一种基于音色分离的语音生成方法、装置、介质及设备与流程
本说明书涉及计算机,尤其涉及一种基于音色分离的语音生成方法、装置、介质及设备。
背景技术:
1、随着深度学习技术的发展,语音合成在诸如智能客服、智能驾驶、影视配音等领域得到了广泛的应用,通过语音合成技术可以实现将指定的文本转换为特定的语音,从而应用到相应的业务场景中。
2、然而,除了自然度以外,在一些业务场景中通常需要对某些对象的语音进行精准的模仿,但是现有方法的语音转换效果较差,难以准确的将文本转换为这些对象对应语音风格下的语音。
3、因此,如何将文本准确的转换为与目标对象语音风格相匹配的语音,是一个亟待解决的问题。
技术实现思路
1、本说明书提供一种基于音色分离的语音生成方法、装置、介质及设备,以部分的解决现有技术存在的上述问题。
2、本说明书采用下述技术方案:
3、本说明书提供了一种基于音色分离的语音生成方法,包括:
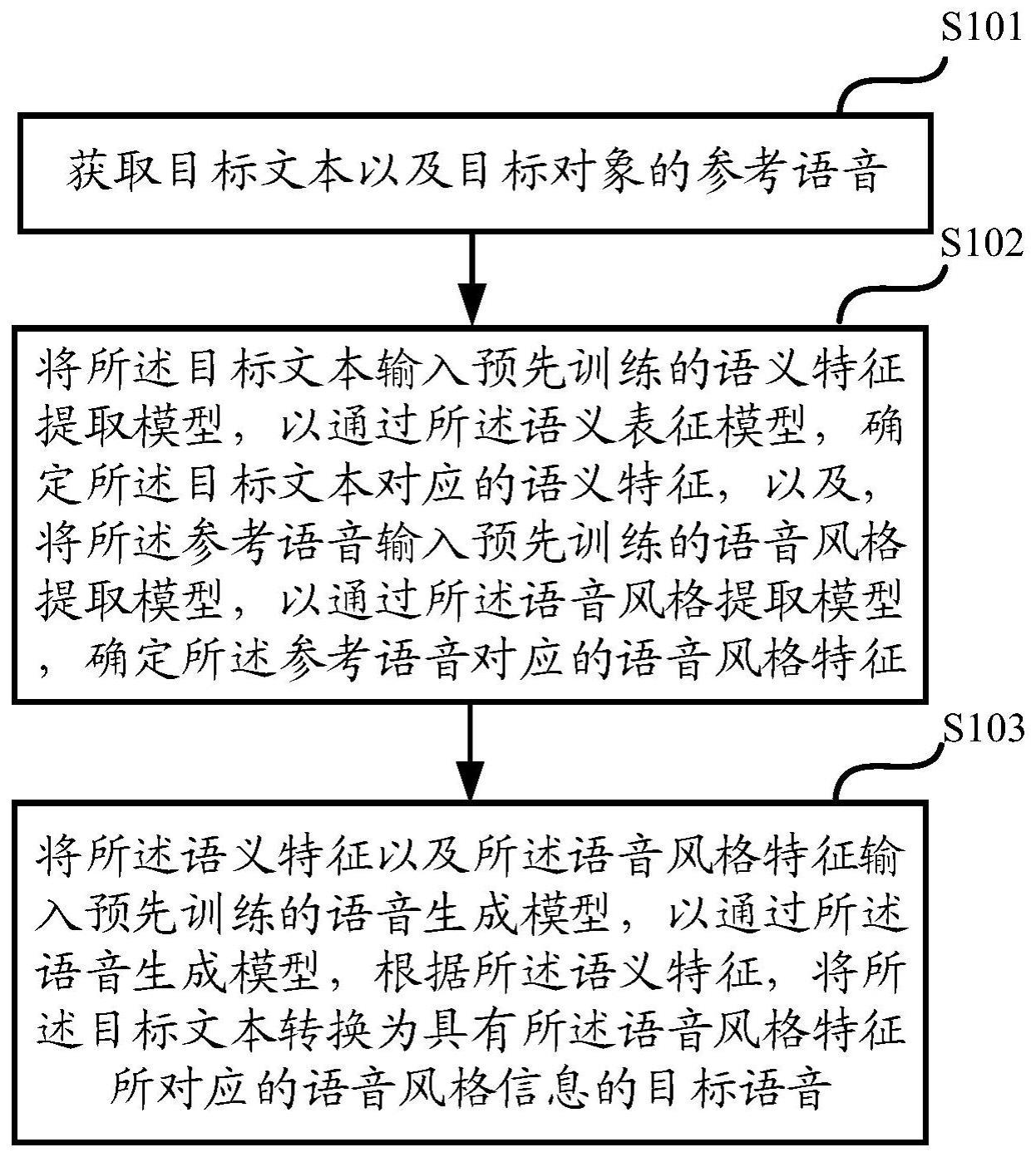
4、获取目标文本以及目标对象的参考语音;
5、将所述目标文本输入预先训练的语义特征提取模型,以通过所述语义表征模型,确定所述目标文本对应的语义特征,以及,将所述参考语音输入预先训练的语音风格提取模型,以通过所述语音风格提取模型,确定所述参考语音对应的语音风格特征;
6、将所述语义特征以及所述语音风格特征输入预先训练的语音生成模型,以通过所述语音生成模型,根据所述语义特征,将所述目标文本转换为具有所述语音风格特征所对应的语音风格信息的目标语音。
7、可选地,将所述参考语音输入预先训练的语音风格提取模型,以通过所述语音风格提取模型,确定所述参考语音对应的语音风格特征,具体包括:
8、通过所述语音风格提取模型,提取所述参考语音所对应的语音风格信息;
9、根据所述语音风格信息,确定所述语音风格特征。
10、可选地,所述语音风格信息包括:所述参考语音对应的音色信息、音调信息、语速信息中的至少一种。
11、可选地,所述语速信息包括:第一语速信息以及第二语速信息,所述第一语速信息用于表征所述参考语音中每两个音素之间的平均间隔时长,所述第二语速信息用于表征所述参考语音中每个音素对应的平均发音时长。
12、可选地,训练所述语义特征提取模型,具体包括:
13、获取第一样本数据,所述第一样本数据为文本数据;
14、将所述第一样本数据输入待训练的语义特征提取模型,以通过所述语义特征提取模型,确定所述第一样本数据对应的预测语义特征;
15、以最小化所述预测语义特征与所述第一样本数据对应的第一标签之间的偏差为优化目标,对所述语义特征提取模型进行训练。
16、可选地,训练所述语音生成模型,具体包括:
17、获取第二样本数据,所述第二样本数据为包含有语义特征和语音风格特征的二元组;
18、将所述第二样本数据输入待训练的语音生成模型,以通过所述语音生成模型,确定所述第二样本数据对应的预测目标语音;
19、以所述预测目标语音与所述第二样本数据对应的第二标签之间的偏差最小化为优化目标,对所述语音生成模型进行训练。
20、可选地,获取第二样本数据,具体包括:
21、获取样本语音,并确定所述样本语音对应的语音风格特征;
22、提取所述样本语音所对应的文本信息,并根据所述文本信息,确定所述样本语音对应的语义特征;
23、根据所述样本语音对应的语音风格特征以及所述样本语音对应的语义特征,确定所述第二样本数据,并将所述文本信息以及所述样本语音的频谱信息作为所述第二标签。
24、本说明书提供了一种基于音色分离的语音生成的装置,包括:
25、获取模块,获取目标文本以及目标对象的参考语音;
26、确定模块,将所述目标文本输入预先训练的语义特征提取模型,以通过所述语义表征模型,确定所述目标文本对应的语义特征,以及,将所述参考语音输入预先训练的语音风格提取模型,以通过所述语音风格提取模型,确定所述参考语音对应的语音风格特征;
27、生成模块,将所述语义特征以及所述语音风格特征输入预先训练的语音生成模型,以通过所述语音生成模型,根据所述语义特征,将所述目标文本转换为具有所述语音风格特征所对应的语音风格信息的目标语音。
28、本说明书提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述基于音色分离的语音生成方法。
29、本说明书提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述基于音色分离的语音生成方法。
30、本说明书采用的上述至少一个技术方案能够达到以下有益效果:
31、在本说明书提供的基于音色分离的语音生成方法中,获取目标文本以及目标对象的参考语音;将目标文本输入预先训练的语义特征提取模型,以通过语义表征模型,确定目标文本对应的语义特征,以及,将参考语音输入预先训练的语音风格提取模型,以通过语音风格提取模型,确定参考语音对应的语音风格特征;将语义特征以及语音风格特征输入预先训练的语音生成模型,以通过语音生成模型,根据语义特征,将目标文本转换为具有语音风格特征所对应的语音风格信息的目标语音。
32、从上述方法可以看出,本方案在生成语音的过程中,可以在通过语义特征提取模型提取目标文本的语义特征的同时,通过语音风格提取模型提取参考语言的语音风格特征,这样一来,语音转换模型就可以基于提取到的语义特征和语音风格特征对目标对象的语音进行精确的模拟,提高语音转换效果,并且,本方案可以将声学特征的提取过程分解为多个具有较小子参数空间的模型来完成,通过在多个较小的子参数空间上进行语音转换可以有效的避免模型在训练过程中产生的过拟合问题。
技术特征:
1.一种基于音色分离的语音生成的方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,将所述参考语音输入预先训练的语音风格提取模型,以通过所述语音风格提取模型,确定所述参考语音对应的语音风格特征,具体包括:
3.如权利要求1或2任一项所述的方法,其特征在于,所述语音风格信息包括:所述参考语音对应的音色信息、音调信息、语速信息中的至少一种。
4.如权利要求3所述的方法,其特征在于,所述语速信息包括:第一语速信息以及第二语速信息,所述第一语速信息用于表征所述参考语音中每两个音素之间的平均间隔时长,所述第二语速信息用于表征所述参考语音中每个音素对应的平均发音时长。
5.如权利要求1所述的方法,其特征在于,训练所述语义特征提取模型,具体包括:
6.如权利要求1所述的方法,其特征在于,训练所述语音生成模型,具体包括:
7.如权利要求6所述的方法,其特征在于,获取第二样本数据,具体包括:
8.一种基于音色分离的语音生成的装置,其特征在于,包括:
9.一种计算机可读存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述权利要求1~7任一项所述的方法。
10.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现上述权利要求1~7任一项所述的方法。
技术总结
本说明书公开了一种基于音色分离的语音生成方法、装置、介质及设备。所述方法包括:获取目标文本以及目标对象的参考语音;将目标文本输入预先训练的语义特征提取模型,以通过语义表征模型,确定目标文本对应的语义特征,以及,将参考语音输入预先训练的语音风格提取模型,以通过语音风格提取模型,确定参考语音对应的语音风格特征;将语义特征以及语音风格特征输入预先训练的语音生成模型,以通过语音生成模型,根据语义特征,将目标文本转换为具有语音风格特征所对应的语音风格信息的目标语音。
技术研发人员:俞再亮,李海燕,易江燕,陶建华,汪涛
受保护的技术使用者:之江实验室
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!