一种语音驱动图像的方法、系统、装置及存储介质与流程
本发明涉及计算机,尤其涉及一种语音驱动图像的方法、系统、装置及存储介质。
背景技术:
1、随着3d视频内容丰富多样性不断的增长与数字虚拟人应用场景的快速发展,对3d数字虚拟人的相关内容产出提出了更高质量与更高效率的创作需求。通过快速的产出生成3d数字虚拟人时的唇形动作、面部表情,可以帮助观众更生动的理解对话内容。视觉动画和听觉声音的双模态信息融合的表达方式,不仅能提高用户对内容的理解度,还能在需要交互的场景中提供一种更为准确的体验,以及提高3d虚拟数字人的艺术性和观赏度。
2、目前制作3d人物唇形表情动画的技术方案包括以下类型:第一是通过专业的动画师听取音频内容,通过人力手工的方式制作出声音与人物动画唇形表匹配的关键帧动画;第二是通过动作捕捉设备捕捉专业演员的面部唇形表情,再由人力对捕捉的数据进行二次修整调节,最后导入渲染引擎驱动人物面部唇形表情运动。以上两种方案都需要耗费大量的人力与时间成本,并且不同的人和设备对最后产出的内容稳定性都有影响。
技术实现思路
1、有鉴于此,本发明实施例的目的是提供一种语音驱动图像的方法、系统、装置及存储介质,能够根据输入语音驱动图像生成包含唇形和表情的三维动画,效率高,稳定性好。
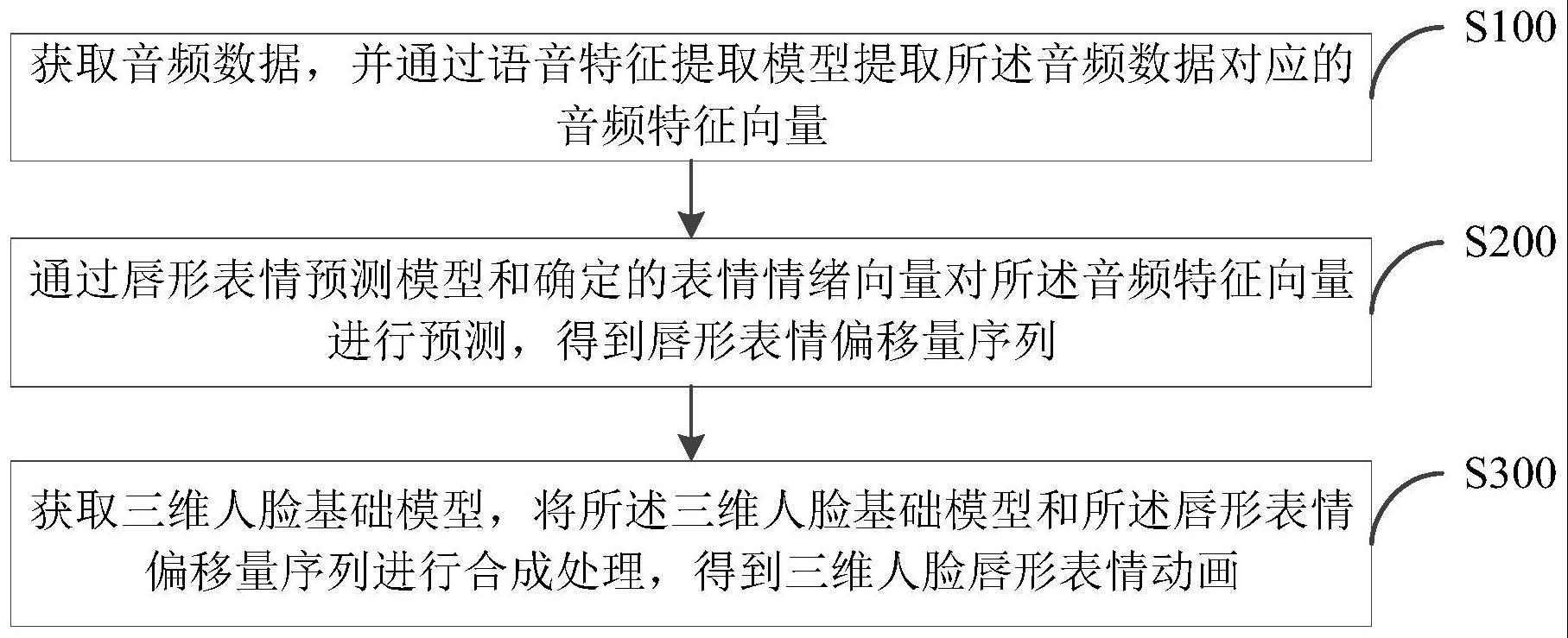
2、第一方面,本发明实施例提供了一种语音驱动图像的方法,包括以下步骤:
3、获取音频数据,并通过语音特征提取模型提取所述音频数据对应的音频特征向量;
4、通过唇形表情预测模型和确定的表情情绪向量对所述音频特征向量进行预测,得到唇形表情偏移量序列;
5、获取三维人脸基础模型,将所述三维人脸基础模型和所述唇形表情偏移量序列进行合成处理,得到三维人脸唇形表情动画。
6、可选地,所述语音特征提取模型包括卷积神经网络和双向长短记忆网络,所述通过语音特征提取模型提取所述音频数据对应的音频特征向量,具体包括:
7、将所述音频数据对应的一维向量输入到所述卷积神经网络,得到高层次的语音特征;
8、将所述高层次的语音特征输入到所述双向长短记忆网络,得到音频特征向量。
9、可选地,所述语音特征提取模型的训练过程包括:
10、获取语音样本数据及对应的真实语音样本特征向量;
11、将所述语音样本数据输入到初始模型,提取预测语音样本特征向量;
12、根据所述预测语音样本特征向量与所述真实语音样本特征向量之间的误差,对所述初始模型的模型参数进行调整,直至所述初始模型输出的预测语音样本特征向量与真实语音样本特征向量之间的误差满足训练要求,得到所述语音特征提取模型。
13、可选地,所述唇形表情预测模型包括transformer神经网络模型,所述transformer神经网络模型包括编码器网络和解码器网络,所述通过唇形表情预测模型和确定的表情情绪向量对所述音频特征向量进行预测,得到唇形表情偏移量序列,具体包括:
14、将所述音频特征向量输入到编码器网络,得到音频信息表征向量序列;
15、将所述音频信息表征向量序列和确定的表情情绪向量输入解码器网络,得到唇形表情偏移量序列。
16、可选地,所述唇形表情预测模型的训练过程包括:
17、获取说话人多个视角的视频样本数据,并根据所述视频数据建立三维点云人脸序列,并根据所述三维点云人脸序列确定真实人脸唇形表情偏移量;
18、提取视频样本数据的语音样本数据,并将所述三维点云人脸序列与语音样本数据进行匹配标注,形成样本数据对;
19、将样本数据对中的语音样本数据输入到编码器网络,得到音频样本信息表征向量;
20、将音频样本信息表征向量、样本数据对中的三维点云人脸序列和随机生成的表情情绪向量输入到解码器网络,得到预测人脸唇形表情偏移量;
21、根据目标损失函数计算真实人脸唇形表情偏移量与预测人脸唇形表情偏移量之间的损失值,并根据所述损失值对编码器网络、解码器网络和目标损失函数进行更新,得到transformer神经网络模型。
22、可选地,所述目标损失函数的计算公式如下:
23、loss=sl×llip+sf×lface+sr×lreg
24、其中,loss表示损失值,llip表示唇形区域的损失值,sl表示唇形区域的影响系数,lface表示唇形区域以外的人脸表情区域的损失值,sf表示唇形区域以外的人脸表情区域的影响系数,lreg表示表情正则项的损失值,sr表示表情正则项的影响系数。
25、可选地,所述表情情绪向量通过以下方式获取:
26、将唇形表情预测模型训练过程中学习得到的表情情绪向量确定为表情情绪向量;
27、或,获取表情信息,根据所述表情信息确定表情情绪向量。
28、第二方面,本发明实施例提供了一种语音驱动图像的系统,包括:
29、第一模块,用于获取音频数据,并通过语音特征提取模型提取所述音频数据对应的音频特征向量;
30、第二模块,用于通过唇形表情预测模型和确定的表情情绪向量对所述音频特征向量进行预测,得到唇形表情偏移量序列;
31、第三模块,用于获取三维人脸基础模型,将所述三维人脸基础模型和所述唇形表情偏移量序列进行合成处理,得到三维人脸唇形表情动画。
32、第三方面,本发明实施例提供了一种语音驱动图像的装置,包括:
33、至少一个处理器;
34、至少一个存储器,用于存储至少一个程序;
35、当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现上述的方法。
36、第四方面,本发明实施例提供了一种存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行上述的方法。
37、实施本发明实施例包括以下有益效果:本实施例通过语音特征提取模型提取音频数据对应的音频特征向量,以使唇形表情预测模型可以适应不同的语言,然后通过唇形表情预测模型和确定的表情情绪向量对音频特征向量进行预测得到唇形表情偏移量序列,得到唇形和表面的变化量,然后根据三维人脸基础模型和唇形表情偏移量序列得到三维人脸唇形表情动画,从而实现根据语音驱动图像生成包含唇形和表情的三维动画,效率高,稳定性好。
技术特征:
1.一种语音驱动图像的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述语音特征提取模型包括卷积神经网络和双向长短记忆网络,所述通过语音特征提取模型提取所述音频数据对应的音频特征向量,具体包括:
3.根据权利要求2所述的方法,其特征在于,所述语音特征提取模型的训练过程包括:
4.根据权利要求1所述的方法,其特征在于,所述唇形表情预测模型包括transformer神经网络模型,所述transformer神经网络模型包括编码器网络和解码器网络,所述通过唇形表情预测模型和确定的表情情绪向量对所述音频特征向量进行预测,得到唇形表情偏移量序列,具体包括:
5.根据权利要求4所述的方法,其特征在于,所述唇形表情预测模型的训练过程包括:
6.根据权利要求5所述的方法,其特征在于,所述目标损失函数的计算公式如下:
7.根据权利要求1所述的方法,其特征在于,所述表情情绪向量通过以下方式获取:
8.一种语音驱动图像的系统,其特征在于,包括:
9.一种语音驱动图像的装置,其特征在于,包括:
10.一种存储介质,其中存储有处理器可执行的程序,其特征在于,所述处理器可执行的程序在由处理器执行时用于执行如权利要求1-7任一项所述的方法。
技术总结
本发明公开了一种语音驱动图像的方法、系统、装置及存储介质,包括:获取音频数据,并通过语音特征提取模型提取所述音频数据对应的音频特征向量;通过唇形表情预测模型和确定的表情情绪向量对所述音频特征向量进行预测,得到唇形表情偏移量序列;获取三维人脸基础模型,将所述三维人脸基础模型和所述唇形表情偏移量序列进行合成处理,得到三维人脸唇形表情动画。本发明实施例能够根据输入语音驱动图像生成包含唇形和表情的三维动画,效率高,稳定性好,可广泛应用于计算机技术领域。
技术研发人员:李权,杨锦,彭绪坪,叶俊杰,王伦基,成秋喜,付玟
受保护的技术使用者:广州赛灵力科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!