声纹识别模型训练方法、装置、电子设备及可读介质与流程
本发明涉及语音数据处理,尤其涉及声纹识别模型训练方法、装置、电子设备及可读介质。
背景技术:
1、声纹识别是一种借助声音完成对语音用户身份识别的技术,其已然成为一种高效的身份识别方法,在多种领域都有着广泛的应用。目前,对于声纹的识别通常通过声纹识别模型来实现。
2、但对于通话场景中的声纹识别,由于在实际场景中存在不同手机设备和不同背景噪音等影响因素,导致声纹识别模型在训练时使用的噪音数据无法匹配实际通话场景,存在噪音和信道不匹配等问题。
3、因此,需要一种训练声纹识别模型的方法来使声纹识别模型适配实际通话场景。
技术实现思路
1、本发明提供了一种声纹识别模型训练方法、装置、电子设备及可读介质,以训练声纹识别模型,使声纹识别模型适配实际通话场景。
2、根据本发明的一方面,提供了一种声纹识别模型训练方法,包括:
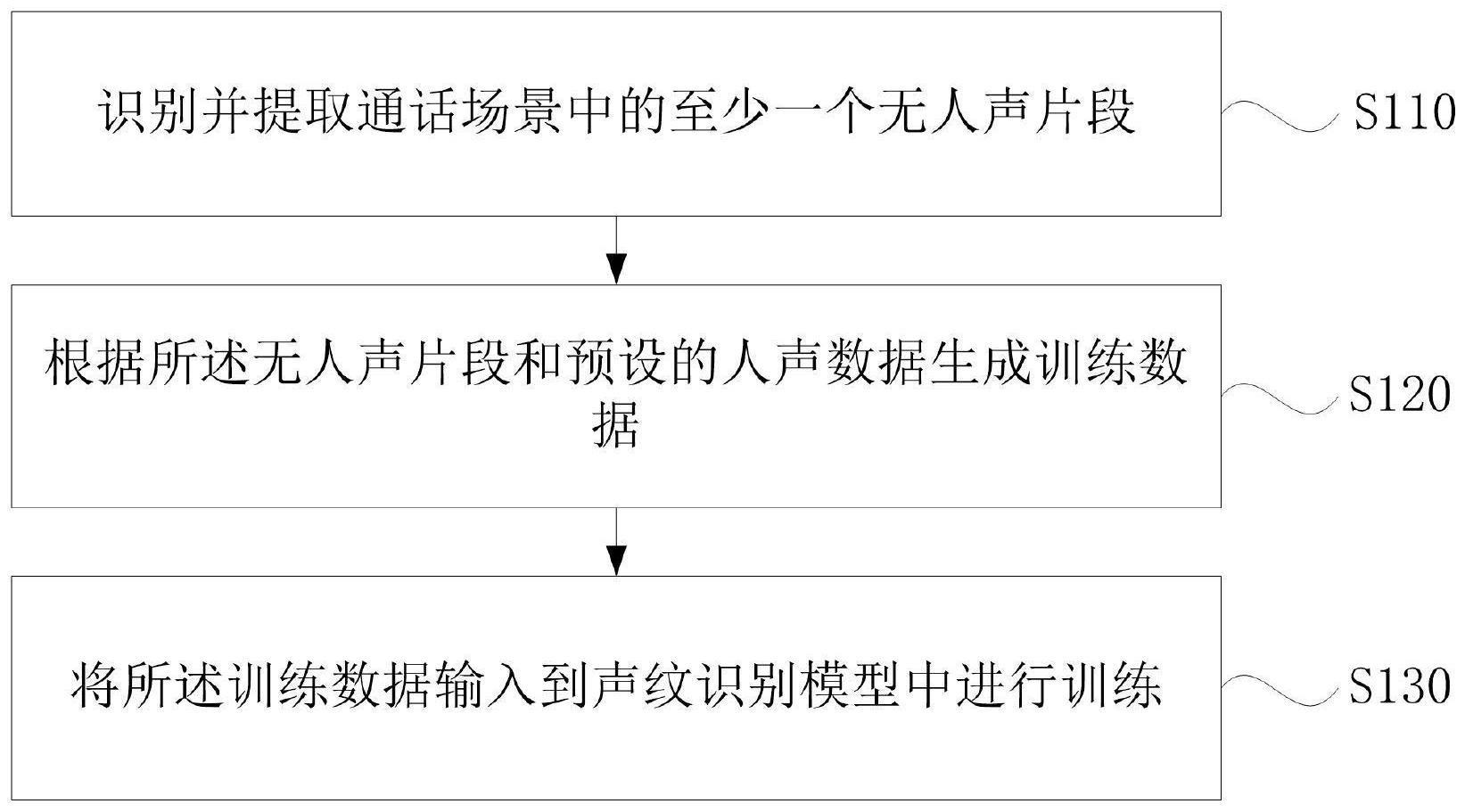
3、识别并提取通话场景中的至少一个无人声片段;
4、根据所述无人声片段和预设的人声数据生成训练数据;
5、将所述训练数据输入到声纹识别模型中进行训练。
6、可选的,所述识别并提取通话场景中的至少一个无人声片段,包括:
7、获取通话场景中的通话录音;
8、确定所述通话录音的频率信息;
9、根据预设的人声频率信息,确定所述频率信息中的至少一个人声片段;
10、从所述通话录音中截取所述人声片段外的录音片段,得到至少一个所述无人声片段。
11、可选的,所述根据所述无人声片段和预设的人声数据生成训练数据,包括:
12、对每个所述无人声片段,执行:
13、截取与当前无人声片段时长相同的目标人声数据;
14、将所述当前无人声片段与所述目标人声数据进行合成,得到所述训练数据。
15、可选的,所述将所述训练数据输入到声纹识别模型中进行训练,包括:
16、对所述声纹识别模型进行fine-tune处理;
17、设置所述声纹识别模型的学习率与正常学习率的对应关系;
18、将训练数据输入所述声纹识别模型中训练直至收敛。
19、可选的,每种所述人声数据对应一种声纹;相应的,该方法还包括:
20、当所述声纹识别模型从所述训练数据中识别出声纹后,与该训练数据对应的声纹进行验证;
21、根据验证结果对所述声纹识别模型进行修正。
22、可选的,该方法还包括:
23、通过所述声纹识别模型对待识别通话录音进行识别,得到声纹信息;
24、根据预设的声纹信息与用户信息的对应关系,对所述通话录音对应的用户进行识别。
25、可选的,通过所述声纹识别模型对待识别通话录音进行识别,得到声纹信息之后,该方法还包括:
26、当不存在所述声纹信息对应的用户信息时,确定通话录音对应的联系方式;
27、根据所述联系方式,通过外部通讯服务器中获取用户信息;
28、建立所述用户信息与所述声纹信息的对应关系。
29、根据本发明的另一方面,提供了一种声纹识别模型训练装置,包括:
30、无人声片段提取单元,用于识别并提取通话场景中的至少一个无人声片段;
31、训练数据生成单元,用于根据所述无人声片段和预设的人声数据生成训练数据;
32、训练数据输入单元,用于将所述训练数据输入到声纹识别模型中进行训练。
33、根据本发明的另一方面,提供了一种电子设备,所述电子设备包括:
34、至少一个处理器;以及
35、与所述至少一个处理器通信连接的存储器;其中,
36、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例所述的声纹识别模型训练方法。
37、根据本发明的另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现本发明任一实施例所述的声纹识别模型训练方法。
38、本发明实施例的技术方案,通过识别并提取通话场景中的至少一个无人声片段,根据所述无人声片段和预设的人声数据生成训练数据,将所述训练数据输入到声纹识别模型中进行训练。本发明的方案利用通话场景中大量存在的背景无人声片段,通过预设的人声数据生成训练数据不断对声纹识别模型进行训练,提高声纹识别的准确率,使声纹识别模型适配通话场景。
39、应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.声纹识别模型训练方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述识别并提取通话场景中的至少一个无人声片段,包括:
3.根据权利要求1所述的方法,其特征在于,所述根据所述无人声片段和预设的人声数据生成训练数据,包括:
4.根据权利要求1所述的方法,其特征在于,所述将所述训练数据输入到声纹识别模型中进行训练,包括:
5.根据权利要求1所述的方法,其特征在于,每种所述人声数据对应一种声纹;相应的,进一步包括:
6.根据权利要求1所述的方法,其特征在于,进一步包括:
7.根据权利要求6所述的方法,其特征在于,通过所述声纹识别模型对待识别通话录音进行识别,得到声纹信息之后,进一步包括:
8.声纹识别模型训练装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现权利要求1-7中任一项所述的声纹识别模型训练方法。
技术总结
本发明公开了声纹识别模型训练方法、装置、电子设备及可读介质。方法包括:识别并提取通话场景中的至少一个无人声片段;根据所述无人声片段和预设的人声数据生成训练数据;将所述训练数据输入到声纹识别模型中进行训练。本发明的方案利用通话场景中大量存在的背景无人声片段,通过预设的人声数据生成训练数据不断对声纹识别模型进行训练,提高声纹识别的准确率,使声纹识别模型适配通话场景。
技术研发人员:张超,王乐,滕勇,丁希剑,李健
受保护的技术使用者:小沃科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!