一种基于声纹特征筛选及变换域二次特征提取的分类方法
本发明属于机器学习、数据表示与分类,尤其涉及一种基于声纹特征筛选及变换域二次特征提取的分类方法。
背景技术:
1、随着社会发展和人们工作、生活节奏的不断加快,由社会各方面因素造成的心理压力使得大众心理疾病患病率持续激增,在众多心理疾病中,抑郁症、焦虑症、多动症等为情绪障碍的典型疾病类型,已经成为本世纪影响人类身心健康的主要危险因素之一。据世界卫生组织的统计数据显示,抑郁症在全球20个主要自杀原因中排名首位,全球有3.5亿人被诊断患有抑郁症,患病率约为4.4%,自杀率高达1.5%,每年由抑郁症和焦虑症导致的生产力丧失使得全球经济损失近1万亿美元。多动症的比例在儿童患病人群中高达20%以上。并且,情绪障碍疾病不仅会严重影响个人的身体健康,也会严重阻碍社会的发展。因此,不管是从个人还是社会方面考虑,情绪障碍类疾病的早诊断早治疗都是必须解决的重点问题,具有实际应用价值。
2、常见的情绪类辅助诊断工具有两种,一种是诊断治疗手册,另一种是症状评定量表,这些诊断方法的主观因素较强,导致情绪类疾病的诊疗标准不客观以及漏诊和误诊问题严重。
3、本发明拟从语音数据的声纹特征角度出发,结合特征筛选、域变换、二次特征提取、特征融合以及分类,致力于通过客观数据特征区分抑郁症及正常人群,进而推广到其他情绪障碍类疾病的分类,提升分类的准确性,以利于未知患者的辅助诊断,辅助临床诊疗及减轻医生工作量。
技术实现思路
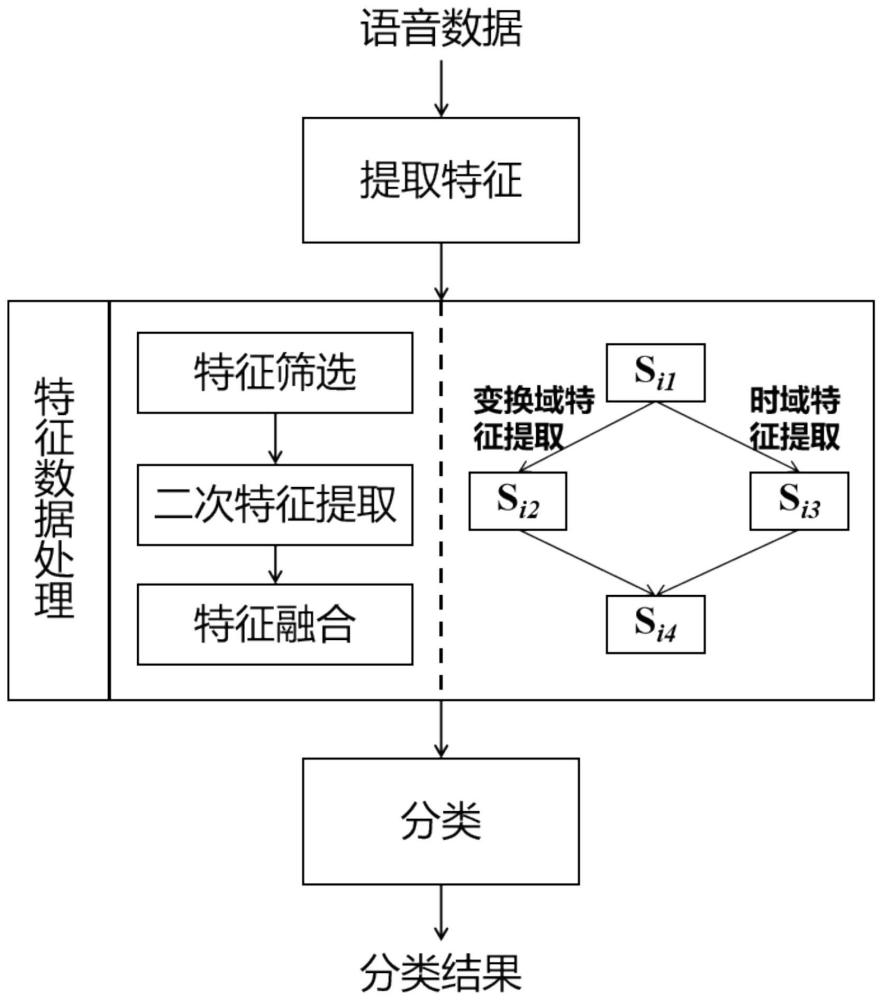
1、本发明针对常用的辅助诊断工具依托于诊断治疗手册及症状评定量表存在主观性强,导致分类准确率低,进而出现漏诊和误诊严重的技术缺陷,提出了一种基于声纹特征筛选及变换域二次特征提取的分类方法,所述方法首先对语音数据提取多种特征数据,所述特征数据经过处理后得到待分类数据,对所述待分类数据进行分类得到分类结果;所述特征数据的处理过程包括特征筛选、二次特征提取及特征融合;所述二次特征提取包括变换域特征提取及时域特征提取。
2、为了达到上述目的,采取如下技术方案:
3、所述种基于声纹特征筛选及变换域二次特征提取的分类方法,包括:
4、s1、遍历语音进行特征提取,分别得到每条语音对应的特征数据;
5、所述特征数据,包括该条语音的能量特征、谱特征及韵律特征;
6、s2、遍历语音对应的特征数据进行特征筛选,得到每条语音对应的筛选后特征数据;
7、s3、将筛选后特征数据进行二次特征提取,得到变换域特征及时域特征;
8、所述二次特征提取,包括变换域特征提取及时域特征提取;
9、所述变换域特征提取,包括小波变换、经验模态分解及局部均值分解;
10、所述时域特征提取,包括求均值、求标准差、求偏度、求峭度、求最值、求峰峰值、求均方根、求振幅因数、求波形因数、求冲击因数、求裕度因数及求能量;
11、s4、将s3得到的变换域特征及时域特征进行特征拼接,得到待分类数据并分类,得到分类结果。
12、s1所述谱特征,包括rasta听觉谱、梅尔倒谱系数、谱能量、谱方差、谱流量、谱倾斜、谱熵及谱峭度;所述梅尔倒谱系数,即mel frequency cepstrum coefficient,简称为mfcc;所述基频,即fundamental frequency,简称f0。
13、s1所述能量特征,包括听觉谱的和、相对光谱滤波后听觉谱的和、均方根能量及过零率;所述韵律特征,包括基频、发声概率、频率微扰及振幅微扰。
14、s1所述一条语音为某人的y条语音中的一条且称某人y条语音统称为一个样本;样本的总数为x,x个样本中包括m个正常人和n个已确诊的抑郁症患者;x个样本中的所有语音条数为(m+n)×y=x×y。
15、所述每条语音的特征数据长度为l。
16、s2所述特征筛选采用fisher准则,具体步骤如下:
17、1)将所有特征分为j个特征块,初始化特征块序号h为1;
18、2)计算第h个特征块内两类样本的均值向量;
19、3)分别计算两类样本类内离散度矩阵并相加得到总类内离散度矩阵;
20、4)计算样本类间离散度矩阵;
21、5)计算类间离散度矩阵与总类内离散度矩阵的比值,并将该比值作为第h个特征块的样本区分能力;
22、6)判断h是否等于j,若不等于,将h加1,跳至2);否则若h等于j,保留区分能力最强的k个特征块,得到筛选后特征数据;
23、所述k大于等于1且小于j。
24、所述筛选后特征数据的长度为p且p小于l。
25、s4所述待分类数据共有两种,其中正常人样本m个,已确诊的抑郁症患者样本n个;所述每个样本包含y组数据。
26、s4所述分类,包括:将待分类数据按比例分为训练集与测试集;将训练集送入分类器中进行训练,得到训练好的分类器;将测试集送入训练好的分类器中进行测试,得到分类结果。
27、所述待分类数据按比例分为训练集与测试集,依据样本划分,即每个样本的所有数据进入训练集或测试集。
28、有益效果
29、本发明所述的一种基于声纹特征筛选及变换域二次特征提取的分类方法,与现有方法相比,具有如下有益效果:
30、1、所述方法使用语音数据进行诊断,客观性强;
31、2、所述方法对语音数据进行特征提取前无需进行静音片段去除等预处理操作,简便且鲁棒性强;
32、3、所述方法仅依赖少量语音数据即可,所以对受试者进行测试时可以节省时间;
33、4、所述方法针对特征数据的处理保留了区分度较高的特征块,并且二次特征提取及特征融合进一步扩大了两类样本的特征差异,保证了高分类准确度;
34、5、所述方法使用声纹特征结合机器学习对抑郁症进行诊断,经验证可达到100%的准确率,实现了抑郁症的客观诊断和高准确率识别,具有重大的实际意义。
技术特征:
1.一种基于声纹特征筛选及变换域二次特征提取的分类方法,其特征在于,包括:
2.根据权利要求1所述的分类方法,其特征在于,s1所述谱特征,包括rasta听觉谱、梅尔倒谱系数、谱能量、谱方差、谱流量、谱倾斜、谱熵及谱峭度;所述梅尔倒谱系数,即melfrequency cepstrum coefficient,简称为mfcc;所述基频,即fundamental frequency,简称f0。
3.根据权利要求1所述的分类方法,其特征在于,s1所述能量特征,包括听觉谱的和、相对光谱滤波后听觉谱的和、均方根能量及过零率;所述韵律特征,包括基频、发声概率、频率微扰及振幅微扰。
4.根据权利要求1所述的分类方法,其特征在于,s1所述一条语音为某人的y条语音中的一条且称某人y条语音统称为一个样本;样本的总数为x,x个样本中包括m个正常人和n个已确诊的抑郁症患者;x个样本中的所有语音条数为(m+n)×y=x×y。
5.根据权利要求1所述的分类方法,其特征在于,所述每条语音的特征数据长度为l。
6.根据权利要求1所述的分类方法,其特征在于,s2所述特征筛选采用fisher准则,具体步骤如下:
7.根据权利要求5或65所述的分类方法,其特征在于,所述筛选后特征数据的长度为p且p小于l。
8.根据权利要求1或4所述的分类方法,其特征在于,s4所述待分类数据共有两种,其中正常人样本m个,已确诊的抑郁症患者样本n个;所述每个样本包含y组数据。
9.根据权利要求1所述的分类方法,其特征在于,s4所述分类,包括:将待分类数据按比例分为训练集与测试集;将训练集送入分类器中进行训练,得到训练好的分类器;将测试集送入训练好的分类器中进行测试,得到分类结果。
10.根据权利要求1所述的分类方法,其特征在于,所述待分类数据按比例分为训练集与测试集,依据样本划分,即每个样本的所有数据进入训练集或测试集。
技术总结
要求小于等于300字符。本发明属于机器学习及数据分类技术领域,尤其涉及一种基于声纹特征筛选及变换域二次特征提取的分类方法。所述方法为:将语音数据提取多种特征数据,然后将所述特征数据进行特征筛选、二次特征提取及特征融合处理得到待分类数据,最后对所述待分类数据进行分类得到分类结果;所述方法打破了常用抑郁症诊断方法主观性较强,导致抑郁症漏诊和误诊严重的缺陷,实现了抑郁症的客观诊断和高准确率识别。
技术研发人员:卢继华,李兆军,冯立辉,杨爱英
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/1/22
- 还没有人留言评论。精彩留言会获得点赞!