一种语音合成方法、装置、设备及存储介质与流程
本公开涉及计算机,尤其涉及一种语音合成方法、装置、设备及存储介质。
背景技术:
1、随着语音合成技术在智能助理和虚拟人物等方面的广泛应用,对口语化语音合成的需求也日益增加,相比偏正式的流利语言,口语化语音合成技术能够还原人与人日常交流过程中的表达方式,合成效果更加真实自然。
2、现有的口语化语音合成技术的重点一般在于拖音、重音以及情感特征的预测和特征迁移,但日常的口语化发音现象包括语气词、重音、拖音、停顿、吸气、哭声、笑声和口误等多种情况,现有的口语化语音合成技术无法较全面的覆盖所有口语化发音现象,也无法对缺少口语化语料的发音人进行知识迁移,从而导致最终的合成效果不够真实自然。
技术实现思路
1、本公开提供了一种语音合成方法、装置、设备及存储介质,以至少解决现有技术中存在的以上技术问题。
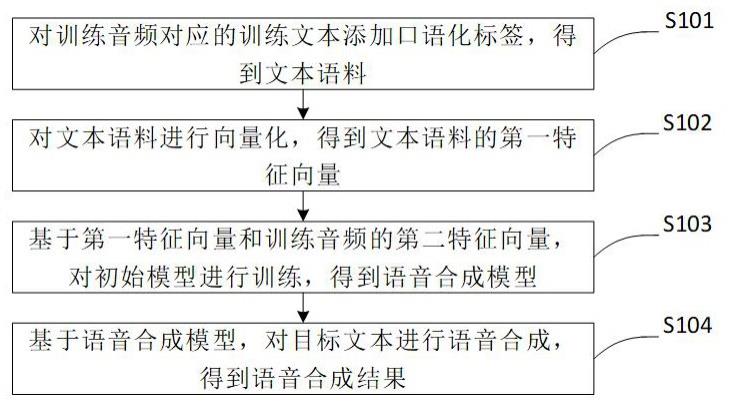
2、根据本公开的第一方面,提供了一种语音合成方法,所述方法包括:对训练音频对应的训练文本添加口语化标签,得到文本语料,所述口语化标签用于表征所述训练音频的发音现象;对所述文本语料进行向量化,得到所述文本语料的第一特征向量;基于所述第一特征向量和所述训练音频的第二特征向量,对初始模型进行训练,得到语音合成模型,所述第二特征向量通过对所述训练音频进行声学特征提取得到;基于所述语音合成模型,对目标文本进行语音合成,得到语音合成结果,所述目标文本包括口语化标签。
3、在一可实施方式中,所述对所述文本语料进行向量化,包括:对所述训练文本对应的音素序列进行向量化,得到音素向量;基于所述口语化标签的标签类别,对所述口语化标签进行向量化,得到标签向量;将所述音素向量与其对应的标签向量进行拼接,得到所述口语化语料的第一特征向量。
4、在一可实施方式中,所述对所述口语化标签进行向量化,包括:所述口语化标签的标签类别为第一类别,对所述口语化标签对应的音素序列进行向量化,得到所述口语化标签对应的第一标签向量;所述口语化标签的标签类别为第二类别,构建所述口语化标签对应的第二标签向量,所述第二标签向量用于表征所述口语化标签存在;所述口语化标签的标签类别为第三类别,对所述口语化标签对应的符号序列进行向量化,得到所述口语化标签对应的第三标签向量;其中,所述第一类别表征所述口语化标签为语气词标签,所述第二类别表征所述口语化标签为语音属性标签,所述第三类别表征所述口语化标签为功能性发声标签。
5、在一可实施方式中,所述对初始模型进行训练,包括:基于所述第一特征向量和第二特征向量,对所述初始模型的第一初始分支进行训练,得到第一模型;基于所述第一模型的输出结果,对所述初始模型的第二初始分支进行训练,得到第二模型;基于所述第一模型和第二模型,生成所述语音合成模型。
6、在一可实施方式中,所述对所述初始模型的第一初始分支进行训练,包括:将所述训练音频对应的说话人信息和训练文本,以及所述第一特征向量输入所述第一初始分支的文本编码器,并将所述第二特征向量输入所述第一初始分支的残差编码器,以对所述第一初始分支进行训练,得到所述第一模型;其中,所述第一初始分支包括文本编码器、残差编码器和解码器,所述解码器的输出为所述第一模型的输出结果。
7、在一可实施方式中,在所述对目标文本进行语音合成之前,还包括:基于标签预测模型,对初始文本添加口语化标签,得到所述目标文本;其中,所述初始文本为需要进行语音合成的文本,所述标签预测模型基于深度神经网络模型训练得到,所述标签预测模型用于根据输入文本,输出与输入文本对应的口语化语料。
8、在一可实施方式中,所述对目标文本进行语音合成,包括:将所述目标文本和所述目标文本对应的说话人信息输入至所述语音合成模型的文本编码器,基于所述语音合成模型输出所述目标文本对应的语音合成结果。
9、根据本公开的第二方面,提供了一种语音合成装置,所述装置包括:添加模块,用于对训练音频对应的训练文本添加口语化标签,得到文本语料,所述口语化标签用于表征所述训练音频的发音现象;向量化模块,用于对所述文本语料进行向量化,得到所述文本语料的第一特征向量;训练模块,用于基于所述第一特征向量和所述训练音频的第二特征向量,对初始模型进行训练,得到语音合成模型,所述第二特征向量通过对所述训练音频进行声学特征提取得到;语音合成模块,用于基于所述语音合成模型,对目标文本进行语音合成,得到语音合成结果,所述目标文本包括口语化标签。
10、根据本公开的第三方面,提供了一种电子设备,包括:
11、至少一个处理器;以及
12、与所述至少一个处理器通信连接的存储器;其中,
13、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本公开所述的方法。
14、根据本公开的第四方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,所述计算机指令用于使计算机执行本公开所述的方法。
15、本公开的一种语音合成方法、装置、设备及存储介质,对训练音频添加口语化标签,口语化标签能够较为全面的覆盖所有口语化发音现象,从而提高语音合成效果的准确性,另外,基于多个说话人对应的训练音频对语音合成模型进行训练,能够对缺少口语化语料的说话人进行知识迁移,进一步保证语音合成效果的自然性。
16、应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种语音合成方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述文本语料进行向量化,包括:
3.根据权利要求2所述的方法,其特征在于,所述对所述口语化标签进行向量化,包括:
4.根据权利要求1所述的方法,其特征在于,所述对初始模型进行训练,包括:
5.根据权利要求4所述的方法,其特征在于,所述对所述初始模型的第一初始分支进行训练,包括:
6.根据权利要求5所述的方法,其特征在于,在所述对目标文本进行语音合成之前,还包括:
7.根据权利要求6所述的方法,其特征在于,所述对目标文本进行语音合成,包括:
8.一种语音合成装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括:
10.一种存储有计算机指令的非瞬时计算机可读存储介质,其特征在于,所述计算机指令用于使计算机执行权利要求1-7中任一项所述的方法。
技术总结
本公开提供了一种语音合成方法、装置、设备及存储介质,涉及计算机技术领域。方法主要包括:对训练音频对应的训练文本添加口语化标签,得到文本语料,口语化标签用于表征训练音频的发音现象;对文本语料进行向量化,得到文本语料的第一特征向量;基于第一特征向量和训练音频的第二特征向量,对初始模型进行训练,得到语音合成模型,第二特征向量通过对训练音频进行声学特征提取得到;基于语音合成模型,对目标文本进行语音合成,得到语音合成结果,目标文本包括口语化标签。
技术研发人员:陆健,徐欣康,胡新辉
受保护的技术使用者:浙江同花顺智能科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!