语音交互方法、装置、车辆及存储介质与流程
本申请涉及语音交互,具体涉及一种语音交互方法、装置、车辆及存储介质。
背景技术:
1、随着人工智能的发展,语音交互系统已经广泛应用于各种设备中,包括汽车。然而,现有的车载语音交互系统在响应性能和理解能力上的平衡上存在挑战。例如,传统的自然语言处理方法通常需要针对特定任务或领域进行训练和调优,对于新的任务或领域的处理效果较差。即,如果面临新的任务或领域,可能需要重新进行大量的工作。在处理复杂、大规模、多变的语言任务时,面临很大的挑战,语音交互质量较差。
技术实现思路
1、本申请的目的之一在于提供一种语音交互方法,其可以基于不同的语音识别信息选取不同的处理模型,可以很好的应对复杂、大规模以多变的语言任务,且可以很好的保证语音交互质量;本申请的目的之二在于提供一种语音交互装置;本申请的目的之三在于提供一种车辆;本申请的目标之四在于提供一种存储介质。
2、为了实现上述目的,第一方面,本申请提供一种语音交互方法,所述语音交互方法包括:
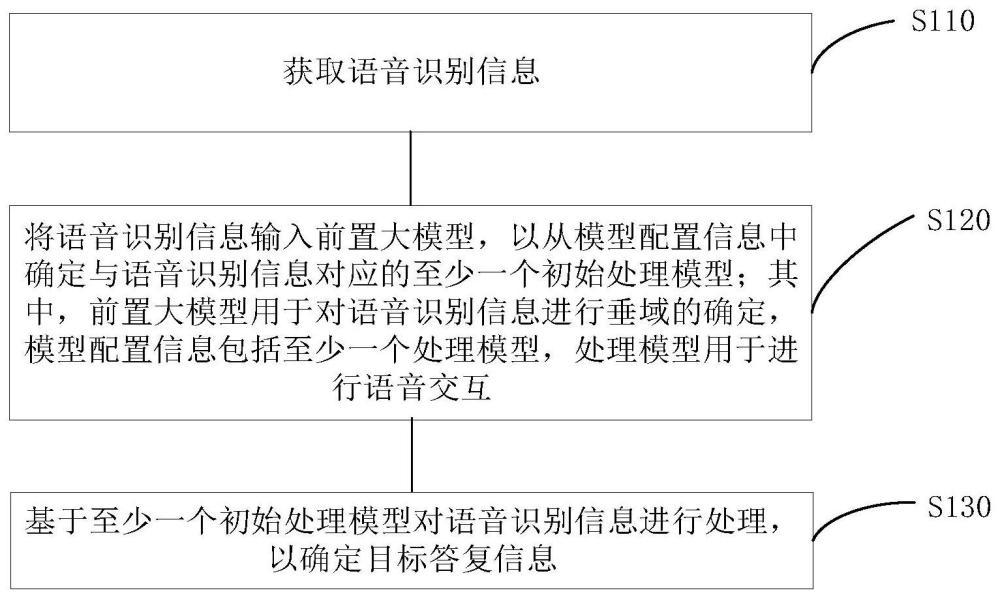
3、获取语音识别信息;
4、将所述语音识别信息输入前置大模型,以从模型配置信息中确定与所述语音识别信息对应的至少一个初始处理模型;其中,所述前置大模型用于对所述语音识别信息进行垂域的确定,所述模型配置信息包括至少一个处理模型,所述处理模型用于进行语音交互;
5、基于至少一个所述初始处理模型对所述语音识别信息进行处理,以确定目标答复信息。
6、进一步地,所述从模型配置信息中确定与所述语音识别信息对应的至少一个初始处理模型,包括:
7、将所述语音识别信息输入前置大模型,以确定所述初始处理模型;其中,所述前置大模型用于对所述语音识别信息进行垂域的确定;
8、其中,若所述前置大模型输出至少一个初始垂域,则将所述模型配置信息中与至少一个所述初始垂域对应的处理模型,确定为所述初始处理模型;和/或,
9、若所述前置大模型未输出初始垂域,则将模型配置信息中的全部处理模型,确定为所述初始处理模型。
10、进一步地,所述将所述语音识别信息输入前置大模型之后,所述语音交互方法包括:
11、若所述前置大模型输出所述语音识别信息的答复信息,则将所述答复信息确定为所述目标答复信息。
12、进一步地,所述前置大模型由以下方式确定;
13、获取具有自然语言处理能力的预训练大模型;
14、获取训练样本集;其中,所述训练样本集包括多个训练样本对,所述训练样本对包括输出样本和输入样本,所述输出样本包括垂域样本,所述输入样本包括与所述垂域样本对应的语音识别信息样本;
15、基于所述训练样本集对所述预训练大模型进行训练,以得到所述前置大模型。
16、进一步地,所述基于至少一个所述初始处理模型对所述语音识别信息进行处理,以确定目标答复信息,包括:
17、将所述语音识别信息输入至少一个所述初始处理模型中,以确定至少一个初始答复信息;其中,至少一个所述初始答复信息与至少一个所述初始处理模型一一对应;
18、从至少一个所述初始垂域中确定目标垂域;
19、从所述目标垂域对应的所述初始处理模型中确定目标处理模型;
20、将所述目标处理模型对应的所述初始答复信息,确定为所述目标答复信息。
21、进一步地,所述基于至少一个所述初始处理模型对所述语音识别信息进行处理,以确定目标答复信息,包括:
22、从至少一个所述初始垂域中确定目标垂域;
23、从所述目标垂域对应的所述初始处理模型中确定目标处理模型;
24、将所述语音识别信息输入所述目标处理模型,以确定所述目标答复信息。
25、进一步地,所述从至少一个所述初始垂域中确定目标垂域,包括:
26、当所述初始垂域的数量为一个时,将所述初始垂域确定为所述目标垂域;和/或,
27、当所述初始垂域的数量为至少两个时,基于优先级配置信息,从至少两个所述初始垂域中确定所述目标垂域;其中,所述优先级配置信息包括多个垂域的优先级信息。
28、进一步地,所述从所述目标垂域对应的所述初始处理模型中确定目标处理模型,包括:
29、当所述目标垂域对应一个所述初始处理模型时,将所述目标垂域对应的所述初始处理模型确定为所述目标处理模型;和/或,
30、当所述目标垂域对应至少两个所述初始处理模型时,基于权重配置信息,从所述目标垂域对应的至少两个所述初始处理模型中确定所述目标处理模型;其中,所述权重配置信息包括多个处理模型的权重信息。
31、进一步地,所述语音交互方法包括:
32、基于所述语音识别信息对应的用户特征以及所述用户特征对应历史信息,对所述目标答复信息进行个性化处理,以确定与所述用户特征匹配的个性化答复信息;
33、输出所述个性化答复信息。
34、进一步地,所述基于所述语音识别信息对应的用户特征以及所述用户特征对应历史信息,对所述目标答复信息进行个性化处理,以确定与所述用户特征匹配的个性化答复信息,包括:
35、将所述目标答复信息以及所述语音识别信息对应的用户标识输入后置大模型,以确定所述个性化答复信息;其中,所述后置大模型基于所述用户特征以及所述历史信息训练得到。
36、进一步地,所述模型配置信息包括至少一个自然语言理解模型和/或至少一个自然语言处理大模型。
37、为实现上述目的,第二方面,本申请还提供一种语音交互装置,所述语音交互装置包括:
38、获取模块,用于获取语音识别信息;
39、确定模块,用于将所述语音识别信息输入前置大模型,以从模型配置信息中确定与所述语音识别信息对应的至少一个初始处理模型;其中,所述前置大模型用于对所述语音识别信息进行垂域的确定,所述模型配置信息包括至少一个处理模型,所述处理模型用于进行语音交互;
40、所述确定模块,还用于基于至少一个所述初始处理模型以及所述语音识别信息,确定目标答复信息。
41、为实现上述目的,第三方面,本申请还提供一种车辆,包括:处理器和存储器,所述处理器用于执行所述存储器中存储的控制程序,以实现如上述第一方面任一项所述的语音交互方法。
42、为实现上述目的,第四方面,本申请还提供一种存储介质,该存储介质存储有一个或者至少一个程序,所述一个或者至少一个程序可被一个或者至少一个处理器执行,以实现如上所述的语音交互方法。
43、本申请的有益效果:
44、本申请中,可以为不同的语音任务匹配合适的处理模型,可以很好的应对复杂、大规模以多变的语言任务,可以提供更高级、更灵活、更人性化、更优质的语音交互体验,而且便于为语音交互带来了多样化的功能选择、定制能力以及持续的技术更新。
技术特征:
1.一种语音交互方法,其特征在于,所述语音交互方法包括:
2.根据权利要求1所述的语音交互方法,其特征在于,所述将所述语音识别信息输入前置大模型,以从模型配置信息中确定与所述语音识别信息对应的至少一个初始处理模型,包括:
3.根据权利要求2所述的语音交互方法,其特征在于,所述将所述语音识别信息输入前置大模型之后,所述语音交互方法包括:
4.根据权利要求2所述的语音交互方法,其特征在于,所述前置大模型由以下方式确定;
5.根据权利要求2所述的语音交互方法,其特征在于,所述基于至少一个所述初始处理模型对所述语音识别信息进行处理,以确定目标答复信息,包括:
6.根据权利要求2所述的语音交互方法,其特征在于,所述基于至少一个所述初始处理模型对所述语音识别信息进行处理,以确定目标答复信息,包括:
7.根据权利要求5或6所述的语音交互方法,其特征在于,所述从至少一个所述初始垂域中确定目标垂域,包括:
8.根据权利要求5或6所述的语音交互方法,其特征在于,所述从所述目标垂域对应的所述初始处理模型中确定目标处理模型,包括:
9.根据权利要求1所述的语音交互方法,其特征在于,所述语音交互方法包括:
10.根据权利要求9所述的语音交互方法,其特征在于,所述基于所述语音识别信息对应的用户特征以及所述用户特征对应历史信息,对所述目标答复信息进行个性化处理,以确定与所述用户特征匹配的个性化答复信息,包括:
11.根据权利要求1-6和9-10中任一项所述的语音交互方法,其特征在于,所述模型配置信息包括至少一个自然语言理解模型和/或至少一个自然语言处理大模型。
12.一种语音交互装置,其特征在于,所述语音交互装置包括:
13.一种车辆,其特征在于,包括:处理器和存储器,所述处理器用于执行所述存储器中存储的控制程序,以实现权利要求1-11中任一项所述的语音交互方法。
14.一种存储介质,其特征在于,所述存储介质存储有一个或者至少一个程序,所述一个或者至少一个程序可被一个或者至少一个处理器执行,以实现权利要求1-11中任一项所述的语音交互方法。
技术总结
本申请涉及一种语音交互方法、装置、车辆及存储介质,其中,语音交互方法包括:获取语音识别信息;将语音识别信息输入前置大模型,以从模型配置信息中确定与语音识别信息对应的至少一个初始处理模型;其中,前置大模型用于对语音识别信息进行垂域的确定,模型配置信息包括至少一个处理模型;基于至少一个初始处理模型对语音识别信息进行处理,以确定目标答复信息。本申请中,可以为不同的语音任务匹配合适的处理模型,可以很好的应对复杂、大规模以多变的语言任务,可以提供更高级、更灵活、更人性化、更优质的语音交互体验,而且便于为语音交互带来了多样化的功能选择、定制能力以及持续的技术更新。
技术研发人员:张大伟,郝玖锋
受保护的技术使用者:重庆长安汽车股份有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!