说唱音频生成方法、装置、设备和可读存储介质与流程
本申请涉及音频分析领域,更具体地说,涉及说唱音频生成方法、装置、设备和可读存储介质。
背景技术:
1、随着说唱类节目的播出,说唱文化在年轻人中流行,因此在泛娱乐社交平台的离线功能场景中,存在满足用户需求生成属于自己的个性化说唱歌曲得到需求。按产品逻辑设定,用户根据歌词进行朗读,结束朗读后点击生成带有用户音色的说唱歌曲,生成的说唱歌曲带有良好的节奏,发音和情感。其中对于生成说唱歌曲就用到说唱音频转换生成算法。
2、目前常用的声音转换生成算法在训练阶段分别在说话人和目标人音频语料提取声学特征,之后使用如动态时间规划(dtw)的帧之间对齐算法对声学特征进行对齐,利用高斯混合模型(gmm)或者人工神经网络ann等模型学习输入声学特征到目标声学特征的映射关系。也就是说,目前常用的声音转换生成算法需要平行的说话人到目标人的音频语料。
3、但是现有技术训练模型实现平行的说话人与目标人语料的数据价格高昂,难以收集,并且合成效果容易出现不自然,存在机械音的情况,在长时音频合成中会出现发音不清晰等情况,这样的合成效果会大幅降低玩法的推广和用户体验。
4、基于上述实际情况,本申请提出了一种说唱音频生成方案,以解决上述弊端。
技术实现思路
1、有鉴于此,本申请提供了一种说唱音频生成方法、装置、设备和可读存储介质,通过提取语义ppg特征和声纹特征转换为用户音色的梅尔普特征,最终转换为带有用户音色的说唱音频,优化说唱音频合成效果,提升说唱音频表现力和自然度,并且不会出现机械音情况。
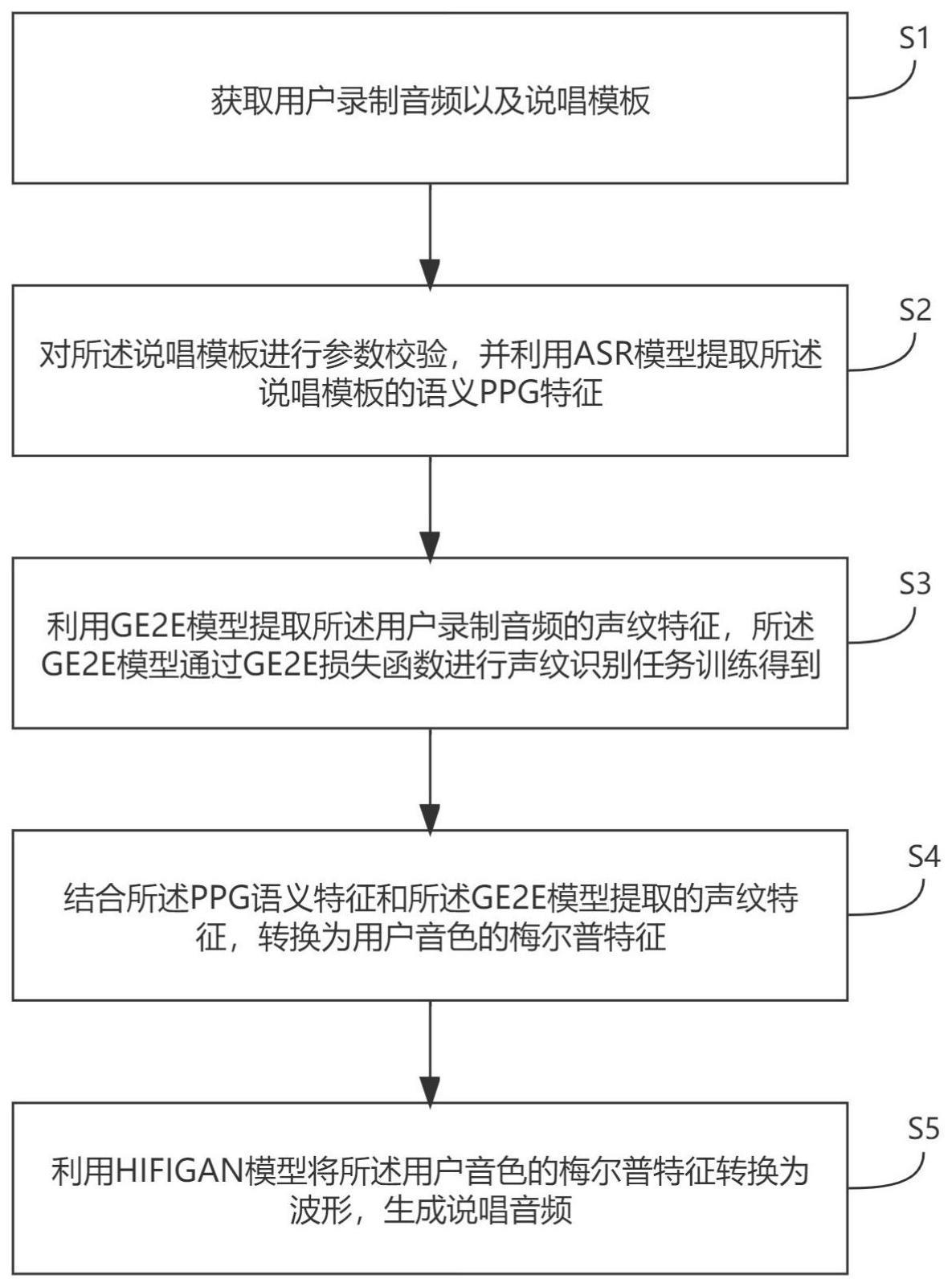
2、一种说唱音频生成方法,包括:
3、获取用户录制音频以及说唱模板;
4、对所述说唱模板进行参数校验,并利用asr模型提取所述说唱模板的语义ppg特征;
5、利用ge2e模型提取所述用户录制音频的声纹特征,所述ge2e模型通过ge2e损失函数进行声纹识别任务训练得到;
6、结合所述ppg语义特征和所述ge2e模型提取的声纹特征,转换为用户音色的梅尔普特征;
7、利用hifigan模型将所述用户音色的梅尔普特征转换为波形,生成说唱音频。
8、可选的,对所述说唱模板进行参数校验,包括:
9、对所述说唱模板的采样率、通道数以及量化位宽进行参数校验。
10、可选的,结合所述ppg语义特征和所述ge2e模型提取的声纹特征,转换为用户音色的梅尔普特征,包括:
11、提取所述用户录制音频的基频特征;
12、基于所述ppg语义特征和所述基频特征,得到初始扩展特征;
13、按时间维度对所述ge2e模型提取的声纹特征以及所述初始扩展特征进行拼接,生成目标拓展特征;
14、对所述目标拓展特征进行分块相对位置注意力解码,得到所述用户音色的梅尔普特征。
15、可选的,基于所述ppg语义特征和所述基频特征,得到初始扩展特征,包括:
16、利用ppg处理网络对所述ppg语义特征进行卷积特征提取,得到第一特征;
17、利用基频处理网络对所述基频特征进行卷积特征提取,得到第二特征;
18、将所述第一特征和所述第二特征进行相加,得到初始扩展特征。
19、可选的,所述hifigan模型包括hifigan声码器和卷积残差结构;
20、所述hifigan声码器包括多尺度判别器和多周期判别器,用于基于所述用户音色的梅尔普特征生成说唱音频;
21、所述卷积残差结构,通过交替使用带洞卷积和普通卷积增大感受野,用于保证所述说唱音频的合成音质,提高推理速度。
22、可选的,对所述目标拓展特征进行分块相对位置注意力解码,得到所述用户音色的梅尔普特征,包括:
23、利用rnn网络捕捉所述目标拓展特征的隐特征并确定分块特征大小;
24、使用分块相对位置注意力机制基于所述分块特征大小提取所述隐特征的上下文特征,并生成所述用户音色的梅尔普特征。
25、可选的,所述分块相对位置注意力机制为:
26、
27、
28、μi=μi-1+δi
29、
30、其中,sm为sofrmax函数,sp为softplus函数,σ为sigmoid函数,k代表k组混合参数,每组参数包含权重w,均值步长δ,缩放大小σ,以及均值大小μ,αi,j为输出的注意力权重,p为分块大小,i代表第i步解码输出,j代表所涉及隐特征时间坐标。
31、一种说唱音频生成装置,包括:
32、素材获取单元,用于获取用户录制音频以及说唱模板;
33、ppg特征单元,用于对所述说唱模板进行参数校验,并利用asr模型提取所述说唱模板的语义ppg特征;
34、声纹特征单元,用于利用ge2e模型提取所述用户录制音频的声纹特征,所述ge2e模型通过ge2e损失函数进行声纹识别任务训练得到;
35、梅尔普特征单元,用于结合所述ppg语义特征和所述ge2e模型提取的声纹特征,转换为用户音色的梅尔普特征;
36、音频生成单元,用于利用hifigan模型将所述用户音色的梅尔普特征转换为波形,生成说唱音频。
37、一种说唱音频生成设备,包括存储器和处理器;
38、所述存储器,用于存储程序;
39、所述处理器,用于执行所述程序,实现如上述的说唱音频生成方法的各个步骤。
40、一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上述的说唱音频生成方法的各个步骤。
41、从上述的技术方案可以看出,本申请实施例提供的一种说唱音频生成方法、装置、设备和可读存储介质,通过获取用户录制音频以及说唱模板,对所述说唱模板进行参数校验,并利用asr模型提取所述说唱模板的语义ppg特征。利用ge2e模型提取所述用户录制音频的声纹特征,所述ge2e模型通过ge2e损失函数进行声纹识别任务训练得到。结合所述ppg语义特征和所述ge2e模型提取的声纹特征,转换为用户音色的梅尔普特征。最后利用hifigan模型将所述用户音色的梅尔普特征转换为波形,生成说唱音频。
42、本申请利用asr模型提取所述说唱模板的语义ppg特征,并使用ge2e模型提取所述用户录制音频的声纹特征,使用用户音频提取的声纹特征按照所述说唱模板进行替换,即可生成带有用户音色的说唱音频,优化说唱音频合成效果,提升说唱音频表现力和自然度,并且不会出现机械音情况。
43、此外,针对长语音的转换效果降低的问题,使用基于分块的相对位置注意力的声音转换模型,能够以较快的速度对长时间的说唱歌曲进行转换,并有较好的转换效果,保证了长语音的转换效果。
技术特征:
1.一种说唱音频生成方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,对所述说唱模板进行参数校验,包括:
3.根据权利要求1所述的方法,其特征在于,结合所述ppg语义特征和所述ge2e模型提取的声纹特征,转换为用户音色的梅尔普特征,包括:
4.根据权利要求3所述的方法,其特征在于,基于所述ppg语义特征和所述基频特征,得到初始扩展特征,包括:
5.根据权利要求1所述的方法,其特征在于,所述hifigan模型包括hifigan声码器和卷积残差结构;
6.根据权利要求3所述的方法,其特征在于,对所述目标拓展特征进行分块相对位置注意力解码,得到所述用户音色的梅尔普特征,包括:
7.根据权利要求6所述的方法,其特征在于,所述分块相对位置注意力机制为:
8.一种说唱音频生成装置,其特征在于,包括:
9.一种说唱音频生成设备,其特征在于,包括存储器和处理器;
10.一种可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现如权利要求1-7中任一项所述的说唱音频生成方法的各个步骤。
技术总结
本申请公开了一种说唱音频生成方法、装置、设备和可读存储介质,方法包括:获取用户录制音频以及说唱模板;对说唱模板进行参数校验,并利用ASR模型提取说唱模板的语义PPG特征;利用GE2E模型提取用户录制音频的声纹特征,GE2E模型通过GE2E损失函数进行声纹识别任务训练得到;结合PPG语义特征和GE2E模型提取的声纹特征,转换为用户音色的梅尔普特征;利用HIFIGAN模型将用户音色的梅尔普特征转换为波形,生成说唱音频。本申请利用ASR模型提取说唱模板的语义PPG特征,并使用GE2E模型提取用户录制音频的声纹特征,使用声纹特征按照说唱模板进行替换,即可生成带有用户音色的说唱音频,优化说唱音频合成效果,提升说唱音频表现力和自然度,并且不会出现机械音情况。
技术研发人员:黄祥康,马金龙,盘子圣,焦南凯,熊佳,徐志坚,谢睿,陈光尧
受保护的技术使用者:广州趣丸网络科技有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!