与阵列几何形状无关的多通道个性化语音增强的制作方法
背景技术:
1、语音增强模型被广泛使用于在线通信工具中,其可以去除背景噪声并让人类语音通过。一些现有系统的局限性之一是它们无法去除干扰说话者,至少因为它们被训练为保留所有人类语音,并且这些现有系统不能够选择目标说话者。如此,本领域技术人员将注意到,虽然一些现有系统描述了语音增强,但是此类现有系统中的语音增强可能不包括去除其他说话者(例如,干扰说话者)的能力。
2、利用此类现有系统,家庭成员的个人信息可能会无意中被共享,诸如在视频会议通话期间。此外,由于空间有限,在不同公司工作且共享同一环境的家庭成员可能会无意中泄露公司机密。
技术实现思路
1、下面参考下面列出的附图详细描述所公开的示例。提供以下
技术实现要素:
来说明本文所公开的一些示例。然而,这并不意味着将所有示例限制为任何特定配置或操作顺序。
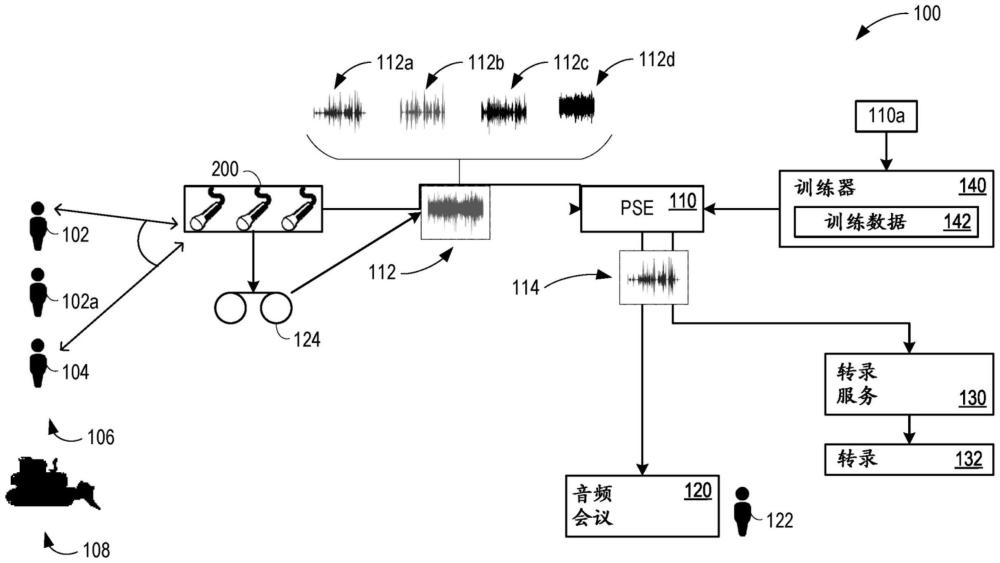
2、与阵列几何形状无关的多通道个性化语音增强(pse)的示例包括:从至少第一目标说话者的登记数据中提取说话者嵌入;从由麦克风阵列所捕获的输入音频中提取空间特征,输入音频包括第一目标说话者和干扰说话者的语音数据的混合;将输入音频、所提取的空间特征和所提取的说话者嵌入提供给经训练的与几何形状无关的pse模型;以及在没有麦克风阵列的几何形状信息的情况下使用经训练的与几何形状无关的pse模型产生输出数据,该输出数据包括具有减少的干扰说话者的语音数据的第一目标说话者的估计的干净语音数据。
技术特征:
1.一种系统,包括:
2.根据权利要求1所述的系统,其中所述指令还可操作以:
3.根据权利要求2所述的系统,其中在训练期间被使用的所述多个麦克风阵列几何形状不包括被用来捕获所述输入音频的麦克风阵列几何形状,并且其中训练所述pse模型不包括利用所述第一目标说话者或第二目标说话者或所述干扰说话者的语音数据来训练所述pse模型。
4.根据权利要求1-3中任一项所述的系统,其中所述说话者嵌入从针对所述第一目标说话者和第二目标说话者的登记数据被提取,并且其中所述输出数据还包括所述第二目标说话者的估计的干净语音数据。
5.根据权利要求1-4中任一项所述的系统,其中所述输入音频包括实时音频,并且其中产生所述输出数据包括实时产生所述输出数据。
6.一种计算机化方法,包括:
7.根据权利要求6所述的方法,还包括:
8.根据权利要求7所述的方法,其中在训练期间被使用的所述多个麦克风阵列几何形状不包括被用来捕获所述输入音频的麦克风阵列几何形状,并且其中训练所述pse模型不包括利用所述第一目标说话者或第二目标说话者或所述干扰说话者的语音数据来训练所述pse模型。
9.根据权利要求6-8中任一项所述的方法,其中所述说话者嵌入从针对所述第一目标说话者和第二目标说话者的登记数据被提取,并且其中所述输出数据还包括所述第二目标说话者的估计的干净语音数据。
10.根据权利要求6-9中任一项所述的方法,其中所述输入音频包括实时音频,并且其中产生所述输出数据包括实时产生所述输出数据。
11.一个或多个计算机存储设备,所述一个或多个计算机存储设备上存储有计算机可执行指令,所述计算机可执行指令在由计算机执行时使所述计算机执行操作,所述操作包括:
12.根据权利要求11所述的一个或多个计算机存储设备,其中所述操作还包括:
13.根据权利要求11或12所述的一个或多个计算机存储设备,其中从针对所述第一目标说话者和第二目标说话者的登记数据提取所述说话者嵌入,并且其中所述输出数据还包括所述第二目标说话者的估计的干净语音数据。
14.根据权利要求11-13中任一项所述的一个或多个计算机存储设备,其中所述输入音频包括实时音频,并且其中产生所述输出数据包括实时产生所述输出数据。
15.根据权利要求11-14中任一项所述的一个或多个计算机存储设备,其中所述空间特征包括通道间相位差(ipd)。
技术总结
与阵列几何形状无关的多通道个性化语音增强(PSE)的示例从目标说话者登记数据中提取说话者嵌入,该说话者嵌入表示一个或多个目标说话者的声学特性。从由麦克风阵列所捕获的输入音频中提取空间特征(例如,通道间相位差)。输入音频包括(多个)目标说话者和一个或多个干扰说话者的语音数据的混合。输入音频、所提取的说话者嵌入和所提取的空间特征被提供给经训练的与几何形状无关的PSE模型。产生输出数据,其包括(多个)目标说话者的估计的干净语音数据,其具有(多个)干扰说话者的语音数据的减少(或消除),而经训练的PSE模型不需要麦克风阵列的几何形状信息。
技术研发人员:S·E·埃斯基梅兹,吉冈拓也,王华明,H·塔赫里安,陈卓,黄学东
受保护的技术使用者:微软技术许可有限责任公司
技术研发日:
技术公布日:2024/5/12
- 还没有人留言评论。精彩留言会获得点赞!