一种服务器、显示设备及数字人交互方法与流程
本申请涉及数字人交互,尤其涉及一种服务器、显示设备及数字人交互方法。
背景技术:
1、ai(artificial intelligence,人工智能)生成虚拟数字人视频是人工智能技术应用的一个全新领域,包括语音合成、语音识别、机器翻译、表情识别、人体动作识别、高清图像处理等多项先进技术。通过ai生成的虚拟人物可用于许多人机交互的场景,如新闻播报、课堂教育、养老陪护等。ai合成虚拟数字人是指通过智能系统自动读取并解析识别外界输入信息,根据解析结果决策虚拟数字人后续的输出文本,然后驱动学习模特说话时的唇动、以及姿态等。
2、为了提高虚拟数字人的生成效率,出现基于声音推理生成3d数字人方案,其主要是通过声音推理模型,采用声音推理生成人脸关键点,然后将该人脸关键点同通过3d人脸重建模型合成3d虚拟数字人。在上述过程中,利用语音驱动推理生成人的面部表情是一个比较困难的任务。这是由于不像声音的产生和嘴唇运动之间关系是确定性的,声音与面部不同情绪类别和强度的表达依赖关系是高度模糊的。结合上下文信息,从输入音频中提取情感特征并含蓄地嵌入到神经网络中来实现情感合成是目前最常见的解决方案。然而由于训练数据有限,这种解决方案不可避免地受到过度平滑回归的影响,并且通常导致有限的表达能力。
技术实现思路
1、本申请一些实施例提供了一种服务器、显示设备及数字人交互方法,根据用户输入的语音数据确定表情参数及口型参数,将表情参数及口型参数结合生成具有较好面部表情表达的数字人图像,实现情感定制和控制。
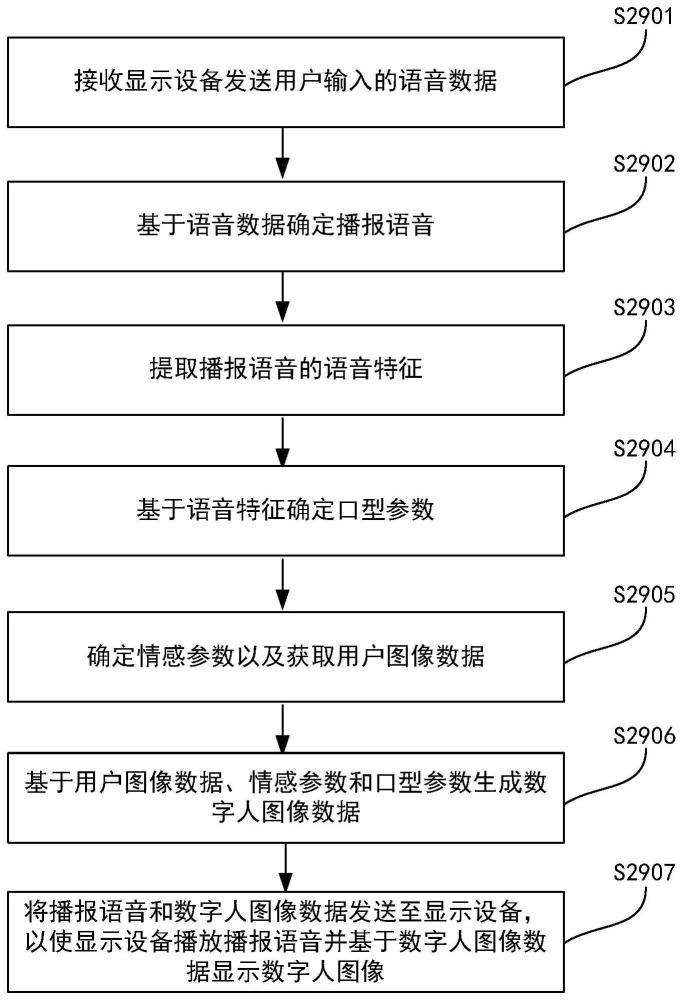
2、第一方面,本申请一些实施例中提供一种服务器,被配置为:
3、接收显示设备发送用户输入的语音数据;
4、基于所述语音数据确定播报语音;
5、提取所述播报语音的语音特征;
6、基于所述语音特征确定口型参数;
7、确定情感参数以及获取用户图像数据;
8、基于所述用户图像数据、所述情感参数和所述口型参数生成数字人图像数据;
9、将所述播报语音和所述数字人图像数据发送至所述显示设备,以使所述显示设备播放所述播报语音并基于所述数字人图像数据显示数字人图像。
10、在一些实施例中,所述服务器执行确定情感参数,被进一步配置为:
11、根据所述语音数据确定回复情感;
12、根据所述回复情感确定情感参数。
13、在一些实施例中,所述服务器执行确定情感参数,被进一步配置为:
14、确定先验情感知识;
15、将所述先验情感知识及所述语音特征输入情感预测器,得到情感表达特征;
16、基于所述情感表达特征确定情感参数。
17、在一些实施例中,所述服务器执行确定先验情感知识,被进一步配置为:
18、获取显示设备采集的用户人脸数据;
19、将所述用户人脸数据输入分散注意力网络模型中,得到先验情感知识,所述分散注意力网络模型包括特征聚类网络、多头注意力网络和注意力融合网络。
20、在一些实施例中,所述服务器执行确定先验情感知识,被进一步配置为:
21、提取所述播报语音的梅尔谱;
22、将所述梅尔谱经过卷积神经网络及特征聚合单元,得到语义特征;
23、将所述语义特征通过双向门控递归单元及全局-局部注意力模块,得到特性特征;
24、获取所述语音特征中的共性特征;
25、将所述共性特征和所述特性特征通过交互注意力模块融合,得到融合特征;
26、将所述共性特征、所述特性特征和所述融合特征输入分类器,得到先验情感知识。
27、在一些实施例中,所述服务器执行确定情感参数,被进一步配置为:
28、确定先验情感知识;
29、将所述先验情感知识及所述语音特征输入情感预测器,得到情感表达特征;
30、获取情感强度;
31、基于所述情感表达特征和所述情感强度确定情感强度表达特征;
32、基于所述情感强度表达特征确定情感参数。
33、在一些实施例中,所述服务器执行基于所述情感表达特征和所述情感强度确定情感强度表达特征,被进一步配置为:
34、计算所述情感表达特征与多个情感聚类中心的距离,所述情感聚类中心通过对不同情绪及样本的先验情感知识向量聚类得到;
35、确定所述距离中的最小距离以及所述最小距离对应的情感聚类中心;
36、根据所述情感表达特征、所述情感强度、所述最小距离以及所述最小距离对应的情感聚类中心,确定情感强度表达特征。
37、在一些实施例中,所述服务器执行基于所述用户图像数据、所述情感参数和所述口型参数生成数字人图像数据,被进一步配置为:
38、将所述情感参数及所述口型参数融合,得到融合参数;
39、基于所述用户图像数据及所述融合参数生成数字人图像数据。
40、第二方面,本申请一些实施例中提供一种显示设备,包括:
41、显示器,被配置为显示用户界面;
42、通信器,被配置为与服务器进行数据通信;
43、控制器,被配置为:
44、接收用户输入的语音数据;
45、将所述语音数据通过所述通信器发送至服务器;
46、接收所述服务器基于所述语音数据下发数字人图像数据及播报语音;
47、播放所述播报语音并基于所述数字人图像数据显示数字人图像。
48、第三方面,本申请一些实施例中提供一种数字人交互方法,包括:
49、接收显示设备发送用户输入的语音数据;
50、基于所述语音数据确定播报语音;
51、提取所述播报语音的语音特征;
52、基于所述语音特征确定口型参数;
53、确定情感参数以及获取用户图像数据;
54、基于所述用户图像数据、所述情感参数和所述口型参数生成数字人图像数据;
55、将所述播报语音和所述数字人图像数据发送至所述显示设备,以使所述显示设备播放所述播报语音并基于所述数字人图像数据显示数字人图像。
56、本申请的一些实施例提供一种服务器、显示设备及数字人交互方法。接收显示设备发送用户输入的语音数据;基于所述语音数据确定播报语音;提取所述播报语音的语音特征;基于所述语音特征确定口型参数;确定情感参数以及获取用户图像数据;基于所述用户图像数据、所述情感参数和所述口型参数生成数字人图像数据;将所述播报语音和所述数字人图像数据发送至所述显示设备,以使所述显示设备播放所述播报语音并基于所述数字人图像数据显示数字人图像。本申请实施例根据用户输入的语音数据确定表情参数及口型参数,将表情参数及口型参数结合生成具有较好面部表情表达的数字人图像,实现情感定制和控制。
技术特征:
1.一种服务器,其特征在于,被配置为:
2.根据权利要求1所述的服务器,其特征在于,所述服务器执行确定情感参数,被进一步配置为:
3.根据权利要求1所述的服务器,其特征在于,所述服务器执行确定情感参数,被进一步配置为:
4.根据权利要求3所述的服务器,其特征在于,所述服务器执行确定先验情感知识,被进一步配置为:
5.根据权利要求3所述的服务器,其特征在于,所述服务器执行确定先验情感知识,被进一步配置为:
6.根据权利要求1所述的服务器,其特征在于,所述服务器执行确定情感参数,被进一步配置为:
7.根据权利要求6所述的服务器,其特征在于,所述服务器执行基于所述情感表达特征和所述情感强度确定情感强度表达特征,被进一步配置为:
8.根据权利要求1所述的服务器,其特征在于,所述服务器执行基于所述用户图像数据、所述情感参数和所述口型参数生成数字人图像数据,被进一步配置为:
9.一种显示设备,其特征在于,包括:
10.一种数字人交互方法,其特征在于,包括:
技术总结
本申请一些实施例示出一种服务器、显示设备及数字人交互方法,所述方法包括:接收显示设备发送用户输入的语音数据;基于所述语音数据确定播报语音;提取所述播报语音的语音特征;基于所述语音特征确定口型参数;确定情感参数以及获取用户图像数据;基于所述用户图像数据、所述情感参数和所述口型参数生成数字人图像数据;将所述播报语音和所述数字人图像数据发送至所述显示设备,以使所述显示设备播放所述播报语音并基于所述数字人图像数据显示数字人图像。本申请实施例根据用户输入的语音数据确定表情参数及口型参数,将表情参数及口型参数结合生成具有较好面部表情表达的数字人图像,实现情感定制和控制。
技术研发人员:付爱国,杨善松
受保护的技术使用者:海信视像科技股份有限公司
技术研发日:
技术公布日:2024/4/7
- 还没有人留言评论。精彩留言会获得点赞!