基于上下文的语音增强的制作方法
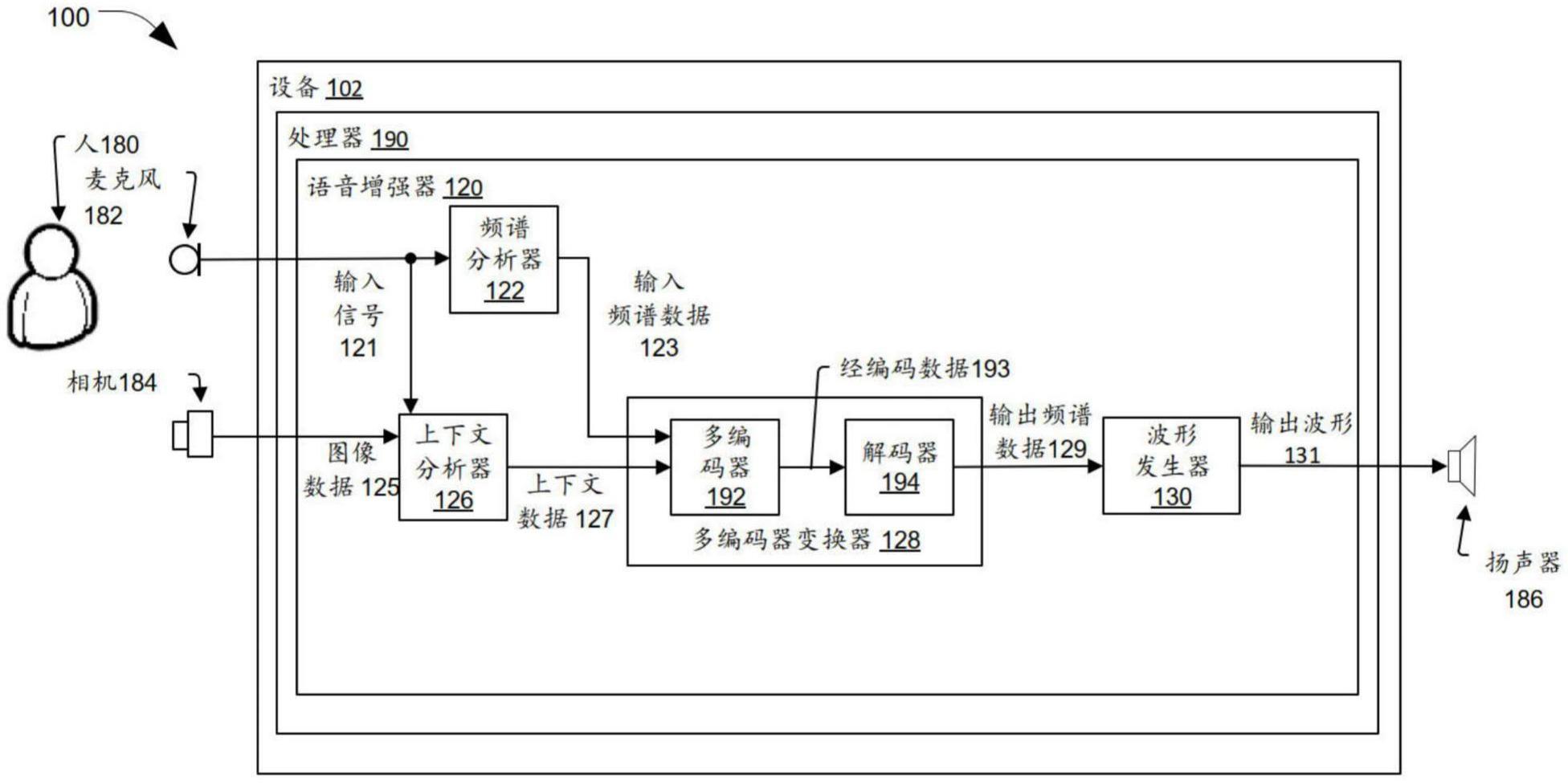
本公开总体上涉及语音增强。
背景技术:
1、技术的进步已经导致更小和更强大的计算设备。举例来说,当前存在多种便携式个人计算设备,包含无线电话,例如移动及智能电话、平板及膝上型计算机,其体积小、重量轻且易于由用户携带。这些设备可以通过无线网络传送话音和数据分组。此外,许多此类设备并入附加功能,例如数字静止相机、数字视频相机、数字记录器及音频文件播放器。此外,这样的设备可以处理可执行指令,包括可以用于访问互联网的软件应用,诸如web浏览器应用。因此,这些设备可以包括显著的计算能力。
2、这样的计算设备通常包含从一个或多个麦克风接收音频信号的功能。举例来说,音频信号可表示由麦克风捕获的用户语音、由麦克风捕获的外部声音或其组合。这样的设备可以包括执行噪声抑制和语音增强的应用。例如,设备可以在频域中执行对有噪语音信号的分析,其使用深度神经网络来减少噪声,然后重构语音。然而,在一些条件下,这样的技术可能无法抑制噪声。在示例中,诸如拍手之类的突然和平稳噪声可能难以从有噪语音信号中去除。改进设备的语音增强能力改进了可以在设备处执行的各种语音相关应用的性能,诸如通信和语音相关识别系统,包括自动语音识别(asr)、说话者识别、情绪识别和事件检测。
技术实现思路
1、根据本公开的一个实现方式,一种用于执行语音增强的设备包括被配置为基于输入信号获得输入频谱数据的一个或多个处理器。输入信号表示包括语音的声音。一个或多个处理器还被配置为使用多编码器变换器处理输入频谱数据和上下文数据,以生成表示输入信号的语音增强版本的输出频谱数据。
2、根据本公开的另一实现方式,一种语音增强方法包括基于输入信号获得输入频谱数据。输入信号表示包括语音的声音。该方法还包括使用多编码器变换器处理输入频谱数据和上下文数据,以生成表示输入信号的语音增强版本的输出频谱数据。
3、根据本公开的另一实现方式,一种非暂时性计算机可读介质存储指令,所述指令在由一个或多个处理器执行时,使得所述一个或多个处理器基于输入信号获得输入频谱数据。输入信号表示包括语音的声音。指令在由一个或多个处理器执行时还使得一个或多个处理器使用多编码器变换器处理输入频谱数据和上下文数据,以生成表示输入信号的语音增强版本的输出频谱数据。
4、根据本公开的另一实现方式,装置包括用于基于输入信号获得输入频谱数据的部件。输入信号表示包括语音的声音。装置还包括用于使用多编码器变换器处理输入频谱数据和上下文数据以生成表示输入信号的语音增强版本的输出频谱数据的部件。
5、在浏览整个申请之后,本公开的其他方面、优点和特征将变得显而易见,包括以下部分:附图说明、具体实施方式和权利要求。
技术特征:
1.一种用于执行语音增强的设备,所述设备包括:
2.根据权利要求1所述的设备,其中,所述多编码器变换器包括:
3.根据权利要求2所述的设备,其中所述一个或多个处理器被配置为:
4.根据权利要求3所述的设备,其中,所述一个或多个数据源包括所述输入信号或图像数据中的至少一个。
5.根据权利要求4所述的设备,其进一步包括被配置为生成所述图像数据的相机。
6.根据权利要求3所述的设备,其中,所述解码器注意力网络包括:
7.根据权利要求2所述的设备,其中所述解码器进一步包括:
8.根据权利要求2所述的设备,所述第一编码器包含被配置为对所述输入频谱数据进行滤波的梅尔滤波器组。
9.根据权利要求2所述的设备,还包括自动语音识别引擎,所述自动语音识别引擎被配置为基于所述输入信号生成文本,其中所述上下文数据包括所述文本。
10.根据权利要求9所述的设备,其中,所述第二编码器包括被配置为处理所述文本的字素到音素转换器。
11.根据权利要求2所述的设备,其中:
12.根据权利要求1所述的设备,还包括说话者识别引擎,所述说话者识别引擎被配置为基于所述输入信号生成说话者提取数据,并且其中所述上下文数据包括所述说话者提取数据。
13.根据权利要求1所述的设备,还包括情绪识别引擎,所述情绪识别引擎被配置为基于所述输入信号生成情绪数据,并且其中所述上下文数据包括所述情绪数据。
14.根据权利要求1所述的设备,还包括噪声分析引擎,所述噪声分析引擎被配置为基于所述输入信号生成噪声类型数据,并且其中,所述上下文数据包括所述噪声类型数据。
15.根据权利要求1所述的设备,还包括:
16.根据权利要求1所述的设备,还包括波形发生器,所述波形发生器被配置为处理所述输出频谱数据以生成对应于所述语音的增强版本的输出波形。
17.一种语音增强方法,所述方法包括:
18.根据权利要求17所述的方法,其中,处理所述输入频谱数据包括:
19.根据权利要求17所述的方法,还包括:从一个或多个数据源获得所述上下文数据,所述一个或多个数据源包括所述输入信号或图像数据中的至少一个。
20.根据权利要求17所述的方法,还包括:
21.根据权利要求17所述的方法,还包括:基于所述输入信号生成文本,其中,所述上下文数据包括所述文本。
22.根据权利要求17所述的方法,还包括基于所述输入信号生成说话者提取数据,并且其中所述上下文数据包括所述说话者提取数据。
23.根据权利要求17所述的方法,还包括基于所述输入信号生成情绪数据,并且其中,所述上下文数据包括所述情绪数据。
24.根据权利要求17所述的方法,还包括基于所述输入信号生成噪声类型数据,并且其中所述上下文数据包括所述噪声类型数据。
25.根据权利要求17所述的方法,还包括处理所述输出频谱数据以生成对应于所述语音的增强版本的输出波形。
26.一种非暂时性计算机可读介质,存储有指令,所述指令在由一个或多个处理器执行时使所述一个或多个处理器:
27.根据权利要求26所述的非暂时性计算机可读介质,其中所述指令可执行以致使所述一个或多个处理器进行以下操作:
28.根据权利要求26所述的非暂时性计算机可读介质,其中所述指令可执行以致使所述一个或多个处理器从一个或多个数据源获得所述上下文数据,所述一个或多个数据源包含所述输入信号或图像数据中的至少一者。
29.一种装置,包括:
30.根据权利要求29所述的装置,其中所述用于获得的部件和所述用于处理的部件集成到虚拟助理、家用电器、智能设备、物联网(iot)设备、通信设备、耳机、车辆、计算机、显示设备、电视、游戏控制台、音乐播放器、收音机、视频播放器、娱乐单元、个人媒体播放器、数字视频播放器、相机或导航设备中的至少一个中。
技术总结
一种用于执行语音增强的设备包括一个或多个处理器,所述一个或多个处理器被配置为基于输入信号获得输入频谱数据。所述输入信号表示包括语音的声音。所述一个或多个处理器还被配置为使用多编码器变换器处理输入频谱数据和上下文数据,以生成表示输入信号的语音增强版本的输出频谱数据。
技术研发人员:K·白,S·张,L-H·金,E·维瑟,S·穆恩,V·蒙塔泽里
受保护的技术使用者:高通股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!