一种基于原生声纹特征的拾音翻译方法、设备及存储介质与流程
本发明属于语音识别,特别是涉及一种基于原生声纹特征的拾音翻译方法、设备及存储介质。
背景技术:
1、在全球化日益加深的今天,跨语言沟通已成为一项日常需求。为了满足这种需求,语音翻译技术得到了迅猛发展。传统的语音翻译流程一般包括语音信号的采集、语音识别(将语音转换为文本)、文本翻译以及语音合成(将翻译后的文本转换回语音)四个步骤。虽然现有技术在语音识别和机器翻译的准确性上取得了显著的进步,但依然存在着一些局限性。
2、现有的语音翻译系统多专注于语音的文字内容,往往忽略了声音中包含的丰富的非语言信息,这不仅导致翻译结果缺乏发言者的语音情感,同时还会降低识别翻译的准确性。
技术实现思路
1、本发明的目的在于提供一种基于原生声纹特征的拾音翻译方法、设备及存储介质,通过对发言者的原生声纹特征进行识别提取,实现对语音翻译结果的修正,同时实现对翻译结果的润色。
2、为解决上述技术问题,本发明是通过以下技术方案实现的:
3、本发明提供一种基于原生声纹特征的拾音翻译方法,包括,
4、获取原生音频;
5、将所述原生音频进行分割得到多个原音素以及对应的顺序;
6、获取每个所述原音素的若干个种类的声纹特征,其中,所述声纹特征的种类包括频谱特征、共振峰特征和/或声音强度特征;
7、对所述原生音频进行语义识别得到原语种文本;
8、将所述原语种文本翻译为转译语义文本;
9、对所述转译语义文本进行音素拟合得到多个转译音素以及对应的顺序;
10、根据所述原音素和对应的顺序以及对应的若干个种类的声纹特征对所述转译音素进行修正得到转译音频。
11、本发明还公开了一种基于原生声纹特征的拾音翻译方法,包括,
12、实时获取并存储音频流;
13、对所述音频流进行降噪滤波得到人声流;
14、获取所述人声流中的空白时段;
15、将空白时段之间的所述人声流截取作为原生音频;
16、对所述原生音频修正得到转译音频。
17、本发明还公开了一种基于原生声纹特征的拾音翻译方法,包括,
18、接收转译音频;
19、播放所述转译音频。
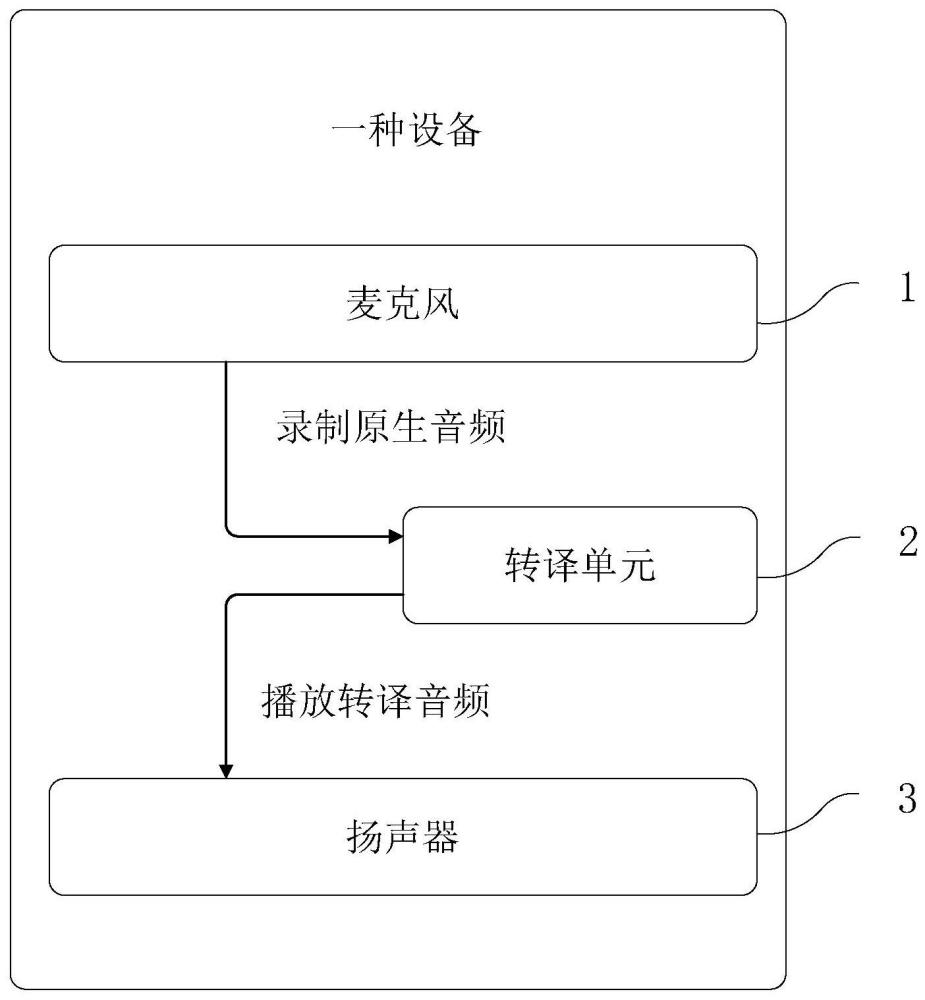
20、本发明还公开了一种设备,其特征在于,包括,
21、麦克风,用于录制得到原生音频;
22、转译单元,将所述原生音频转译为转译音频
23、扬声器,用于播放所述转译音频。
24、本发明还公开了一种存储介质,包括,
25、所述存储介质中存储有至少一条命令、至少一段程序、代码集或指令集,所述至少一条命令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现一种基于原生声纹特征的拾音翻译方法。
26、本发明通过对麦克风录制发言者的原生音频,再通过转译单元对发言者的原生声纹特征进行识别提取,最后通过扬声器对转译音频进行播放。在此过程中能够将发言者的个人的语音特征赋予翻译后合成的语音中,不仅实现对语音翻译结果的修正,同时实现对翻译结果的润色。
27、当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
技术特征:
1.一种基于原生声纹特征的拾音翻译方法,其特征在于,包括,
2.根据权利要求1所述的方法,其特征在于,所述根据所述原音素和对应的顺序以及对应的若干个种类的声纹特征对所述转译音素进行修正得到转译音频的步骤,包括,
3.根据权利要求2所述的方法,其特征在于,所述根据所述原文本段对应的若干个所述原音素的若干个种类的声纹特征对所述转译文本段对应的若干个所述转译音素进行修正得到所述转译文本段对应转译语段的步骤,包括,
4.根据权利要求3所述的方法,其特征在于,所述根据所述原文本段对应的每个所述原音素的声纹特征向量挑选出若干个特征原音素,并获取每个特征原音素的时长比例系数的步骤,包括,
5.根据权利要求3所述的方法,其特征在于,所述根据所述原生音频进行分割得到多个所述原音素以及对应的顺序对所述转译音素进行修正得到转译音频的步骤,还包括,
6.根据权利要求2所述的方法,其特征在于,所述根据所述转译文本段的顺序对所述转译语段进行合并得到转译音频的步骤,包括,
7.一种基于原生声纹特征的拾音翻译方法,其特征在于,包括,
8.一种基于原生声纹特征的拾音翻译方法,其特征在于,包括,
9.一种拾音翻译设备,其特征在于,包括,
10.一种存储介质,其特征在于,包括,
技术总结
本发明公开一种基于原生声纹特征的拾音翻译方法、设备及存储介质,涉及语音识别技术领域。本发明包括,获取原生音频;将原生音频进行分割得到多个原音素以及对应的顺序;获取每个原音素的若干个种类的声纹特征;对原生音频进行语义识别得到原语种文本;将原语种文本翻译为转译语义文本;对转译语义文本进行音素拟合得到多个转译音素以及对应的顺序;根据原音素和对应的顺序以及对应的若干个种类的声纹特征对转译音素进行修正得到转译音频。本发明通过对发言者的原生声纹特征进行识别提取,实现对语音翻译结果的修正,同时实现对翻译结果的润色。
技术研发人员:郑晓辉,牟欣语
受保护的技术使用者:青岛润恒益科技有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!