一种基于少量强标注数据的声音事件检测方法和装置与流程
本发明属于音频信号处理,具体涉及一种基于少量强标注数据的声音事件检测方法和装置。
背景技术:
1、声音事件检测具体定义为:从音频时序数据中检测出感兴趣的声音事件,将其划分到正确的设定类别中,同时标记出声音事件发生在音频时序数据中的开始和结束时刻。声音事件检测技术可以应用于监听和异常检测相关的很多场景中,例如安防监控中可以用于监测一些异常声音如爆炸等。在工业制造领域也可以用于机械异常工作声音的监测。也可以对智能家居生活中的声音进行监测和反馈。因此,声音事件检测技术极具实用价值。
2、现实生活中的声音事件常常会伴随发生,声音事件发生的时长也是变化不断的,这就导致数据的收集和标注都十分困难。早期的声音事件检测采用的是隐马尔可夫模型、随机森林回归、支持向量机等方法。随着深度学习的不断发展,越来越多的基于深度学习的方法在表现上确实优于传统的方法,但是深度学习的方法需要大量的数据支撑,但由于声音的复杂性导致数据收集困难,对声音事件类别和发生的起止时刻正确标注也需要耗费巨大的人力物力。尤其是对事件发生的起止时刻标注,这需要对每一个时间的时刻进行判断标记,才能较为精确地标记,十分消耗人力。在声音事件检测任务中,这一类同时包含事件类别和事件发生起止时刻的数据我们称之为强标注数据,另一类只有事件类别而没有事件发生起止时刻的数据称为弱标注数据,弱标注数据的获取比强标注数据容易得多。而且在某些特殊领域里面,数据量可能较为少量,很难达到深度学习需要的数据量。
3、正如前文所述,针对声音事件检测过程中,尤其针对一些数据难以获取的特殊领域,强标注数据难以获取且数据量少,不能达到深度学习需求的数据量的情况,需提出一种有效的声音事件检测模型,实现利用少量强注数据实现声音事件的有效检测。
技术实现思路
1、本发明的目的是解决强标注数据收集和标记困难,尤其针对一些特殊应用领域,难以利用少量数据实现声音事件检测模型训练的问题。本发明提出一种基于少量强标注数据的声音事件检测方法和装置。
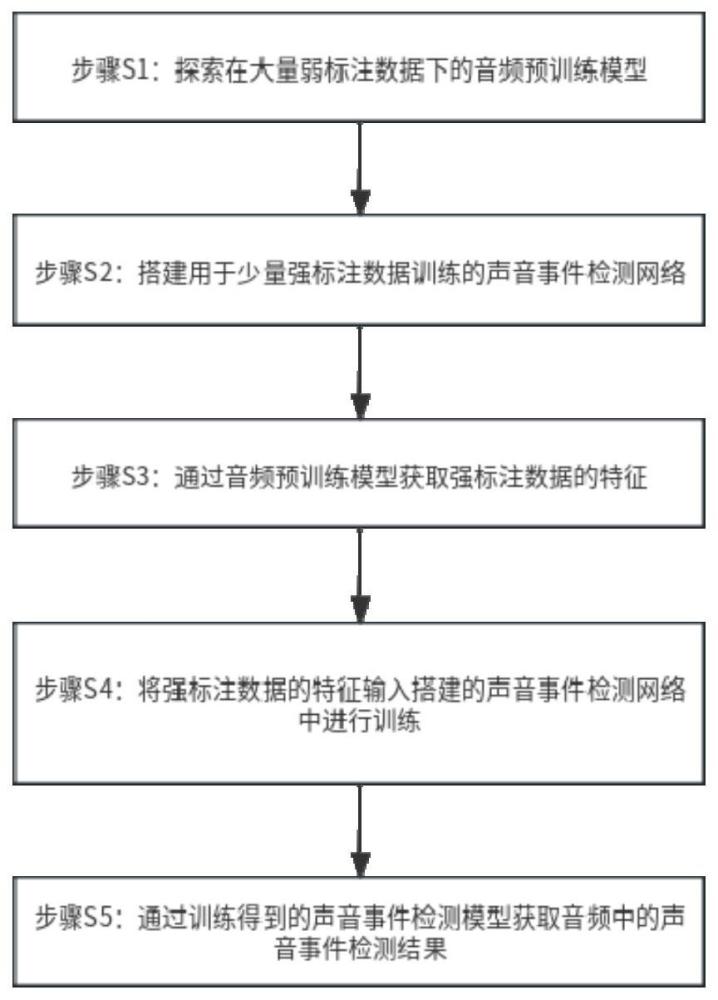
2、本发明第一方面提供一种基于少量强标注数据的声音事件检测方法,包括:
3、s1、构建在大量弱标注数据下的音频预训练模型;
4、s2、采用少量强标注数据训练得到初步的声音事件检测网络;
5、s3、通过音频预训练模型获取强标注数据的特征;
6、s4、将强标注数据的特征输入初步的声音事件检测网络中进行训练,得到训练后的声音事件检测模型;
7、s5、将待预测的音频输入到训练后的声音事件检测模型中,检测待预测的音频中的声音事件。
8、可选的,构建在大量弱标注数据下的音频预训练模型,包括:
9、s11、获取大量弱标注数据集,大量弱标注数据集包括:原始音频文件和标签文件;
10、s12、提取原始音频文件的音频特征;
11、s13、基于音频特征和标签文件,对预设的第一神经网络进行训练,得到用于音频分类的音频预训练模型;预设的第一神经网络包含:卷积神经网络层、最大池化层、平均池化层、线性层、注意力机制层、sigmoid输出层。
12、可选的,音频特征包括:对数梅尔频谱特征和一维时序卷积特征。
13、可选的,采用少量强标注数据训练得到初步的声音事件检测网络,包括:
14、搭建预设的第二神经网络;
15、采用强标注数据对预设的第二神经网络进行训练,得到初步的声音事件检测网络;
16、预设的第二神经网络包含:卷积层、池化层、注意力机制层、标准化层、上采样层、sigmoid输出层。
17、可选的,通过音频预训练模型获取强标注数据的特征,包括:
18、通过将少量强标注数据输入到音频预训练模型中,将音频预训练模型的线性层的输出结果作为强标注数据的特征。
19、可选的,强标注数据包括:至少一个音频信息和各音频信息包含的事件信息;将强标注数据的特征输入初步的声音事件检测网络中进行训练,得到训练后的声音事件检测模型,包含以下步骤:
20、对于事件信息中的感兴趣事件,根据感兴趣事件的事件发生的起止时刻,获取其在强标注数据的各音频信息中的标签标记,作为转化后的特征;
21、将强标注数据的特征和转化后的特征输入初步的声音事件检测网络中进行训练,得到训练后的声音事件检测模型。
22、本发明第二方面提供一种基于少量强标注数据的声音事件检测装置,包括:
23、音频预训练模型获取模块,用于构建在大量弱标注数据下的音频预训练模型;
24、初步的声音事件检测网络获取模块,用于采用少量强标注数据训练得到初步的声音事件检测网络;
25、强标注数据的特征获取模块,用于通过音频预训练模型获取强标注数据的特征;
26、训练模块,用于将强标注数据的特征输入初步的声音事件检测网络中进行训练,得到训练后的声音事件检测模型;
27、检测模块,用于将待预测的音频输入到训练后的声音事件检测模型中,检测待预测的音频中的声音事件。
28、可选的,音频预训练模型获取模块,包括:
29、弱标注数据集获取单元,用于获取大量弱标注数据集,大量弱标注数据集包括:原始音频文件和标签文件;
30、提取单元,用于提取原始音频文件的音频特征;
31、训练单元,用于基于音频特征和标签文件,对预设的第一神经网络进行训练,得到用于音频分类的音频预训练模型;预设的第一神经网络包含:卷积神经网络层、最大池化层、平均池化层、线性层、注意力机制层、sigmoid输出层。
32、本发明提供一种基于少量强标注数据的声音事件检测方法和装置,该方法包括:s1、构建在大量弱标注数据下的音频预训练模型;s2、采用少量强标注数据训练得到初步的声音事件检测网络;s3、通过音频预训练模型获取强标注数据的特征;s4、将强标注数据的特征输入初步的声音事件检测网络中进行训练,得到训练后的声音事件检测模型;s5、将待预测的音频输入到训练后的声音事件检测模型中,检测待预测的音频中的声音事件。解决强标注数据收集和标记困难,尤其针对一些特殊应用领域,难以利用少量数据实现声音事件检测模型训练的问题。
技术特征:
1.一种基于少量强标注数据的声音事件检测方法,其特征在于,包括:
2.根据权利要求1所述的声音事件检测方法,其特征在于,构建在大量弱标注数据下的音频预训练模型,包括:
3.根据权利要求2所述的声音事件检测方法,其特征在于,音频特征包括:对数梅尔频谱特征和一维时序卷积特征。
4.根据权利要求1所述的声音事件检测方法,其特征在于,采用少量强标注数据训练得到初步的声音事件检测网络,包括:
5.根据权利要求2所述的声音事件检测方法,其特征在于,通过音频预训练模型获取强标注数据的特征,包括:
6.根据权利要求1所述的声音事件检测方法,其特征在于,强标注数据包括:至少一个音频信息和各音频信息包含的事件信息;将强标注数据的特征输入初步的声音事件检测网络中进行训练,得到训练后的声音事件检测模型,包含以下步骤:
7.一种基于少量强标注数据的声音事件检测装置,其特征在于,包括:
8.根据权利要求7所述的声音事件检测装置,其特征在于,音频预训练模型获取模块,包括:
技术总结
本发明提供一种基于少量强标注数据的声音事件检测方法和装置,该方法包括:S1、构建在大量弱标注数据下的音频预训练模型;S2、采用少量强标注数据训练得到初步的声音事件检测网络;S3、通过音频预训练模型获取强标注数据的特征;S4、将强标注数据的特征输入初步的声音事件检测网络中进行训练,得到训练后的声音事件检测模型;S5、将待预测的音频输入到训练后的声音事件检测模型中,检测待预测的音频中的声音事件。解决强标注数据收集和标记困难,尤其针对一些特殊应用领域,难以利用少量数据实现声音事件检测模型训练的问题。
技术研发人员:袁涛,张晗亮,于泽,李斌,朱旭彤,黎涛
受保护的技术使用者:中国航空工业集团公司成都飞机设计研究所
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!