音频识别模型训练方法、装置、计算机设备及存储介质与流程
本申请属于深度学习,具体而言,本申请涉及一种音频识别模型训练方法、装置、计算机设备及存储介质。
背景技术:
1、命令词识别属于音频识别领域,其被广泛应用于智能家居的音频控制,如用于智能音箱、蓝牙语音耳机、智能风扇、空调等的语音控制。此类应用场景不同于通用音频识别,其只需保证在指定的命令词列表有高的准确率和低误识别率,即可做到很好的用户体验。
2、基于此类应用场景的特点,控制命令词之间往往会存在很大的相似性,比如用于控制音箱的“播放上一首”和“播放下一首”,用于空调的“温度调高四度”和“温度调高十度”等,这些高相似度的控制命令词极易造成智能设备的误识别。如何有效降低相似控制命令词的误识别,是一个需要解决的技术问题。
技术实现思路
1、本申请的主要目的为提供一种音频识别模型训练方法、装置、计算机设备及存储介质,旨在解决相似控制命令词的音频误识别概率较高的技术问题。
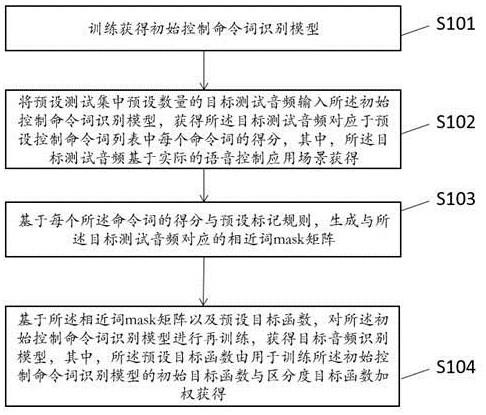
2、为了实现上述发明目的,本申请提供一种音频识别模型训练方法,所述音频识别模型用于控制命令词的识别,所述方法包括:
3、训练获得初始控制命令词识别模型;
4、将预设测试集中预设数量的目标测试音频输入所述初始控制命令词识别模型,获得所述目标测试音频对应于预设控制命令词列表中每个命令词的得分,其中,所述目标测试音频基于实际的语音控制应用场景获得;
5、基于每个所述命令词的得分与预设标记规则,生成与所述目标测试音频对应的相近词mask矩阵;
6、基于所述相近词mask矩阵以及预设目标函数,对所述初始控制命令词识别模型进行再训练,获得目标音频识别模型,其中,所述预设目标函数由用于训练所述初始控制命令词识别模型的初始目标函数与区分度目标函数加权获得。
7、在一些实施例中,所述初始目标函数为ctc目标函数。
8、在一些实施例中,所述训练获得初始控制命令词识别模型的步骤,包括:
9、基于预收集的控制命令词语料,对通用音频识别模型进行训练,获得初始控制命令词识别模型,或通过无监督的方式对通用音频识别模型进行训练,获得初始控制命令词识别模型。
10、在一些实施例中,所述相近词mask矩阵的初始元素值均为0,所述基于每个所述命令词的得分与预设标记规则,生成与所述目标测试音频对应的相近词mask矩阵的步骤,包括:
11、若所述目标测试音频对应的真实控制命令词的得分不是最大得分,则将所述预设控制命令词列表中得分比所述真实控制命令词的得分高的命令词设为候选竞争词;
12、将所述候选竞争词在所述相近词mask矩阵中对应的元素值设为-1和将所述真实控制命令词在所述相近词mask矩阵中对应的元素值设为1;以及,
13、若所述目标测试音频对应的真实控制命令词的得分为最大得分,则将所述预设控制命令词列表中得分高于预设阈值的命令词设为所述候选竞争词;
14、并将所述候选竞争词在所述相近词mask矩阵中对应的元素值设为-1和将所述真实控制命令词在所述相近词mask矩阵中对应的元素值设为1。
15、在一些实施例中,所述预设测试集包括多个内容相同的目标测试音频。
16、在一些实施例中,所述预设目标函数由如下公式获得:
17、
18、其中,为预设目标函数,为初始目标函数,为区分度目标函数,为超参数。
19、在一些实施例中,所述区分度目标函数的数值计算包括如下步骤:
20、计算所述初始控制命令词识别模型的输出在所述预设控制命令词列表中每个命令词的路径上的路径得分;
21、将所述路径得分与所述相近词mask矩阵相乘,获得所述区分度目标函数的数值。
22、本申请还提供一种音频识别模型训练装置,所述音频识别模型用于控制命令词的识别,所述装置包括:
23、初始控制命令词识别模型训练模块,用于训练获得初始控制命令词识别模型;
24、命令词得分获取模块,将预设测试集中预设数量的目标测试音频输入所述初始控制命令词识别模型,获得所述目标测试音频对应于预设控制命令词列表中每个命令词的得分,其中,所述目标测试音频基于实际的语音控制应用场景获得;
25、相近词mask矩阵获得模块,用于基于每个所述命令词的得分与预设标记规则,生成与所述目标测试音频对应的相近词mask矩阵;
26、目标音频识别模型获取模块,用于基于所述相近词mask矩阵以及预设目标函数,对所述初始控制命令词识别模型进行再训练,获得目标音频识别模型,其中,所述预设目标函数由用于训练所述初始控制命令词识别模型的初始目标函数与区分度目标函数加权获得。
27、本申请还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述任一实施例提供的音频识别模型训练方法的步骤。
28、本申请还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述任一实施例提供的音频识别模型训练方法的步骤。
29、有益效果:
30、本申请所提供的一种音频识别模型训练方法、装置、计算机设备及存储介质,通过预先训练通用音频识别模型作为初始控制命令词识别模型,并基于初始控制命令词识别模型获得目标测试音频对应于预设控制命令词列表中每个命令词的得分,从而生成与目标测试音频对应的相近词mask矩阵,然后基于相近词mask矩阵以及预设目标函数,对初始控制命令词识别模型进行再训练,获得目标音频识别模型,其中,目标测试音频基于实际的语音控制应用场景获得,预设目标函数由用于训练初始控制命令词识别模型的初始目标函数与区分度目标函数加权获得。由于在音频识别模型训练过程中,增设了区分度目标函数,提高了音频识别模型对各控制命令词的区分度识别的能力,且相似词mask矩阵的计算结合了实际的语音控制应用场景数据,提高了音频识别模型对不同语音控制应用场景的适配能力,从而有效降低相似控制命令词的误识别的概率。
技术特征:
1.一种音频识别模型训练方法,其特征在于,所述音频识别模型用于控制命令词的识别,所述方法包括:
2.根据权利要求1所述的音频识别模型训练方法,其特征在于,所述初始目标函数为ctc目标函数。
3.根据权利要求1所述的音频识别模型训练方法,其特征在于,所述训练获得初始控制命令词识别模型的步骤,包括:
4.根据权利要求1所述的音频识别模型训练方法,其特征在于,所述相近词mask矩阵的初始元素值均为0,所述基于每个所述命令词的得分与预设标记规则,生成与所述目标测试音频对应的相近词mask矩阵的步骤,包括:
5.根据权利要求4所述的音频识别模型训练方法,其特征在于,所述预设测试集包括多个内容相同的目标测试音频。
6.根据权利要求2所述的音频识别模型训练方法,其特征在于,所述预设目标函数由如下公式获得:
7.根据权利要求6所述的音频识别模型训练方法,其特征在于,所述区分度目标函数的数值计算包括如下步骤:
8.一种音频识别模型训练装置,其特征在于,所述音频识别模型用于控制命令词的识别,所述装置包括:
9.一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1-7任一项所述的音频识别模型训练方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1-7任一项所述的音频识别模型训练方法的步骤。
技术总结
本申请属于深度学习技术领域,特别涉及一种音频识别模型训练方法、装置、计算机设备及存储介质。方法包括:训练获得初始控制命令词识别模型;将预设测试集中的其中一个目标测试音频输入所述初始控制命令词识别模型,获得所述目标测试音频对应于预设控制命令词列表中每个命令词的得分,其中,所述目标测试音频基于实际的语音控制应用场景获得;基于每个所述命令词的得分与预设标记规则,生成与所述目标测试音频对应的相近词mask矩阵;基于所述相近词mask矩阵以及预设目标函数,对所述初始控制命令词识别模型进行再训练,获得目标音频识别模型。本申请可降低相似控制命令词的音频误识别的概率。
技术研发人员:李杰,王广新,杨汉丹
受保护的技术使用者:深圳市友杰智新科技有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!