一种基于ADRMFCC融合特征的语音识别方法
发明涉及语音识别,特别涉及一种基于adrmfcc融合特征的语音识别方法。
背景技术:
1、随着科技的发展和人工智能的兴起,语音识别技术已经成为人们日常生活中不可或缺的一部分。然而,传统的语音识别技术在噪声干扰、说话人变化等方面仍然存在一定的局限性,因此如何提高语音识别的准确率一直是研究的重点之一。为了克服这些问题,越来越多的研究者开始关注语音特征提取技术,特征提取是语音信号处理中的关键步骤,直接影响着后续任务效果。
2、目前主流的语音特征主要包括基于声学层特征和音素层特征,例如梅尔频率倒谱系数,gammatone频率倒谱系数,以及线性预测倒谱系数等。然而,在嘈杂环境下,这些特征很容易受到干扰,导致识别效果不佳。另一方面,基于音素层的识别方法将语音信号分割成若干个音素单元,并将每个音素单元映射到对应的音素库中的音素单元,得到一个表示整个语音信号的音素序列。最后,通过分析这个音素序列的特征,例如音素出现的概率和音素之间的转移概率等,来对整个语音信号进行识别。相对于声学层特征,基于音素层特征的语音识别方法受噪声环境的影响较小。然而,由于音素的切分提取较为困难,因此识别性能可能会下降。
3、随着深度学习被引入语音识别领域,由wang z等提出将mfcc中梅尔滤波器进行翻转得到imfcc特征,该特征可以获取语音高频特征信息,结合mfcc特征以表征更全面的语音信息。由zhao等提出的fbank特征提取时基于滤波器组对音频进行滤波,可以捕获音频的重要信息,但fbank特征只考虑了音频的频率分布信息,对于其他音频的特征信息如时域和能量信息等没有涉及,导致识别效果不好。为了克服mfcc和fbank特征提取的缺点,本发明提出在rmfcc特征中引入残差信号概念,提取语音信号中不能被mfcc所描述的残余信息,可以有效地提高语音识别的准确率。除此之外,各种深度学习框架也被应用于语音识别任务,包括深度神经网络(dnn,deep neural network),长短时记忆神经网络(lstm,long short-term memory),循环神经网络(rnn,recurrent neural network)双向循环神经网络(birnn,bidirectional recurrent neural network,birnn)等神经网络模型。本发明采用birnn作为语音识别任务模型。birnn能够利用过去和未来的信息,可以有效地捕捉长期依赖关系,对当前的状态进行更全面的建模,因此对于需要考虑上下文信息的任务,如语音识别、自然语言处理等,具有较好的效果。不仅如此,birnn可以减少梯度消失和梯度爆炸的问题,因为反向循环神经网络可以补充正向循环神经网络中可能丢失的信息。
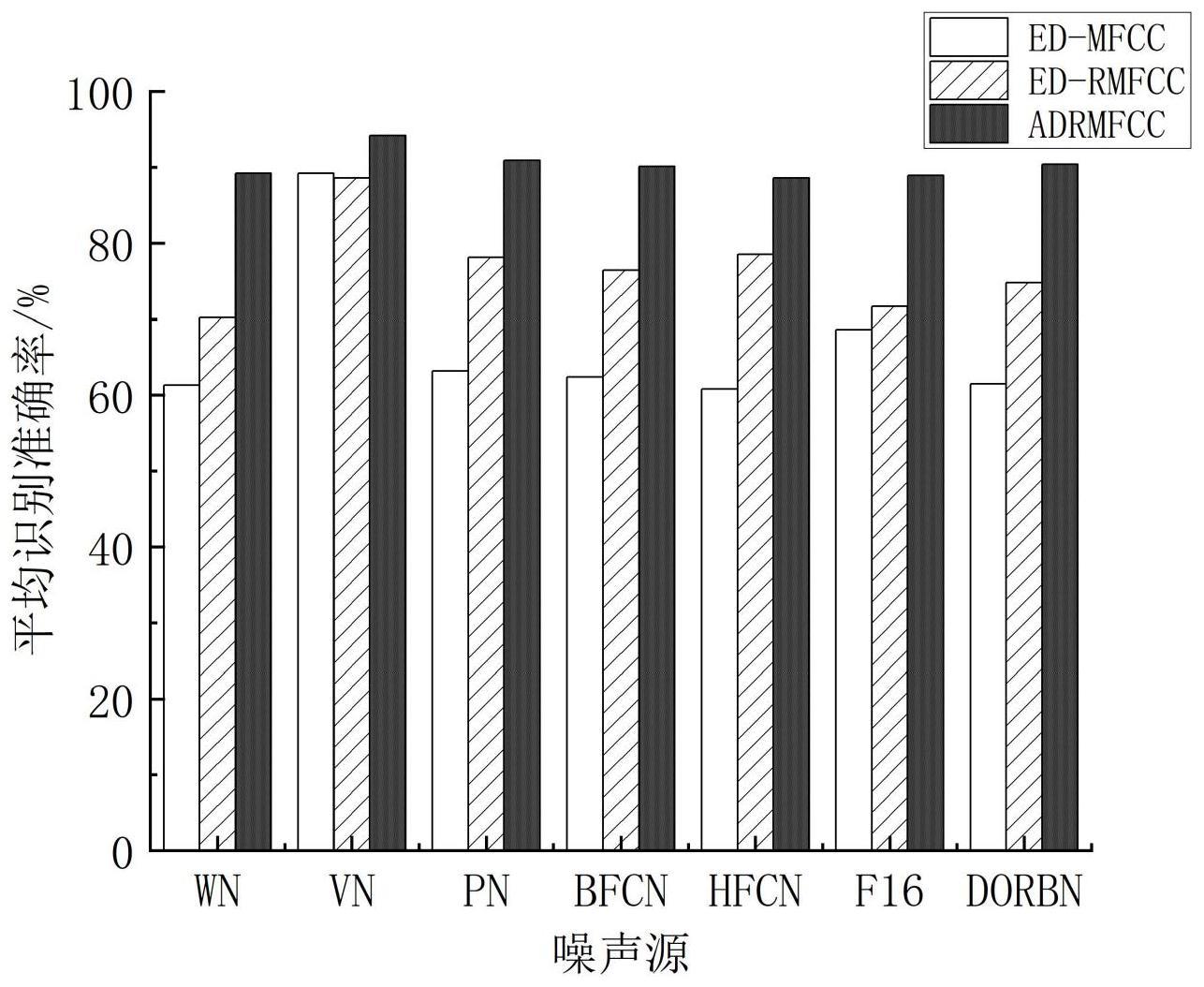
4、针对复杂噪声环境下的语音识别准确率低和鲁棒性差的问题,本发明提出了一种基于增减残差梅尔倒谱系数(adrmfcc,addition-deletion residual mel frequencycepstral coefficients)的语音识别方法。该方法首先利用基于增减分量法的语音贡献度特征筛选方式对mfcc和rmfcc特征进行筛选。然后将这两种特征进行融合拼接生成adrmfcc特征。并将处理后的融合特征adrmfcc送入双向循环神经网络进行识别。实验结果表明,在不同的噪声种类和信噪比条件下,本发明所提出的方法显著提高了语音识别性能。
技术实现思路
1、本发明的目的是提供一种基于adrmfcc融合特征的语音识别方法,旨在解决上述技术问题。
2、本发明的上述技术目的是通过以下技术方案得以实现的:
3、一种基于adrmfcc融合特征的语音识别方法,其特征在于,包括以下步骤:
4、s1、mfcc特征提取,在特征提取过程中,1)首先将语音信号分帧,并对每一帧进行加窗处理;2)接下来对每一帧进行fft变换,得到该帧语音信号的频谱;3)然后使用一组梅尔滤波器将频谱转换为梅尔频率谱,并对梅尔频率谱取对数运算,得到的是以db为单位的对数谱;4)最后对对数谱进行离散余弦变换,得到mfcc特征;一般使用20-40个滤波器,得到20-40维度的特征向量;在使用mfcc特征时需要对特征进行归一化处理,以保证不同特征维度的重要性相同,第i帧第j维的mfcc为:
5、
6、其中:i=1,2,l,i,i为语音参数;j=1,2,l,jm,jm为mfcc维度;m为滤波器数量;m为滤波器,将i′jm维的mfcc特征矩阵表示为m;
7、s2、rmfcc特征提取,具体的计算步骤如下:
8、1)对语音信号x(n)分帧加窗,使用的是汉明窗,分帧加窗后的第i帧信号为xi(n);
9、2)对xi(n)进行离散傅里叶变换,有
10、
11、其中n为离散傅里叶变换的点数;
12、3)si(k)的功率谱密度为
13、pi(k)=|si(k)|2 (3)
14、4)对每帧的功率谱进行lpc分析,得到lpc系数,使用lpc系数对每帧的音频信号进行线性预测编码,得到lpc预测信号;
15、
16、5)将原始音频信号与lpc预测信号作差,得到残差信号;
17、
18、6)使用mel滤波器组将残差信号转换为mel频率谱;
19、
20、其中r(k,i)为第k帧dft结果,hm(i)为第m个梅尔滤波器响应,
21、7)对mel频率谱进行倒谱变换,得到rmfcc;
22、
23、其中m是梅尔滤波器数量,sm(k,m)是第k帧残差信号经过第m个梅尔滤波器的响应,n为rmfcc系数阶数;
24、s3、基于增减分量法的融合特征adrmfcc,去除不必要的维度成分,得到mfcc与rmfcc中含有对语音识别有贡献度的特征维度,增减分量法的平均贡献度函数如下:
25、
26、其中gi表示贡献度,p(i,j)表示第i维到第j维特征作为语音特征参数时的识别准确率,首先检测特征参数每个维数i~j组合的识别率,然后由上式计算每个维度的贡献度。
27、与现有技术相比,本发明具有以下有益效果:
28、该方法利用基于增减分量法的语音贡献度的特征筛选方式对mfcc和rmfcc特征进行筛选,然后将两种特征进行融合拼接后得到adrmfcc特征。并将处理后的融合特征adrmfcc送入双向循环神经网络进行识别。不同噪声源下的语音识别准确率均有所提升,且鲁棒性也有所增强,所提方法适用于复杂噪声环境下的语音识别。
技术特征:
1.一种基于adrmfcc融合特征的语音识别方法,其特征在于,包括以下步骤:
技术总结
针对复杂噪声环境下的语音识别准确率低和鲁棒性差的问题,本发明提出了一种基于ADRMFCC融合特征的语音识别方法。该方法利用增减分量法筛选残差梅尔倒谱系数(RMFCC)与梅尔倒谱系数(MFCC)各维度特征的语音贡献度改进语音识别性能,接着将筛选后的特征进行拼接融合,最后将处理好的融合特征ADRMFCC送入双向循环神经网络进行识别。实验结果表明,本发明所提方法在在不同的噪声种类和信噪比条件下远高于其单一特征下的识别准确率和性能,在‑5dB低信噪比条件下可以打到73%以上的识别准确率,在其他噪声源下的平均正确率达到90%左右。证明本发明所提方法的有效性和鲁棒性。
技术研发人员:马建,朵琳,韦贵香
受保护的技术使用者:昆明理工大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!