一种语音转换方法、系统及存储介质与流程
本申请涉及语音转换,尤其涉及一种语音转换方法、系统及存储介质。
背景技术:
1、语音转换技术是指在不改变语音内容的情况下,将源人物语音转换成目标人物语音的技术,这种技术涉及到对语音信号的参数进行分析和修改,以实现语音的转换。语音转换技术广泛应用于虚拟形象、数字人或真人语音等场景下,用户可以选择对应的目标人物语音,并在上述场景中完成对源说话人的语音转换,提高音频的互动性。
2、待转换音频是包括源人物语音的音频,除了人声外,待转换音频还可能包括背景噪音。因此,在语音转换的过程中,需要结合降噪增益技术对待转换音频进行处理,从而得到纯净的源人物语音,进而对源人物语音进行语音转换。
3、但是,当待转换音频中包括多个人物语音的时候,其他人物语音与源人物语音相互交错,在语音转换的过程中,会将其他人物语音和源人物语音同时转换为目标人物语音,从而导致转换后音频的场景还原度下降。
技术实现思路
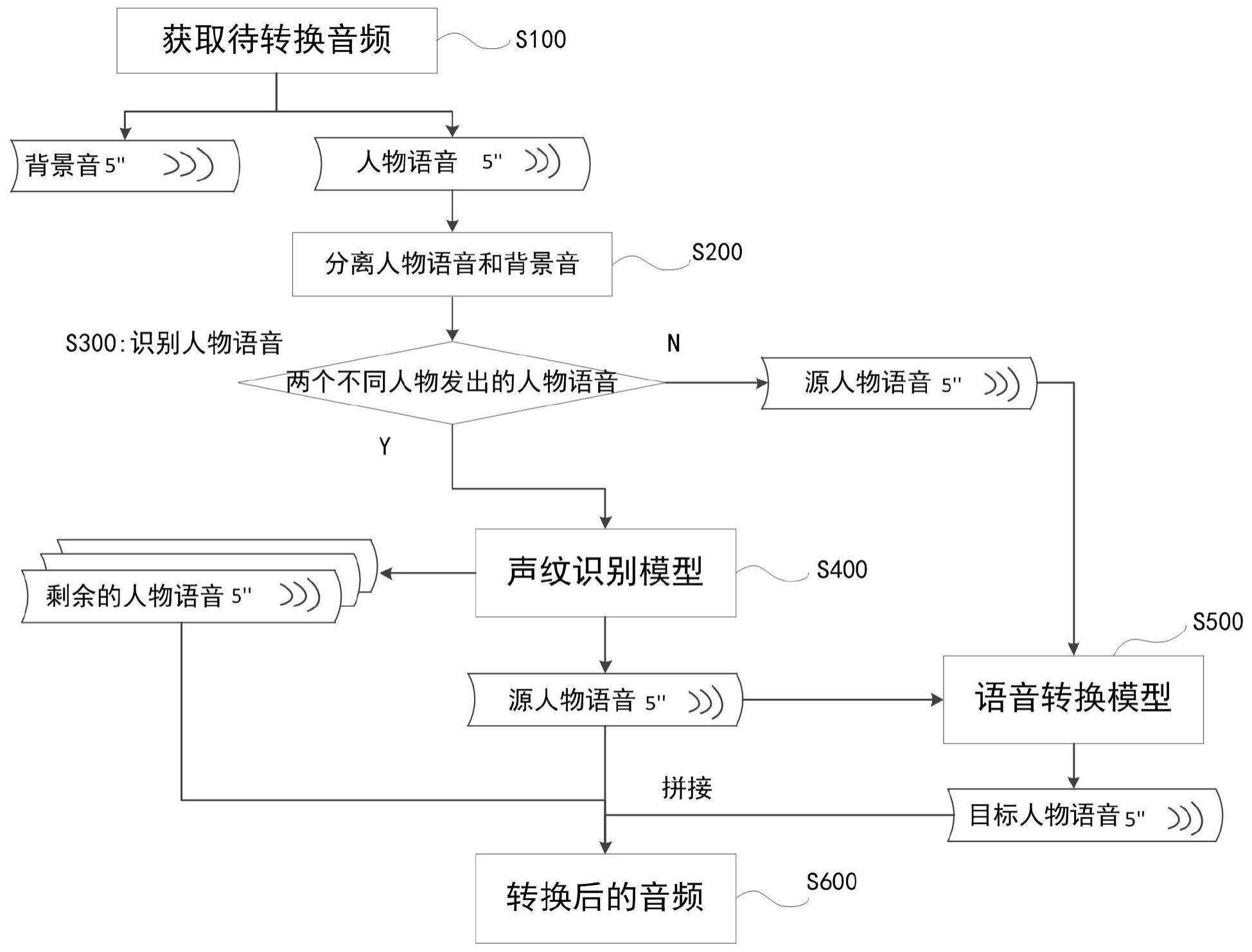
1、为了提高语音转换后的音频的场景还原度,第一方面,本申请的部分实施例提供一种语音转换方法,包括:
2、获取待转换音频;
3、识别所述待转换音频中的人物语音;
4、使用端点检测技术从所述待转换音频中分离人物语音和背景音;
5、识别所述待转换音频中的人物语音;
6、如果所述待转换音频中识别出至少两个不同人物发出的人物语音,则通过声纹识别模型从所述人物语音识别出源人物语音,所述声纹识别模型包括参照声纹,所述源人物语音是语音声纹与参照声纹的声纹相似度大于或等于相似度阈值的人物语音;
7、通过语音转换模型将所述源人物语音转换为目标人物语音;
8、将所述背景音、剩余的人物语音和所述目标人物语音进行拼接,得到转换后的音频。
9、在一些实施例中,所述人物语音包括至少一个人物语音片段,所述使用端点检测技术从所述待转换音频中分离人物语音和背景音步骤,包括:
10、通过端点检测技术检测所述待转换音频中各个音频片段的音频活性值;
11、根据所述音频活性值从所述待转换音频中分离出人物语音片段,所述人物语音片段是音频活性值大于活性值阈值的语音片段;
12、如果所述人物语音片段的数量为一个,则根据所述人物语音片段输出所述人物语音;
13、如果所述人物语音片段的数量为多个,则拼接所述人物语音片段,得到所述人物语音;
14、根据待转换音频中剩余的音频生成背景音。
15、在一些实施例中,所述通过声纹识别模型从所述人物语音识别出源人物语音的步骤前,还包括:
16、获取源人物说出的第一训练音频;
17、通过端点检测技术从所述第一训练音频中分离出源人物语音片段;
18、通过所述源人物语音片段训练所述声纹识别模型。
19、在一些实施例中,所述通过语音转换模型将所述源人物语音转换为目标人物语音的步骤前,还包括:
20、获取目标人物说出的第二训练音频;
21、通过端点检测技术从所述第二训练音频中分离出目标人物语音片段;
22、通过所述目标人物语音片段训练所述语音转换模型。
23、在一些实施例中,所述通过声纹识别模型从所述人物语音识别出源人物语音的步骤,包括:
24、获取所述人物语音的语音声纹;
25、将所述语音声纹输入至所述声纹识别模型,以通过所述声纹识别模型计算所述语音声纹和所述声纹识别模型的参照声纹的声纹相似度;
26、如果所述声纹相似度大于或等于相似度阈值,则将所述人物语音标记为源人物语音;
27、如果所述声纹相似度小于相似度阈值,则通过所述声纹识别模型输出静默音频,所述静默音频为不执行语音转换的音频。
28、在一些实施例中,所述通过声纹识别模型从所述人物语音识别出源人物语音的步骤前,还包括:
29、根据正序的时序顺序检测人物语音之间的重叠语音;
30、根据语义检测技术获取所述重叠语音的语义信息和来源对象信息;
31、根据所述语义信息和来源对象信息对所述重叠语音进行裁剪操作,得到人物语音片段。
32、在一些实施例中,所述用端点检测技术从所述待转换音频中分离人物语音和背景音的步骤后,所述方法还包括:
33、将所述人物语音输入深度聚类识别模型;
34、通过所述深度聚类识别模型获取所述人物语音片段的音频特征;
35、根据音频特征之间的特征相似度对所述人物语音片段执行分类,得到至少两个音频集合,所述音频集合是来源为同一人物的人物语音片段的集合。
36、在一些实施例中,所述方法还包括:
37、获取用户输入的选择指令,所述选择指令用于在人物语音中选择源人物语音;
38、根据所述选择指令,对源人物语音的音频集合执行标记;
39、所述通过语音转换模型对所述源人物语音执行语音转换的步骤,还包括:
40、通过语音转换模型对被标记的音频集合执行语音转换。
41、第二方面,本申请的部分实施例提供一种语音转换系统,包括存储器和处理器,其中,所述存储器用于存储声纹识别模型和语音转换模型,所述处理器被配置为:
42、获取待转换音频;
43、识别所述待转换音频中的人物语音;
44、使用端点检测技术从所述待转换音频中分离人物语音和背景音;
45、识别所述待转换音频中的人物语音;
46、如果所述待转换音频中识别出至少两个不同人物发出的人物语音,则通过声纹识别模型从所述人物语音识别出源人物语音,所述声纹识别模型包括参照声纹,所述源人物语音是语音声纹与参照声纹的声纹相似度大于或等于相似度阈值的人物语音;
47、通过语音转换模型将所述源人物语音转换为目标人物语音;
48、将所述背景音、剩余的人物语音和所述目标人物语音进行拼接,得到转换后的音频。
49、第三方面,本申请的部分实施例提供一种计算机可读存储介质,所述计算机可读存储介质中包括计算机指令,所述计算机指令用于指示计算机执行第一方面所述的语音转换方法。
50、由以上技术方案可知,本申请提供一种语音转换方法、系统及存储介质,通过端点检测技术从待转换音频中分离人物语音和背景音,并识别待转换音频中的人物语音,如果待转换语音中识别出至少两个不同人物发出的人物语音,则通过声纹识别模型在人物语音中识别出源人物语音,再通过语音转换模型将源人物语音转换为目标人物语音,最后将背景音、剩余的人物语音和目标人物语音拼接,得到转换后的音频。本申请通过在多个人物语音中识别出源人物语音,避免多个人物语音混淆源人物语音的语音转换,从而将背景音、剩余的人物语音和转换后得到的目标人物语音拼接,使得语音转换更加真实自然,提高语音转换后音频的场景还原度。
技术特征:
1.一种语音转换方法,其特征在于,包括:
2.根据权利要求1所述的语音转换方法,其特征在于,所述人物语音包括至少一个人物语音片段,所述使用端点检测技术从所述待转换音频中分离人物语音和背景音步骤,包括:
3.根据权利要求1所述的语音转换方法,其特征在于,所述通过声纹识别模型从所述人物语音识别出源人物语音的步骤前,还包括:
4.根据权利要求1所述的语音转换方法,其特征在于,所述通过语音转换模型将所述源人物语音转换为目标人物语音的步骤前,还包括:
5.根据权利要求1所述的语音转换方法,其特征在于,所述通过声纹识别模型从所述人物语音识别出源人物语音的步骤,包括:
6.根据权利要求5所述的语音转换方法,其特征在于,所述通过声纹识别模型从所述人物语音识别出源人物语音的步骤前,还包括:
7.根据权利要求2所述的语音转换方法,其特征在于,所述用端点检测技术从所述待转换音频中分离人物语音和背景音的步骤后,所述方法还包括:
8.根据权利要求7所述的语音转换方法,其特征在于,所述方法还包括:
9.一种语音转换系统,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中包括计算机指令,所述计算机指令用于指示计算机执行权利要求1-8任意一项所述的语音转换方法。
技术总结
本申请提供一种语音转换方法、系统及存储介质,通过识别待转换音频中的人物语音,通过端点检测技术从待转换音频中分离人物语音和背景音,并识别待转换音频中的人物语音,如果待转换语音中识别出至少两个不同人物发出的人物语音,则通过声纹识别模型在人物语音中识别出源人物语音,再通过语音转换模型将源人物语音转换为目标人物语音,最后将背景音、剩余的人物语音和目标人物语音拼接,得到转换后的音频。本申请通过在多个人物语音中识别出源人物语音,避免多个人物语音混淆源人物语音的语音转换,从而将背景音、剩余的人物语音和转换后得到的目标人物语音拼接,使得语音转换更加真实自然,提高语音转换后音频的场景还原度。
技术研发人员:张朕,侯杰
受保护的技术使用者:苏州君林智能科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!