实施例中,上下文基于由特征生成器104生成的特征来确定(例如,通过使用fft特征的和与差改变进行最大似然估计或简单阈值比较)。以下关于图6更详细地描述了用于上下文检测的示例方法。
41.所确定的上下文由语音活动检测器108用来加载因上下文而异的语音活动模型,诸如可被存储在语音活动模型库110中,在一些实施例中,语音活动模型库110可被存储在电子设备的存储器中。
42.因上下文而异的语音活动模型一般可提高语音活动检测器108准确地标识所接收的音频信号中的语音的能力。值得注意的是,在一些实施例中,上下文检测器106可能不存在,或者上下文检测器106可以不确定上下文,在该情形中,语音活动检测器108可使用基本或默认语音活动检测模型,而非因上下文而异的模型。
43.语音活动检测器108使用语音活动检测模型112来确定所接收的音频信号是否包括语音活动。如上,语音活动可包括音频信号中人类语音的存在,并且可进一步包括一个或多个关键词、用自然语言引擎解析的语句等。在一些情形中,语音活动检测器108可使用多级语音活动检测模型112。
44.一旦语音活动检测器108确定所接收的音频信号中的语音活动,它就为另一系统功能114生成信号。例如,检测到的语音活动中的关键字可能导致应用启动、或电子设备的另一部分(例如,屏幕、其他处理器、或其他传感器)苏醒、或查询在本地或在远程数据服务处运行等。在一些实施例中,系统功能114可仅接收关于语音活动已经被检测到的指示,而在其他实施例中,系统功能114可接收附加信息,诸如特定于检测到的语音活动的信息,诸如语音活动中的一个或多个检测到的关键词。值得注意的是,在语音活动检测器108与系统功能114之间可能存在附加功能(未示出),诸如语音活动检测或分析的附加级。
45.图2描绘了特征生成器200的示例实施例,特征生成器200可被实现为图1的特征生成器104。
46.特征生成器200在信号预处理器202处接收音频信号。如上,音频信号可来自电子设备的音频源,诸如麦克风。
47.信号预处理器202可对所接收的音频信号执行各种预处理步骤。例如,信号预处理器202可将该音频信号拆分成并行音频信号并将这些信号中的一个信号延迟预定时间量以将这些音频信号准备好以供输入fft电路。
48.作为另一示例,信号预处理器202可执行窗函数,诸如hamming、hann、blackman-harris、kaiser-bessel窗函数、或其他基于正弦的窗函数,这可提高进一步处理级(诸如信号域变换器204)的性能。一般地,其中的加窗(或窗)函数可被用来减小所接收的音频信号数据的每个有限序列的边界处的不连续性的幅度以改进进一步处理。
49.作为另一示例,信号预处理器202可将音频信号数据从并行转换至串行,或者反之亦然,以供进一步处理。
50.经预处理音频信号随后被提供给音频数据缓冲器212,音频数据缓冲器212可在语音活动检测待决的情况下保存音频数据,并且随后在检测到语音活动的情况下与附加处理级共享数据,诸如关于图3-5进一步描述的。
51.经预处理音频信号还被提供给信号域变换器204,信号域变换器204一般被配置成将经预处理音频信号从第一域变换到第二域,诸如从时域变换到频域。
52.在一些实施例中,信号域变换器204实现傅立叶变换,诸如快速傅立叶变换。例如,在一些实施例中,快速傅立叶变换可以是16频带(或频槽、通道或点)快速傅立叶变换,其生成可由模型高效处理的紧凑型特征集。有益的是,与常规单通道处理(诸如常规硬件snr阈值检测)相比,傅立叶变换提供了关于传入音频信号的精细频谱域信息。
53.信号域变换器204的结果是一组音频特征,诸如经变换数据中每频带的一组电压、功率或能量。
54.该组音频特征随后被提供给信号特征滤波器206,信号特征滤波器206被配置成减小音频特征数据中的特征集的大小或压缩该特征集。在一些实施例中,信号特征滤波器206可被配置成从音频特征集丢弃某些特征,诸如来自多频带快速傅立叶变换的多个频带的对称或冗余特征。丢弃该数据减少了数据流的总体大小以供进一步处理,并且可被称为压缩数据流。
55.例如,在一些实施例中,由于音频信号是实数,因此16频带fft可包括功率被平方之后的8个对称或冗余频带。由此,信号特征滤波器206可滤除冗余或对称频带信息。
56.经滤波音频特征集随后被提供给噪声本底分析器208,噪声本底分析器208可被配置成确定音频特征集中的每个特征的最小统计。
57.在一些实施例中,噪声本底分析器208被配置为具有用于预定数目的个体特征的槽的缓冲器,根据预定数目的个体特征可在音频数据的预定数目的观察或帧的过程上确定最小值观察(例如,最小统计)。经滤波音频特征集中的每个特征的这些最小值可包括噪声本底特征集,其可在后续处理中用于确定信噪比。
58.经滤波音频特征集和噪声本底特征集随后被提供给信噪比转换器210,信噪比转换器210被配置成基于这些特征集来确定信噪比。在一些实施例中,该转换使用对数函数(诸如以10为底的对数函数)来执行。对数函数可以有益地压缩特征范围以使得进一步处理更高效。此外,对数函数可通过将除法转换成计算上不那么成本高的减法(例如,其中分子和分母的对数值彼此相减以获得与除法运算等效的值)来有益地减少或避免计算上成本高的除法运算。
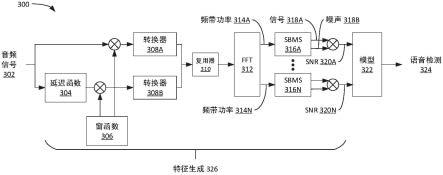
59.图3描绘了可在电子设备中被实现为硬件的多通道最小统计(mcms)话音活动检测(vad)电路300的高级框图。vad电路300可以是如图1中的语音活动检测器108的示例。
60.音频信号302可以例如是16khz pcm数据。音频信号数据最初被拆分,其中一条支路进入延迟缓冲器304。在一些实施例中,延迟缓冲器304被配置成在音频信号数据中生成50%延迟。例如,若音频信号具有16个样本,则50%延迟将使信号偏移8个样本,诸如图5的示例中所示。
61.在一个实施例中,16khz pcm传入信号被编群成步长为8(即,50%交叠)的16
×
1向量,或者换言之,在加窗、交叠和相加之后的16个pcm样本。
62.音频信号302的原始和经延迟两条支路随后由窗函数306处理并且随后分别传递给转换器308a和308b。在一些实施例中,窗函数是正弦窗函数,诸如hamming或hann窗函数。此外,在该实施例中,转换器308a和308b是串行至并行(s/p)转换器,s/p转换器将串行数据流转换成并行数据流。
63.经加窗和经转换数据流(例如,向量)随后被提供给复用器310,复用器310组合数据流以输入到快速傅立叶变换器(fft)312中。一般地,fft 312是被配置成生成针对多个个体频带的功率数据;换言之,基于硬件的fft电路。
64.在一个实施例中,fft 312是16频带fft引擎,其由于延迟缓冲器304而具有50%交叠。在此类实施例中,fft 312将输入信号解压缩成多个频带,每个频带具有所确定的功率值。值得注意的是,由于该示例中的输入音频信号总是实数,所以来自fft 312的fft输出的绝对值是对称的。由此,在该示例中,滤除重复的频带并保留16个频带中的仅8个频带(即,314a-314n,其中n=8)以供后续处理。
65.在输入音频信号302是经由延迟缓冲器304而具有50%交叠的16khz pcm数据并且fft 312是16频带变换的示例中,每个fft输出端口处的输出采样率是16khz/16频带fft/0.5交叠=2khz。
66.个体频带功率314a-n随后被提供给单频带最小统计(sbms)块316a-n,sbms块316a-n被配置成关于每个个体功率频带314a-n确定信号功率电平(例如,318a)和噪声本底功率电平(318b)。
67.在一个实施例中,至sbms 316a-316n的输入是由fft 312确定的个体频带功率314a-n的幅值平方输出。幅值平方fft输出允许容易地确定重复频带值。在其中fft 312被配置成输出8个个体频带314a-n的示例中,则存在8个对应sbms块(316a-n)。在一个实施例中,每个sbms块的输出信号的采样率是100hz或每采样10ms。
68.每个sbms块316a-n可被配置成使用例如积分和转储电路来计算信号功率。在此类示例中,来自fft 312的输入信号首先被幅度平方,并且随后被累加达c个循环,其中c给出期望帧速率。由此,对于2khz输入速率和10ms帧速率,c为20。
69.每个sbms块316a-n还可被配置成输出以10为底的对数信号功率以及以10为底的对数噪声功率,它们的差异给出个体频带对数信噪比(snr)320a-320n。这些snr值随后被馈送到模型322中以最终确定音频信号302中的语音活动。
70.在其他实施例中,其他测量可被用作至模型322的输入。例如,在一些情形中,仅信号分量(例如,318a)可被提供给模型322,并且该信号分量可与基线噪声本底或常数进行比较。
71.在一个实施例中,模型322是多列支持向量机(svm)模型,并且语音活动检测决策是针对每个个体fft频带作出的。在其他实施例中,模型322可以是用于较低功率应用的单列svm。
72.值得注意的是,在该实施例中,模型322以硬件来实现。模型322的参数可被存储在存储器(未描绘)中并被加载。如以上在图1中所示,模型322可基于为音频信号302确定的不同上下文来加载不同的模型参数(例如,权重和偏置)。
73.图4描绘了用于语音活动检测模型(诸如图3中的模型322)的示例推断信号流400。
74.最初,每向量具有m个信噪比(snr)或对数snr的特征向量(诸如由图3中sbmc 316a-n输出的那些特征向量)被提供给串行至并行数据转换器404。转换器404获取多维向量输入并将一组特征帧(其包括目标特征帧406b、f个过去特征帧406a和f个将来特征帧406c)输出到输入特征缓冲器422。此处,“过去”和“将来”是基于目标特征帧的相对术语。由此,在该示例中,在输入特征空间中总共存在2f+1个帧,并且每个帧(例如,406)具有m个观
察。
75.特征帧406被提供给大小为(2f+1)*m
×
h的多列svm模型408,其中h是多列svv模型408的输出数目(例如,输出层中的节点数目)。值得注意的是,在其他示例中,svm模型408可由其他类型的机器学习模型(诸如神经网络模型)来代替。在该示例中,多列svm模型408以硬件来实现。在一些实施例中,模型408的权重和偏置可以是静态的,而在其他实施例中,权重和偏置可被动态地加载,例如,从存储器加载,诸如以上关于图1所描述的。
76.在所描绘的示例中,多列svm模型408输出大小为1
×
h的特征图410。特征图410随后在被激活函数414处理之前由偏置算子412施加1
×
h偏置集。在一些实施例中,激活函数412是非线性激活函数,诸如relu。
77.激活输出随后被传递给h
×
1单列svm模型416,在该示例中,单列svm模型416输出1
×
1标量值。随后将标量值与阈值进行比较以确定在特征化音频信号402中是否检测到任何语音活动。例如,若标量值大于或等于阈值,则检测到语音活动,并且若标量值小于阈值,则未检测到任何语音活动,反之亦然。
78.由此,推断信号流400可被描述为多层感知器模型,在该示例中,多层感知器模型包括两层svm模型。
79.在一个示例中,特征生成块(诸如如上所述)每10ms帧输出8
×
1snr向量。这些帧随后被馈送到帧抽头延迟线以堆叠21个帧(10个过去帧、一个目标帧和10个将来帧),随后被馈送到168
×
20svm矩阵(例如,21帧snr*8个特征=168),该svm矩阵像多相内插器一样工作。一般地,多相内插器获取信号流并使用多相滤波器组(例如,将输入信号拆分成给定数目的等距子带的滤波器组)来执行上采样(内插)。特征的成帧有利地包括输入数据流中的更多音频上下文(历史)信息,并且增大了特征大小。
80.svm矩阵被应用于输入数据以生成每帧1
×
20向量。随后将1
×
20向量与固定的1
×
20偏置向量相加。此后,非线性激活函数(例如,relu)被用来创建激活并向检测系统添加非线性。最后,语音活动检测通过将20
×
1单列svm模型应用于激活来作出以生成可与阈值进行比较的标量输出。
81.由此,在该示例中,数据的总共21个帧被用来进行单个语音活动检测,包括10个过去特征帧(例如,406a)、10个将来特征帧(例如,406c)以及用于语音活动检测的单个目标特征帧(例如,406b)。以此方式,多列svm模型408处理目标帧(决策点)之前和之后的信号,并基于这些帧有效地作出联合决策。
82.示例上下文检测方法
83.上下文感知的有益方面是对音频场景和音频事件的分类或分类的改变。如上所述,当确定上下文时,一组因上下文而异的模型参数被加载到模型中,诸如关于图1(112)、3(322)和4(400)所讨论的语音活动模型。
84.在一个实施例中,上下文检测方法缓冲n个音频样本,并且随后对经缓冲样本执行域变换(例如,fft)以获得信号功率频谱。该方法随后步进n/2个样本并重复域变换,如图5中所描绘的。具体而言,图5描绘了n个音频样本的第一选择502、n/2个音频样本的步长504,并且随后为n个音频采样的第二选择506,其中一半与第一步交叠。
85.在一些实施例中,可对频谱系数应用附加滤波。在一些实施例中,n可以相对较小,诸如16、8、或甚至4。
86.在一些实施例中,n个样本的每个域变换使用fft来执行,并根据下式获取系数的绝对值的平方以获得频谱系数:
[0087][0088]
频谱系数s
t,m
随后可被滤波。例如,在一些实施例中,可使用系数α=1
–
n/2048,这对应于在使用每秒16k个样本的输入音频数据时滤波器的1/2寿命衰减约为1/20秒。这可被表示为:
[0089]
γ
t,m
=αγ
t-1,m
+(1-α)s
t,m
,
[0090]
其中γ
t,m
是经滤波频谱系数。
[0091]
滤波的结果随后可根据下式转换成分贝值:
[0092]
γ
t,m
=10log
10
γ
t,m
[0093]
其中γ
t,m
是经滤波频谱系数的分贝值。
[0094]
随后,可根据下式来确定总能量e
t
,其是经滤波频谱系数的总和:
[0095]et
=10log
10
∑γ
t,m
[0096]
最后,可从γ
t,m
中减去e
t
(分贝值)以产生:
[0097]
△
t,m
=γ
t,m-e
t
,
[0098]
其中e
t
是经平滑的总能量,并且
△
t,m
是经平滑和归一化的频谱系数。
[0099]
为了确定音频场景是不同的还是不变的,可将e
t
和
△
t,m
与阈值进行比较。一般地,大部分频谱能量将落入第一谱带,并且使用该假言来避免计算e
t
并取而代之地从其他谱带中减去第一谱带是可能的。
[0100]
若以下任一者为真,则该方法将触发检测到的上下文改变,换言之,上下文感知:
[0101][0102][0103][0104][0105]
在先前表达式中,t值是阈值,目前上阈值和下阈值被设为相同的值。然而,保留将t值m保持为单独阈值的灵活性可能是值得的。每当存在检测到的上下文改变时,也要求参考值(和),并且这些参考值被设为e
t
和
△
t,m
的当前值。换句话说,每当检测到新上下文时,系数就成为针对后续上下文改变的新参考。
[0106]
在一些实施例中,能量阈值的值为15db,
△
阈值的值为10db。
[0107]
由此,前述上下文检测方法被设计成每当音频中存在总能量改变(向上或向下)或者每当存在音频的模式改变时触发。
[0108]
用于执行基于硬件的语音活动检测的示例方法
[0109]
图6描绘了用于执行基于硬件的语音活动检测的示例方法600。
[0110]
方法600在步骤602始于从电子设备的音频源接收音频数据。在一些实施例中,音
频源包括电子设备的一个或多个麦克风。
[0111]
方法600随后行进至步骤604,其中使用基于硬件的特征生成器基于所接收的音频数据来生成多个模型输入特征。
[0112]
在一些实施例中,基于硬件的特征生成器包括硬件实现的快速傅立叶变换电路,诸如以上关于图2(204)和3(312)所描述的。在一些实施例中,特征生成器可由图7中的特征生成器电路726来实现。
[0113]
在一些实施例中,使用该基于硬件的特征生成器来生成该多个模型输入特征包括以下一者或多者:预处理所接收的音频数据以生成域变换输入数据;使用域变换电路基于该域变换输入数据来生成多个频带输出;从来自该域变换电路的多个频带输出中选择频带输出子集;以及确定该频带输出子集中的每个频带输出的信噪比,其中每个频带输出的每个信噪比是一模型输入特征,诸如以上关于图2和3所描述的。在一些实施例中,该频带输出子集包括八个频带输出。
[0114]
在一些实施例中,预处理所接收的音频数据包括以下一者或多者:将所接收的音频数据拆分成第一音频数据流和第二音频数据流;将延迟函数应用于第二音频数据流以生成经延迟的第二音频数据流;将窗函数应用于第一音频数据流和经延迟的第二音频数据流;以及将串行至并行转换应用于第一音频数据流和经延迟的第二音频数据流。
[0115]
在一些实施例中,确定频带输出子集中的每个频带输出的信噪比包括以下一者或多者:确定该频带输出子集中的每个频带输出的噪声本底;将对数函数应用于该频带输出子集中的每个频带输出的噪声本底;确定该频带输出子集中的每个频带输出的信号功率电平;以及将对数函数应用于该频带输出子集中的每个频带输出的信号功率电平,其中该频带输出子集中的每个频带输出的信噪比包括对数信噪比,诸如以上关于图3所描述的(例如,snr 320a-n)。
[0116]
方法600随后行进至步骤606,其中向基于硬件的语音活动检测模型提供该多个模型输入特征。该语音活动检测模型随后可基于模型参数(例如,因上下文而异的模型参数)来处理输入特征以生成模型输出值。
[0117]
方法600随后行进至步骤608,其中从该基于硬件的语音活动检测模型接收输出值,诸如以上关于图3所描述的324或图4中的框416的输出。
[0118]
方法600随后行进至步骤610,其中基于该输出值来确定该音频数据中的语音活动的存在。在一些实施例中,确定语音活动可由语音活动检测器电路来实现,诸如图7中的730。
[0119]
在一些实施例中,该基于硬件的语音活动检测模型包括硬件实现的svm模型,诸如举例而言以上关于图1-4所描述的。在一些实施例中,该硬件实现的svm模型包括:第一多列svm电路;以及第二单列svm电路,第二单列svm电路被配置成生成该输出值,诸如举例而言以上关于图4所描述。
[0120]
在一些实施例,方法600进一步包括:将用于该硬件实现的svm模型的多个模型参数加载到该电子设备的存储器(例如,图7中的存储器724)中。
[0121]
在一些实施例,方法600进一步包括:在确定该音频数据中的语音活动的存在之后在一时间区间内禁用语音活动检测以避免冗余检测。在一些实施例中,该时间区间可被称为“后遗时间区间”,并且可例如通过图7中的后遗电路732来实现。
[0122]
在一些实施例,方法600进一步包括:确定该音频数据的上下文;将因上下文而异的模型参数加载到该电子设备的存储器中;以及基于因上下文而异的模型参数来确定该音频数据中的语音活动的存在(例如,其中该基于硬件的语音活动检测模型使用因上下文而异的模型参数来生成模型输出值)。在一些实施例中,上下文检测可例如通过图7中的上下文检测器电路728来实现。
[0123]
用于执行基于硬件的语音活动检测的示例处理系统
[0124]
图7描绘了用于执行基于硬件的语音活动检测(诸如举例而言在本文中关于图6所描述的)的示例处理系统700。
[0125]
电子设备700包括中央处理单元(cpu)702,其在一些示例中可以是多核cpu。在cpu 702处执行的指令可例如从与cpu 702相关联的存储器(诸如举例而言存储器724)加载。
[0126]
电子设备700还包括为特定功能定制的附加处理组件,诸如图形处理单元(gpu)704、数字信号处理器(dsp)706、神经处理单元(npu)708、多媒体处理单元710、以及无线连通性组件712。
[0127]
npu(诸如npu 708)一般是被配置成用于实现用于执行机器学习算法(诸如用于处理人工神经网络(ann)、深度神经网络(dnn)、随机森林(rf)等的算法)的所有必要的控制和算术逻辑的专用电路。npu有时可被替换地称为神经信号处理器(nsp)、张量处理单元(tpu)、神经网络处理器(nnp)、智能处理单元(ipu)、视觉处理单元(vpu)或图形处理单元。
[0128]
npu(诸如npu 708)被配置成加速常见机器学习任务(诸如图像分类、机器翻译、对象检测以及各种其他预测模型)的执行。在一些示例中,多个npu可被实例化在单个芯片(诸如片上系统(soc))上,而在其他示例中,多个npu可以是专用神经网络加速器的一部分。
[0129]
npu可被优化以用于训练或推断,或者在一些情形中可被配置成平衡训练与推断之间的性能。对于能够执行训练和推断两者的npu,这两个任务可能通常仍然是独立执行的。
[0130]
被设计成加速训练的npu一般被配置成加速对新模型的优化,这是涉及输入现有数据集(常常是被标记的或含标签的)、在数据集上进行迭代、以及接着调节模型参数(诸如权重和偏置)以便改进模型性能的高度计算密集的操作。一般而言,基于错误预测进行优化涉及往回传递通过模型的各个层并确定梯度以减少预测误差。
[0131]
被设计成加速推断的npu一般被配置成在完整模型上操作。此类npu因而可被配置成输入新的数据片段以及通过已经训练好的模型来快速处理该数据片段以生成模型输出(例如推断)。
[0132]
在一种实现中,npu 708是cpu 702、gpu 704和/或dsp 706中的一者或多者的一部分。
[0133]
在一些示例中,无线连通性组件712可包括例如用于第三代(3g)连通性、第四代(4g)连通性(例如,4g lte)、第五代连通性(例如,5g或nr)、wi-fi连通性、蓝牙连通性、以及其他无线数据传输标准的子组件。无线连通性处理组件712被进一步连接到一个或多个天线714。
[0134]
电子设备700还可包括与任何方式的传感器相关联的一个或多个传感器处理单元716、与任何方式的图像传感器相关联的一个或多个图像信号处理器(isp)718、和/或可包括基于卫星的定位系统组件(例如,gps或glonass)以及惯性定位系统组件的导航处理器
720。
[0135]
电子设备700还可包括一个或多个输入和/或输出设备722,诸如屏幕、触敏表面(包括触敏显示器)、物理按钮、扬声器、麦克风等等。
[0136]
在一些示例中,电子设备700的一个或多个处理器可基于arm或risc-v指令集。
[0137]
电子设备700还包括存储器724,该存储器724代表一个或多个静态和/或动态存储器,诸如动态随机存取存储器、基于闪存的静态存储器等等。在该示例中,存储器724包括计算机可执行组件,其可由电子设备700的前述处理器中的一个或多个处理器执行。
[0138]
具体而言,在该示例中,存储器724包括确定组件724a、接收组件724b、处理组件724c、输出组件724d和vad模型参数724e。所描绘的组件以及未描绘的其他组件可被配置成执行本文中所描述的方法的各方面。
[0139]
电子设备700进一步包括特征生成器电路726,诸如以上关于图1(104)、2(200)和3(326)所描述的。
[0140]
电子设备700进一步包括上下文检测器电路728,诸如以上关于图1(106)所描述的。
[0141]
电子设备700进一步包括语音活动检测器电路730,诸如以上关于图1(108)、3(300)和4(400)所描述的。
[0142]
电子设备700进一步包括特征后遗电路732,诸如以上关于图6所描述的。
[0143]
一般而言,电子设备700和/或其组件可被配置成执行本文中所描述的方法。
[0144]
示例条款
[0145]
在以下经编号条款中描述了各实现示例。
[0146]
条款1:一种用于执行语音活动检测的方法,包括:从电子设备的音频源接收音频数据;使用基于硬件的特征生成器基于所接收的音频数据来生成多个模型输入特征;基于由基于硬件的语音活动检测模型基于该模型输入特征生成的输出值来确定该音频数据中的语音活动的存在。
[0147]
条款2:如条款1的方法,其中使用该基于硬件的特征生成器来生成该多个模型输入特征包括:预处理所接收的音频数据以生成域变换输入数据;使用域变换电路基于该域变换输入数据来生成多个频带输出;从来自该域变换电路的多个频带输出中选择频带输出子集;以及确定该频带输出子集中的每个频带输出的信噪比,其中每个频带输出的每个信噪比是该多个模型输入特征中的一模型输入特征。
[0148]
条款3:如条款2的方法,其中该基于硬件的特征生成器包括硬件实现的快速傅立叶变换电路。
[0149]
条款4:如条款2-3中的任一者的方法,其中确定该频带输出子集中的每个频带输出的信噪比包括:确定该频带输出子集中的每个频带输出的噪声本底;将对数函数应用于该频带输出子集中的每个频带输出的噪声本底;确定该频带输出子集中的每个频带输出的信号功率电平;以及将对数函数应用于该频带输出子集中的每个频带输出的信号功率电平,其中该频带输出子集中的每个频带输出的信噪比包括对数信噪比。
[0150]
条款5:如条款2-4中的任一者的方法,其中预处理所接收的音频数据包括:将所接收的音频数据拆分成第一音频数据流和第二音频数据流;将延迟函数应用于第二音频数据流以生成经延迟的第二音频数据流;将窗函数应用于第一音频数据流和经延迟的第二音频
数据流;以及将串行至并行转换应用于第一音频数据流和经延迟的第二音频数据流。
[0151]
条款6:如条款1-5中的任一项的方法,其中该基于硬件的语音活动检测模型包括硬件实现的svm模型。
[0152]
条款7:如条款6的方法,其中该硬件实现的svm模型包括:第一多列svm电路;以及第二单列svm电路,第二单列svm电路被配置成生成该输出值。
[0153]
条款8:如条款6的方法,进一步包括将用于该硬件实现的svm模型的多个模型参数加载到该电子设备的存储器中。
[0154]
条款9:如条款2-8中的任一者的方法,其中该频带输出子集包括八个频带输出。
[0155]
条款10:如条款1-9中的任一者的方法,其中该音频源包括该电子设备的一个或多个麦克风。
[0156]
条款11:一种处理系统,包括:存储器,该存储器包括计算机可执行指令;以及一个或多个处理器,该一个或多个处理器被配置成执行这些计算机可执行指令并使该处理系统执行根据条款1-10中的任一者的方法。
[0157]
条款12:一种处理系统,包括用于执行根据条款1-10中的任一者的方法的装置。
[0158]
条款13:一种包括计算机可执行指令的非瞬态计算机可读介质,这些计算机可执行指令在由处理系统的一个或多个处理器执行时使该处理系统执行根据条款1-10中的任一者的方法。
[0159]
条款14:一种实现在计算机可读存储介质上的计算机程序产品,该计算机可读存储介质包括用于执行根据条款1-10中的任一者的方法的代码。
[0160]
附加考虑
[0161]
提供先前描述是为了使本领域任何技术人员均能够实践本文中所描述的各个实施例。本文中所讨论的示例并非是对权利要求中阐述的范围、适用性或者实施例的限定。对这些实施例的各种修改将容易为本领域技术人员所明白,并且在本文中所定义的普适原理可被应用于其他实施例。例如,可对所讨论的要素的功能和布置作出改变而不会脱离本公开的范围。各种示例可恰适地省略、替代、或添加各种规程或组件。例如,可以按与所描述的次序不同的次序来执行所描述的方法,并且可以添加、省略、或组合各种步骤。而且,参照一些示例所描述的特征可在一些其他示例中被组合。例如,可使用本文中所阐述的任何数目的方面来实现装置或实践方法。另外,本公开的范围旨在覆盖使用作为本文中所阐述的本公开的各个方面的补充或者不同于本文中所阐述的本公开的各个方面的其他结构、功能性、或者结构及功能性来实践的此类装置或方法。应当理解,本文中所披露的本公开的任何方面可由权利要求的一个或多个元素来实施。
[0162]
如本文中所使用的,术语“示例性”意指“用作示例、实例或解说”。本文中描述为“示例性”的任何方面不必被解释为优于或胜过其他方面。
[0163]
如本文中所使用的,引述一列项目“中的至少一者”的短语是指这些项目的任何组合,包括单个成员。作为示例,“a、b或c中的至少一者”旨在涵盖:a、b、c、a-b、a-c、b-c、和a-b-c,以及具有多重相同元素的任何组合(例如,a-a、a-a-a、a-a-b、a-a-c、a-b-b、a-c-c、b-b、b-b-b、b-b-c、c-c、和c-c-c,或者a、b和c的任何其他排序)。
[0164]
如本文所使用的,术语“确定”涵盖各种各样的动作。例如,“确定”可包括演算、计算、处理、推导、研究、查找(例如,在表、数据库或另一数据结构中查找)、查明及诸如此类。
而且,“确定”可以包括接收(例如,接收信息)、访问(例如,访问存储器中的数据)及诸如此类。而且,“确定”可包括解析、选择、选取、建立及诸如此类。
[0165]
本文中所公开的各方法包括用于实现方法的一个或多个步骤或动作。这些方法步骤和/或动作可以彼此互换而不会脱离权利要求的范围。换言之,除非指定了步骤或动作的特定次序,否则具体步骤和/或动作的次序和/或使用可以改动而不会脱离权利要求的范围。此外,上述方法的各种操作可由能够执行相应功能的任何合适的装置来执行。这些装置可包括各种硬件和/或软件组件和/或模块,包括但不限于电路、专用集成电路(asic)、或处理器。一般地,在存在附图中解说的操作的场合,这些操作可具有带相似编号的相应配对装置加功能组件。
[0166]
以下权利要求并非旨在被限定于本文中示出的实施例,而是应被授予与权利要求的语言相一致的全部范围。在权利要求内,对单数元素的引用不旨在意指“有且只有一个”(除非专门如此声明),而是“一个或多个”。除非特别另外声明,否则术语“一些/某个”指的是一个或多个。权利要求的任何要素都不应当在35u.s.c.
§
112(f)的规定下来解释,除非该要素是使用短语“用于
……
的装置”来明确叙述的或者在方法权利要求情形中该要素是使用短语“用于
……
的步骤”来叙述的。本公开通篇描述的各个方面的要素为本领域普通技术人员当前或今后所知的所有结构上和功能上的等效方案通过引述被明确纳入于此,且旨在被权利要求所涵盖。此外,本文所公开的任何内容都不旨在捐献于公众,无论此类公开内容是否明确记载在权利要求书中。
相关技术
网友询问留言
已有4条留言
-
 0189245... 来自[中国] 2023年02月07日 10:09看着不错 继续努力
0189245... 来自[中国] 2023年02月07日 10:09看着不错 继续努力 -
0155345... 来自[中国] 2023年02月06日 23:24支持支持
-
0137972... 来自[中国] 2023年02月06日 13:17鼓励技术创新,
-
0176660... 来自[中国] 2023年02月06日 12:10看着还行
1