发音评测方法及装置、电子设备及可读存储介质与流程
本公开涉及语音处理,具体涉及发音评测方法及装置、电子设备及可读存储介质。
背景技术:
1、发音评测是计算机辅助语言学习(computer aided language learning,call)领域的一项重要任务,对音频数据进行评测,是许多口语考试和学习场景中必不可少的环节。传统的发音评测模型会对待评测音频数据的正确发音程度进行评测,再根据发音程度的得分计算获得整个待评测音频数据的评分。目前,传统的发音评测模型对待评测音频数据的评测准确性较低。
技术实现思路
1、有鉴于此,本公开提供一种发音评测方法及装置、电子设备及可读存储介质,通过发音评测模型获得待评测音频数据的错误类型和分数,发音评测模型能够结合错误类型进行评分,解决了传统的发音评测模型对待评测音频数据的评测准确性较低的问题。
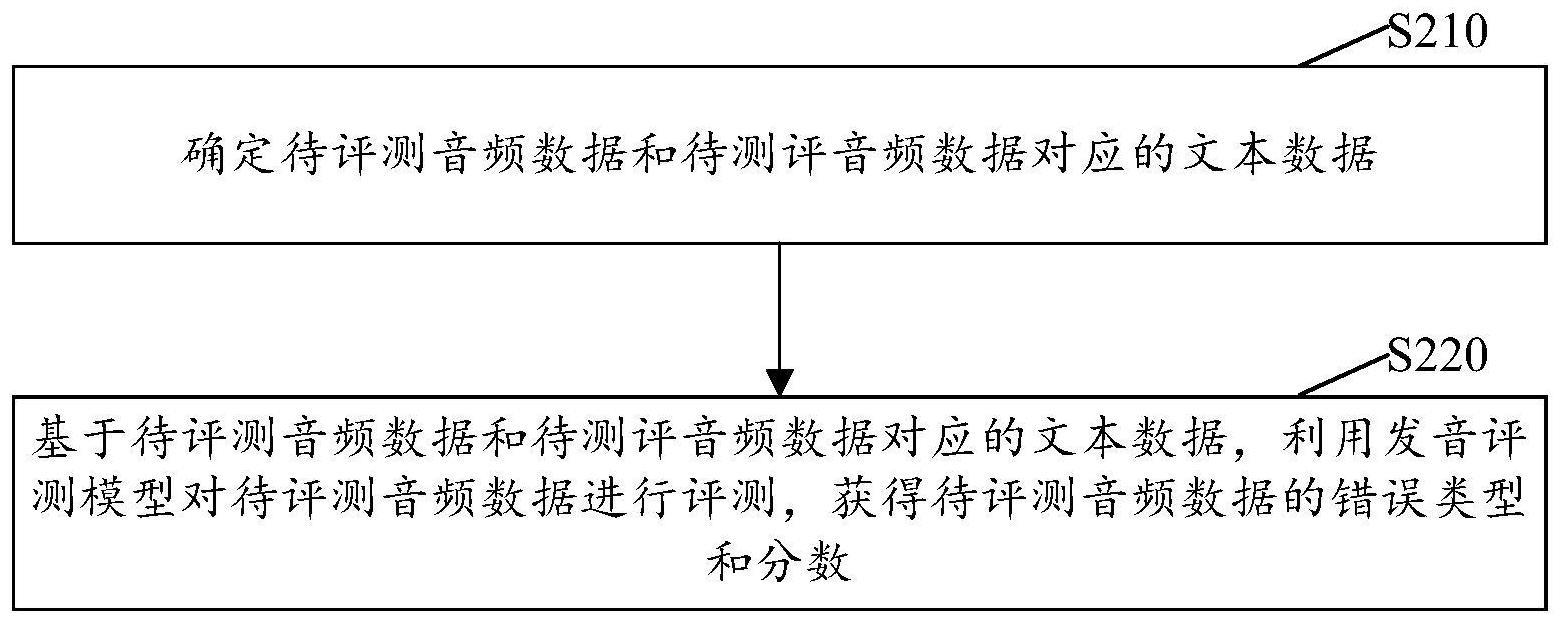
2、第一方面,本公开一实施例提供的一种发音评测方法,包括:确定待评测音频数据和所述待测评音频数据对应的文本数据;基于待评测音频数据和待测评音频数据对应的文本数据,利用发音评测模型对待评测音频数据进行评测,获得待评测音频数据的错误类型和分数,其中,发音评测模型利用自注意力机制和交叉注意力机制对待评测音频数据和待测评音频数据对应的文本数据进行评测,以得到待评测音频数据的错误类型和分数。
3、结合第一方面,在第一方面的某些实现方式中,在基于待评测音频数据和待测评音频数据对应的文本数据,利用发音评测模型对待评测音频数据进行评测,获得待评测音频数据的错误类型和分数之前,该方法还包括:生成训练样本,其中,训练样本包括多个音频数据、多个音频数据各自对应的文本数据和多个音频数据各自对应的标签,标签包括错误类型标签和分数标签;将多个音频数据、多个音频数据各自对应的文本数据,输入深度学习模型,得到多个音频数据各自对应的预测错误类型和预测分数;利用第一损失函数,基于多个音频数据各自对应的预测错误类型和错误类型标签,得到错误类型损失;利用第二损失函数,基于多个音频数据各自对应的预测分数和分数标签,得到分数损失;基于错误类型损失和所述分数损失,调整学习模型,得到发音评测模型。
4、结合第一方面,在第一方面的某些实现方式中,标签还包括错误概率标签,多个音频数据包括至少一个非标准音频数据;将多个音频数据、多个音频数据各自对应的文本数据,输入深度学习模型,得到多个音频数据各自对应的预测错误类型和预测分数,包括:将多个音频数据、多个音频数据各自对应的文本数据,输入深度学习模型,得到多个音频数据各自对应的预测错误类型、预测分数和预测错误概率;发音评方法还包括:利用第三损失函数,基于多个音频数据各自对应的错误概率标签,得到错误概率损失;基于错误类型损失和分数损失,调整深度学习模型,得到所述发音评测模型,包括:基于错误类型损失、分数损失和错误概率损失,调整深度学习模型,得到发音评测模型,其中,发音评测模型用于预测待评测音频数据的错误类型、错误概率和分数。
5、结合第一方面,在第一方面的某些实现方式中,深度学习模型包括编码器和解码器,解码器包括文本数据处理层和三个并联的全连接层;将多个音频数据、多个音频数据各自对应的文本数据,输入深度学习模型,得到多个音频数据各自对应的预测错误类型、预测分数和预测错误概率,包括:利用编码器,基于多个音频数据,生成第一隐层向量;利用文本数据处理层,基于多个音频数据各自对应的文本数据和第一隐层向量,生成第二隐层向量;利用三个并联的全连接层,基于第二隐层向量,生成预测错误类型、预测错误概率和预测分数,其中,三个并联的全连接层分别输出预测错误类型、预测错误概率和预测分数;基于预测错误类型、预测错误概率和预测分数,以及错误类型标签、错误概率标签和分数标签,调整深度学习模型的参数,得到发音评测模型,发音评测模型用于预测待评测音频数据的错误类型、错误概率和分数。
6、结合第一方面,在第一方面的某些实现方式中,编码器包括卷积神经网络层和编码层;利用编码器,基于多个音频数据,生成第一隐层向量,包括:利用卷积神经网络层,对多个音频数据进行特征提取,得到多个音频数据的局部关系特征;利用编码层,对局部关系特征进行编码,生成第一隐层向量。
7、结合第一方面,在第一方面的某些实现方式中,生成训练样本,包括:基于多个音频数据,确定多个音频数据各自对应的文本数据;基于多个音频数据和多个音频数据各自对应的文本数据,通过训练好的标签生成模型,生成错误类型标签和分数标签。
8、结合第一方面,在第一方面的某些实现方式中,在基于多个音频数据和多个音频数据各自对应的文本数据,通过训练好的标签生成模型,生成错误类型标签和分数标签之前,该方法还包括:基于标签音频数据样本和标签音频数据样本对应的文本数据,利用训练好的教师模型,确定标签音频数据样本对应的初始错误类型标签;利用标签音频数据样本、标签音频数据样本对应的文本数据、初始错误类型标签和初始分数标签,训练学生模型,生成训练好的标签生成模型。
9、第二方面,本公开一实施例提供的一种发音评测装置,包括:确定模块,用于确定待评测音频数据和待测评音频数据对应的文本数据;评测模块,用于基于待评测音频数据和待测评音频数据对应的文本数据,利用发音评测模型对待评测音频数据进行评测,获得待评测音频数据的错误类型和分数,其中,发音评测模型利用自注意力机制和交叉注意力机制对待评测音频数据和待测评音频数据对应的文本数据进行评测,以得到待评测音频数据的错误类型和分数。
10、第三方面,本公开一实施例提供一种电子设备,包括:处理器;用于存储处理器可执行指令的存储器,其中,处理器用于执行上述第一方面所提及的发音评测方法。
11、第四方面,本公开一实施例提供一种计算机可读存储介质,该存储介质存储有计算机程序,计算机程序用于执行上述第一方面所提及的发音评测方法。
12、本公开实施例的发音评测方法,通过发音评测模型对待评测音频数据进行处理,发音评测模型利用自注意力机制和交叉注意力机制对待评测音频数据和待测评音频数据对应的文本数据进行评测,以得到待评测音频数据的错误类型和分数对待评测音频数据进行评测,获得待评测音频数据的错误类型和分数。发音评测模型可以结合错误类型进行评分,评分结果更加精确,提高了待评测音频数据的评测结果准确性,解决了传统的发音评测模型对待评测音频数据的评测准确性较低的问题。
技术特征:
1.一种发音评测方法,其特征在于,包括:
2.根据权利要求1所述的发音评测方法,其特征在于,在所述基于所述待评测音频数据和所述待测评音频数据对应的文本数据,利用发音评测模型对所述待评测音频数据进行评测,获得所述待评测音频数据的错误类型和分数之前,还包括:
3.根据权利要求2所述的发音评测方法,其特征在于,所述标签还包括错误概率标签,所述多个音频数据包括至少一个非标准音频数据;
4.根据权利要求3所述的发音评测方法,其特征在于,所述深度学习模型包括编码器和解码器,所述解码器包括文本数据处理层和三个并联的全连接层;所述将所述多个音频数据、所述多个音频数据各自对应的文本数据,输入深度学习模型,得到所述多个音频数据各自对应的预测错误类型、预测分数和预测错误概率,包括:
5.根据权利要求4所述的发音评测方法,其特征在于,所述编码器包括卷积神经网络层和编码层;所述利用所述编码器,基于所述多个音频数据,生成第一隐层向量,包括:
6.根据权利要求1至5任一所述的发音评测方法,其特征在于,所述生成训练样本,包括:
7.根据权利要求6所述的发音评测方法,其特征在于,在所述基于所述多个音频数据和所述多个音频数据各自对应的文本数据,通过训练好的标签生成模型,生成所述错误类型标签和所述分数标签之前,还包括:
8.一种发音评测装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序用于执行上述权利要求1至7任一项所述的发音评测方法。
技术总结
本公开披露一种发音评测方法及装置、电子设备及可读存储介质,涉及语音处理领域。该发音评测方法包括:确定待评测音频数据和所述待测评音频数据对应的文本数据;基于待评测音频数据和待测评音频数据对应的文本数据,利用发音评测模型对待评测音频数据进行评测,获得待评测音频数据的错误类型和分数,其中,发音评测模型利用自注意力机制和交叉注意力机制对待评测音频数据和待测评音频数据对应的文本数据进行评测,以得到待评测音频数据的错误类型和分数。本公开实施例的发音评测方法通过发音评测模型,对待评测音频数据进行评测,结合错误类型进行评分,使得获得的评分结果更加精确,提高了发音评测模型的准确性。
技术研发人员:王冰珏
受保护的技术使用者:科大讯飞股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!