利用基于语音合成的模型适配改进语音识别的制作方法
本公开涉及利用基于语音合成的模型适配来改进语音识别。
背景技术:
1、自动语音识别(asr)、采取音频输入并且将其转录成文本的过程已经成为移动设备和其他设备中使用的重要技术。通常,自动语音识别尝试通过采取音频输入(例如,语音话语)并且将音频输入转录成文本来提供人已经说过什么的准确转录。现代asr模型基于深度神经网络的正在进行的开发而继续在准确性(例如,低词错率(wer))和时延(例如,用户说话与转录之间的延迟)这两者上进行改进。然而,开发基于深度学习的asr模型的一个挑战是,asr模型的参数倾向于过拟合训练数据,从而导致asr模型在训练数据不够广泛时难以泛化未见的数据。结果,在更大的训练数据集上训练asr模型改进了asr模型的准确性。能够并入合成语音和/或数据增强语音以增加用于训练asr模型的训练数据的音量。
技术实现思路
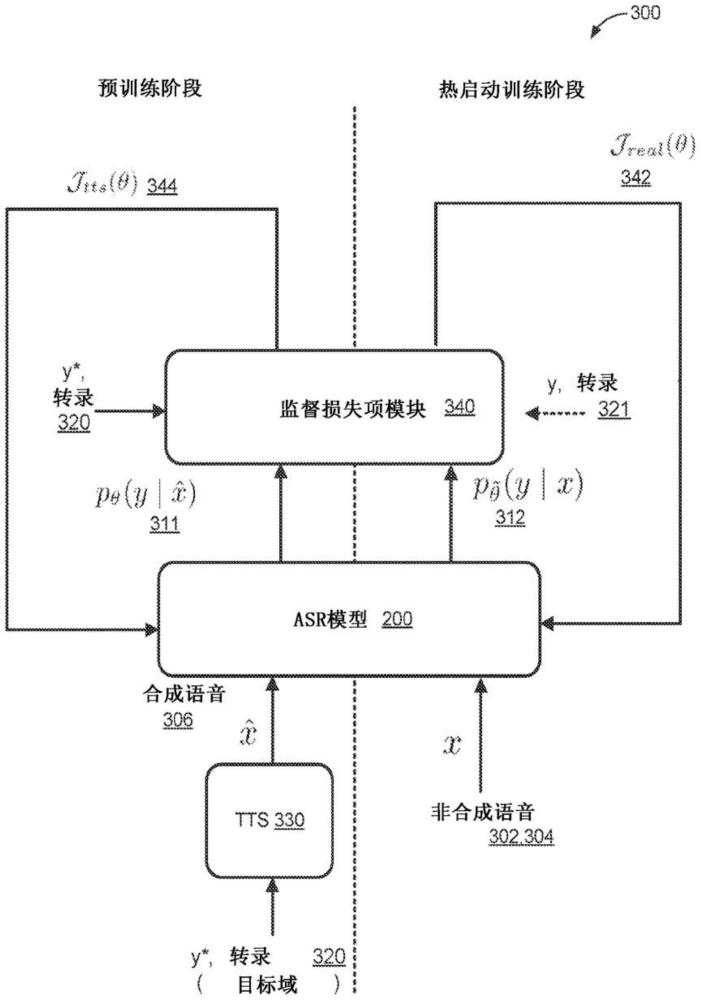
1、本公开的一个方面提供了一种计算机实现的方法,该方法在数据处理硬件上执行时使数据处理硬件执行操作。操作包括:获取目标域中的合成语音的样本话语以及获取目标域中的非合成语音的转录话语。操作还包括在目标域中的合成语音的样本话语上预训练语音识别模型以获得用于热启动训练的初始状态。在预训练语音识别模型后,操作还包括在目标域中的非合成语音的转录话语上热启动训练语音识别模型以教导语音识别模型学习识别目标域中的真实/人类语音。
2、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,获取目标域中的合成语音的样本话语包括使用文本到语音(tts)系统,基于被接收作为在tts系统处的输入的话语的对应转录来生成每个合成语音的样本话语。可以从语言模型对对应转录进行采样。可以在目标域中的转录音频样本上训练和/或在与目标域不同的域外音频样本上训练tts系统。tts系统还可以被配置为跨合成语音的话语改变话音特性或跨合成语音的话语改变韵律/风格质量中的至少一个。
3、在一些示例中,操作还包括将数据增强应用于合成语音的样本话语中的一个或多个。这里,所应用的数据增强可以包括添加噪声、添加混响或操纵定时中的至少一个。语音识别模型可以包括诸如递归神经网络-换能器(rnn-t)模型的基于帧对准的换能器模型。语音识别模型可以包括基于对准的编码器-解码器模型。
4、本公开的另一方面提供了一种系统,该系统包括数据处理硬件和与数据处理硬件通信并且存储指令的存储器硬件,该指令在数据处理硬件上执行时使数据处理硬件执行操作。操作包括:获取目标域中的合成语音的样本话语以及获取目标域中的非合成语音的转录话语。操作还包括在目标域中的合成语音的样本话语上预训练语音识别模型以获得用于热启动训练的初始状态。在预训练语音识别模型后,操作还包括在目标域中的非合成语音的转录话语上热启动训练语音识别模型以教导语音识别模型学习识别目标域中的真实/人类语音。
5、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,获取目标域中的合成语音的样本话语包括使用文本到语音(tts)系统,基于被接收作为在tts系统处的输入的话语的对应转录来生成每个合成语音的样本话语。可以从语言模型对对应转录进行采样。可以在目标域中的转录音频样本上训练和/或在与目标域不同的域外音频样本上训练tts系统。tts系统还可以被配置为跨合成语音的话语改变话音特性或跨合成语音的话语改变韵律/风格质量中的至少一个。
6、在一些示例中,操作还包括将数据增强应用于合成语音的样本话语中的一个或多个。这里,所应用的数据增强可以包括添加噪声、添加混响或操纵定时中的至少一个。语音识别模型可以包括诸如递归神经网络-换能器(rnn-t)模型的基于帧对准的换能器模型。语音识别模型可以包括基于对准的编码器-解码器模型。
7、在附图和以下描述中阐述了本公开的一个或多个实施方式的细节。根据说明书和附图以及权利要求,其他方面、特征和优点将是显而易见的。
技术特征:
1.一种由数据处理硬件(510)执行的计算机实现的方法(400),所述方法使所述数据处理硬件(510)执行操作,所述操作包括:
2.根据权利要求1所述的方法(400),其中,获取所述目标域中的所述合成语音(306)的样本话语包括使用文本到语音(tts)系统(330),基于作为在所述tts系统(330)处的输入接收的话语的对应转录(320)来生成合成语音(306)的每个样本话语。
3.根据权利要求2所述的方法(400),其中,从语言模型对所述对应转录(320)进行采样。
4.根据权利要求2或3所述的方法(400),其中,在所述目标域中的转录音频样本上训练所述tts系统(330)。
5.根据权利要求2至4中的任一项所述的方法(400),其中,在与所述目标域不同的域外音频样本上训练所述tts系统(330)。
6.根据权利要求2至5中的任一项所述的方法(400),其中,所述tts系统(330)被配置为跨合成语音(306)的话语改变话音特性。
7.根据权利要求2至6中的任一项所述的方法(400),其中,所述tts系统(330)被配置为跨合成语音(306)的话语改变韵律/风格质量。
8.根据权利要求1至7中的任一项所述的方法(400),其中,所述操作还包括将数据增强应用于所述合成语音(306)的样本话语中的一个或多个。
9.根据权利要求8所述的方法(400),其中,所应用的数据增强包括添加噪声、添加混响或操纵定时中的至少一个。
10.根据权利要求1至9中的任一项所述的方法(400),其中,所述语音识别模型(200)包括基于帧对准的换能器模型(200a)。
11.根据权利要求10所述的方法(400),其中,所述基于帧对准的换能器模型(200a)包括递归神经网络-换能器(rnn-t)模型(200a)。
12.根据权利要求1至11中的任一项所述的方法(400),其中,所述语音识别模型(200)包括基于对准的编码器-解码器模型(200b)。
13.一种系统(100),包括:
14.根据权利要求13所述的系统(100),其中,获取所述目标域中的所述合成语音(306)的样本话语包括使用文本到语音(tts)系统(330),基于作为在所述tts系统(330)处的输入接收的话语的对应转录(320)来生成合成语音(306)的每个样本话语。
15.根据权利要求14所述的系统(100),其中,从语言模型对所述对应转录(320)进行采样。
16.根据权利要求14或15所述的系统(100),其中,在所述目标域中的转录音频样本上训练所述tts系统(330)。
17.根据权利要求14至16中的任一项所述的系统(100),其中,在与所述目标域不同的域外音频样本上训练所述tts系统(330)。
18.根据权利要求14至17中的任一项所述的系统(100),其中,所述tts系统(330)被配置为跨合成语音(306)的话语改变话音特性。
19.根据权利要求14至18中的任一项所述的系统(100),其中,所述tts系统(330)被配置为跨合成语音(306)的话语改变韵律/风格质量。
20.根据权利要求13至19中的任一项所述的系统(100),其中,所述操作还包括将数据增强应用于所述合成语音(306)的样本话语中的一个或多个。
21.根据权利要求20所述的系统(100),其中,所应用的数据增强包括添加噪声、添加混响或操纵定时中的至少一个。
22.根据权利要求13至21中的任一项所述的系统(100),其中,所述语音识别模型(200)包括基于帧对准的换能器模型(200a)。
23.根据权利要求22所述的系统(100),其中,所述基于帧对准的换能器模型(200a)包括递归神经网络换能器(rnn-t)模型(200a)。
24.根据权利要求13至23中的任一项所述的系统(100),其中,所述语音识别模型(200)包括基于对准的编码器-解码器模型(200b)。
技术总结
用于训练语音识别模型(200)的方法(400)包括:获取目标域中的合成语音(306)的样本话语;获取目标域中的非合成语音(304)的转录话语;以及在目标域中的合成语音的样本话语上预训练语音识别模型以获得用于热启动训练的初始状态。在预训练语音识别模型后,方法还包括在目标域中的非合成语音的转录话语上热启动训练语音识别模型以教导语音识别模型学习识别目标域中的真实/人类语音。
技术研发人员:安德鲁·罗森伯格,布瓦那·拉马巴德兰
受保护的技术使用者:谷歌有限责任公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!