一种耳鸣治疗声的优化方法及系统与流程
本发明涉及耳鸣声治疗音频数据处理,尤其涉及一种耳鸣声治疗音频优化的方法。
背景技术:
1、耳鸣是指在没有外部声源存在的情况下,由患者主观听觉感知到类似纯音、蝉声等干扰声的现象,甚至会导致患者失眠和抑郁,严重影响患者正常生活,且在临床上高频耳鸣患者较为普遍。
2、由于对多种类型耳鸣都有一定缓解效果,且治疗代价低,声治疗被广泛应用于耳鸣治疗领域。声治疗分为掩蔽疗法和切迹疗法,具体治疗方式为给患者播放掩蔽或切迹音来缓解耳鸣。
3、在掩蔽疗法中,选择的音源基本为匹配耳鸣频率的纯音或包含患者耳鸣频率的白噪声和窄带噪声,这是因为掩蔽音需要包含耳鸣频率且在耳鸣频率处能量较高,才能达到较好的掩蔽效果,但这类音源听感不佳,会降低患者的治疗服从性,而悦耳的自然声等音源低频能量较高,选择这类音源对高频耳鸣患者掩蔽效果不佳。
4、在切迹疗法中,以患者的耳鸣频率为中心,抑制或滤除一定带宽的信号,生成切迹音,且切迹频率处能量越大减轻患者感知耳鸣音的效果越好。其中,音源的选择与掩蔽音源类似,需要耳鸣频率附近的频带能量高,但是切迹音源通常基于自然声,这类声音低频含量丰富,对于低频耳鸣疗效较好,高频耳鸣效果有限。
5、同时,患者如果长时间重复听同一首音乐会使听觉细胞敏感性降低,也会激活病人耳鸣记忆回放,达不到放松减压效果,产生治疗耐受性,导致治疗效果降低。
技术实现思路
1、为了克服上述技术缺陷,本发明的第一个方面提供一种耳鸣治疗声的优化方法,其包括:
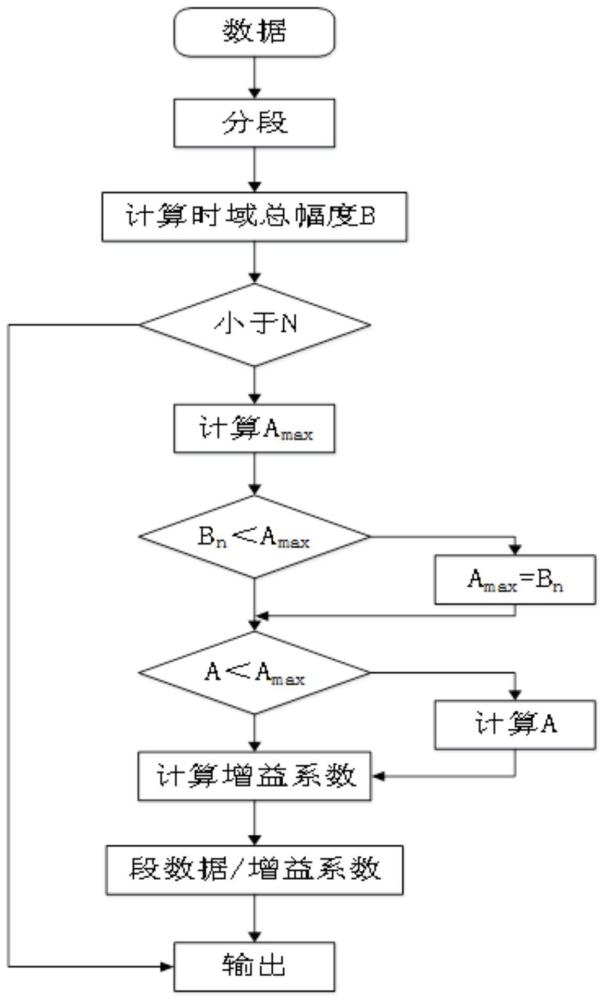
2、步骤s1:将需要播放的音源进行分段,每段包含相同数量的采样点;
3、步骤s2:每次仅实时输入一段音源数据,每段数据有重叠的输入,重叠率的范围[0,100%);
4、步骤s3:对输入的每段音源数据中的所有采样点的时域数据,计算其平方值之和;
5、步骤s4:对每段音源数据中的所述平方值之和取二次方根,从而计算出每段音源数据的时域总幅度,并依次存储每段音源数据的时域总幅度;
6、步骤s5:预设amax等于所存储的n段音源数据的时域总幅度相加并取平均值,当且仅当首次计算amax时,处理音频段数小于n时直接输出数据;
7、步骤s6:对于每一段音源数据,以n为上限,重复步骤s4-步骤s5,重新计算当前均值并与amax比较,如果当前均值>amax,则更新amax的值为当前均值;
8、步骤s7:比较a与最近更新的amax值,如果a<amax,则更新a的值,更新方式如下:a(n)=β*a(n-1)+(1-β)*amax;
9、其中,n为处理的数据段数,β为随机变化因子,取值范围[0.5,1.0);
10、步骤s8:计算每段音源数据的增益系数g,增益系数g等于所处理数据段的时域总幅度除以a;
11、步骤s9:将所处理数据段的每个采样点的时域数据除以该段音源对应的增益系数g;
12、步骤s10:实时输出处理后的一段数据,每段数据有重叠的输出,重叠率的范围[0,100%)。
13、进一步地,步骤s10进一步包括:将单独处理后的每一段数据按照首尾相连的方式进行不重叠拼接之后实时输出。
14、本申请的第二个方面提供一种耳鸣治疗声的优化系统,其包括:
15、分段模块,所述分段模块用于将需要播放的音源进行分段,每段包含相同数量的采样点;
16、输入模块,所述输入模块用于每次仅实时输入一段音源数据,每段数据有重叠的输入,重叠率的范围[0,100%);
17、计算模块,所述计算模块用于对输入的每段音源数据中的所有采样点的时域数据,计算其平方值之和;还用于对每段音源数据中的所述平方值之和取二次方根,从而计算出每段音源数据的时域总幅度,并依次存储每段音源数据的时域总幅度;还用于预设amax等于所存储的n段音源数据的时域总幅度相加并取平均值,当且仅当首次计算amax时,处理音频段数小于n时直接输出数据;还用于对于每一段音源数据,以n为上限,重新计算当前均值并与amax比较,如果均值>amax,则更新amax的值为当前均值;还用于比较a与最近更新的amax值,如果a<amax,则更新a的值,更新方式如下:a(n)=β*a(n-1)+(1-β)*amax;其中,n为处理的数据段数,β为随机变化因子,取值范围[0.5,1.0);还用于计算每段音源数据的增益系数g,增益系数g等于所处理数据段的时域总幅度除以a;还用于将所处理数据段的每个采样点的时域数据除以该段音源对应的增益系数g;
18、输出模块,所述输出模块用于实时输出处理后的一段数据,每段数据有重叠的输出,重叠率的范围[0,100%)。
19、进一步地,所述输出模块还用于将单独处理后的每一段数据按照首尾相连的方式进行不重叠拼接之后实时输出。
20、采用了上述技术方案后,与现有技术相比,具有以下有益效果:
21、本发明提供一种用于优化耳鸣声治疗音源的预处理方法,使优化后的音源适合掩蔽或切迹疗法。同时,引入了随机变化因子作为参数,以达到每重复播放同一首音乐时,都可以在保留音源大部分原有听感的前提下,细节处的声音频率会有所不同。
技术特征:
1.一种耳鸣治疗声的优化方法,其特征在于,包括:
2.如权利要求1所述的耳鸣治疗声的优化方法,其特征在于,步骤s10进一步包括:将单独处理后的每一段数据按照首尾相连的方式进行不重叠拼接之后实时输出。
3.一种耳鸣治疗声的优化系统,其特征在于,包括:
4.如权利要求3所述的耳鸣治疗声的优化方法,其特征在于,所述输出模块还用于将单独处理后的每一段数据按照首尾相连的方式进行不重叠拼接之后实时输出。
技术总结
本发明提供了一种耳鸣治疗声的优化方法及系统。优化方法包括:步骤S1:将需要播放的音源进行分段;步骤S2:每次仅实时输入一段音源数据;步骤S3:对输入的每段音源数据中的所有采样点的时域数据,计算其平方值之和;步骤S4:对每段音源数据中的所述平方值之和取二次方根,并依次存储每段音源数据的时域总幅度;步骤S5:计算A<subgt;max</subgt;;步骤S6:更新Amax的值;步骤S7:更新A的值;步骤S8:计算每段音源数据的增益系数G;步骤S9:将所处理数据段的每个采样点的时域数据除以该段音源对应的增益系数G;步骤S10:实时输出处理后的数据。本申请使每重复播放同一首音乐时,都可以使细节处的声音频率会有所不同。
技术研发人员:张硕,邢政,李思远,柴永鑫
受保护的技术使用者:上海劢司达医疗科技有限公司
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!