语音识别方法及相关装置、电子设备和存储介质与流程
本申请涉及音频数据处理,特别是涉及一种语音识别方法及相关装置、电子设备和存储介质。
背景技术:
1、如今,语音识别技术已经被广泛应用于各种人机交互场景,如语音助手、语音搜索、语音输入法等。而相较于传统语音识别,端到端语音识别框架,逐渐成为一种趋势,即直接将音频序列转化为文本序列。
2、然而,说话过程中通常并非全程均是有效语音,还可能存在诸如噪声等无效音频。然而,现有技术在识别过程中,不仅对有效语音进行识别并输出,也会误识别噪音等无效音频并输出,对噪声的拒识能力较低,导致语音识别结果的准确性难以保障。有鉴于此,如何增强对噪声的拒识能力,以尽可能提升语音识别的准确性,成为亟待解决的问题。
技术实现思路
1、本申请主要解决的技术问题是提供一种语音识别方法及相关装置、电子设备和存储介质,能够增强对噪声的拒识能力,以尽可能提升语音识别的准确性。
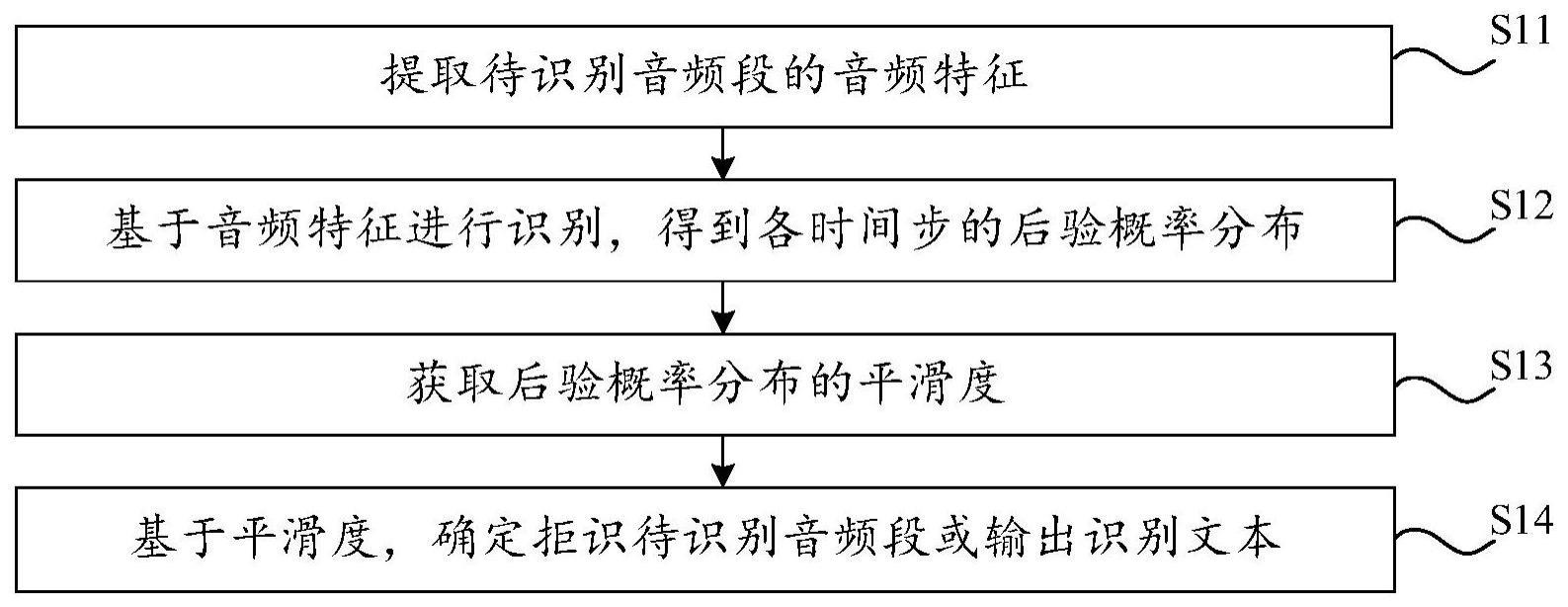
2、为了解决上述技术问题,本申请第一方面提供了一种语音识别方法,包括:提取待识别音频段的音频特征;基于音频特征进行识别,得到各时间步的后验概率分布;其中,每个时间步的后验概率分布包括对应时间步的识别字词属于预设词典中各个预设字词的概率值,且待识别音频段的识别文本由各时间步的后验概率分布得到;获取后验概率分布的平滑度;基于平滑度,确定拒识待识别音频段或输出识别文本。
3、为了解决上述技术问题,本申请第二方面提供了一种语音识别装置,包括提取模块、识别模块、获取模块和确定模块。其中,提取模块用于提取待识别音频段的音频特征;识别模块用于基于音频特征进行识别,得到各时间步的后验概率分布;其中,每个时间步的后验概率分布包括对应时间步的识别字词属于预设词典中各个预设字词的概率值,且待识别音频段的识别文本由各时间步的后验概率分布得到;获取模块用于获取后验概率分布的平滑度;确定模块用于基于平滑度,确定拒识待识别音频段或输出识别文本。
4、为了解决上述技术问题,本申请第三方面提供了一种电子设备,包括相互耦接的存储器和处理器,存储器中存储有程序指令,处理器用于执行程序指令以实现上述第一方面中的语音识别方法。
5、为了解决上述技术问题,本申请第四方面提供了一种计算机可读存储介质,存储有能够被处理器运行的程序指令,程序指令用于实现上述第一方面中的语音识别方法。
6、上述方案,通过提取待识别音频段的音频特征,并基于音频特征进行识别,得到各时间步的后验概率分布,每个时间步的后验概率分布包括对应时间步的识别字词属于预设词典中各个预设字词的概率值,且待识别音频段的识别文本由各时间步的后验概率分布得到,再获取后验概率分布的平滑度,基于平滑度,确定拒识待识别音频段或输出识别文本,一方面基于平滑度,可以在待识别音频段为无效音频的情况下,确定拒识待识别音频,进而尽可能地增强对噪声的拒识能力,另一方面基于平滑度,在确定待识别音频段为有效音频的情况下,再输出待识别音频段的识别文本,进而尽可能地提升语音识别的准确性。此外,相较于在语音识别过程中对音频内容进行识别直接输出识别文本,通过后验概率分布的平滑度,先确定是否拒识待识别音频段,在确定无需进行拒识之后,再输出识别文本,尽可能地增强对噪声的拒识能力,节省资源并提高用户的使用体验。故此,能够增强对噪声的拒识能力,以尽可能提升语音识别的准确性。
7、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本申请。
技术特征:
1.一种语音识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,在所述提取待识别音频段的音频特征之前,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,所述获取所述后验概率分布的平滑度,包括:
4.根据权利要求3所述的方法,其特征在于,所述基于所述各个时间步的概率差值,得到所述平滑度,包括以下任一者:
5.根据权利要求1所述的方法,其特征在于,在所述基于所述平滑度,确定拒识所述待识别音频段或输出所述识别文本之前,所述方法还包括:
6.根据权利要求5所述的方法,其特征在于,所述获取用于确定是否拒识的判断阈值,包括:
7.根据权利要求1所述的方法,其特征在于,在所述基于所述平滑度,确定拒识所述待识别音频段或输出所述识别文本之后,所述方法还包括:
8.一种语音识别装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括相互耦接的存储器和处理器,所述存储器中存储有程序指令,所述处理器用于执行所述程序指令以实现权利要求1至7任一项所述的语音识别方法。
10.一种计算机可读存储介质,其特征在于,存储有能够被处理器运行的程序指令,所述程序指令用于实现权利要求1至7任一项所述的语音识别方法。
技术总结
本申请公开了一种语音识别方法及相关装置、电子设备和存储介质,其中,语音识别方法包括:提取待识别音频段的音频特征,并基于音频特征进行识别,得到各时间步的后验概率分布;其中,每个时间步的后验概率分布包括对应时间步的识别字词属于预设词典中各个预设字词的概率值,且待识别音频段的识别文本由各时间步的后验概率分布得到;再获取后验概率分布的平滑度,并基于平滑度,确定拒识待识别音频段或输出识别文本。上述方案,能够增强对噪声的拒识能力,以尽可能提升语音识别的准确性。
技术研发人员:胡今朝,欧阳鹏翔,吴重亮,马志强,李永超
受保护的技术使用者:安徽讯飞寰语科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!