一种确定鼾声信号的方法、装置、电子设备和存储介质与流程
本发明涉及信号处理领域,尤其涉及一种确定鼾声信号的方法、装置、电子设备和存储介质。
背景技术:
1、鼾声是入睡后发出的粗重鼻息声。打鼾不仅困扰用户本人、影响同伴,还会对用户本人健康造成威胁。
2、对于鼾声段检测,目前少有能应用于嵌入式系统的实时检测方法,多数是后处理、模型和参数固定的方法,例如高斯混合模型、隐马尔科夫模型,更复杂的还有聚类、支持向量机等机器学习算法甚至深度学习算法,这些算法计算复杂、实时性差,深度学习算法甚至需要服务器级别的计算和存储资源,很难在嵌入式系统上实现。
3、因此,亟需一种可以在嵌入式系统上实现实时鼾声信号检测的方法。
技术实现思路
1、为了解决现有技术的问题,本发明实施例提供了一种确定鼾声信号的方法、装置、电子设备和存储介质。技术方案如下:
2、根据本发明的一方面,提供了一种确定鼾声信号的方法,所述方法包括:
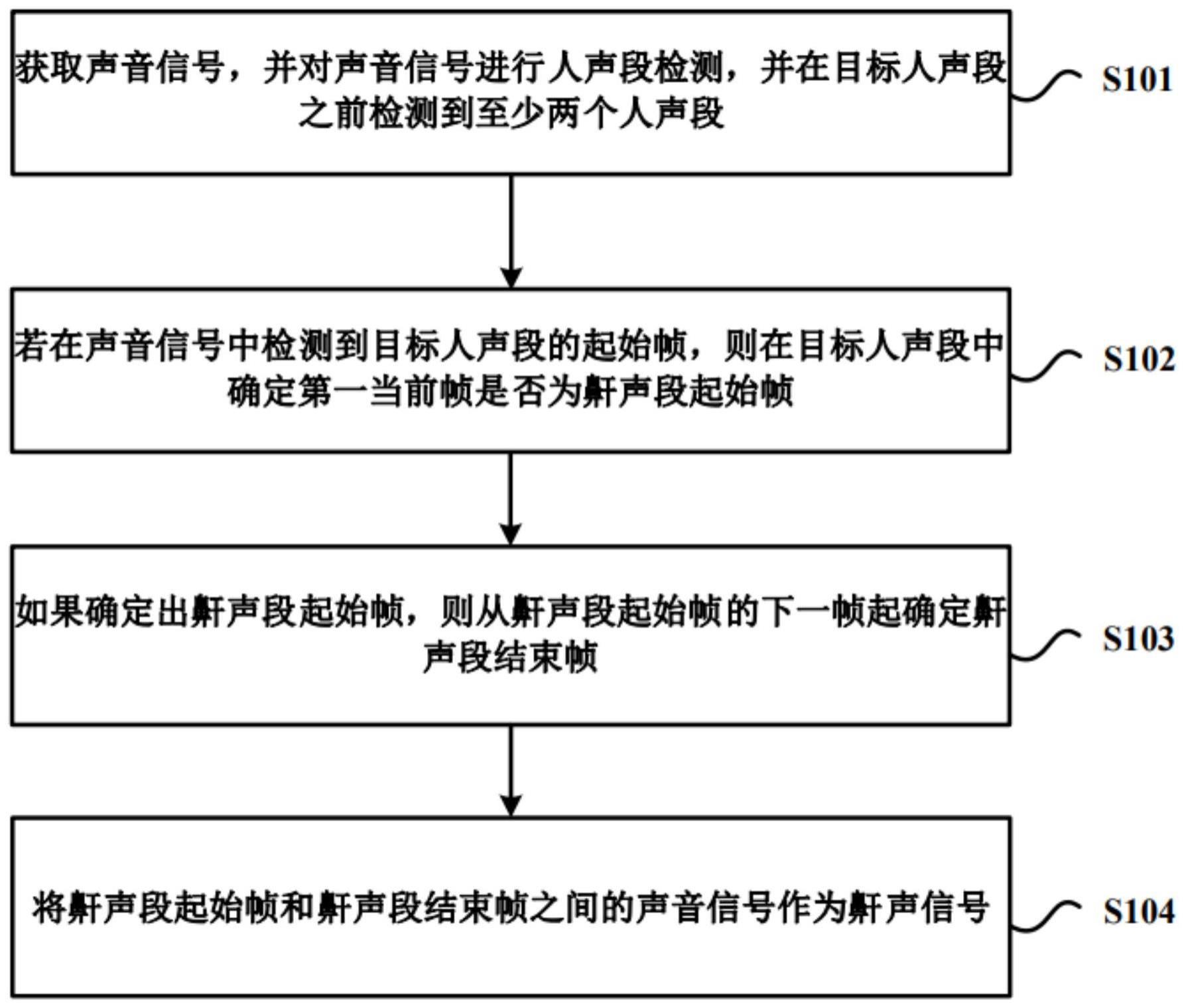
3、获取声音信号,并对所述声音信号进行人声段检测,并在目标人声段之前检测到至少两个人声段;
4、若在所述声音信号中检测到目标人声段的起始帧,则在所述目标人声段中确定第一当前帧是否为鼾声段起始帧;
5、如果确定出鼾声段起始帧,则从所述鼾声段起始帧的下一帧起确定鼾声段结束帧;
6、将所述鼾声段起始帧和所述鼾声段结束帧之间的声音信号作为鼾声信号。
7、根据本发明的另一方面,提供了一种确定鼾声信号的装置,所述装置包括:
8、获取模块,用于获取声音信号,并对所述声音信号进行人声段检测,并在目标人声段之前检测到至少两个人声段;
9、第一确定模块,用于若在所述声音信号中检测到目标人声段的起始帧时,则在所述目标人声段中确定第一当前帧是否为鼾声段起始帧;
10、第二确定模块,用于如果确定出鼾声段起始帧,则从所述鼾声段起始帧的下一帧起确定鼾声段结束帧;将所述鼾声段起始帧和所述鼾声段结束帧之间的声音信号作为鼾声信号。
11、根据本发明的另一方面,提供了一种电子设备,包括:
12、处理器;以及
13、存储程序的存储器,
14、其中,所述程序包括指令,所述指令在由所述处理器执行时使所述处理器执行上述确定鼾声信号的方法。
15、根据本发明的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使计算机执行上述确定鼾声信号的方法。
16、本发明中,实时采集声音信号后,可以实时地进行人声段检测,确定声音信号中的人声段,并在确定出至少两个人声段后,从目标人声段的起始帧开始,逐帧检测鼾声段起始帧和鼾声段结束帧。由于上述处理的计算量相较于高斯混合模型、隐马尔科夫模型、聚类模型、支持向量机等机器学习算法的计算量较小,可以在嵌入式系统上实现实时的鼾声信号检测。
技术特征:
1.一种确定鼾声信号的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,当所述第一当前帧为所述目标人声段的起始帧时,所述在所述目标人声段中确定第一当前帧是否为鼾声段起始帧,包括:
3.根据权利要求2所述的方法,其特征在于,基于所述至少两个人声段与所述目标人声段的起始帧的预设特性的相似性或鼾声特性,确定所述目标人声段的起始帧是否为鼾声段起始帧,包括:
4.根据权利要求2所述的方法,其特征在于,基于所述至少两个人声段与所述目标人声段的起始帧的预设特性的相似性和鼾声特性,确定所述目标人声段的起始帧是否为鼾声段起始帧,包括:
5.根据权利要求3或4任一项所述的方法,其特征在于,
6.根据权利要求5所述的方法,其特征在于,对于频谱相似性,所述计算所述目标人声段的起始帧的相似性得分,进一步包括:
7.根据权利要求3或4任一项所述的方法,其特征在于,
8.根据权利要求7所述的方法,其特征在于,所述方法还包括:
9.根据权利要求1所述的方法,其特征在于,
10.根据权利要求9所述的方法,其特征在于,所述方法还包括:
11.根据权利要求1所述的方法,其特征在于,所述至少两个人声段中至少检测到一段鼾声信号。
12.根据权利要求1所述的方法,其特征在于,所述从所述鼾声段起始帧的下一帧起确定鼾声段结束帧,包括:
13.根据权利要求12所述的方法,其特征在于,所述确定所述第二当前帧是否为鼾声段结束帧,包括:
14.根据权利要求9或13任一所述的方法,其特征在于,所述方法还包括:
15.一种确定鼾声信号的装置,其特征在于,所述装置包括:
16.一种电子设备,包括:
17.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使计算机执行根据权利要求1-14中任一项所述的方法。
技术总结
本发明提供一种确定鼾声信号的方法、装置、电子设备和存储介质,属于信号处理领域。方法包括:获取声音信号,并对所述声音信号进行人声段检测,并在目标人声段之前检测到至少两个人声段;若在所述声音信号中检测到目标人声段的起始帧,则在所述目标人声段中确定第一当前帧是否为鼾声段起始帧;如果确定出鼾声段起始帧,则从所述鼾声段起始帧的下一帧起确定鼾声段结束帧;将所述鼾声段起始帧和所述鼾声段结束帧之间的声音信号作为鼾声信号。采用本发明,可以在嵌入式系统上实现实时的鼾声信号检测。
技术研发人员:张虎
受保护的技术使用者:深圳市倍轻松科技股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!