语音合成方法、系统、电子设备及可读存储介质与流程
本申请实施方式涉及语音处理,更具体地,涉及一种语音合成方法和系统。本申请实施方式还涉及一种电子设备、一种计算机可读存储介质。
背景技术:
1、语音合成(text to speech,tts)是人工智能研究领域的分支之一,用于将文字信息转换为语音信息。tts分为语音合成前端和语音合成后端。合成前端用于将文本序列转换为相应的声学特征序列,其中声学特征序列可例如包括韵律、多音字以及重音等信息;合成后端用于将声学特征序列输入声学模型,并通过声学模型将声学特征序列转换为语音。
2、目前,tts一直受到真实音频数据(ground truth,可理解为录音)的声学特征与其预测特征值之间差异的困扰。通常该问题可通过增强声学模型,例如使其具有更先进的结构或更复杂的算法来解决,或者例如使声码器适应预测特征来解决。然而,这些方法也使预测器的训练更加困难,并对预测器的建模能力提出了更高的要求。
技术实现思路
1、本申请实施方式提供了一种可至少部分解决相关技术中存在的上述问题的语音合成方法、系统、电子设备和计算机可读存储介质。
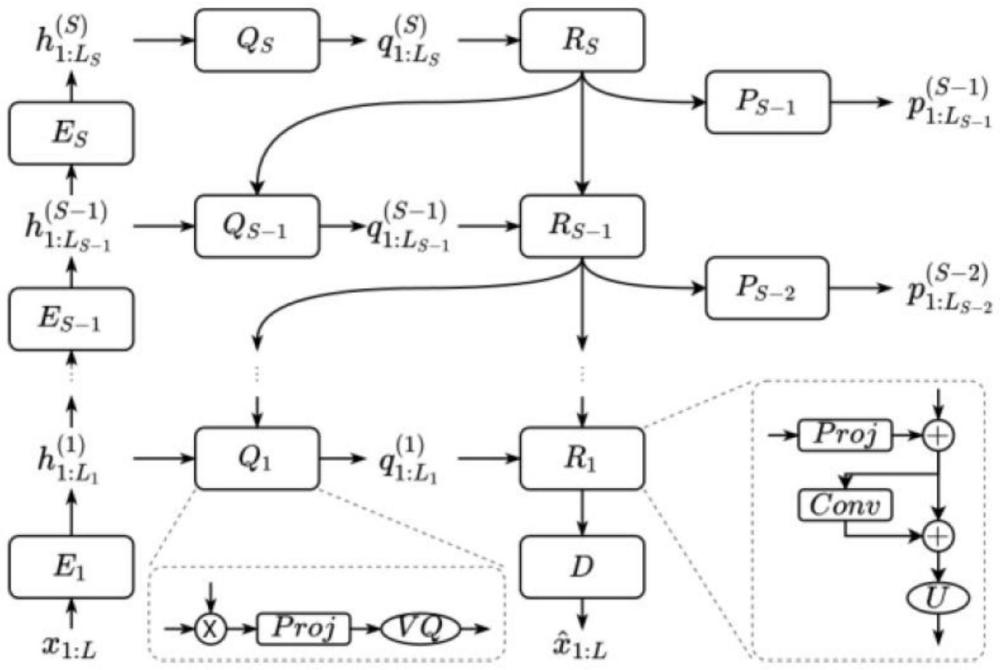
2、本申请一方面提供了一种语音合成方法,实现所述语音合成方法的系统包括预测器和声码器,所述语音合成方法包括:采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化,以形成索引序列;以及将所述索引序列映射为声音波形,得到与所述输入文本对应的合成语音。
3、在本申请一个实施方式中,采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化包括:将所述声学特征序列转化为一组具有不同时间分辨率阶段的子序列;以及采用多个所述预定代码本分别对每个所述子序列进行量化。
4、在本申请一个实施方式中,采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化包括:采用损失函数对量化结果进行优化,其中所述损失函数包括均方误差和三重态损失。
5、在本申请一个实施方式中,采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化包括:通过指数移动平均线方法更新所述预定代码本。
6、在本申请一个实施方式中,采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化,以形成索引序列包括:利用包括编码器模型的矢量量化变分自编码器,将所述声学特征序列嵌入为隐藏序列;以及基于所述编码器模型,采用多个所述预定代码本对所述隐藏序列中的每个向量进行量化,以形成所述索引序列。
7、在本申请一个实施方式中,利用包括编码器模型的矢量量化变分自编码器,将所述声学特征序列嵌入为隐藏序列包括:按照预定时间分辨率阶段将所述声学特征序列转化为一组所述子序列;以及将一组所述子序列逐步地嵌入为所述隐藏序列。
8、在本申请一个实施方式中,所述隐藏序列包括与所述声学特征序列的所述子序列对应的多个子序列,所述隐藏序列的多个子序列包括第一子序列和第二子序列,其中所述第一子序列的时间分辨率阶段高于所述第二子序列的时间分辨率阶段,采用多个所述预定代码本对所述隐藏序列中的每个向量进行量化,以形成所述索引序列包括:采用分别与所述第一子序列和所述第二子序列对应的多个预定代码本,分别量化所述第一子序列和所述第二子序列;以及通过所述第一子序列的预测序列估计所述第二子序列。
9、在本申请一个实施方式中,采用多个所述预定代码本分别对每个所述子序列进行量化包括:从具有最高时间分辨率阶段的子序列开始逐渐地执行量化。
10、在本申请一个实施方式中,所述方法包括:利用基于快速高质量语音合成fastspeech的多阶段预测器,接收所述声学特征序列,并采用多个所述预定代码对所述声学特征序列中的每个向量进行量化。
11、本申请另一方面提供了语音合成系统,所述系统包括:预测器,被配置为采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化,以形成索引序列;以及声码器,被配置为将所述索引序列映射为声音波形,得到与所述输入文本对应的合成语音。
12、在本申请一个实施方式中,所述预测器被进一步被配置为:将所述声学特征序列转化为一组具有不同时间分辨率阶段的子序列;以及采用多个所述预定代码本分别对每个所述子序列进行量化。
13、在本申请一个实施方式中,所述预测器被进一步被配置为:采用损失函数对量化结果进行优化,其中所述损失函数包括均方误差和三重态损失。
14、在本申请一个实施方式中,所述预测器被进一步被配置为:通过指数移动平均线方法更新所述预定代码本。
15、在本申请一个实施方式中,所述预测器被进一步配置为:利用包括编码器模型的矢量量化变分自编码器,将所述声学特征序列嵌入为隐藏序列;以及基于所述编码器模型,采用多个所述预定代码本对所述隐藏序列中的每个向量进行量化,以形成所述索引序列。
16、在本申请一个实施方式中,所述矢量量化变分自编码器被进一步配置为:按照预定时间分辨率阶段将所述声学特征序列转化为一组所述子序列;以及将一组所述子序列逐步地嵌入为所述隐藏序列。
17、在本申请一个实施方式中,所述隐藏序列包括与所述声学特征序列的所述子序列对应的多个子序列,所述隐藏序列的多个子序列包括第一子序列和第二子序列,其中所述第一子序列的时间分辨率阶段高于所述第二子序列的时间分辨率阶段,所述矢量量化变分自编码器被进一步配置为:
18、通过所述第一子序列的预测序列估计所述第二子序列。
19、在本申请一个实施方式中,所述预测器被进一步被配置为:从具有最高时间分辨率阶段的子序列开始逐渐地执行量化。
20、在本申请一个实施方式中,所述预测器为基于快速高质量语音合成fastspeech的多阶段预测器。
21、本申请又一方面提供了一种电子设备,其包括至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如本申请一方面提供的任一项语音合成方法。
22、本申请又一方面提供了存储有计算机指令的非瞬时计算机可读存储介质,所述计算机指令用于使所述计算机执行如本申请一方面提供的任一项语音合成方法。
23、根据本申请至少一个实施方式提供的语音合成方法、系统电子设备和计算机可读存储介质,可减少真实音频数据的声学特征与其预测特征之间差异,使合成语音呈现出更好的保真度,并在粗粒度和细粒度上都呈现出更自然的韵律。
技术特征:
1.一种语音合成方法,其特征在于,所述语音合成方法包括:
2.根据权利要求1所述的语音合成方法,其中,采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化包括:
3.根据权利要求1或2所述的语音合成方法,其中,采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化包括:
4.根据权利要求1或2所述的语音合成方法,其中,采用多个
5.根据权利要求1或2所述的语音合成方法,其中,采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化,以形成索引序列包括:
6.根据权利要求5所述的语音合成方法,其中,利用包括编码器模型的矢量量化变分自编码器,将所述声学特征序列嵌入为隐藏序列包括:
7.根据权利要求6所述的语音合成方法,其中,所述隐藏序列包括与所述声学特征序列的所述子序列对应的多个子序列,所述隐藏序列的多个子序列包括第一子序列和第二子序列,其中所述第一子序列的时间分辨率阶段高于所述第二子序列的时间分辨率阶段,
8.根据权利要求2所述的语音合成方法,其中,采用多个所述预定代码本分别对每个所述子序列进行量化包括:
9.根据权利要求1或2所述的语音合成方法,其中,所述方法包括:
10.一种语音合成系统,其特征在于,所述系统包括:
11.根据权利要求10所述的系统,其中,所述预测器被进一步被配置为:
12.根据权利要求10或11所述的系统,其中,所述预测器被进一步被配置为:
13.根据权利要求10或11所述的系统,其中,所述预测器被进一步被配置为:
14.根据权利要求10或11所述的系统,其中,所述预测器被进一步配置为:
15.根据权利要求14所述的系统,其中,所述矢量量化变分自编码器被进一步配置为:
16.根据权利要求15所述的系统,其中,所述隐藏序列包括与所述声学特征序列的所述子序列对应的多个子序列,所述隐藏序列的多个子序列包括第一子序列和第二子序列,其中所述第一子序列的时间分辨率阶段高于所述第二子序列的时间分辨率阶段,所述矢量量化变分自编码器被进一步配置为:
17.根据权利要求11所述的系统,其中,所述预测器被进一步被配置为:
18.根据权利要求10或11所述的系统,其中,
19.一种电子设备,其特征在于,包括:
20.一种存储有计算机指令的非瞬时计算机可读存储介质,其特征在于,所述计算机指令用于使所述计算机执行权利要求1至9中任一项所述语音合成方法。
技术总结
本申请提供了一种语音合成方法及系统、电子设备和计算机可读存储介质。实现语音合成方法的系统包括预测器和声码器,语音合成方法包括:采用多个预定代码本对输入文本的声学特征序列中的每个向量进行量化,以形成索引序列;以及将索引序列映射为声音波形,得到与输入文本对应的合成语音。本申请提供的语音合成方法,可减少真实音频数据的声学特征与其预测特征之间的差异,使合成语音呈现出更好的保真度,并在粗粒度和细粒度上都呈现出更自然的韵律。
技术研发人员:蒙美玲,吴锡欣,郭浩瀚
受保护的技术使用者:博智感知交互研究中心有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!