声音识别模型的训练方法、装置、电子设备及存储介质与流程
本公开涉及声音识别,尤其涉及一种声音识别模型的训练方法、装置、电子设备及存储介质。
背景技术:
1、煤岩识别即用一种方法自动识别出煤岩对象为煤或岩石,煤矿设备的工作音频与其机械结构、工作状态密切相关,是分析设备运行状态的一项重要指标,当设备的零件或部件由于作业后状态发生变化,其声纹信号特性也会相应发生变化,基于声纹的监测手段用于采煤机工作的煤岩识别技术具有重要意义。
2、当前技术中的煤岩识别方法仅适用于带有记忆截割功能的采煤机设备,可用于较平整的采集工作环境,对于较复杂的环境与其它采煤机设备不具有适用性,识别技术的准确率和效率也会受实际工作环境影响。
技术实现思路
1、本公开旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本公开的一个目的在于提出一种声音识别模型的训练方法。
3、本公开的第二个目的在于提出一种声音识别模型的训练装置。
4、本公开的第三个目的在于提出一种电子设备。
5、本公开的第四个目的在于提出一种非瞬时计算机可读存储介质。
6、本公开的第五个目的在于提出一种计算机程序产品。
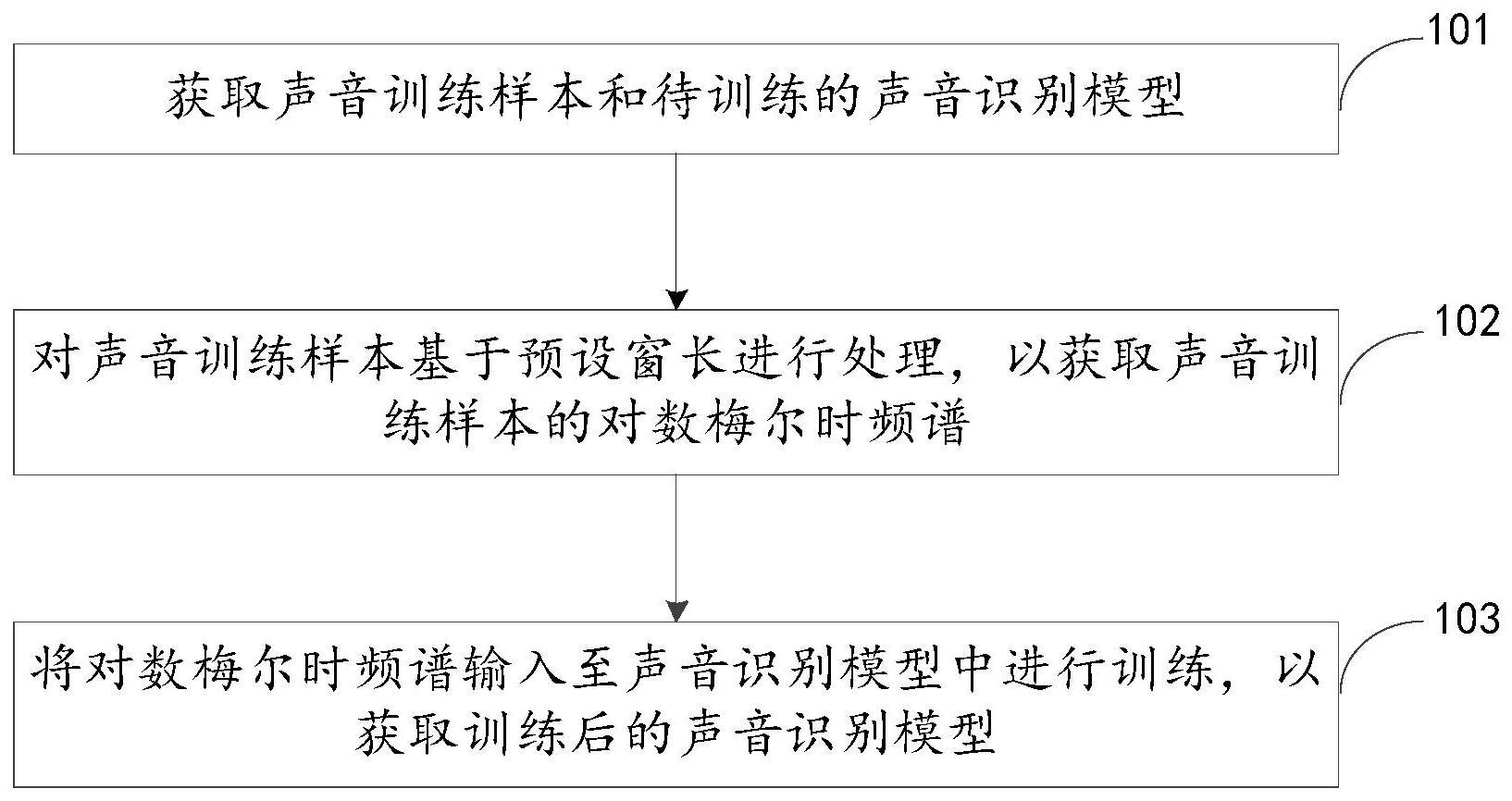
7、为达上述目的,本公开第一方面实施方式提出了一种声音识别模型的训练方法,包括:获取声音训练样本和待训练的声音识别模型;对声音训练样本基于预设窗长进行处理,以获取声音训练样本的对数梅尔时频谱;将对数梅尔时频谱输入至声音识别模型中进行训练,以获取训练后的声音识别模型。
8、根据本公开的一个实施方式,对声音训练样本基于预设窗长进行处理,以获取声音训练样本的对数梅尔时频谱,包括:对声音训练样本基于预设窗长,进行短时傅立叶变换,以获取声音训练样本的时频谱;基于时频谱和预设的梅尔滤波器,获取声音训练样本的对数梅尔时频谱。
9、根据本公开的一个实施方式,基于时频谱和预设的梅尔滤波器,获取声音训练样本的对数梅尔时频谱,包括:将时频谱与梅尔滤波器进行点乘,以获取梅尔时频谱;基于梅尔时频谱进行对数运算,以获取对数梅尔时频谱。
10、根据本公开的一个实施方式,将对数梅尔时频谱输入至声音识别模型中进行训练,包括:对不同预设窗长的对数梅尔时频谱进行采样处理,以获取同一维度下的多通道信号;将多通道信号输入至声音识别模型中进行训练。
11、根据本公开的一个实施方式,对不同预设窗长的对数梅尔时频谱进行采样处理,以获取同一维度下的多通道信号,包括:对不同预设窗长的对数梅尔时频谱进行上采样,以实现将对数梅尔时频谱对应的二维矩阵统一为同一大小,从而生成同一维度下的多通道信号。
12、根据本公开的一个实施方式,将多通道信号输入至声音识别模型中进行训练,包括:获取多通道信号输入至声音识别模型的输出结果;基于输出结果和预设的损失函数,确定损失值;基于损失值对声音识别模型进行训练。
13、根据本公开的一个实施方式,基于损失值对声音识别模型进行训练,包括:将损失值与损失阈值进行比较;响应于损失值大于损失阈值,对声音识别模型参数进行调整。
14、为达上述目的,本公开第二方面实施例提出了一种声音识别模型的训练装置,包括:获取模块,用于获取声音训练样本和待训练的声音识别模型;处理模块,用于对所述声音训练样本基于预设窗长进行处理,以获取所述声音训练样本的对数梅尔时频谱;训练模块,用于将所述对数梅尔时频谱输入至所述声音识别模型中进行训练,以获取训练后的声音识别模型。
15、为达上述目的,本公开第三方面实施例提出了一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以实现如本公开第一方面实施例所述的声音识别模型的训练方法。
16、为达上述目的,本公开第四方面实施例提出了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于实现如本公开第一方面实施例所述的声音识别模型的训练方法。
17、为达上述目的,本公开第五方面实施例提出了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时用于实现如本公开第一方面实施例所述的声音识别模型的训练方法。
18、通过使用不同长度的时间窗对训练样本进行处理,在进行特征提取的时候既捕捉声信号中长时程的稳态特征,又能捕捉瞬时精细的信号变化,可以增加声音识别的准确性,同时可以适用于不同的环境,提升本方案的实用性。
技术特征:
1.一种声音识别模型的训练方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述声音训0练样本基于预设窗长进行处理,以获取所述声音训练样本的对数梅尔时频谱,包括:
3.根据权利要求2所述的方法,其特征在于,所述基于所述时频谱和预设的梅尔滤波器,获取所述声音训练样本的对数梅尔时频谱,包括:
4.根据权利要求1-3中任一项所述的方法,其特征在于,所述将所述对数梅尔时频谱输入至所述声音识别模型中进行训练,包括:
5.根据权利要求4所述的方法,其特征在于,所述对不同预设窗长的对数梅尔时频谱进行采样处理,以获取同一维度下的多通道信号,包括:
6.根据权利要求4所述的方法,其特征在于,所述将所述多通道信号输入至所述声音识别模型中进行训练,包括:
7.根据权利要求6所述的方法,其特征在于,基于所述损失值对所述声音识别模型进行训练,包括:
8.一种声音识别模型的训练装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括存储器、处理器;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如权利要求1-8中任一项所述的方法。
技术总结
本公开提出了一种声音识别模型的训练方法、装置、电子设备及存储介质,涉及声音识别技术领域,该方法包括:获取声音训练样本和待训练的声音识别模型;对声音训练样本基于预设窗长进行处理,以获取声音训练样本的对数梅尔时频谱;将对数梅尔时频谱输入至声音识别模型中进行训练,以获取训练后的声音识别模型。通过使用不同长度的时间窗对训练样本进行处理,在进行特征提取的时候既捕捉声信号中长时程的稳态特征,又能捕捉瞬时精细的信号变化,可以增加声音识别的准确性,同时可以适用于不同的环境,提升本方案的实用性。
技术研发人员:曹宁宁,高思伟,王峰,冯银辉,李再峰,贺鹏,王帅,郑闯,刘姗姗
受保护的技术使用者:北京天玛智控科技股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!