一种多语音下的语音转写方法与流程
1.本发明涉及语音转写策略处理技术领域,具体是一种多语音下的语音转写方法。
背景技术:
2.像视频会议或者现场会议,会设置多个话筒,每个话筒前有对应的一个与会者,这些与会者可能会同时使用各种的话筒进行发言,也即有多个语音输入。为了将发言的语音转写为文字输出,例如,在大屏上将发言的语音同步转写为文字显示出来,以便于与会者看到文字,特别是针对聋哑人来说,更能清楚指定发言内容。目前对这种多语音转写文字的处理方案中,需要在每一个话筒上集成一个转写引擎,从而为每一个话筒所接收到的语音进行转写并输出文字。但这种处理方案,需要多个转写引擎,带来的成本较高。
3.正常情况下,声音最大的与会者的发言更能够被其他与会者所听到,声音越小,越难被其他与会者所听到。基于此,发明人实际研究发现,当有多人多话筒需要进行语音转写时,只需要将声音最大的进行转写即可,能够满足会议要求,因此,需要有一种基于此的语音转写方案,以便于能够以较低成本的实现语音转写并且满足会议发言听清楚的要求。
技术实现要素:
4.针对现有技术的不足,本发明的目的是提供一种多语音下的语音转写方法,其能够解决背景技术所描述的问题。
5.实现本发明的目的的技术方案为:一种多语音下的语音转写方法,包括如下步骤:
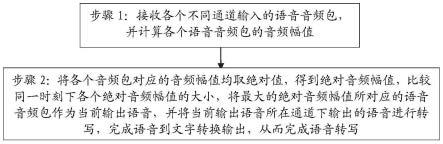
6.步骤1:接收各个不同通道输入的语音音频包,并计算各个语音音频包的音频幅值;
7.步骤2:将各个音频包对应的音频幅值均取绝对值,得到绝对音频幅值,比较同一时刻下各个绝对音频幅值的大小,将最大的绝对音频幅值所对应的语音音频包作为当前输出语音,并将当前输出语音所在通道下输出的语音进行转写,完成语音到文字转换输出,从而完成语音转写。
8.进一步地,所述计算各个语音音频包的音频幅值,其具体实现包括以下步骤:
9.步骤1-1:将接收到的语音音频包从字节数组转换为整形数组;
10.步骤1-2:从语音音频包中的第一个数组开始,将当前数组与下一个数组进行位移操作,得到位移数组,然后将位移数组与下一个数组进行位移操作,直至与最后一个数组进行位移操作,从而得到最终的位移数组;
11.步骤1-3:将最终的位移数组进行求和,并且将求和结果除以语音音频包的大小,从而得到语音音频包的音频幅值。
12.进一步地,整形数组可以用[]uni t8或[]uni t16表示,中括号[]同样表示语音数据。
[0013]
进一步地,若当前输出语音与上一次的输出语音不是来自同一个通道,则将当前输出语音所对应通道下的声音作为当前输出语音,完成语音转写。
[0014]
进一步地,由各个语音通道输入带动语音音频包发送给服务器,由服务器接收并存储,并在服务器内完成计算各个语音音频包的音频幅值。
[0015]
本发明的有益效果为:本发明只需要一个语音转写引擎,即可实现对多人多话筒语音输入下的语音转写过程,大大节省成本,并且能够实施判断哪个话筒的声音最大,进而将声音最大的声音进行转写,能够更符合实际情况,和与会者只能清楚听到音量最大的声音的实际情况更相符。本发明可以作为一个语音转写程序软件,写入集成在包括语音等处理的新一代信息处理终端上,能够有效应用在在线会议或者现场会议的语音转写。
附图说明
[0016]
图1为本发明的流程示意图;
[0017]
图2为实现计算语音音频波的音频幅值的流程示意图。
具体实施方案
[0018]
下面,结合附图以及具体实施方案,对本发明做进一步描述:
[0019]
如图1和图2所示,一种多语音下的语音转写方法,包括如下步骤:
[0020]
步骤1:接收各个不同通道输入的语音音频包,并计算各个语音音频包的音频幅值。
[0021]
在本步骤中,每一个话筒对应一个语音通道,也即每一个话筒均可输入语音,产生对应的语音音频包。当然,通道也可以是其他终端,例如手机、麦克风等可完成语音输入的设备终端。
[0022]
在一个可选的实施方式中,由话筒等各个语音通道输入带动语音音频包发送给服务器,由服务器接收并存储,并在服务器内完成计算各个语音音频包的音频幅值。例如,服务器建立与各个话筒的通信连接,即可监听并接收来自话筒发送过来的语音音频,语音音频以音频包发生给服务器,服务器接收到各个话筒队队员的语音音频包。
[0023]
其中,同一时间时刻下,若有多个与会者进行发言,服务器会在同一时刻下接收到各个话筒所输入的语音音频包。
[0024]
所述计算各个语音音频包的音频幅值,其具体实现包括以下步骤:
[0025]
步骤1-1:将接收到的语音音频包从字节数组转换为整形数组。
[0026]
语音音频包默认为字节数组,即[]byte来表示,中括号[]来表示语音数据,整形数组可以用[]uni t8或[]uni t16表示,中括号[]同样表示语音数据。
[0027]
步骤1-2:从语音音频包中的第一个数组开始,将当前数组与下一个数组进行位移操作,得到位移数组,然后将位移数组与下一个数组进行位移操作,直至与最后一个数组进行位移操作,从而得到最终的位移数组。
[0028]
在本步骤中,假设当前数组为a,为语音音频包中的第i个语音音频包,也即用a[i]表示,数组a的整形数组类型为uint16,则进行位移操作并得到位移数组s3的指令为:s=(uint16(a[i])《《8)|uint16(a[i+1])。若s2=s&(1《《15),s2不为零,则s3=int16(int32(s2)-(int32(1)《《16),否则s3=int16(0)。最终得到一个由多个位移数组s3构成的数组,最终的数组也即是最终的位移数组。
[0029]
步骤1-3:将最终的位移数组进行求和,并且将求和结果除以语音音频包的大小
(语音音频包的大小也即是接收到的[]byte的包大小),从而得到语音音频包的音频幅值,音频幅值的类型为float64。
[0030]
步骤2:将各个音频包对应的音频幅值均取绝对值,得到绝对音频幅值,比较同一时刻下各个绝对音频幅值的大小,将最大的绝对音频幅值所对应的语音音频包作为当前输出语音,并将当前输出语音所在话筒下输出的语音进行转写,完成语音到文字转换输出,从而完成语音转写。
[0031]
在本步骤中,也即是同一时刻所接收到的语音包中,将音频幅值最大(也即是发言声音最大)的语音音频包进行转写,从而只需要一个转写引擎即可完成多人多语音下的语音转写,能够有效降低成本。
[0032]
在一个可选的实施方式中,若当前输出语音与上一次的输出语音不是来自同一个通道(也即不是来自同一个话筒),则将当前输出语音所对应的话筒下的声音作为当前输出语音,也即将该话筒下的语音进行转写,完成语音转写。
[0033]
本发明只需要一个语音转写引擎,即可实现对多人多话筒语音输入下的语音转写过程,大大节省成本,并且能够实施判断哪个话筒的声音最大,进而将声音最大的声音进行转写,能够更符合实际情况,和与会者只能清楚听到音量最大的声音的实际情况更相符。本发明可以作为一个语音转写程序软件,写入集成在包括语音等处理的新一代信息处理终端上,能够有效应用在在线会议或者现场会议的语音转写。
[0034]
本说明书所公开的实施例只是对本发明单方面特征的一个例证,本发明的保护范围不限于此实施例,其他任何功能等效的实施例均落入本发明的保护范围内。对于本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及变形,而所有的这些改变以及变形都应该属于本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1