处理音频数据的方法及装置、音频数据处理设备和介质与流程
本公开涉及人工智能领域,更具体地,涉及处理音频数据的方法以及装置、音频数据处理设备和存储介质。
背景技术:
1、语音交互技术在现代社会中扮演着越来越重要的角色。随着诸如智能手机、智能音箱和语音助手等的语音交互设备的普及,人们越来越多地使用语音交互来完成各种任务,诸如发送短信、查询信息和控制智能家居设备等。
技术实现思路
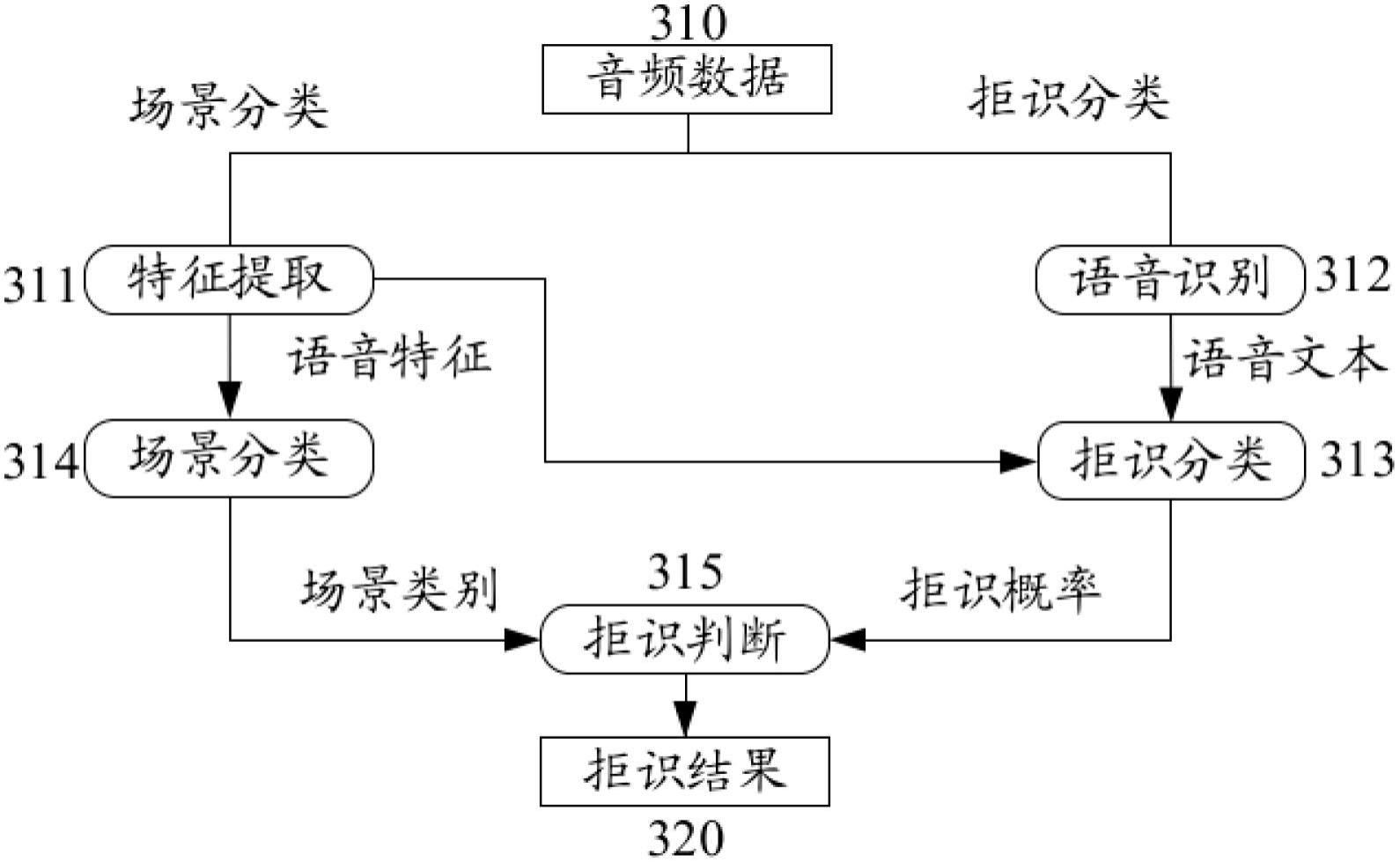
1、本公开的至少一实施例提供了一种处理音频数据的方法,所述方法包括:从由语音交互设备获取的音频数据中提取语音特征;对所述音频数据进行语音识别,以获得与所述音频数据相对应的语音文本;基于所述语音特征和所述语音文本,确定对所述音频数据的拒识概率;基于所述语音特征,确定所述音频数据所属的场景类别;以及基于所确定的拒识概率和场景类别,确定对所述音频数据的拒识结果,所述拒识结果指示所述语音交互设备是否对所述音频数据进行拒识。
2、本公开的至少一实施例提供了一种音频数据处理装置,包括:语音特征提取模块,被配置为从由语音交互设备获取的音频数据中提取语音特征;语音文本生成模块,被配置为对所述音频数据进行语音识别,以获得与所述音频数据相对应的语音文本;拒识概率确定模块,被配置为基于所述语音特征和所述语音文本,确定对所述音频数据的拒识概率;场景类别确定模块,被配置为基于所述语音特征,确定所述音频数据所属的场景类别;以及拒识结果确定模块,被配置为基于所确定的拒识概率和场景类别,确定对所述音频数据的拒识结果,所述拒识结果指示所述语音交互设备是否对所述音频数据进行拒识。
3、本公开的至少一实施例提供了一种音频数据处理设备,包括:处理器;以及存储器,其中,所述存储器中存储有计算机可执行程序,当由所述处理器执行所述计算机可执行程序时,执行如上所述的处理音频数据的方法。
4、本公开的至少一实施例提供了一种计算机可读存储介质,其上存储有计算机可执行指令,所述指令在被处理器执行时用于实现如上所述的处理音频数据的方法。
5、本公开的至少一实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行根据本公开的至少一实施例的处理音频数据的方法。
技术特征:
1.处理音频数据的方法,所述方法包括:
2.如权利要求1所述的方法,其中,所述音频数据是由所述语音交互设备在一时间段内获取的;
3.如权利要求1所述的方法,其中,对所述音频数据进行语音识别,以获得与所述音频数据相对应的语音文本,包括:
4.如权利要求1所述的方法,其中,基于所述语音特征和所述语音文本,确定对所述音频数据的拒识概率,包括:
5. 如权利要求2所述的方法,其中,基于所述语音特征,确定所述音频数据所属的场景类别,包括:
6.如权利要求5所述的方法,其中,基于所述语音特征,确定所述音频数据所属的场景类别,还包括:
7.如权利要求6所述的方法,其中,基于所述音频数据在所述时间段内所属的场景类别、以及所述语音交互设备在所述时间段前序的若干连续时间段内采集的历史音频数据在相应时间段内所属的场景类别,确定所述音频数据所属的场景类别,包括:
8.如权利要求7所述的方法,其中,所述预定条件包括:在所述音频数据在所述时间段内所属的场景类别和所述历史音频数据在相应时间段内所属的场景类别中出现概率最大、并且所述出现概率达到预定阈值。
9. 如权利要求1所述的方法,其中,基于所确定的拒识概率和场景类别,确定对所述音频数据的拒识结果,包括:
10. 如权利要求9所述的方法,其中,在所确定的拒识概率不满足预定拒识条件的情况下,基于所确定的场景类别确定对所述音频数据的拒识结果,包括:
11.如权利要求10所述的方法,其中,所述预定拒识条件包括:所确定的拒识概率小于预定拒识概率。
12.处理音频数据的装置,包括:
13. 音频数据处理设备,包括:
14.计算机程序产品,所述计算机程序产品存储在计算机可读存储介质上,并且包括计算机指令,所述计算机指令在由处理器运行时使得计算机设备执行权利要求1-11中任一项所述的方法。
15.计算机可读存储介质,其上存储有计算机可执行指令,所述指令在被处理器执行时用于实现如权利要求1-11中任一项所述的方法。
技术总结
本公开的至少一实施例提供了一种处理音频数据的方法和装置、音频数据处理设备和计算机可读存储介质。本公开的至少一实施例所提供的方法针对由语音交互设备获取的音频数据,分别从中提取语音特征和语音文本,继而基于语音特征和语音文本确定对音频数据的拒识概率,并且基于语音特征对该音频数据所属的场景进行分类,以联合所确定的拒识概率和场景分类结果共同确定语音交互设备对该音频数据的最终拒识结果。该方法能够利用包括声音和文本的多模态信息进行拒识概率确定,并且利用从音频数据中提取的场景信息来判断语音交互设备的当前使用场景是否属于交互场景,从而基于两类结果的融合实现更准确的语音交互拒识判断。
技术研发人员:李林峰,黄海荣,曹阳
受保护的技术使用者:湖北星纪魅族集团有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!