一种语音信号合成方法、装置、电子设备及存储介质与流程
本发明实施例涉及语音处理,尤其涉及一种语音信号合成方法、装置、电子设备及存储介质。
背景技术:
1、随着社会信息化、智能化进程的推进,智能交互越来越成为一种必要性,智能语音交互是智能交互的主要交互方式之一,在汽车、家居、手机等产品上都有对智能语音交互的集成,特别在汽车领域,语音交互在汽车的应用已经变成不可或缺的功能,语音交互涉及语音识别、自然语言处理、语音信号合成等重要环境。目前业界进行语音信号合成的方法主要有基于规则、基于统计、基于深度学习和基于混合模型等几种方法,这些方法都存在以下缺陷:多个任务单独训练模型,需要大量的数据、计算资源和内存空间,易造成很大的资源浪费,导致语音信号合成的速率较低;多个任务单独训练模型,模型无法适应不同的任务,导致语音信号合成的精度不足、准确率低。
技术实现思路
1、本发明提供了一种语音信号合成方法、装置、电子设备及存储介质,以实现准确且高效的语音信号合成。
2、第一方面,本发明实施例提供了一种语音信号合成方法,包括:
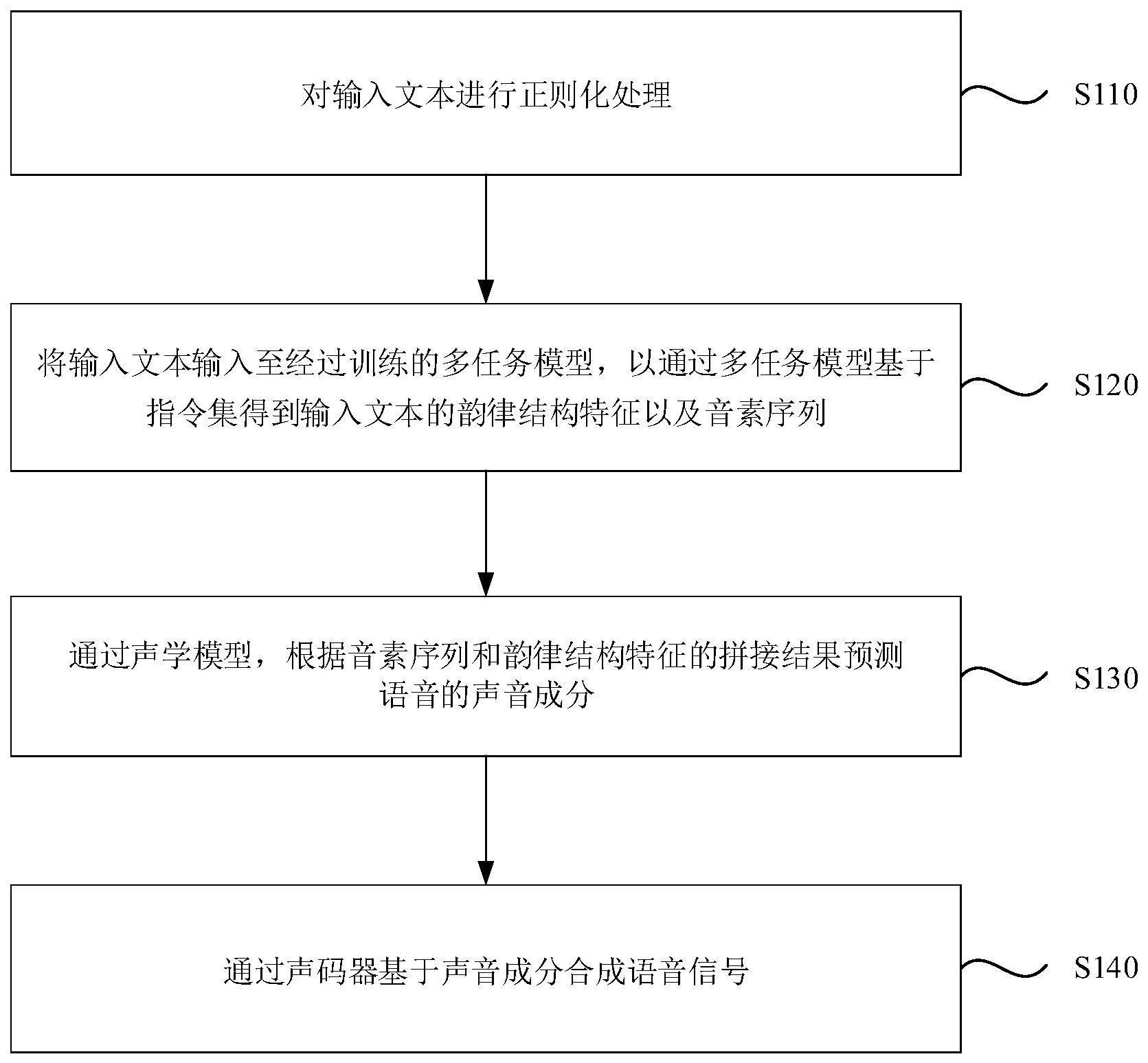
3、对输入文本进行正则化处理;
4、将输入文本输入至经过训练的多任务模型,以通过多任务模型基于指令集得到输入文本的韵律结构特征以及音素序列;
5、通过声学模型,根据音素序列和韵律结构特征的拼接结果预测语音的声音成分;
6、通过声码器基于声音成分合成语音信号。
7、第二方面,本发明实施例提供了一种语音信号合成装置,包括:
8、文本处理模块,用于对输入文本进行正则化处理;
9、音律特征获取模块,用于将输入文本输入至经过训练的多任务模型,以通过多任务模型基于指令集得到输入文本的韵律结构特征以及音素序列;
10、成分拼接模块,用于通过声学模型,根据音素序列和韵律结构特征的拼接结果预测语音的声音成分;
11、语音合成模块,用于通过声码器基于声音成分合成语音信号。
12、第三方面,本发明实施例提供了一种电子设备,包括:
13、至少一个处理器;以及
14、与至少一个处理器通信连接的存储器;其中,
15、存储器存储有可被至少一个处理器执行的计算机程序,计算机程序被至少一个处理器执行,以使至少一个处理器能够执行如第一方面所述的语音信号合成方法。
16、第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如第一方面所述的语音信号合成方法。
17、本发明实施例提供了一种语音信号合成方法、装置、电子设备及存储介质,首先通过对输入文本进行正则化处理;再将输入文本输入至经过训练的多任务模型,以通过多任务模型基于指令集得到输入文本的韵律结构特征以及音素序列;再通过声学模型,根据音素序列和韵律结构特征的拼接结果预测语音的声音成分;最后通过声码器基于声音成分合成语音信号。上述技术方案,通过多任务模型基于指令集将输入文本转换为对应的韵律结构特征和音素序列,最后通过声学模型和声码器将音素序列和韵律结构特征合成语音信号,避免了为每个任务单独构建多任务模型,从而降低了多任务模型的复杂度,增强了文本转音素的精度和质量,提高了语音信号合成的处理效率和准确性,有助于在多语言场景中更加准确地预测出语音信号合成中的发音信息。
18、应当理解,本部分所描述的内容并非旨在标识本发明实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其他特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种语音信号合成方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,还包括:
3.根据权利要求2所述的方法,其特征在于,在基于指令数据集对所述多任务模型进行训练之前,还包括:
4.根据权利要求2所述的方法,其特征在于,所述指令数据集还包括包含韵律预测指令和音素预测指令的验证数据以及包含韵律预测指令和音素预测指令的测试数据;
5.根据权利要求3所述的方法,其特征在于,根据指令模板对所述韵律结构文本数据进行标注,包括:
6.根据权利要求1所述的方法,其特征在于,通过声码器基于所述声音成分合成语音信号,包括:
7.根据权利要求1所述的方法,其特征在于,所述多任务模型基于预训练语言模型构建,所述预训练语言模型的词汇表由预训练模型词汇、韵律音素以及文本音素构成。
8.一种语音信号合成装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-7中任一所述的语音信号合成方法。
技术总结
本发明公开了一种语音信号合成方法、装置、电子设备及存储介质。该方法包括:对输入文本进行正则化处理;将输入文本输入至经过训练的多任务模型;通过声学模型,根据音素序列和韵律结构特征的拼接结果预测语音的声音成分;通过声码器基于声音成分合成语音信号。上述技术方案,通过多任务模型基于指令集将输入文本转换为对应的韵律结构特征和音素序列,最后通过声学模型和声码器将音素序列和韵律结构特征合成语音信号,避免了为每个任务单独构建多任务模型,从而降低了多任务模型的复杂度,增强了文本转音素的精度和质量,提高了语音信号合成的处理效率和准确性,有助于在多语言场景中更加准确地预测出语音信号合成中的发音信息。
技术研发人员:梁小明,何金鑫,张毅,孙宇嘉,王紫烟,付振,王明月
受保护的技术使用者:中国第一汽车股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!