域适应的声纹特征识别方法及系统与流程
本发明涉及声纹识别,特别是涉及一种域适应的声纹特征识别方法及系统。
背景技术:
1、在声纹识别系统中,识别的准确性取决于大量标记培训数据的可用性,这些数据通常是数百小时的语音录音,其中包括来自数千名说话者的多会话录音。这些录音采集到之后通常是存储在声纹数据底库中,便于后续的声纹识别操作。在收集录音的时候,往往是通过各个应用程序采集的,为每个应用程序收集如此大的域内数据作为新的关注域,成本较高,且已经存在的大多数可用资源丰富的数据将不匹配新的关注域,即大多数将是域外数据。
2、然而,当声纹识别系统使用的域数据与训练数据使用的域数据属于不同的领域时,会出现出现域不匹,从而存在声纹识别性能较低的问题。
技术实现思路
1、基于此,为了解决上述技术问题,提供一种域适应的声纹特征识别方法及系统,可以提高声纹识别的识别性能。
2、一种域适应的声纹特征识别方法,所述方法包括:
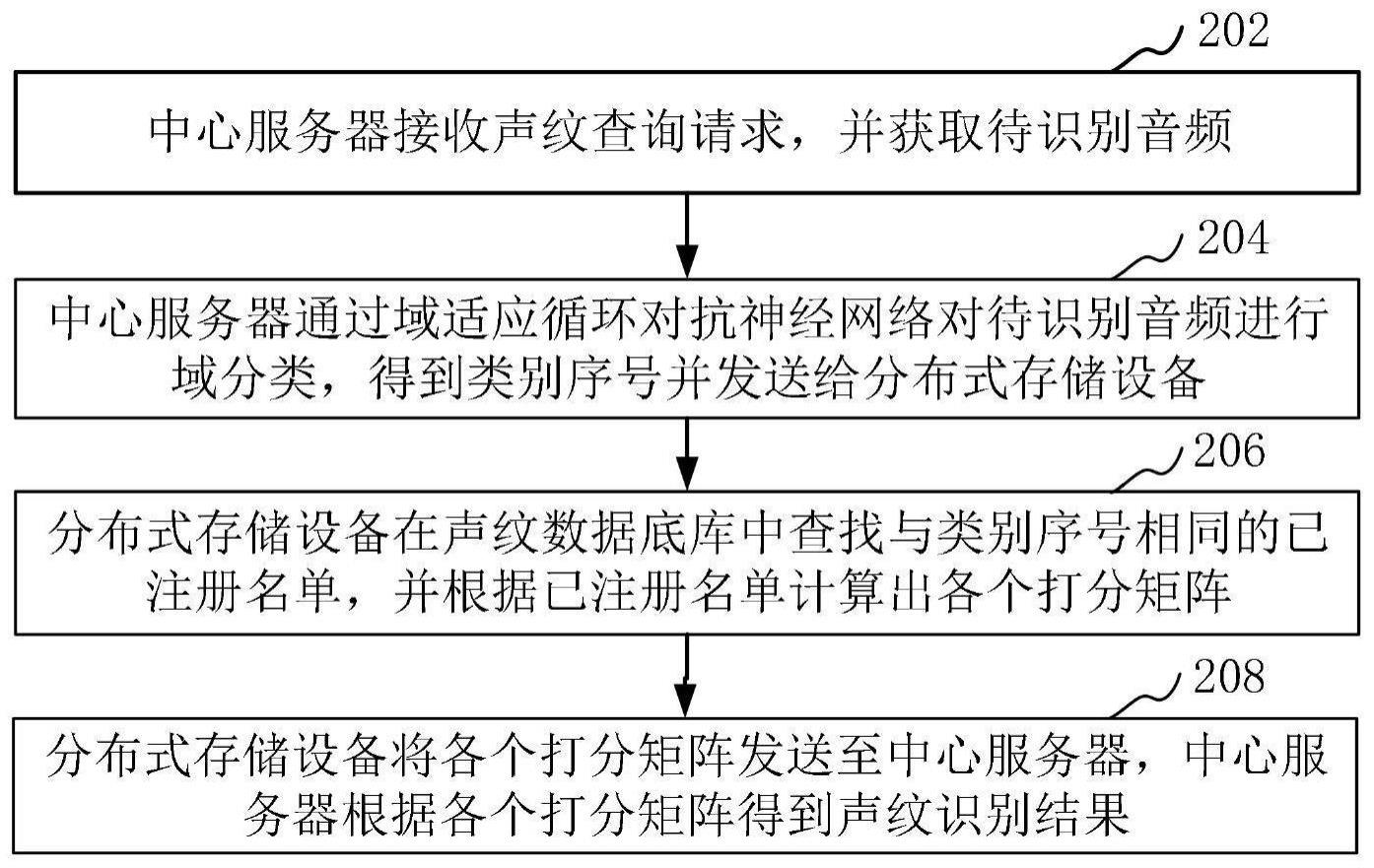
3、中心服务器接收声纹查询请求,并获取待识别音频;
4、所述中心服务器通过域适应循环对抗神经网络对所述待识别音频进行域分类,得到类别序号并发送给分布式存储设备;
5、所述分布式存储设备在声纹数据底库中查找与所述类别序号相同的已注册名单,并根据所述已注册名单计算出各个打分矩阵;
6、所述分布式存储设备将各个所述打分矩阵发送至所述中心服务器,所述中心服务器根据各个所述打分矩阵得到声纹识别结果。
7、在其中一个实施例中,所述中心服务器通过域适应循环对抗神经网络对所述待识别音频进行域分类,包括:
8、所述中心服务器提取所述待识别音频中的i-vector,并将所述i-vector输入到所述域适应循环对抗神经网络中;
9、通过i-vector提取器初步提取所述待识别音频中的特征;
10、所述域适应循环对抗神经网络通过编码器提取所述待识别音频中的声纹信息和域信息;
11、根据所述特征、所述声纹信息和域信息通过余弦相似度计算域分类结果。
12、在其中一个实施例中,所述域适应循环对抗神经网络的训练过程包括:
13、基于深度神经网络构建声纹编码器;
14、根据所述声纹编码器训练所述i-vector提取器、训练掩码循环生成对抗模型。
15、在其中一个实施例中,训练所述i-vector提取器,包括:
16、获取源域语音数据,并从所述原域语音数据中提取出声纹特征参数mfcc;
17、根据所述声纹特征参数mfcc训练通用背景模型;
18、根据所述通用背景模型训练i-vector提取器;
19、通过所述i-vector提取器提取训练i-vector,并根据所述训练i-vector训练特征映射模型plda,通过所述特征映射模型plda将所述训练i-vector映射至隐空间并完成识别。
20、在其中一个实施例中,训练掩码循环生成对抗模型,包括:
21、将所述训练i-vector作为掩码循环生成对抗模型的双流训练输入,得到具有目标域至源域的域迁移能力的生成器模型参数;
22、根据所述生成器模型参数训练得到掩码循环生成对抗模型。
23、在其中一个实施例中,所述根据所述训练i-vector训练特征映射模型plda,包括:
24、将所述训练i-vector作为输入以训练对抗分离性自编码器模型;
25、通过所述对抗分离性自编码器模型提取出所述源域语音数据中的广义向量特征,并根据所述广义向量特征训练特征映射模型plda。
26、在其中一个实施例中,所述根据所述已注册名单计算出各个打分矩阵,包括:
27、根据所述已注册名单将每条录音通过声纹编码器编码并归一化为查询声纹,并根据所述查询声纹构成各个查询矩阵;
28、根据所述声纹数据底库中的声纹编码构成为各个底库矩阵;
29、根据各个所述查询矩阵、各个所述底库矩阵,基于cannon算法利用多处理器并行技术计算得到各个打分矩阵。
30、一种域适应的声纹特征识别系统,所述系统包括中心服务器、分布式存储设备,其中:
31、所述中心服务器,用于接收声纹查询请求,并获取待识别音频;
32、所述中心服务器,还用于通过域适应循环对抗神经网络对所述待识别音频进行域分类,得到类别序号并发送给分布式存储设备;
33、所述分布式存储设备,用于在声纹数据底库中查找与所述类别序号相同的已注册名单,并根据所述已注册名单计算出各个打分矩阵;
34、所述分布式存储设备,还用于将各个所述打分矩阵发送至所述中心服务器,所述中心服务器根据各个所述打分矩阵得到声纹识别结果。
35、上述域适应的声纹特征识别方法及系统,中心服务器接收声纹查询请求,并获取待识别音频;所述中心服务器通过域适应循环对抗神经网络对所述待识别音频进行域分类,得到类别序号并发送给分布式存储设备;所述分布式存储设备在声纹数据底库中查找与所述类别序号相同的已注册名单,并根据所述已注册名单计算出各个打分矩阵;所述分布式存储设备将各个所述打分矩阵发送至所述中心服务器,所述中心服务器根据各个所述打分矩阵得到声纹识别结果。通过使用域适应循环对抗神经网络进行域分类,从而根据类别序号计算打分矩阵并得到声纹识别结果,当数据属于不同域时,不会出现域不匹配的现象,提高了声纹识别的识别性能。
技术特征:
1.一种域适应的声纹特征识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的域适应的声纹特征识别方法,其特征在于,所述中心服务器通过域适应循环对抗神经网络对所述待识别音频进行域分类,包括:
3.根据权利要求2所述的域适应的声纹特征识别方法,其特征在于,所述域适应循环对抗神经网络的训练过程包括:
4.根据权利要求3所述的域适应的声纹特征识别方法,其特征在于,训练所述i-vector提取器,包括:
5.根据权利要求4所述的域适应的声纹特征识别方法,其特征在于,训练掩码循环生成对抗模型,包括:
6.根据权利要求4所述的域适应的声纹特征识别方法,其特征在于,所述根据所述训练i-vector训练特征映射模型plda,包括:
7.根据权利要求1所述的域适应的声纹特征识别方法,其特征在于,所述根据所述已注册名单计算出各个打分矩阵,包括:
8.一种域适应的声纹特征识别系统,其特征在于,所述系统包括中心服务器、分布式存储设备,其中:
9.根据权利要求8所述的域适应的声纹特征识别系统,其特征在于,所述中心服务器还用于通过i-vector提取器初步提取所述待识别音频中的特征;所述域适应循环对抗神经网络通过编码器提取所述待识别音频中的声纹信息和域信息;根据所述特征、所述声纹信息和域信息通过余弦相似度计算域分类结果。
10.根据权利要求9所述的域适应的声纹特征识别系统,其特征在于,所述中心服务器还用于基于深度神经网络构建声纹编码器;根据所述声纹编码器训练所述i-vector提取器、训练掩码循环生成对抗模型。
技术总结
本方案涉及一种域适应的声纹特征识别方法及系统。所述方法包括:中心服务器接收声纹查询请求,并获取待识别音频;所述中心服务器通过域适应循环对抗神经网络对所述待识别音频进行域分类,得到类别序号并发送给分布式存储设备;所述分布式存储设备在声纹数据底库中查找与所述类别序号相同的已注册名单,并根据所述已注册名单计算出各个打分矩阵;所述分布式存储设备将各个所述打分矩阵发送至所述中心服务器,所述中心服务器根据各个所述打分矩阵得到声纹识别结果。通过使用域适应循环对抗神经网络进行域分类,从而根据类别序号计算打分矩阵并得到声纹识别结果,当数据属于不同域时,不会出现域不匹配的现象,提高了声纹识别的识别性能。
技术研发人员:张星东,赵胜,丁卓
受保护的技术使用者:南京龙垣信息科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!