模型训练方法、声学模型、语音合成系统和电子设备与流程
本申请涉及语音处理,特别涉及一种模型训练方法、声学模型、语音合成系统和电子设备。
背景技术:
1、目前,实现文字转换为语音功能的语音合成系统已经广泛部署于电子设备中,以满足用户对文字转换为语音功能的需求。例如,如图1所示,当用户在电子设备100的办公软件中打开文档后,并点击了语音朗读控件200,则会调用语音合成系统将文档中的文字转换为语音,以实现对文档进行朗读。
2、如图2所示,目前常用的将文字转换为语音的语音合成系统一般包括前端系统和后端系统,其中前端系统包括文本正则模块、韵律预测模块和注音模块;后端系统包括声学模型和声码器。其中,现有技术中声学模型一般采用自回归框架模型,如图3所示,自回归框架模型一般包括编码器、解码器和后处理模块,其中编码器包括嵌入层和序列特征提取(cbhg)模块,编码器用于对输入的文本进行特征整合,转化为高位抽象的特征向量。解码器包括注意力模型、双向长短时记忆网络(bidirectional long short-term memory,bilstm)、线性投影网络、双层的前处理网络和停止标记(stop token)模块,解码器用于对编码器的输出进行解码,使得输出特征的维度靠近标准输出特征。后处理模块用于对解码器输出特征的进一步矫正。
3、但是自回归框架声学模型语音合成速度较慢,导致合成语音的时间较长,进而导致增加设备功耗,且自回归框架声学模还容易出现重复吐词或漏词的情况。
技术实现思路
1、本申请实施例中提供一种模型训练方法、声学模型、语音合成系统和电子设备。
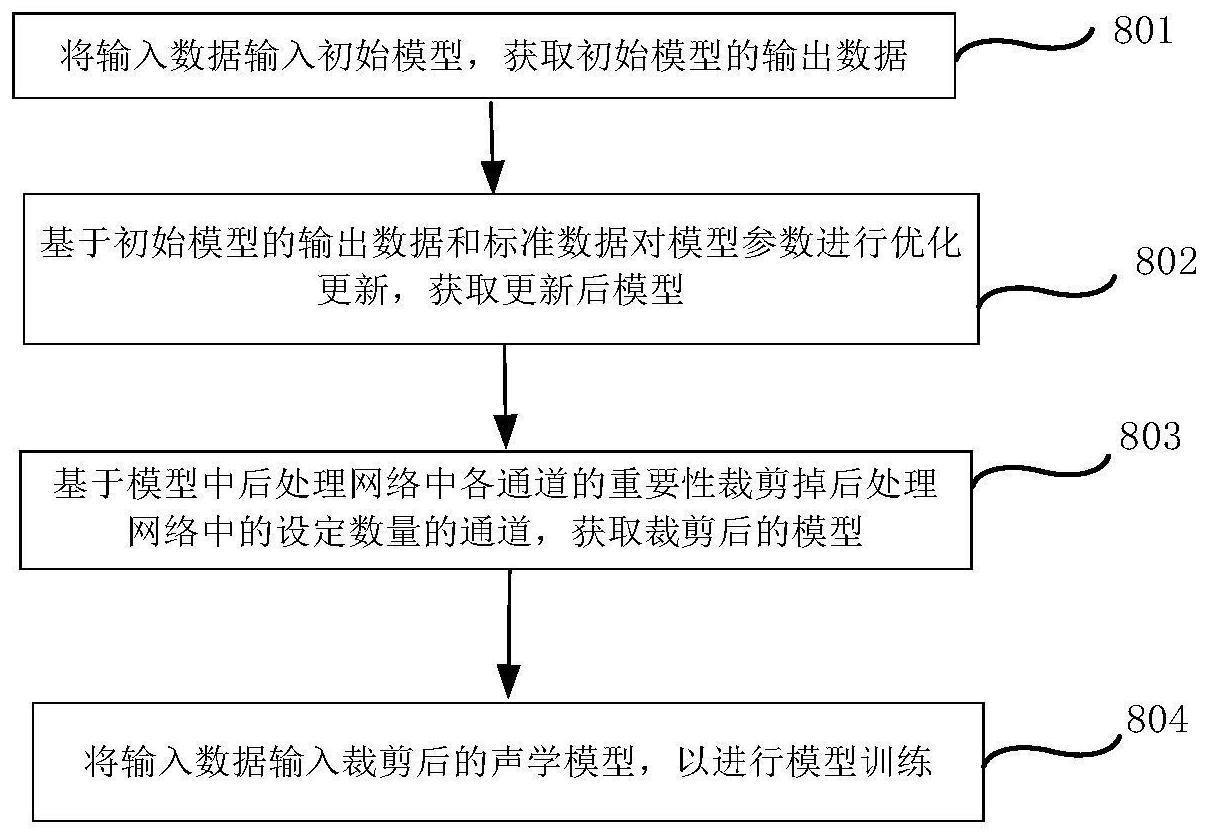
2、第一方面,本申请实施例提供一种模型训练方法,用于电子设备,所述方法包括:获取第一模型,将输入数据输入所述第一模型进行处理,获取所述输入数据对应的第一模型输出结果;获取所述输入数据对应的预设标准输出结果;基于所述第一模型输出结果和所述预设标准输出结果对所述第一模型进行优化,获取第二模型,所述第二模型包括第一后处理网络;确定所述第一后处理网络中各通道的重要性基于所述各通道的重要性对所述第一后处理网络中的部分通道进行裁剪,以获取第二后处理网络,并且基于所述第二后处理网络获得第三模型;确定所述第三模型满足模型要求,并将所述第三模型作为最终训练模型。
3、可以理解,后处理网络用于对声学模型中解码器的输出特征进行进一步矫正,因此,将后处理网络中的部分通道裁剪掉不会较大程度影响声学模型的最终输出结果。且本申请实施例中只裁剪后处理网络中重要性较低的通道,能够在减小后处理网络的占用内存的情况下,保证后处理网络的数据处理精度。在后处理网络的占用内存减小的情况下,整体声学模型的占用内存也能有效减小。
4、在一种可能的实现中,所述确定所述第三模型满足模型要求,包括:将所述输入数据输入所述第三模型进行处理,获取所述输入数据对应的第三模型输出结果;当所述第三模型输出结果和所述预设标准输出结果的相似度大于等于设定值,则确定第三模型满足模型要求。
5、在一种可能的实现中,所述基于所述第一后处理网络中各通道的重要性对所述第一后处理网络中的部分通道进行裁剪,以获取第二后处理网络,并且基于所述第二后处理网络获得第三模型;包括:获取所述第一后处理网络中各通道的输出特征;获取所述预设标准输出结果中各通道的输出特征;基于所述第一后处理网络各通道的输出特征与所述预设标准输出结果的各通道的输出特征的相似度,确定后处理网络中各通道的重要性特征值;基于所述第一后处理网络中各通道的重要性特征值对所述第一后处理网络中的设定数量的通道进行裁剪,获取所述第二后处理网络;基于所述第二处理网络获得所述第三模型。
6、在一种可能的实现中,所述基于所述第一后处理网络中各通道的重要性对所述第一后处理网络中的部分通道进行裁剪,以获取第二后处理网络,并且基于所述第二后处理网络获得第三模型;包括:获取所述第一后处理网络中各通道的数据量;基于所述第一后处理网络中各通道的数据量对所述第一后处理网络中的设定数量的通道进行裁剪,获取所述第二后处理网络;基于所述第二处理网络获得所述第三模型。
7、在一种可能的实现中,在确定所述第三模型不满足模型要求的情况下,基于所述第三模型输出结果和所述预设标准输出结果对所述第三模型进行优化,获取第四模型。
8、在一种可能的实现中,所述模型为声学模型,所述模型包括变量预测模块,所述变量预测模块包括音高音量预测模块;所述音高音量预测模块包括第一层结构、第二层结构、第三层结构、第四层结构和第五层结构;所述第五层结构包括第一线性层和第二线性层;所述第一层结构、所述第二层结构、所述第三层结构、所述第四层结构和所述第五层结构的第一线性层用于预测音高信息,所述第一层结构、所述第二层结构、所述第三层结构、所述第四层结构和所述第五层结构的第二线性层用于预测音量信息。
9、可以理解,本申请实施例中,音高音量预测模块采用复合网络机构,前四层共用参数,最后一层保持包括两个线性层,可以有效降低变量预测模块的占用内存,进而降低声学模型的整体内存。
10、在一种可能的实现中,所述第一层结构包括一维卷积层和relu算子,所述第二层结构包括线性投影网络和dropout算子,所述第三层结构包括一维卷积层和relu算子。
11、可以理解,本申请实施例中,扩展卷积网络和双向gru网络的组合结构相对于一些实施例中提供的声学模型采用transformer算子复杂度较低,占用内存更小,因此,更能有效降低整体声学模型的内存。
12、在一种可能的实现中,所述声学模型包括特征提取模块,所述特征提取模块包括扩展卷积网络和双向gru网络。
13、第二方面,本申请实施例提供一种声学模型,所述声学模型基于本申请提及的训练方法训练获取。本申请实施例中,声学模型采用并行框架模型。如图5所示,并行框架模型包括:编码器、解码器和后处理模块。
14、第三方面,本申请实施例提供一种语音合成系统,包括本申请提及的声学模型。
15、第四方面,本申请提供一种电子设备,包括:存储器,用于存储所述电子设备的一个或多个处理器执行的指令,以及所述处理器,是所述电子设备的一个或多个处理器之一,用于执行本申请提及的模型训练方法。
16、第五方面,本申请提供一种可读存储介质,所述可读介质上存储有指令,所述指令在电子设备上执行时使得所述电子设备执行本申请提及的模型训练方法。
17、第六方面,本申请提供一种计算机程序产品,包括:执行指令,所述执行指令存储在可读存储介质中,电子设备的至少一个处理器可以从所述可读存储介质读取所述执行指令,所述至少一个处理器执行所述执行指令使得所述电子设备执行本申请提及的模型训练方法。
技术特征:
1.一种模型训练方法,用于电子设备,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述确定所述第三模型满足模型要求,包括:
3.根据权利要求1所述的方法,其特征在于,所述基于所述第一后处理网络中各通道的重要性对所述第一后处理网络中的部分通道进行裁剪,以获取第二后处理网络,并且基于所述第二后处理网络获得第三模型;包括:
4.根据权利要求1所述的方法,其特征在于,所述基于所述第一后处理网络中各通道的重要性对所述第一后处理网络中的部分通道进行裁剪,以获取第二后处理网络,并且基于所述第二后处理网络获得第三模型;包括:
5.根据权利要求2所述的方法,其特征在于,在确定所述第三模型不满足模型要求的情况下,基于所述第三模型输出结果和所述预设标准输出结果对所述第三模型进行优化,以获取第四模型。
6.根据权利要求1-5任一项所述的方法,其特征在于,所述模型为声学模型,所述模型包括变量预测模块,所述变量预测模块包括音高音量预测模块;
7.根据权利要求6所述的方法,其特征在于,所述第一层结构包括一维卷积层和relu算子,所述第二层结构包括线性投影网络和dropout算子,所述第三层结构包括一维卷积层和relu算子。
8.根据权利要求1-5或7任一项所述的方法,其特征在于,所述声学模型包括特征提取模块,所述特征提取模块包括扩展卷积网络和双向gru网络。
9.一种声学模型,其特征在于,所述声学模型基于所述权利要求1-8任一项的模型训练方法训练获取。
10.一种语音合成系统,其特征在于,包括权利要求9所述的声学模型。
11.一种电子设备,其特征在于,包括:存储器,用于存储所述电子设备的一个或多个处理器执行的指令,以及所述处理器,是所述电子设备的一个或多个处理器之一,用于执行权利要求1-8任一项所述的模型训练方法。
12.一种可读存储介质,其特征在于,所述可读介质上存储有指令,所述指令在电子设备上执行时使得所述电子设备执行权利要求1-8任一项所述的模型训练方法。
13.一种计算机程序产品,包括:执行指令,所述执行指令存储在可读存储介质中,电子设备的至少一个处理器可以从所述可读存储介质读取所述执行指令,所述至少一个处理器执行所述执行指令使得所述电子设备执行权利要求1-8任一项所述的模型训练方法。
技术总结
本申请涉及语音处理技术领域,公开了一种模型训练方法、声学模型、语音合成系统和电子设备;方法包括:获取第一模型,将输入数据输入第一模型进行处理,获取输入数据对应的第一模型输出结果;获取输入数据对应的预设标准输出结果;基于第一模型输出结果和预设标准输出结果对第一模型进行优化,获取第二模型,第二模型包括第一后处理网络;确定第一后处理网络中各通道的重要性;基于各通道的重要性对第一后处理网络中的部分通道进行裁剪,以获取第二后处理网络,并且基于第二后处理网络获得第三模型;在确定第三模型满足模型要求的情况下,将第三模型作为最终训练模型。基于上述方案,能够在保证模型性能的同时有效减小模型的占用内存。
技术研发人员:龚雪飞
受保护的技术使用者:荣耀终端有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!