一种基于mixup方法的语音识别方法与流程
本发明涉及语音识别,具体为一种基于mixup方法的语音识别方法。
背景技术:
1、随着深度学习技术的发展,自动语音识别(automatic speechrecognition,简称asr)技术得到了迅速的发展。例如dnn、cnn、rnn以及一些端到端模型等先进模型的识别精度优于ann(artificialneuralnetwork,人工神经网络,简称ann)、hmm(hiddenmarkovmodel,隐马尔可夫模型,简称hmm)等传统混合模型。然而,基于深度学习的asr模型需要大量的标记训练数据来对抗过拟合并确保高精度,特别是对于训练数据很少、应用场景变化多样的语音识别任务。
2、如公开号为cn114187898a,名称为“一种基于融合神经网络结构的端到端语音识别方法”的专利申请,其通过使用specaugment数据增强算法对音频的mel频谱进行数据增强,属于开源算法,同时该方法存在超参数过多、不好调控等缺点。
3、公开号为cn114171012a,名称为“一种基于特征剪裁和平移的语音识别数据增强方法”的专利申请,其通过对音频的频谱分别在时间轴和频率轴生成平移矩阵,然后使用平移矩阵对原频谱做矩阵变换得到新的频谱特征,该方法类似于specaugment方法,存在着超参数多、适应性不强等缺点。
4、公开号为cn110211575a,名称为“用于数据增强的语音加噪方法及系统”的专利申请,其利用无噪音频和带噪音频同时输入网络,同时对无噪音频添加随机高斯噪声得到噪音隐向量,最后将带噪音频隐向量以及无噪音频得到的噪音隐向量同时训练语音识别模型来提升模型的鲁棒性。此种方法首先对训练数据要求较高,目前无噪音频比较少,数据获取难度较高。且随机添加噪声不好控制噪声添加程度,可能会降低模型的识别能力。
5、公开号为cn114974217a,名称为“数据增强方法、装置、设备和存储介质”的专利申请,其使用扰动单元、编码单元和解码单元对音频进行数据增强,该方法在原始音频的时域上分别进行速率扰动和音量扰动,并通过低通滤波进行编码,然后训练asr模型。此种方法需手动设置好扰动参数以及滤波系数,实际应用起来参数不好控制,效果难以保证。
6、基于此种现状,目前提出了诸多对asr数据的增强方法,主要是针对asr原始训练的音频数据,如速度扰动、音调调节、随机添加噪声等方式。同时,specaugment方法提出分别沿着时间轴和频率轴对音频的mel频谱图进行掩码,并且实验证明该方法在识别精度上取得了很好的提高。但这些方法都集中在改变原始输入的音频或其对应的频谱图,而没有改变对应的标签。同时,速度扰动等这些对原始音频进行数据增强的方式需要针对不同的音频长度、速度、音量等因素设置动态参数,需要仔细调整参数才能达到一定的效果。且specaugment方法需要大量的超参数(时间扭曲参数w,时间频率掩码参数t和f,时间掩码上限p,时间频率掩码数量mf和mt)来确定如何进行语音增强,其中参数不当可能会造成大量的、关键的信息丢失而不能正确生成文本,或者可能对语音产生很小的变化而没有增强效果。
技术实现思路
1、本发明的目的是提供一种基于mixup方法的语音识别方法,以解决上述现有技术中的不足之处。
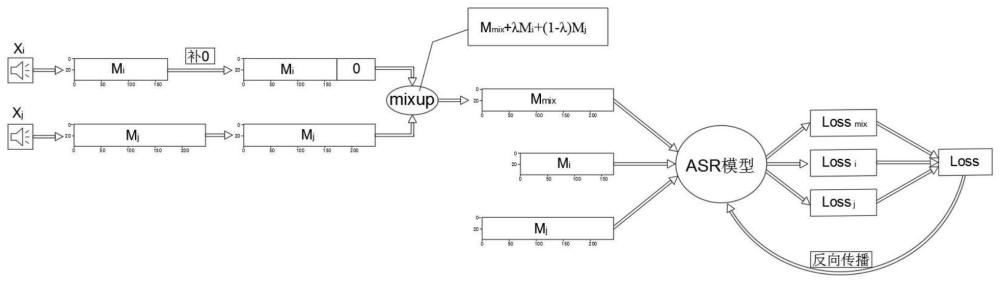
2、为了实现上述目的,本发明提供如下技术方案:一种基于mixup方法的语音识别方法,包括以下步骤:s1、mixup输入音频:对两个输入音频xi和xj,先分别求两个音频的mel频谱,分别得到形状为[li,40]和[lj,40]的mel频谱mi和mj,其中li和lj代表两个音频的mel频谱长度,然后将mi和mj通过补0至相同长度;使用mixup方法对补0至相同长度的mi和mj频谱进行mixup操作,得到mixup后的mel频谱mmix;s2、神经网络训练:分别将mel频谱mi、mj以及mmix同时输入神经网络中,得到对应的网络预测值pi、pj以及pmix,并使用下述公式计算当前step的loss,l(i,mix)=l(pmix,yi),l(j,mix)=l(pmix,yj),li=l(pi,yi),lj=l(pj,yj),l=λl(i,mix)+(1-λ)l(j,mix)+li+lj,其中,yi和yj分别代表第i个和第j个训练样本对应的标签,l代表asr模型训练过程中所用的loss函数;s3、神经网络参数更新:使用s2公式所表示的loss函数计算方式来反向传播,更新神经网络的参数。
3、进一步的,所述mixup方法为:mmix+λmi+(1-λ)mj,其中mi代表第i个训练样本,mj代表第j个训练样本,mmix代表mixup操作之后的训练样本,λ是融合参数,服从beta(α,α)分布,α取值范围为[0,∞]。
4、进一步的,所述[li,40]和[lj,40]中的40为固定的mel频谱维度。
5、进一步的,所述loss函数包括ctc loss、ce loss或labelsmooth loss。
6、相比于现有的语音识别模型中的数据增强方法,本发明提供的一种基于mixup方法的语音识别方法,通过将图像识别任务中的mixup操作引入asr任务中,为了解决不同音频长度不一致无法直接相加的问题,本发明首先提取每一个音频的mel频谱,并通过补0至相同长度,在mel频谱上就能实现两个音频的mixup操作,mel频谱是音频在频域上的表示。由于每条音频标签长度不等且是离散分布,然后先用mixup之后的音频分别与两个输入音频对应的标签计算loss,再在loss上进行mixup操作,避免了标签size(标签长度)不一致无法直接进行mixup的问题。
7、通过该方法来训练asr模型主要有以下几个优点:1)训练样本多样性,通过每次随机对训练数据中的两个音频以及对应标签进行mixup操作获得新的样本,同时利用两个音频的原有标签来监督mixup之后的训练样本,提升asr模型的鲁棒性;2)同时将mixup之前的两个音频以及对应标签训练asr模型,可以同时提高asr模型的准确率;3)在训练每个epoch时,由于每次mixup操作的两个音频都不同,所以每个epoch训练数据都不一致,丰富了训练样本。
技术特征:
1.一种基于mixup方法的语音识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于mixup方法的语音识别方法,其特征在于,在s3中,使用s2中的公式所表示的loss函数计算方式来反向传播,更新神经网络的参数。
3.根据权利要求1所述的一种基于mixup方法的语音识别方法,其特征在于,所述mixup方法为:mmix+λmi+(1-λ)mj,其中mi代表第i个训练样本,mj代表第j个训练样本,mmix代表mixup操作之后的训练样本。
4.根据权利要求3所述的一种基于mixup方法的语音识别方法,其特征在于,所述λ是融合参数,服从beta(α,α)分布,α取值范围为[0,∞]。
5.根据权利要求1所述的一种基于mixup方法的语音识别方法,其特征在于,所述[li,40]和[lj,40]中的40均为固定的mel频谱维度。
6.根据权利要求2所述的一种基于mixup方法的语音识别方法,其特征在于,所述loss函数采用ctc loss。
7.根据权利要求2所述的一种基于mixup方法的语音识别方法,其特征在于,所述loss函数采用celoss。
8.根据权利要求2所述的一种基于mixup方法的语音识别方法,其特征在于,所述loss函数采用labelsmoothloss。
9.根据权利要求1所述的一种基于mixup方法的语音识别方法,其特征在于,两个输入音频xi和xj的标签长度不相等。
10.根据权利要求1所述的一种基于mixup方法的语音识别方法,其特征在于,两个输入音频xi和xj的标签是离散的。
技术总结
本发明公开了一种基于mixup方法的语音识别方法,涉及语音识别处理技术领域,包括以下步骤:S1、对两个输入音频X<subgt;i</subgt;和X<subgt;j</subgt;,分别得到频谱M<subgt;i</subgt;和M<subgt;j</subgt;,然后将M<subgt;i</subgt;和M<subgt;j</subgt;通过补0至相同长度;使用mixup方法对补0至相同长度的M<subgt;i</subgt;和M<subgt;j</subgt;频谱进行mixup操作,得到mixup后的Mel频谱M<subgt;mix</subgt;;S2、分别将Mel频谱M<subgt;i</subgt;、M<subgt;j</subgt;以及M<subgt;mix</subgt;同时输入神经网络中,得到对应的网络预测值P<subgt;i</subgt;、P<subgt;j</subgt;以及P<subgt;mix</subgt;,并使用公式计算当前step的Loss;S3、使用S2公式所表示的Loss函数计算方式来反向传播,更新神经网络的参数。本发明能够显著提升ASR模型的鲁棒性与准确性,并且丰富了训练样本。
技术研发人员:凌承昆
受保护的技术使用者:天翼云科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!