抗噪语音识别模型的自监督训练方法、系统和存储介质与流程
本发明涉及智能语音领域,尤其涉及一种抗噪语音识别模型的自监督训练方法、系统和存储介质。
背景技术:
1、为了进一步提高用户的语音交互体验,会使用自监督学习来提升asr(automaticspeech recognition,自动语音识别)的性能。例如,通过利用大量的未标记语音来学习有利于asr(或者其他下游任务)的上下文化语音表示来进行自监督学习。在自监督训练的框架下,加入一个从加噪语音到原始语音的重构模块,在自监督训练中加入语音重构的目标函数,从而提高自监督语音嵌入的抗噪能力,进而提升语音识别性能。
2、在实现本发明过程中,发明人发现相关技术中至少存在如下问题:
3、现有技术通常集成的重构模块(例如,se(speech enhancement,语音增强模块))作为自动语音识别的预处理前端,以抑制来自噪声语音中的噪声。然而,由于重构模块和自监督训练框架的交互较少,没有对模型的结构进行优化,对背景噪声的抗噪能力有限,影响了语音识别的效果。
技术实现思路
1、为了至少解决现有技术中自监督训练的模型抗噪能力有限的问题。
2、第一方面,本发明实施例提供一种抗噪语音识别模型的自监督训练方法,包括:
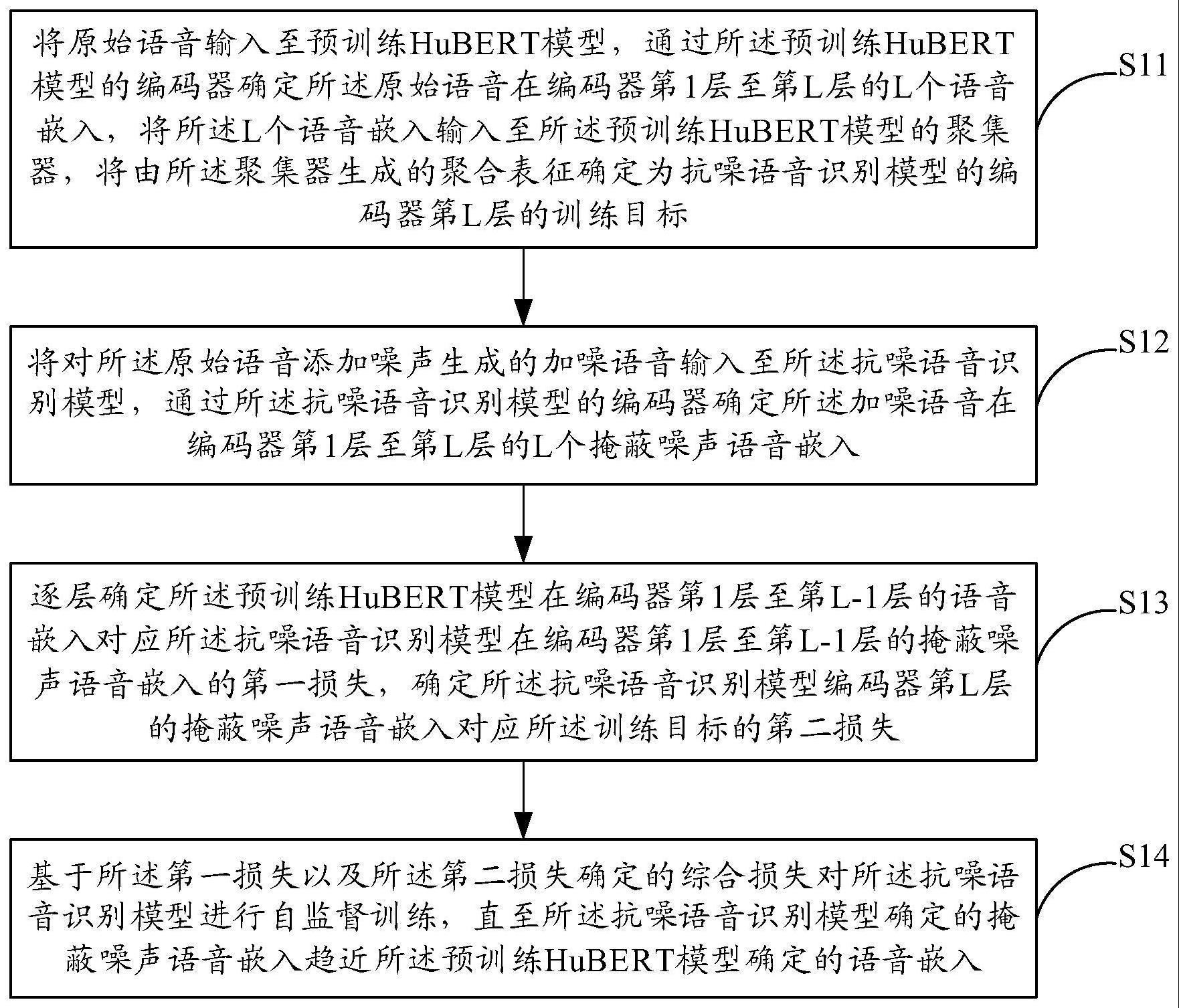
3、将原始语音输入至预训练hubert模型,通过所述预训练hubert模型的编码器确定所述原始语音在编码器第1层至第l层的l个语音嵌入,将所述l个语音嵌入输入至所述预训练hubert模型的聚集器,将由所述聚集器生成的聚合表征确定为抗噪语音识别模型的编码器第l层的训练目标;
4、将对所述原始语音添加噪声生成的加噪语音输入至所述抗噪语音识别模型,通过所述抗噪语音识别模型的编码器确定所述加噪语音在编码器第1层至第l层的l个掩蔽噪声语音嵌入;
5、逐层确定所述预训练hubert模型在编码器第1层至第l-1层的语音嵌入对应所述抗噪语音识别模型在编码器第1层至第l-1层的掩蔽噪声语音嵌入的第一损失,确定所述抗噪语音识别模型编码器第l层的掩蔽噪声语音嵌入对应所述训练目标的第二损失;
6、基于所述第一损失以及所述第二损失确定的综合损失对所述抗噪语音识别模型进行自监督训练,直至所述抗噪语音识别模型确定的掩蔽噪声语音嵌入趋近所述预训练hubert模型确定的语音嵌入。
7、第二方面,本发明实施例提供一种抗噪语音识别模型的自监督训练系统,包括:
8、训练目标确定程序模块,用于将原始语音输入至预训练hubert模型,通过所述预训练hubert模型的编码器确定所述原始语音在编码器第1层至第l层的l个语音嵌入,将所述l个语音嵌入输入至所述预训练hubert模型的聚集器,将由所述聚集器生成的聚合表征确定为抗噪语音识别模型的编码器第l层的训练目标;
9、语音嵌入确定程序模块,用于将对所述原始语音添加噪声生成的加噪语音输入至所述抗噪语音识别模型,通过所述抗噪语音识别模型的编码器确定所述加噪语音在编码器第1层至第l层的l个掩蔽噪声语音嵌入;
10、损失确定程序模块,用于逐层确定所述预训练hubert模型在编码器第1层至第l-1层的语音嵌入对应所述抗噪语音识别模型在编码器第1层至第l-1层的掩蔽噪声语音嵌入的第一损失,确定所述抗噪语音识别模型编码器第l层的掩蔽噪声语音嵌入对应所述训练目标的第二损失;
11、自监督训练程序模块,用于基于所述第一损失以及所述第二损失确定的综合损失对所述抗噪语音识别模型进行自监督训练,直至所述抗噪语音识别模型确定的掩蔽噪声语音嵌入趋近所述预训练hubert模型确定的语音嵌入。
12、第三方面,提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的抗噪语音识别模型的自监督训练方法的步骤。
13、第四方面,本发明实施例提供一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现本发明任一实施例的抗噪语音识别模型的自监督训练方法的步骤。
14、本发明实施例的有益效果在于:在hubert架构上实现了针对语音识别的抗噪预训练方法,提升自监督训练的模型的抗噪能力,进一步提升自动语音识别的准确性。
技术特征:
1.一种抗噪语音识别模型的自监督训练方法,包括:
2.根据权利要求1所述的方法,其中,在所述确定所述抗噪语音识别模型编码器第l层的掩蔽噪声语音嵌入与所述训练目标的第二损失之后,所述方法还包括:
3.根据权利要求1所述的方法,其中,所述逐层确定所述预训练hubert模型在编码器第1层至第l-1层的语音嵌入对应所述抗噪语音识别模型在编码器第1层至第l-1层的掩蔽噪声语音嵌入的第一损失包括:
4.根据权利要求1所述的方法,其中,所述预训练hubert模型的聚集器用于确定编码器第1层至第l层语音嵌入的加权和。
5.一种抗噪语音识别模型的自监督训练系统,包括:
6.根据权利要求5所述的系统,其中,所述损失确定程序模块还用于:
7.根据权利要求5所述的系统,其中,所述损失确定程序模块用于:
8.根据权利要求5所述的系统,其中,所述预训练hubert模型的聚集器用于确定编码器第1层至第l层语音嵌入的加权和。
9.一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1-4中任一项所述方法的步骤。
10.一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现权利要求1-4中任一项所述方法的步骤。
技术总结
本发明实施例提供一种抗噪语音识别模型的自监督训练方法、系统和存储介质。该方法包括:将原始语音输入至预训练HuBERT模型,通过预训练HuBERT模型的编码器确定原始语音在编码器第1层至第L层的L个语音嵌入,将L个语音嵌入输入至预训练HuBERT模型的聚集器,将由聚集器生成的聚合表征确定为抗噪语音识别模型的编码器第L层的训练目标;逐层确定预训练HuBERT模型在编码器第1层至第L层的语音嵌入对应抗噪语音识别模型在编码器第1层至第L层的掩蔽噪声语音嵌入的损失;基于损失对抗噪语音识别模型进行自监督训练。本发明实施例在HuBERT架构上实现了针对语音识别的抗噪预训练方法,提升自监督训练的模型的抗噪能力,进一步提升自动语音识别的准确性。
技术研发人员:钱彦旻,王巍
受保护的技术使用者:思必驰科技股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!